Recognition: unknown
Efficient Page Migration in Hybrid Memory Systems
Pith reviewed 2026-05-10 01:10 UTC · model grok-4.3
The pith
Duon stores updated page mappings directly in the TLB and page table to avoid shootdowns and invalidations during migration in hybrid memory systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a flat address space that pools high-bandwidth memory with slower DRAM or NVM, page migration to faster tiers normally requires TLB shootdowns and cache line invalidations. Duon eliminates these steps by writing the updated mapping information directly into the TLB and page table for the remapped pages.
What carries the argument
Duon, a mechanism that stores the new mapping for each migrated page directly inside the TLB and page table entries so that shootdowns and invalidations are no longer needed.
If this is right
- Page migration no longer triggers TLB shootdowns.
- Cache lines remain valid after a page is relocated.
- Any existing page migration policy can be used without added overhead.
- Overall instructions-per-cycle performance rises by 3.87 percent compared with prior methods.
Where Pith is reading between the lines
- More frequent page moves become practical because their cost drops.
- The same direct-update idea could apply to other large-memory remapping schemes.
- Lower migration overhead may allow systems to keep more data in fast memory and reduce energy spent on slower tiers.
Load-bearing premise
Directly writing new mappings into the TLB and page table after migration keeps the system correct and does not create hidden performance or coherence problems on real hardware.
What would settle it
A workload run with Duon that still shows accesses using stale TLB entries or cache coherence errors after a page has been moved.
Figures












read the original abstract
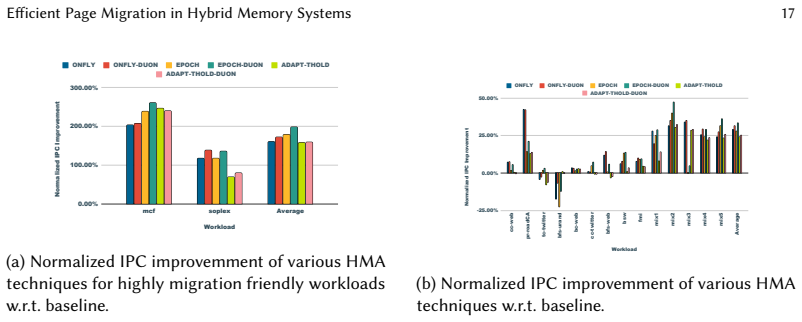
Heterogeneous Memory Architecture (HMA) aims to optimize memory usage by leveraging a combination of memory types, such as high-bandwidth memory (HBM), commodity DRAM, and non-volatile memory (NVM), when utilized as main memory. To achieve maximum performance benefits, frequently accessed data pages are prioritized for storage in the faster HBM, while less frequently accessed pages are stored in slower memory types like DRAM or NVM. This enables a more efficient allocation of memory resources and improves overall system performance. In a Flat Address Space memory organization, all memory types, both fast and slow, are treated as a unified memory pool. This approach increases the overall memory capacity accessible to the system. In Flat Address Space organization, frequently accessed data pages may need to be remapped from slower memory to faster memory to improve memory access times. Such relocation requires changes to the data/states in the TLB (TLB shootdown) and the processor cache (cache line invalidations), leading to performance degradation. To address these inefficiencies, we propose a novel solution called Duon. The goal of Duon is to eliminate the overheads associated with page migration in systems using Extended TLB and Page Table. Specifically, our approach ensures that the updated mapping information for remapped pages is carefully stored directly in the TLB and page table itself. By doing so, the need for TLB shootdown and cache line invalidation after page migration is eliminated. Consequently, our proposal results in an overall improvement in IPC by 3.87% over existing state-of-the-art techniques, enhancing the efficiency and performance of heterogeneous memory systems. Further, our approach can work with any of the existing page migration policies and improve the performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Duon, a technique for efficient page migration in heterogeneous memory systems (HMA) organized as a flat address space. It argues that by directly storing updated page mappings in an extended TLB and page table during migration from slower to faster memory (e.g., DRAM/NVM to HBM), the overheads of TLB shootdowns and cache-line invalidations are eliminated. The approach is claimed to be compatible with any existing migration policy and yields a 3.87% IPC improvement over state-of-the-art methods.
