Recognition: unknown
ViBR: Automated Bug Replay from Video-based Reports using Vision-Language Models
Pith reviewed 2026-05-10 01:47 UTC · model grok-4.3
The pith
ViBR reproduces bugs from GUI screen videos by using CLIP to segment actions and vision-language models to compare states for replay.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
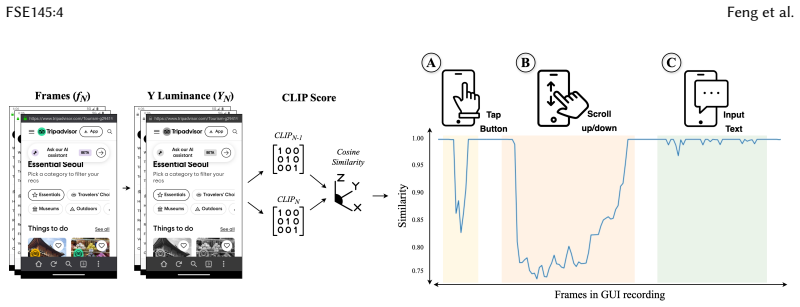
ViBR segments input GUI videos into action boundaries via CLIP-based embedding similarity, then uses vision-language models for region-aware GUI state comparison to guide step-by-step replay of the observed bug, reaching a 72 percent reproduction success rate on the collected recordings.
What carries the argument
The ViBR pipeline that detects action boundaries with CLIP embedding similarity and drives replay through vision-language model comparisons of GUI regions.
If this is right
- Developers can obtain working bug reproductions directly from video reports instead of watching and manually recreating each one.
- Methods that depend on pre-built UI transition graphs or instrumented apps become less necessary for routine bug handling.
- The volume of video-based bug reports that can be processed increases without proportional growth in manual effort.
- Heuristic image-processing techniques for replay are replaced by model-driven state comparison in many cases.
Where Pith is reading between the lines
- The same segmentation-plus-comparison pattern could extend to reproducing issues in desktop or web applications from screen recordings.
- Higher-resolution region detection in future vision-language models would likely raise the reproduction rate further on complex interfaces.
- Embedding ViBR-style replay into bug trackers would let reporters submit videos and receive confirmation of reproduction automatically.
Load-bearing premise
Pre-trained vision-language models can accurately detect action boundaries in arbitrary GUI videos and compare states across apps without app-specific fine-tuning or explicit touch indicators.
What would settle it
A new test collection of 100 GUI bug videos from previously unseen apps where ViBR reproduces fewer than half the cases would show the approach does not generalize at the reported level.
Figures







read the original abstract
Bug reports play a critical role in software maintenance by helping users convey encountered issues to developers. Recently, GUI screen capture videos have gained popularity as a bug reporting artifact due to their ease of use and ability to retain rich contextual information. However, automatically reproducing bugs from such recordings remains a significant challenge. Existing methods often rely on fragile image-processing heuristics, explicit touch indicators, or pre-constructed UI transition graphs, which require non-trivial instrumentation and app-specific setup. This paper presents ViBR, a lightweight and fully automated approach that reproduces bugs directly from GUI recordings. Specifically, ViBR combines CLIP-based embedding similarity for action boundary segmentation with Vision-Language Models (VLMs) for region-aware GUI state comparison and guided bug replay. Experimental results show that ViBR successfully reproduces 72% of bug recordings, significantly outperforming state-of-the-art baselines and ablation variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ViBR, a lightweight automated system for reproducing bugs directly from GUI screen-capture videos. It segments action boundaries via CLIP embedding similarity and uses off-the-shelf Vision-Language Models for region-aware GUI state comparison to drive replay, without requiring touch indicators or app-specific instrumentation. The central empirical claim is a 72% reproduction success rate that significantly outperforms state-of-the-art baselines and ablation variants.
Significance. If the performance claims are substantiated, the work would offer a practical advance in software maintenance by enabling fully automated replay from the increasingly common artifact of user-submitted video bug reports. The avoidance of pre-built UI graphs or explicit instrumentation is a clear strength relative to prior approaches.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the headline 72% reproduction rate is presented without any accompanying dataset size, number of recordings, application diversity statistics, or statistical significance tests. This directly undermines assessment of whether the result generalizes beyond the evaluated cases or is driven by easy instances.
