Recognition: unknown
Demonstrating a Future for MLIR-native DSL Compilers on a NumPy-like Example
Pith reviewed 2026-05-10 00:42 UTC · model grok-4.3
The pith
A NumPy-like DSL implements its full frontend and semantic analyses directly inside MLIR using a new type checker.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a NumPy-like DSL for offloading numeric tensor kernels can be made entirely MLIR-native by implementing all frontend actions and semantic analyses directly within MLIR. This is made possible by a new dialect-agnostic MLIR type checker. A simple yet effective parallel-first lowering scheme then connects the language to another MLIR dataflow dialect for seamless offloading. The resulting system performs well on real-world use cases from weather modeling and computational fluid dynamics in Fortran.
What carries the argument
A dialect-agnostic type checker that performs all frontend actions and semantic analyses directly inside MLIR.
If this is right
- DSL compilers can avoid external toolchains for parsing and analysis while retaining domain expressiveness.
- Tensor kernels can be lowered to dataflow representations for offloading through a parallel-first strategy.
- The approach supports production workloads in scientific computing such as weather modeling and computational fluid dynamics.
- Open-source MLIR-native DSL implementations become feasible without duplicating standard compiler infrastructure.
Where Pith is reading between the lines
- Similar type checkers could be reused across additional dialects to support mixed-language programs inside the same representation.
- Broader testing on domains beyond numeric tensors would clarify how far the native-frontend model generalizes.
- The Fortran demonstrations suggest a route to accelerate legacy scientific codes by selective offloading of hot kernels.
- Reduced duplication of frontend work across DSL projects could shorten the time from prototype to maintained production tool.
Load-bearing premise
That a dialect-agnostic type checker and parallel-first lowering scheme can be implemented inside MLIR without losing expressiveness or incurring unacceptable overhead compared with conventional DSL compiler stacks.
What would settle it
A side-by-side measurement of compilation time, generated-code runtime, and supported language features for the same NumPy-like kernels when compiled through this MLIR-native stack versus a conventional external DSL compiler toolchain on the weather modeling and CFD benchmarks.
Figures


read the original abstract
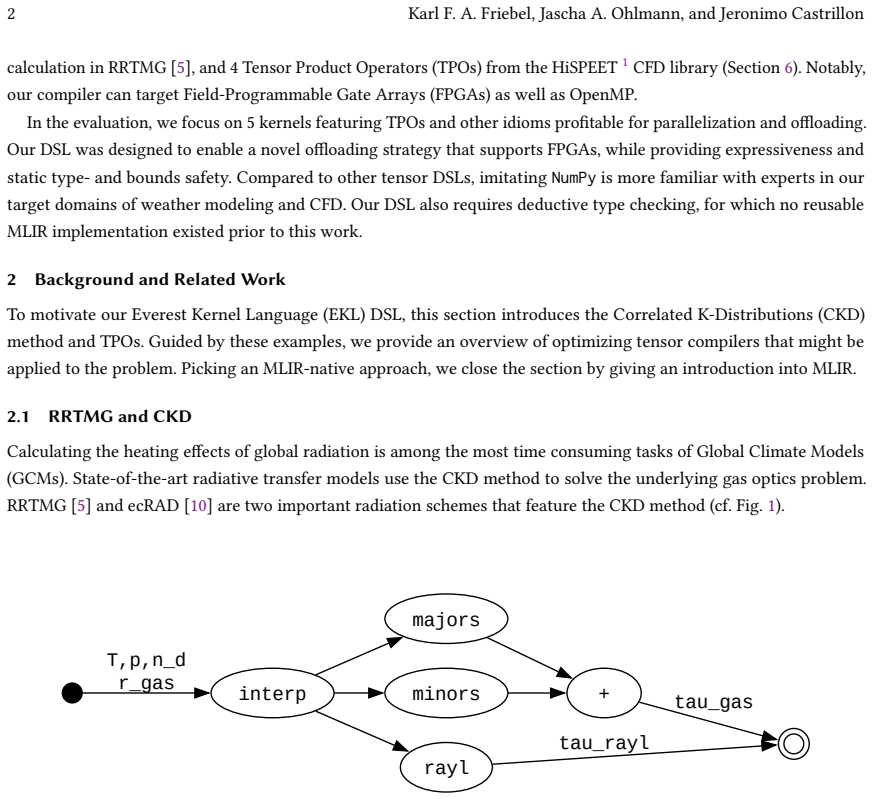
Compilers for general-purpose languages have been shown to be at a disadvantage when it comes to specialized application domains as opposed to their Domain-Specific Language (DSL) counterparts. However, the field of DSL compilers features little consolidation in terms of compiler frameworks and adjacent software ecosystems. As a result, considerable work is duplicated, lost to maintenance issues, or remains undiscovered, and most DSLs are never considered "production-ready". One notable development is the introduction of the Multi-Level Intermediate Representation (MLIR), which promises a similar impact on DSL compilers as LLVM had on general-purpose tooling. In this work, we present a NumPy-like DSL made for offloading numeric tensor kernels that is entirely MLIR-native. In a first for open-source, it implements all frontend actions and semantic analyses directly within MLIR. Most notably, this is made possible by our new dialect-agnostic MLIR type checker, created for the future of DSLs in MLIR. We implement a simple, yet effective, parallel-first lowering scheme that connects our language to another MLIR dataflow dialect for seamless offloading. We show that our approach performs well in real-world use cases from the domain of weather modeling and Computational Fluid Dynamics (CFD) in Fortran.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a NumPy-like DSL for offloading numeric tensor kernels whose entire frontend (parsing, semantic analysis) and lowering are implemented as MLIR operations and passes. This is enabled by a new dialect-agnostic MLIR type checker that operates on MLIR type and attribute interfaces. A parallel-first lowering scheme targets another MLIR dataflow dialect for seamless offloading. The approach is demonstrated by successfully compiling and running weather-modeling and CFD kernels originally written in Fortran.