Significance. If the coherence mechanism is sound and the performance gain is reproducible, the work could reduce migration costs in hybrid memory architectures, benefiting systems that combine HBM with commodity DRAM or NVM. The compatibility claim with existing policies is a potential strength, but the absence of any correctness argument, pseudocode, or hardware model in the abstract leaves the significance highly conditional.
major comments (2)
- [Abstract] Abstract: The central claim that 'carefully storing' updated mappings directly in the TLB and page table eliminates TLB shootdown and cache-line invalidation is load-bearing for the 3.87% IPC result, yet no mechanism, coherence protocol, or hardware assumption is provided. In standard multi-core x86/ARM systems, a page-table write on one core leaves stale TLB entries on others unless an IPI-based shootdown (or equivalent) is issued; the manuscript must specify how Duon preserves translation coherence without these steps or without non-standard hardware support.
- [Abstract] Abstract: The performance claim of a 3.87% IPC improvement over state-of-the-art techniques is presented without any reference to evaluation methodology, benchmarks, workloads, simulation parameters, or baseline implementations. This makes it impossible to assess whether the gain is attributable to the proposed coherence elimination or to other unstated factors.
Simulated Author's Rebuttal
Thank you for your review and constructive feedback on our manuscript. We appreciate the points raised about the abstract and will revise it to provide additional clarity on the mechanism and evaluation details while preserving the overall contribution. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'carefully storing' updated mappings directly in the TLB and page table eliminates TLB shootdown and cache-line invalidation is load-bearing for the 3.87% IPC result, yet no mechanism, coherence protocol, or hardware assumption is provided. In standard multi-core x86/ARM systems, a page-table write on one core leaves stale TLB entries on others unless an IPI-based shootdown (or equivalent) is issued; the manuscript must specify how Duon preserves translation coherence without these steps or without non-standard hardware support.
Authors: We agree that the abstract is too concise to convey the coherence mechanism. The full manuscript describes Duon as relying on an extended TLB design that performs in-place atomic updates to page mappings, with hardware-level propagation ensuring all cores observe the new translation without software shootdowns or invalidations. This assumes an extended TLB supporting direct coherence for mapping changes, as outlined in the design section. To address the concern, we will revise the abstract to briefly state the hardware assumptions and reference the detailed protocol explanation (including any pseudocode) in the body. We will also expand the relevant sections if needed to strengthen the correctness argument. revision: yes
-
Referee: [Abstract] Abstract: The performance claim of a 3.87% IPC improvement over state-of-the-art techniques is presented without any reference to evaluation methodology, benchmarks, workloads, simulation parameters, or baseline implementations. This makes it impossible to assess whether the gain is attributable to the proposed coherence elimination or to other unstated factors.