- [Approach] Approach section (CLIP-based segmentation): the method assumes pre-trained CLIP embeddings reliably detect action boundaries in raw GUI videos lacking touch cues, yet no precision, recall, or boundary-error metrics are reported for this component. Because segmentation errors propagate directly to state comparison and replay, this omission is load-bearing for the overall success-rate claim.
- [Evaluation] Evaluation section (VLM state comparison): the region-aware comparison step relies on off-the-shelf VLMs without app-specific fine-tuning or explicit touch indicators, but no ablation isolating segmentation accuracy from comparison accuracy, nor error analysis of false-positive/negative state matches, is provided. This leaves the outperformance over baselines difficult to attribute.
minor comments (1)
- [Abstract] The abstract would benefit from a concise statement of dataset characteristics (e.g., number of apps, video lengths, bug types) to allow readers to contextualize the 72% figure immediately.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below. We have revised the manuscript to incorporate additional context, metrics, and analyses where the comments identify gaps in the original presentation.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the headline 72% reproduction rate is presented without any accompanying dataset size, number of recordings, application diversity statistics, or statistical significance tests. This directly undermines assessment of whether the result generalizes beyond the evaluated cases or is driven by easy instances.
Authors: We agree that the abstract would benefit from summarizing key evaluation details already present in the Evaluation section. We have revised the abstract to include a concise description of the dataset (number of recordings and application diversity) along with reference to the statistical significance tests reported in the Evaluation section. This provides readers with immediate context for assessing the 72% figure without altering the core claim. revision: yes
-
Referee: [Approach] Approach section (CLIP-based segmentation): the method assumes pre-trained CLIP embeddings reliably detect action boundaries in raw GUI videos lacking touch cues, yet no precision, recall, or boundary-error metrics are reported for this component. Because segmentation errors propagate directly to state comparison and replay, this omission is load-bearing for the overall success-rate claim.
Authors: We acknowledge the value of standalone metrics for the segmentation component. In the revised manuscript, we have added precision, recall, and boundary-error metrics for the CLIP-based action boundary detection, computed against manually annotated ground truth on the evaluation videos. These metrics demonstrate the effectiveness of pre-trained CLIP embeddings for GUI videos without touch indicators and include discussion of how residual segmentation errors are handled downstream. revision: yes
-
Referee: [Evaluation] Evaluation section (VLM state comparison): the region-aware comparison step relies on off-the-shelf VLMs without app-specific fine-tuning or explicit touch indicators, but no ablation isolating segmentation accuracy from comparison accuracy, nor error analysis of false-positive/negative state matches, is provided. This leaves the outperformance over baselines difficult to attribute.
Authors: We agree that isolating component contributions and providing error analysis improves attribution. The revised Evaluation section now includes additional ablation experiments that separately disable or modify the segmentation and region-aware VLM comparison steps. We have also added a categorized error analysis of false-positive and false-negative state matches, identifying common causes such as visual similarity between GUI states. These changes clarify the sources of ViBR's performance gains relative to the baselines. revision: yes
Circularity Check
No circularity: empirical evaluation against external baselines with no self-referential derivations or fitted predictions.
full rationale
The paper describes an empirical system (ViBR) that applies off-the-shelf CLIP embeddings for action segmentation and VLMs for state comparison, then reports a 72% reproduction rate from direct experiments on bug recordings. No equations, parameters, or first-principles derivations are present that reduce the reported success metric to quantities fitted from the evaluation data itself. The evaluation is framed as comparison to state-of-the-art baselines and ablation variants, which are external to the method. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes for the core pipeline. The approach is therefore self-contained against external benchmarks; any concerns about generalization of pre-trained models pertain to correctness or assumption strength, not circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained CLIP and vision-language models can reliably segment actions and compare GUI states from video frames without additional training or instrumentation.
