Recognition: unknown
Tracing Relational Knowledge Recall in Large Language Models
Pith reviewed 2026-05-10 02:15 UTC · model grok-4.3
The pith
Per-head attention contributions to the residual stream are strong features for linear classification of relations recalled by large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We systematically evaluate different latent representations derived from attention head and MLP contributions, showing that per-head attention contributions to the residual stream are comparatively strong features for linear relation classification. Feature attribution analyses of the trained probes, as well as characteristics of the different relation types, reveal clear correlations between probe accuracy and relation specificity, entity connectedness, and how distributed the signal on which the probe relies is across attention heads. Finally, we show how token-level feature attribution of probe predictions can be used to reveal probe behavior in further detail.
What carries the argument
Per-head attention contributions to the residual stream as features for linear relation classification probes.
If this is right
- Linear probes using per-head attention features achieve higher accuracy in classifying recalled relations than those using MLP or combined representations.
- Probe performance increases with the specificity of the relation and the connectedness of subject and object entities.
- The relevant signal for relation classification is spread across multiple attention heads rather than localized.
- Token-level feature attribution can identify which specific tokens in the input most influence the probe's prediction of the relation.
Where Pith is reading between the lines
- This probing method might be used to detect when a model is about to recall incorrect relations during generation.
- Similar techniques could be applied to study recall of other knowledge types such as numerical or temporal facts.
- Insights from head contributions could inform methods to enhance factual recall by strengthening certain attention patterns.
Load-bearing premise
Linear probes on per-head attention representations faithfully capture the model's internal relational recall mechanism rather than dataset artifacts or probe-specific patterns.
What would settle it
Observing whether ablating the per-head attention contributions to the residual stream causes the model to fail at recalling correct relations in generated text, or if the probes fail to generalize to unseen relation types or different model architectures.
Figures




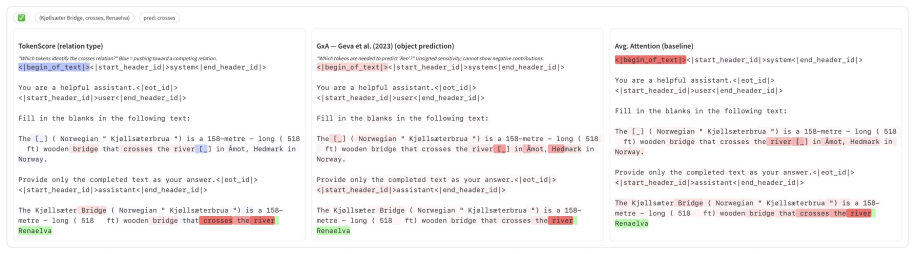
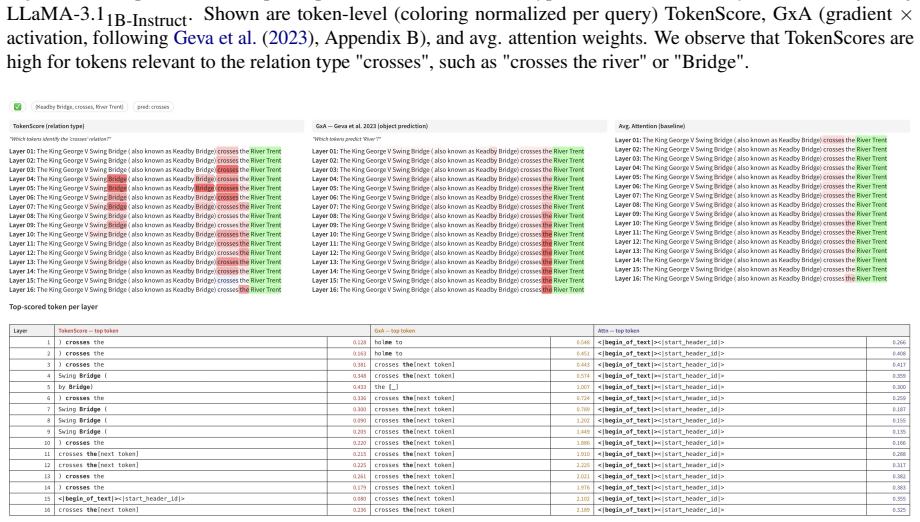





read the original abstract
We study how large language models recall relational knowledge during text generation, with a focus on identifying latent representations suitable for relation classification via linear probes. Prior work shows how attention heads and MLPs interact to resolve subject, predicate, and object, but it remains unclear which representations support faithful linear relation classification and why some relation types are easier to capture linearly than others. We systematically evaluate different latent representations derived from attention head and MLP contributions, showing that per-head attention contributions to the residual stream are comparatively strong features for linear relation classification. Feature attribution analyses of the trained probes, as well as characteristics of the different relation types, reveal clear correlations between probe accuracy and relation specificity, entity connectedness, and how distributed the signal on which the probe relies is across attention heads. Finally, we show how token-level feature attribution of probe predictions can be used to reveal probe behavior in further detail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies how LLMs recall relational knowledge during generation by evaluating latent representations from attention heads and MLPs for linear relation classification. It claims that per-head attention contributions to the residual stream are comparatively strong features for such probes, with feature attribution revealing correlations between probe accuracy and factors like relation specificity, entity connectedness, and signal distribution across heads. The work also applies token-level attribution to inspect probe predictions in detail.