Authors: We agree the abstract omits evaluation context due to length limits. The manuscript's evaluation section details the methodology, including cycle-accurate simulation, benchmarks, and baselines used to obtain the 3.87% IPC gain. We will revise the abstract to include a brief reference to the evaluation setup (e.g., simulation framework and workload characteristics) so readers can better attribute the reported improvement. revision: yes
Circularity Check
No circularity; engineering proposal with no derivation chain or fitted inputs
full rationale
The manuscript proposes Duon, a technique to avoid TLB shootdowns and cache invalidations during page migration by directly updating mappings in the TLB and page table. The abstract and provided text contain no equations, parameters fitted to data, self-citations used as load-bearing premises, uniqueness theorems, or ansatzes. The 3.87% IPC claim is presented as an empirical outcome of the proposal rather than a mathematical reduction to prior results. No step reduces by construction to its own inputs; the work is a self-contained systems design evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shashank Adavally, Mahzabeen Islam, and Krishna Kavi. 2021. Dynamically Adapting Page Migration Policies Based on Applications’ Memory Access Behaviors. J. Emerg. Technol. Comput. Syst. 17, 2, Article 16 (March 2021), 24 pages. doi:10.1145/3444750 , Vol. 1, No. 1, Article . Publication date: April 2026. Efficient Page Migration in Hybrid Memory Systems 21
-
[2]
Shashank Adavally and Shashankadavally. 2021. Subpage Migration in Heterogeneous Memory Systems. https: //api.semanticscholar.org/CorpusID:252564184
2021
-
[3]
Christian Bienia, Sanjeev Kumar, Jaswinder Pal Singh, and Kai Li. 2008. The PARSEC benchmark suite: Characterization and architectural implications. In2008 International Conference on Parallel Architectures and Compilation Techniques (PACT). 72–81
2008
-
[4]
E. Chen, D. Lottis, A. Driskill-Smith, D. Druist, V. Nikitin, S. Watts, X. Tang, and D. Apalkov. 2010. Non-volatile spin-transfer torque RAM (STT-RAM). In 68th Device Research Conference. 249–252. doi:10.1109/DRC.2010.5551975
-
[5]
Chiachen Chou, Aamer Jaleel, and Moinuddin Qureshi. 2017. BATMAN: techniques for maximizing system bandwidth of memory systems with stacked-DRAM. In Proceedings of the International Symposium on Memory Systems (Alexandria, Virginia) (MEMSYS ’17). Association for Computing Machinery, New York, NY, USA, 268–280. doi:10.1145/3132402.3132404
-
[6]
Chia Chen Chou, Aamer Jaleel, and Moinuddin K. Qureshi. 2014. CAMEO: A Two-Level Memory Organization with Capacity of Main Memory and Flexibility of Hardware-Managed Cache. In 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture. 1–12. doi:10.1109/MICRO.2014.63
- [7]
-
[8]
Yuncheng Guo, Yu Hua, and Pengfei Zuo. 2018. DFPC: A dynamic frequent pattern compression scheme in NVM- based main memory. In 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE). 1622–1627. doi:10.23919/DATE.2018.8342274
-
[9]
Mahzabeen Islam, Shashank Adavally, Marko Scrbak, and Krishna Kavi. 2020. On-the-fly Page Migration and Address Reconciliation for Heterogeneous Memory Systems. J. Emerg. Technol. Comput. Syst. 16, 1, Article 10 (Jan. 2020), 27 pages. doi:10.1145/3364179
-
[10]
Joe Jeddeloh and Brent Keeth. 2012. Hybrid memory cube new DRAM architecture increases density and performance. In 2012 Symposium on VLSI Technology (VLSIT). 87–88. doi:10.1109/VLSIT.2012.6242474
-
[11]
JEDEC. 2023. Low Power Double Data Rate (LPDDR) 5/5X. https://www.jedec.org/document_search?search_api_ views_fulltext=jesd209
2023
-
[12]
Loh, Cansu Kaynak, and Babak Falsafi
Djordje Jevdjic, Gabriel H. Loh, Cansu Kaynak, and Babak Falsafi. 2014. Unison Cache: A Scalable and Effective Die- Stacked DRAM Cache. In Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture (Cambridge, United Kingdom) (MICRO-47). IEEE Computer Society, USA, 25–37. doi:10.1109/MICRO.2014.51
- [13]
-
[14]
Hongshin Jun, Jinhee Cho, Kangseol Lee, Ho-Young Son, Kwiwook Kim, Hanho Jin, and Keith Kim. 2017. HBM (High Bandwidth Memory) DRAM Technology and Architecture. In2017 IEEE International Memory Workshop (IMW). 1–4. doi:10.1109/IMW.2017.7939084
-
[15]
Shivanjali Khare and Michael Totaro. 2019. Big Data in IoT. In 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT). 1–7. doi:10.1109/ICCCNT45670.2019.8944495
-
[16]
Jung-Sik Kim, Chi Sung Oh, Hocheol Lee, Donghyuk Lee, Hyong Ryol Hwang, Sooman Hwang, Byongwook Na, Joungwook Moon, Jin-Guk Kim, Hanna Park, Jang-Woo Ryu, Kiwon Park, Sang Kyu Kang, So-Young Kim, Hoyoung Kim, Jong-Min Bang, Hyunyoon Cho, Minsoo Jang, Cheolmin Han, Jung-Bae LeeLee, Joo Sun Choi, and Young-Hyun Jun. 2012. A 1.2 V 12.8 GB/s 2 Gb Mobile Wide-...