Reference graph
Works this paper leans on
-
[1]
ankidroid Issue 4707
2017. ankidroid Issue 4707. https://github.com/ankidroid/Anki-Android/issues/4707
2017
-
[2]
ankidroid Issue 4977
2018. ankidroid Issue 4977. https://github.com/ankidroid/Anki-Android/issues/4977
2018
-
[3]
AndBible Issue 261
2019. AndBible Issue 261. https://github.com/AndBible/and-bible/issues/261
2019
-
[4]
BugClipper
2021. BugClipper. https://bugclipper.com/
2021
-
[5]
Command line tools for recording, replaying and mirroring touchscreen events for Android
2021. Command line tools for recording, replaying and mirroring touchscreen events for Android. https://github.com/ appetizerio/replaykit
2021
-
[6]
Python and OpenCV-based scene cut/transition detection program & library
2021. Python and OpenCV-based scene cut/transition detection program & library. https://github.com/Breakthrough/ PySceneDetect
2021
-
[7]
Record the screen on your iPhone, iPad, or iPod touch
2021. Record the screen on your iPhone, iPad, or iPod touch. https://support.apple.com/en-us/HT207935
2021
-
[8]
Take a screenshot or record your screen on your Android device
2021. Take a screenshot or record your screen on your Android device. https://support.google.com/android/answer/ 9075928?hl=en
2021
-
[9]
TestFairy
2021. TestFairy. https://www.testfairy.com/
2021
-
[10]
Video uploads now available across GitHub
2021. Video uploads now available across GitHub. https://github.blog/news-insights/product-news/video-uploads- available-github/
2021
-
[11]
Android Debug Bridge (adb) - Android Developers
2023. Android Debug Bridge (adb) - Android Developers. https://developer.android.com/studio/command-line/adb
2023
-
[12]
Android Uiautomator2 Python Wrapper
2023. Android Uiautomator2 Python Wrapper. https://github.com/openatx/uiautomator2
2023
-
[13]
Introducing ChatGPT
2023. Introducing ChatGPT. https://chat.openai.com/
2023
-
[14]
OpenAI Codex
2023. OpenAI Codex. https://openai.com/blog/openai-codex
2023
-
[15]
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku
2025. Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. https://www.anthropic.com/news/3- 5-models-and-computer-use
2025
-
[16]
Jorge Aranda and Gina Venolia. 2009. The secret life of bugs: Going past the errors and omissions in software repositories. In2009 IEEE 31st International Conference on Software Engineering. IEEE, 298–308
2009
-
[17]
Carlos Bernal-Cárdenas, Nathan Cooper, Kevin Moran, Oscar Chaparro, Andrian Marcus, and Denys Poshyvanyk
-
[18]
InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering
Translating video recordings of mobile app usages into replayable scenarios. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering. 309–321
-
[19]
Nicolas Bettenburg, Sascha Just, Adrian Schröter, Cathrin Weiss, Rahul Premraj, and Thomas Zimmermann. 2008. What makes a good bug report?. InProceedings of the 16th ACM SIGSOFT International Symposium on Foundations of software engineering. 308–318
2008
-
[20]
Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann, and Sunghun Kim. 2008. Extracting structural information from bug reports. InProceedings of the 2008 international working conference on Mining software repositories. 27–30
2008
-
[21]
Chunyang Chen, Sidong Feng, Zhenchang Xing, Linda Liu, Shengdong Zhao, and Jinshui Wang. 2019. Gallery dc: Design search and knowledge discovery through auto-created gui component gallery.Proceedings of the ACM on Human-Computer Interaction3, CSCW (2019), 1–22
2019
-
[22]
Hu Chen, Mingzhe Sun, and Eckehard Steinbach. 2009. Compression of Bayer-pattern video sequences using adjusted chroma subsampling.IEEE transactions on circuits and systems for video technology19, 12 (2009), 1891–1896
2009
-
[23]
Guangzhao Dai, Xiangbo Shu, Wenhao Wu, Rui Yan, and Jiachao Zhang. 2024. GPT4Ego: unleashing the potential of pre-trained models for zero-shot egocentric action recognition.IEEE Transactions on Multimedia(2024)
2024
- [24]
- [25]
-
[26]
Mona Erfani Joorabchi, Mehdi Mirzaaghaei, and Ali Mesbah. 2014. Works for me! characterizing non-reproducible bug reports. InProceedings of the 11th Working Conference on Mining Software Repositories. 62–71
2014
-
[27]
Mattia Fazzini, Martin Prammer, Marcelo d’Amorim, and Alessandro Orso. 2018. Automatically translating bug reports into test cases for mobile apps. InProceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis. 141–152
2018
-
[28]
2025.Towards Effective Bug Reproduction for Mobile Applications
Sidong Feng. 2025.Towards Effective Bug Reproduction for Mobile Applications. Ph. D. Dissertation. Monash University
2025
-
[29]