Significance. If the implementation claims hold, the work is significant because it supplies the first open-source, fully MLIR-native DSL compiler stack that keeps frontend components inside MLIR rather than relying on external parsers or custom frontends. The dialect-agnostic type checker directly addresses a recurring obstacle for multi-dialect DSLs and could reduce duplicated effort across the DSL ecosystem. The successful lowering of real Fortran-derived numeric kernels provides concrete evidence that the architecture can preserve necessary expressiveness for tensor-heavy scientific codes.
major comments (2)
- Abstract: the claim that the approach 'performs well in real-world use cases' is unsupported by any quantitative benchmarks, timing data, error metrics, or baseline comparisons against conventional DSL stacks or hand-written offload code. Without such evidence the central demonstration that the MLIR-native design incurs no unacceptable overhead remains unverified.
- Abstract and implementation description: the assertion that this is 'a first for open-source' in placing all frontend actions inside MLIR would be strengthened by an explicit comparison table or section that enumerates prior MLIR-based DSL efforts and precisely defines which frontend actions (lexing, parsing, name resolution, type checking) are newly internalized.
minor comments (1)
- The manuscript would benefit from a short table listing the new MLIR operations and passes introduced for the frontend, together with their dialect dependencies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and indicate the revisions planned for the next version of the paper.
read point-by-point responses
-
Referee: Abstract: the claim that the approach 'performs well in real-world use cases' is unsupported by any quantitative benchmarks, timing data, error metrics, or baseline comparisons against conventional DSL stacks or hand-written offload code. Without such evidence the central demonstration that the MLIR-native design incurs no unacceptable overhead remains unverified.
Authors: The manuscript's core demonstration is the successful compilation and execution of complex Fortran-derived kernels from weather modeling and CFD domains, establishing that the MLIR-native frontend and parallel-first lowering preserve the expressiveness required for tensor-heavy scientific codes. We acknowledge that the abstract phrasing 'performs well' is not backed by quantitative timing data or baseline comparisons in the current version. To address this, we will add an evaluation section with timing measurements on the target workloads and comparisons against hand-written offload code and conventional DSL stacks. revision: yes
-
Referee: Abstract and implementation description: the assertion that this is 'a first for open-source' in placing all frontend actions inside MLIR would be strengthened by an explicit comparison table or section that enumerates prior MLIR-based DSL efforts and precisely defines which frontend actions (lexing, parsing, name resolution, type checking) are newly internalized.
Authors: We agree that a structured comparison would better support the novelty claim regarding full internalization of frontend actions. The manuscript currently asserts this as a first for open-source MLIR-native DSL compilers. In revision we will insert a dedicated comparison table (likely in the related work section) that enumerates prior MLIR DSL efforts and explicitly maps which frontend stages—lexing, parsing, name resolution, and type checking—are implemented inside MLIR versus relying on external components. revision: yes
Circularity Check
No circularity: implementation demonstration without derivation chain
full rationale
This paper is an implementation and demonstration report for an MLIR-native NumPy-like DSL, including a dialect-agnostic type checker and parallel-first lowering. No mathematical derivations, predictions, fitted parameters, or first-principles results are presented that could reduce to inputs by construction. Claims rest on the concrete open-source artifact and empirical results from Fortran kernels in weather/CFD domains, which constitute independent evidence rather than self-referential steps. No self-citation load-bearing, ansatz smuggling, or renaming of known results occurs in a load-bearing way.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLIR's existing infrastructure is sufficient to host all frontend actions and semantic analyses for a NumPy-like tensor DSL without external tools.