Significance. If the central claim holds after addressing validation gaps, the work would advance mechanistic interpretability of LLMs by pinpointing which internal representations support relational recall and why some relations are more linearly accessible. The systematic comparison of representation types and the use of feature attribution to link accuracies to relation properties are positive elements that could guide future probing and editing techniques.
major comments (2)
- [Abstract and experimental evaluation] The central claim that per-head attention contributions to the residual stream are comparatively strong features for linear relation classification (Abstract) rests on the unverified assumption that probe accuracies reflect the model's internal recall process. Without controls for dataset artifacts—such as relation specificity and entity connectedness that the paper itself correlates with accuracy—the probes may exploit data properties rather than model-derived signals, rendering the feature attribution analyses non-diagnostic of causal usage.
- [Methods and experimental setup] The manuscript lacks sufficient detail on data splits, model variants, hyperparameter choices, and explicit controls against probe overfitting (e.g., cross-validation or adversarial baselines). This absence makes it impossible to verify that reported accuracies are not inflated by probe-specific patterns or distributed signals across heads, directly weakening support for the comparative strength of attention contributions.
minor comments (2)
- The abstract would benefit from explicitly naming the LLMs, relation datasets, and number of relations evaluated to improve immediate assessability of scope and generalizability.
- Notation for 'per-head attention contributions to the residual stream' should be defined more formally on first use, including how these are extracted from the forward pass.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important considerations for validating our probing results and ensuring methodological clarity. We address the major comments point by point below, providing clarifications and indicating planned revisions.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] The central claim that per-head attention contributions to the residual stream are comparatively strong features for linear relation classification (Abstract) rests on the unverified assumption that probe accuracies reflect the model's internal recall process. Without controls for dataset artifacts—such as relation specificity and entity connectedness that the paper itself correlates with accuracy—the probes may exploit data properties rather than model-derived signals, rendering the feature attribution analyses non-diagnostic of causal usage.
Authors: While we acknowledge that high probe accuracy does not by itself prove that the LLM internally uses these representations for relational recall, our analyses go beyond raw accuracy by employing feature attribution to identify the specific contributions from attention heads that the probes rely upon. The observed correlations with relation specificity, entity connectedness, and signal distribution are intended to explain variations in linear accessibility across relation types, which we view as a substantive finding rather than a confound. To further address concerns about dataset artifacts, we will incorporate additional controls such as adversarial baselines and stratified cross-validation in the revised manuscript to demonstrate that the probes capture model-derived signals. revision: partial
-
Referee: [Methods and experimental setup] The manuscript lacks sufficient detail on data splits, model variants, hyperparameter choices, and explicit controls against probe overfitting (e.g., cross-validation or adversarial baselines). This absence makes it impossible to verify that reported accuracies are not inflated by probe-specific patterns or distributed signals across heads, directly weakening support for the comparative strength of attention contributions.
Authors: We agree that the methods section would benefit from greater detail to facilitate reproducibility and verification. In the revised manuscript, we will expand the experimental setup to include: (1) precise descriptions of data splits, including how relations were divided into training and test sets while preserving relation types; (2) the full list of model variants evaluated; (3) hyperparameter settings for probe training, including regularization to prevent overfitting; and (4) results from cross-validation and adversarial baselines to confirm robustness against probe-specific patterns. These additions will strengthen the evidence for the comparative strength of per-head attention contributions. revision: yes
Circularity Check
Empirical probing study with no circular derivations or self-referential reductions
full rationale
The paper is an empirical investigation that trains linear probes on various LLM latent representations (attention head contributions to residual stream, MLP outputs) and measures classification accuracy on external relation datasets. Probe performance, feature attribution, and correlations with relation properties are reported as experimental outcomes. No equations, fitted parameters, or derivations are presented that reduce the reported accuracies or claims to the inputs by construction. The central claim follows directly from measured results on held-out data rather than tautological re-expression of fitted values or self-citation chains. The study is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes can extract causally relevant information from model activations about internal computations
Reference graph
Works this paper leans on
-
[1]
Guillaume Alain and Yoshua Bengio. 2017. https://openreview.net/forum?id=HJ4-rAVtl Understanding intermediate layers using linear classifier probes . In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Workshop Track, Toulon, France
2017
-
[2]
Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, and Tom Kwiatkowski. 2019. https://doi.org/10.18653/v1/P19-1279 Matching the blanks: Distributional similarity for relation learning . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2895--2905, Florence, Italy. Association for Computational Linguistics
- [3]
-
[4]
Xavier Suau Cuadros, Luca Zappella, and Nicholas Apostoloff. 2022. https://proceedings.mlr.press/v162/cuadros22a.html Self-conditioning pre-trained language models . In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 4455--4473. PMLR
2022
-
[5]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, and Angela Fan et al. 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models . Preprint, arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. 2022. https://arxiv.org/abs/2209.10652 Toy models of superposition . Preprint, arXiv:2209.10652
work page internal anchor Pith review arXiv 2022
-
[7]
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.751 Dissecting recall of factual associations in auto-regressive language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216--12235, Singapore. Association for Computational Linguistics
-
[8]
Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. 2018. https://doi.org/10.18653/v1/D18-1514 F ew R el: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4803--4809, Brussels, Be...