Sidong Feng and Chunyang Chen. 2022. Gifdroid: an automated light-weight tool for replaying visual bug reports. In Proceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings. 95–99
2022
-
[30]
Sidong Feng and Chunyang Chen. 2022. GIFdroid: automated replay of visual bug reports for Android apps. In Proceedings of the 44th International Conference on Software Engineering. 1045–1057
2022
-
[31]
Sidong Feng and Chunyang Chen. 2024. Prompting is all you need: Automated android bug replay with large language models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–13
2024
- [32]
-
[33]
Sidong Feng, Chunyang Chen, and Zhenchang Xing. 2022. Gallery dc: Auto-created gui component gallery for design search and knowledge discovery. InProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings. 80–84
2022
-
[34]
Sidong Feng, Chunyang Chen, and Zhenchang Xing. 2023. Video2Action: Reducing human interactions in action annotation of app tutorial videos. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 1–15
2023
-
[35]
Sidong Feng, Changhao Du, Huaxiao Liu, Qingnan Wang, Zhengwei Lv, Gang Huo, Xu Yang, and Chunyang Chen
-
[36]
In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP)
Agent for user: Testing multi-user interactive features in tiktok. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 57–68
- [37]
-
[38]
Sidong Feng, Haochuan Lu, Jianqin Jiang, Ting Xiong, Likun Huang, Yinglin Liang, Xiaoqin Li, Yuetang Deng, and Aldeida Aleti. 2024. Enabling cost-effective ui automation testing with retrieval-based llms: A case study in wechat. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1973–1978
2024
-
[39]
Sidong Feng, Haochuan Lu, Ting Xiong, Yuetang Deng, and Chunyang Chen. 2023. Towards efficient record and replay: A case study in wechat. InProceedings of the 31st ACM joint European software engineering conference and symposium on the foundations of software engineering. 1681–1692
2023
-
[40]
Sidong Feng, Suyu Ma, Han Wang, David Kong, and Chunyang Chen. 2024. Mud: Towards a large-scale and noise- filtered ui dataset for modern style ui modeling. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–14
2024
-
[41]
Sidong Feng, Mulong Xie, and Chunyang Chen. 2023. Efficiency matters: Speeding up automated testing with gui rendering inference. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 906–918
2023
-
[42]
Sidong Feng, Mulong Xie, Yinxing Xue, and Chunyang Chen. 2023. Read it, don’t watch it: Captioning bug recordings automatically. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2349–2361
2023
-
[43]
Lorenzo Gomez, Iulian Neamtiu, Tanzirul Azim, and Todd Millstein. 2013. Reran: Timing-and touch-sensitive record and replay for android. In2013 35th International Conference on Software Engineering (ICSE). IEEE, 72–81
2013
-
[44]
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. 2024. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14281–14290
2024
- [45]
-
[46]
2012.Troyd: Integration testing for android
Jinseong Jeon and Jeffrey S Foster. 2012.Troyd: Integration testing for android. Technical Report
2012
-
[47]
Andrew J Ko and Brad A Myers. 2006. Barista: An implementation framework for enabling new tools, interaction techniques and views in code editors. InProceedings of the SIGCHI conference on Human Factors in computing systems. 387–396
2006
-
[48]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2017. Droidbot: a lightweight ui-guided test input generator for android. In2017 IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C). IEEE, 23–26
2017
-
[49]
Hui Liu, Mingzhu Shen, Jiahao Jin, and Yanjie Jiang. 2020. Automated classification of actions in bug reports of mobile apps. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. 128–140
2020
-
[50]
Li Liu, Diji Yang, Sijia Zhong, Kalyana Suma Sree Tholeti, Lei Ding, Yi Zhang, and Leilani Gilpin. 2024. Right this way: Can VLMs Guide Us to See More to Answer Questions?Advances in Neural Information Processing Systems37 (2024), 132946–132976
2024
-
[51]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. 2024. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision. Springer, 38–55
2024
-
[52]
David G Lowe. 2004. Distinctive image features from scale-invariant keypoints.International journal of computer vision60, 2 (2004), 91–110
2004
- [53]
-
[54]
Dmitry Nurmuradov and Renee Bryce. 2017. Caret-HM: recording and replaying Android user sessions with heat map generation using UI state clustering. InProceedings of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis. 400–403
2017
- [55]
-
[56]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE145. Publication date: July 2026. ViBR: Automated Bug Replay from Video-ba...