invented entities (1)
-
dialect-agnostic MLIR type checker
no independent evidence
Reference graph
Works this paper leans on
-
[1]
d.].ClangIR - A new high-level IR for clang.https://llvm.github.io/clangir
[n. d.].ClangIR - A new high-level IR for clang.https://llvm.github.io/clangir
-
[2]
d.].Torch-MLIR
[n. d.].Torch-MLIR. https://github.com/llvm/torch-mlir
-
[3]
2024.Leveraging the MLIR infrastructure for the computing continuum
Jiahong Bi, Guilherme Korol, and Jeronimo Castrillon. 2024.Leveraging the MLIR infrastructure for the computing continuum. Technical Report. Technische Universität Dresden. https://www.cfaed.tu-dresden.de/files/Images/people/chair-cc/publications/2409_BI_CPSW.pdf
2024
-
[4]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al
-
[5]
In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18)
{TVM}: An automated {End-to-End} optimizing compiler for deep learning. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). 578–594
-
[6]
S.A. Clough, M.W. Shephard, E.J. Mlawer, J.S. Delamere, M.J. Iacono, K. Cady-Pereira, S. Boukabara, and P.D. Brown. 2005. Atmospheric radiative transfer modeling: a summary of the AER codes.Journal of Quantitative Spectroscopy and Radiative Transfer91, 2 (2005), 233–244. doi:10.1016/j. jqsrt.2004.05.058
work page doi:10.1016/j 2005
-
[7]
M. O. Deville, P. F. Fischer, and E. H. Mund. 2002.High-Order Methods for Incompressible Fluid Flow. Cambridge University Press. doi:10.1017/ CBO9780511546792
2002
-
[8]
Andi Drebes. 2020. Teckyl: An MLIR frontend for tensor operations. https://github.com/andidr/teckyl
2020
-
[9]
Fabrizio Ferrandi, Vito Giovanni Castellana, Serena Curzel, Pietro Fezzardi, Michele Fiorito, Marco Lattuada, Marco Minutoli, Christian Pilato, and Antonino Tumeo. 2021. Bambu: an open-source research framework for the high-level synthesis of complex applications. In2021 58th ACM/IEEE 18 Karl F. A. Friebel, Jascha A. Ohlmann, and Jeronimo Castrillon Desig...
2021
-
[10]
Franz Franchetti, Tze Meng Low, Doru Thom Popovici, Richard M. Veras, Daniele G. Spampinato, Jeremy R. Johnson, Markus Püschel, James C. Hoe, and José M. F. Moura. 2018. SPIRAL: Extreme Performance Portability.Proc. IEEE106, 11 (2018), 1935–1968. doi:10.1109/JPROC.2018.2873289
-
[11]
Robin Hogan and Alessio Bozzo. 2016. ECRAD: A new radiation scheme for the IFS. doi:10.21957/whntqkfdz
-
[12]
2003.The computation factory: de Prony’s project for making tables in the 1790s
George Karniadakis and Spencer Sherwin. 2005.Spectral/hp Element Methods for Computational Fluid Dynamics. Oxford University Press. doi:10.1093/acprof:oso/9780198528692.001.0001
work page doi:10.1093/acprof:oso/9780198528692.001.0001 2005
-
[13]
Fredrik Kjolstad, Shoaib Kamil, Stephen Chou, David Lugato, and Saman Amarasinghe. 2017. The Tensor Algebra Compiler.Proc. ACM Program. Lang.1, OOPSLA, Article 77 (Oct. 2017), 29 pages. doi:10.1145/3133901
-
[14]
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Oleksandr Zinenko. 2021. MLIR: Scaling Compiler Infrastructure for Domain Specific Computation. In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). 2–14. doi:10.1109/CGO51591.2021.9370308
-
[15]
Roland Leißa, Marcel Ullrich, Joachim Meyer, and Sebastian Hack. 2025. MimIR: An Extensible and Type-Safe Intermediate Representation for the DSL Age.Proc. ACM Program. Lang.9, POPL, Article 4 (Jan. 2025), 31 pages. doi:10.1145/3704840
-
[16]
Martin Lücke, Michel Steuwer, and Aaron Smith. 2021. Integrating a functional pattern-based IR into MLIR. InProceedings of the 30th ACM SIGPLAN International Conference on Compiler Construction(Virtual, Republic of Korea)(CC 2021). Association for Computing Machinery, New York, NY, USA, 12–22. doi:10.1145/3446804.3446844
-
[17]
Jarno Mielikainen, Erik Price, Bormin Huang, Hung-Lung Allen Huang, and Tsengdar Lee. 2016. GPU Compute Unified Device Architecture (CUDA)-based Parallelization of the RRTMG Shortwave Rapid Radiative Transfer Model.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing9, 2 (2016), 921–931. doi:10.1109/JSTARS.2015.2427652
-
[18]
Christian Pilato, Subhadeep Banik, Jakub Beránek, Fabien Brocheton, Jeronimo Castrillon, Riccardo Cevasco, Radim Cmar, Serena Curzel, Fabrizio Ferrandi, Karl F. A. Friebel, Antonella Galizia, Matteo Grasso, Paulo Silva, Jan Martinovic, Gianluca Palermo, Michele Paolino, Andrea Parodi, Antonio Parodi, Fabio Pintus, Raphael Polig, David Poulet, Francesco Re...