-
[9]
Roee Hendel, Mor Geva, and Amir Globerson. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.624 In-context learning creates task vectors . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9318--9333, Singapore. Association for Computational Linguistics
-
[10]
Evan Hernandez, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. 2024. https://openreview.net/forum?id=w7LU2s14kE Linearity of relation decoding in transformer language models . In The twelfth international conference on learning representations
2024
-
[11]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, and Rory sayres. 2018. https://proceedings.mlr.press/v80/kim18d.html Interpretability beyond feature attribution: Quantitative testing with concept activation vectors ( TCAV ) . In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Procee...
2018
-
[12]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA
2015
-
[13]
Xiaopeng Li, Shasha Li, Shezheng Song, Jing Yang, Jun Ma, and Jie Yu. 2024. https://doi.org/10.1609/aaai.v38i17.29818 PMET : Precise Model Editing in a Transformer . Proceedings of the AAAI Conference on Artificial Intelligence, 38(17):18564--18572
-
[14]
Yihong Liu, Runsheng Chen, Lea Hirlimann, Ahmad Dawar Hakimi, Mingyang Wang, Amir Hossein Kargaran, Sascha Rothe, Fran c ois Yvon, and Hinrich Schuetze. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.52 On relation-specific neurons in large language models . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, page...
-
[15]
Ang Lv, Yuhan Chen, Kaiyi Zhang, Yulong Wang, Lifeng Liu, Ji-Rong Wen, Jian Xie, and Rui Yan. 2024. https://doi.org/10.48550/arXiv.2403.19521 Interpreting Key Mechanisms of Factual Recall in Transformer - Based Language Models . arXiv preprint. ArXiv:2403.19521 [cs]
-
[16]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/6f1d43d5a82a37e89b0665b33bf3a182-Paper-Conference.pdf Locating and editing factual associations in gpt . In Advances in Neural Information Processing Systems, volume 35, pages 17359--17372. Curran Associates, Inc
2022
-
[17]
Victor Morand, Nadi Tomeh, Josiane Mothe, and Benjamin Piwowarski. 2025. https://doi.org/10.48550/arXiv.2510.19410 ToMMeR -- Efficient Entity Mention Detection from Large Language Models . arXiv preprint. ArXiv:2510.19410 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.19410 2025
-
[18]
James Murdoch, Peter J
W. James Murdoch, Peter J. Liu, and Bin Yu. 2018. https://openreview.net/forum?id=rkRwGg-0Z Beyond word importance: Contextual decomposition to extract interactions from LSTM s . In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018)
2018
-
[19]
Nicholas Popovic and Michael F \"a rber. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.988 Embedded named entity recognition using probing classifiers . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17830--17850, Miami, Florida, USA. Association for Computational Linguistics
-
[20]
Masaki Sakata, Benjamin Heinzerling, Sho Yokoi, Takumi Ito, and Kentaro Inui. 2025. https://doi.org/10.18653/v1/2025.findings-acl.858 On entity identification in language models . In Findings of the Association for Computational Linguistics: ACL 2025, pages 16717--16741, Vienna, Austria. Association for Computational Linguistics
-
[21]
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. https://proceedings.mlr.press/v70/sundararajan17a.html Axiomatic attribution for deep networks . In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 3319--3328. PMLR
2017
-
[22]
Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron C Wallace, and David Bau. 2024. https://openreview.net/forum?id=AwyxtyMwaG Function vectors in large language models . In The Twelfth International Conference on Learning Representations
2024
-
[23]
Yiqun Wang, Chaoqun Wan, Sile Hu, Yonggang Zhang, Xiang Tian, Yaowu Chen, Xu Shen, and Jieping Ye. 2025. https://doi.org/10.18653/v1/2025.acl-long.1133 Tracing and dissecting how LLM s recall factual knowledge for real world questions . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
-
[24]
Zijian Wang, Britney Whyte, and Chang Xu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.287 Locating and extracting relational concepts in large language models . In Findings of the Association for Computational Linguistics: ACL 2024, pages 4818--4832, Bangkok, Thailand. Association for Computational Linguistics
-
[25]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Zeping Yu and Sophia Ananiadou. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.191 Neuron-level knowledge attribution in large language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3267--3280, Miami, Florida, USA. Association for Computational Linguistics
-
[27]
Zeping Yu, Yonatan Belinkov, and Sophia Ananiadou. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.567 Back attention: Understanding and enhancing multi-hop reasoning in large language models . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 11268--11283, Suzhou, China. Association for Computational Linguistics
-
[28]
Zifan Zheng, Yezhaohui Wang, Yuxin Huang, Shichao Song, Mingchuan Yang, Bo Tang, Feiyu Xiong, and Zhiyu Li. 2025. https://doi.org/10.1016/j.patter.2025.101176 Attention heads of large language models . Patterns, 6(2):101176
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.