2021
-
[57]
Yale Song, Miriam Redi, Jordi Vallmitjana, and Alejandro Jaimes. 2016. To click or not to click: Automatic selection of beautiful thumbnails from videos. InProceedings of the 25th ACM International on Conference on Information and Knowledge Management. 659–668
2016
-
[58]
Tomás Soucek and Jakub Lokoc. 2024. Transnet v2: An effective deep network architecture for fast shot transition detection. InProceedings of the 32nd ACM International Conference on Multimedia. 11218–11221
2024
-
[59]
Ting Su, Jue Wang, and Zhendong Su. 2021. Benchmarking automated gui testing for android against real-world bugs. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 119–130
2021
-
[60]
Ramadass Sudhir and Lt Dr S Santhosh Baboo. 2011. An efficient CBIR technique with YUV color space and texture features.Computer Engineering and Intelligent Systems2, 6 (2011), 78–85
2011
-
[61]
Yulei Sui, Yifei Zhang, Wei Zheng, Manqing Zhang, and Jingling Xue. 2019. Event trace reduction for effective bug replay of Android apps via differential GUI state analysis. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1095–1099
2019
- [62]
-
[63]
Yuxuan Wan, Chaozheng Wang, Yi Dong, Wenxuan Wang, Shuqing Li, Yintong Huo, and Michael Lyu. 2025. Divide- and-Conquer: Generating UI Code from Screenshots.Proceedings of the ACM on Software Engineering2, FSE (2025), 2099–2122
2025
- [64]
-
[65]
Dingbang Wang, Yu Zhao, Sidong Feng, Zhaoxu Zhang, William GJ Halfond, Chunyang Chen, Xiaoxia Sun, Jiangfan Shi, and Tingting Yu. 2024. Feedback-driven automated whole bug report reproduction for android apps. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1048–1060
2024
-
[66]
Shiqi Wang, Abdul Rehman, Zhou Wang, Siwei Ma, and Wen Gao. 2011. SSIM-motivated rate-distortion optimization for video coding.IEEE Transactions on Circuits and Systems for Video Technology22, 4 (2011), 516–529
2011
-
[67]
Craig Watman, David Austin, Nick Barnes, Gary Overett, and Simon Thompson. 2004. Fast sum of absolute differences visual landmark detector. InIEEE International Conference on Robotics and Automation, 2004. Proceedings. ICRA’04. 2004, Vol. 5. IEEE, 4827–4832
2004
-
[68]
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang. 2024. Longvlm: Efficient long video understanding via large language models. InEuropean Conference on Computer Vision. Springer, 453–470
2024
-
[69]
Mulong Xie, Sidong Feng, Zhenchang Xing, Jieshan Chen, and Chunyang Chen. 2020. UIED: a hybrid tool for GUI element detection. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1655–1659
2020
-
[70]
Mulong Xie, Zhenchang Xing, Sidong Feng, Xiwei Xu, Liming Zhu, and Chunyang Chen. 2022. Psychologically-inspired, unsupervised inference of perceptual groups of GUI widgets from GUI images. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 332–343
2022
-
[71]
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. 2023. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441(2023)
work page internal anchor Pith review arXiv 2023
-
[72]
Yue Zhao, Ishan Misra, Philipp Krähenbühl, and Rohit Girdhar. 2023. Learning video representations from large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6586–6597
2023
-
[73]
Yu Zhao, Tingting Yu, Ting Su, Yang Liu, Wei Zheng, Jingzhi Zhang, and William GJ Halfond. 2019. Recdroid: automatically reproducing android application crashes from bug reports. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 128–139
2019
-
[74]
Ting Zhou, Yanjie Zhao, Xinyi Hou, Xiaoyu Sun, Kai Chen, and Haoyu Wang. 2025. DeclarUI: Bridging Design and Development with Automated Declarative UI Code Generation.Proceedings of the ACM on Software Engineering2, FSE (2025), 219–241. Received 2026-02-24; accepted 2026-03-24 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE145. Publication date: July 2026
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.