-
[19]
Christian Pilato, Stanislav Bohm, Fabien Brocheton, Jeronimo Castrillon, Riccardo Cevasco, Vojtech Cima, Radim Cmar, Dionysios Diamantopoulos, Fabrizio Ferrandi, Jan Martinovic, Gianluca Palermo, Michele Paolino, Antonio Parodi, Lorenzo Pittaluga, Daniel Raho, Francesco Regazzoni, Katerina Slaninova, and Christoph Hagleitner. 2021. EVEREST: A design envir...
-
[20]
Robert Pincus, Eli J. Mlawer, and Jennifer S. Delamere. 2019. Balancing Accuracy, Efficiency, and Flexibility in Ra- diation Calculations for Dynamical Models.Journal of Advances in Modeling Earth Systems11, 10 (2019), 3074–3089. arXiv:https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2019MS001621 doi:10.1029/2019MS001621
-
[21]
Norman A. Rink and Jeronimo Castrillon. 2019. TeIL: a type-safe imperative Tensor Intermediate Language. InProceedings of the 6th ACM SIGPLAN International Workshop on Libraries, Languages, and Compilers for Array Programming (ARRAY)(Phoenix, AZ, USA)(ARRAY 2019). ACM, New York, NY, USA, 57–68. doi:10.1145/3315454.3329959
-
[22]
Norman A. Rink, Immo Huismann, Adilla Susungi, Jeronimo Castrillon, Jörg Stiller, Jochen Fröhlich, and Claude Tadonki. 2018. CFDlang: High-level code generation for high-order methods in fluid dynamics. InProceedings of the Real World Domain Specific Languages Workshop 2018(Vienna, Austria)(RWDSL2018). Association for Computing Machinery, New York, NY, US...
-
[23]
William C Skamarock, Joseph B Klemp, Jimy Dudhia, David O Gill, Zhiquan Liu, Judith Berner, Wei Wang, Jordan G Powers, Michael G Duda, Dale M Barker, et al. 2019. A description of the advanced research WRF version 4.NCAR tech. note ncar/tn-556+ str145 (2019)
2019
- [24]
-
[25]
Stephanie Soldavini, Felix Suchert, Serena Curzel, Michele Fiorito, Karl Friebel, Fabrizio Ferrandi, Radim Cmar, Jeronimo Castrillon, and Christian Pilato. 2024. Etna: MLIR-Based System-Level Design and Optimization for Transparent Application Execution on CPU-FPGA Nodes. In2024 IEEE 32nd Annual International Symposium on Field-Programmable Custom Computi...
-
[26]
Jörg Stiller. 2020. A spectral deferred correction method for incompressible flow with variable viscosity.J. Comput. Phys.423 (2020), 7–12. doi:10.1016/j.jcp.2020.109840
-
[27]
Rink, Albert Cohen, Jeronimo Castrillon, and Claude Tadonki
Adilla Susungi, Norman A. Rink, Albert Cohen, Jeronimo Castrillon, and Claude Tadonki. 2018. Meta-programming for Cross-Domain Tensor Optimizations. InProceedings of 17th ACM SIGPLAN International Conference on Generative Programming: Concepts and Experiences (GPCE’18) (Boston, MA, USA)(GPCE 2018). ACM, New York, NY, USA, 79–92. doi:10.1145/3278122.3278131
-
[28]
Yuzhu Wang, Mingxin Guo, Yuan Zhao, and Jinrong Jiang. 2021. GPUs-RRTMG_LW: high-efficient and scalable computing for a longwave radiative transfer model on multiple GPUs.The Journal of Supercomputing77 (2021), 4698–4717
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.