-
[17]
Youngin Kim, Hyeonjin Kim, and William J. Song. 2023. NOMAD: Enabling Non-blocking OS-managed DRAM Cache via Tag-Data Decoupling. In 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 193–205. doi:10.1109/HPCA56546.2023.10071016
-
[18]
Yoongu Kim, Weikun Yang, and Onur Mutlu. 2016. Ramulator: A Fast and Extensible DRAM Simulator.IEEE Computer Architecture Letters 15, 1 (2016), 45–49. doi:10.1109/LCA.2015.2414456
-
[19]
Apostolos Kokolis, Dimitrios Skarlatos, and Josep Torrellas. 2019. PageSeer: Using Page Walks to Trigger Page Swaps in Hybrid Memory Systems. In 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA). 596–608. doi:10.1109/HPCA.2019.00012
-
[20]
Jagadish B. Kotra, Haibo Zhang, Alaa R. Alameldeen, Chris Wilkerson, and Mahmut T. Kan- demir. 2018. CHAMELEON: A Dynamically reconfigurable heterogeneous memory system. In Proceedings - 51st Annual IEEE/ACM International Symposium on Microarchitecture, MICRO 2018 (Proceedings of the Annual International Symposium on Microarchitecture, MICRO). IEEE Comput...
-
[21]
Yongjun Lee, Jongwon Kim, Hakbeom Jang, Hyunggyun Yang, Jangwoo Kim, Jinkyu Jeong, and Jae W. Lee. 2015. A fully associative, tagless DRAM cache. In Proceedings of the 42nd Annual International Symposium on Computer Architecture (Portland, Oregon) (ISCA ’15). Association for Computing Machinery, New York, NY, USA, 211–222. doi:10.1145/2749469.2750383
-
[22]
Shengmei Li, Buqi Cheng, Xingyu Gao, Lin Qiao, and Zhizhong Tang. 2009. Performance Characterization of SPEC CPU2006 Benchmarks on Intel and AMD Platform. In 2009 First International Workshop on Education Technology and Computer Science, Vol. 2. 116–121. doi:10.1109/ETCS.2009.288
-
[23]
Haikun Liu, Yujie Chen, Xiaofei Liao, Hai Jin, Bingsheng He, Long Zheng, and Rentong Guo. 2017. Hardware/software cooperative caching for hybrid DRAM/NVM memory architectures. In Proceedings of the International Conference on Supercomputing (Chicago, Illinois) (ICS ’17). Association for Computing Machinery, New York, NY, USA, Article 26, 10 pages. doi:10....
-
[24]
Jihang Liu and Shimin Chen. 2019. Initial Experience with 3D XPoint Main Memory. In 2019 IEEE 35th International Conference on Data Engineering Workshops (ICDEW). 300–305. doi:10.1109/ICDEW.2019.00009
-
[25]
Loh and Mark D
Gabriel H. Loh and Mark D. Hill. 2011. Efficiently enabling conventional block sizes for very large die-stacked DRAM caches. In 2011 44th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). 454–464
2011
-
[26]
Meswani, Sergey Blagodurov, David Roberts, John Slice, Mike Ignatowski, and Gabriel H
Mitesh R. Meswani, Sergey Blagodurov, David Roberts, John Slice, Mike Ignatowski, and Gabriel H. Loh. 2015. Heterogeneous memory architectures: A HW/SW approach for mixing die-stacked and off-package memories. In 2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA). 126–136. doi:10.1109/ HPCA.2015.7056027
-
[27]
OpenAI. 2022. ChatGPT. https://chat.openai.com
2022
-
[28]
Moinuddin K. Qureshi and Gabe H. Loh. 2012. Fundamental Latency Trade-off in Architecting DRAM Caches: Outper- forming Impractical SRAM-Tags with a Simple and Practical Design. In 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture. 235–246. doi:10.1109/MICRO.2012.30
- [29]
-
[30]
Shihao Song, Anup Das, Onur Mutlu, and Nagarajan Kandasamy. 2020. Improving phase change memory performance with data content aware access. In Proceedings of the 2020 ACM SIGPLAN International Symposium on Memory Management (London, UK) (ISMM 2020). Association for Computing Machinery, New York, NY, USA, 30–47. doi:10. 1145/3381898.3397210
-
[31]
Arun Subramaniyan, Yufeng Gu, Timothy Dunn, Somnath Paul, Md Vasimuddin, Sanchit Misra, David Blaauw, Satish Narayanasamy, and Reetuparna Das. 2021. GenomicsBench: A Benchmark Suite for Genomics. In 2021 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 1–12. doi:10.1109/ISPASS51385. 2021.00012
-
[32]
Nittala Swapna Suhasini and Srilatha Puli. 2021. Big Data Analytics in Cloud Computing. In 2021 Sixth International Conference on Image Information Processing (ICIIP), Vol. 6. 320–325. doi:10.1109/ICIIP53038.2021.9702705
-
[33]
Evangelos Vasilakis, Vassilis Papaefstathiou, Pedro Trancoso, and Ioannis Sourdis. 2020. Hybrid2: Combining Caching and Migration in Hybrid Memory Systems. In 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). 649–662. doi:10.1109/HPCA47549.2020.00059
-
[34]
R Matthew Ward, Robert Schmieder, Gareth Highnam, and David Mittelman and. 2013. Big data challenges and opportunities in high-throughput sequencing. Systems Biomedicine 1, 1 (2013), 29–34. doi:10.4161/sysb.24470 arXiv:https://doi.org/10.4161/sysb.24470
-
[35]
Philip Wong, Simone Raoux, SangBum Kim, Jiale Liang, John P
H.-S. Philip Wong, Simone Raoux, SangBum Kim, Jiale Liang, John P. Reifenberg, Bipin Rajendran, Mehdi Asheghi, and Kenneth E. Goodson. 2010. Phase Change Memory.Proc. IEEE 98, 12 (2010), 2201–2227. doi:10.1109/JPROC.2010.2070050
-
[36]
Yinglong Xia, Ilie Gabriel Tanase, Lifeng Nai, Wei Tan, Yanbin Liu, Jason Crawford, and Ching-Yung Lin. 2014. Graph analytics and storage. In 2014 IEEE International Conference on Big Data (Big Data). 942–951. doi:10.1109/BigData. 2014.7004326
-
[37]
Vinson Young, Chiachen Chou, Aamer Jaleel, and Moinuddin Qureshi. 2018. ACCORD: Enabling Associativity for Gigascale DRAM Caches by Coordinating Way-Install and Way-Prediction. In 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA). 328–339. doi:10.1109/ISCA.2018.00036
-
[38]
Hughes, Nadathur Satish, Onur Mutlu, and Srinivas Devadas
Xiangyao Yu, Christopher J. Hughes, Nadathur Satish, Onur Mutlu, and Srinivas Devadas. 2017. Banshee: bandwidth-efficient DRAM caching via software/hardware cooperation. InProceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture (Cambridge, Massachusetts) (MICRO-50 ’17). Association for Comput- ing Machinery, New York, NY, USA,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.