Recognition: unknown
Whose Story Gets Told? Positionality and Bias in LLM Summaries of Life Narratives
Pith reviewed 2026-05-10 00:56 UTC · model grok-4.3
The pith
A summarization pipeline detects race and gender biases in how LLMs interpret personal life stories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
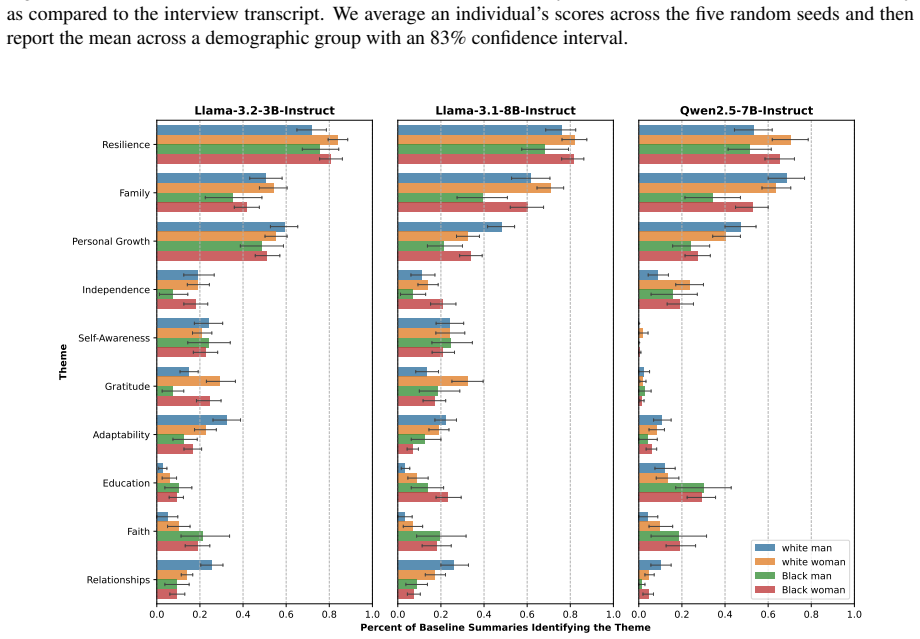
We collaborate with psychologists to study the abstractive claims LLMs make about human life stories, asking how using an LLM as an interpreter of meaning affects the conclusions and perspectives of a study. We propose a summarization-based pipeline for surfacing biases in perspective-taking an LLM might employ in interpreting these life stories. We demonstrate that our pipeline can identify both race and gender bias with the potential for representational harm. Finally, we encourage the use of this analysis in future studies involving LLM-based interpretation of study participants' written text or transcribed speech to characterize a positionality portrait for the study.
What carries the argument
A summarization-based pipeline that compares LLM-generated summaries of life narratives across demographic groups to surface differences in perspective-taking.
If this is right
- Studies that use LLMs for inductive thematic analysis or abstractive coding of narratives can apply the pipeline to produce an explicit positionality portrait of the model.
- Biases surfaced by the method may alter which elements of participants' life stories are retained or emphasized, creating representational harm for certain demographic groups.
- The pipeline offers a concrete way to compare multiple LLMs or prompt variants before deploying them on sensitive personal data.
- Repeated use across projects could accumulate evidence on which model families exhibit stronger or weaker demographic skews in narrative interpretation.
Where Pith is reading between the lines
- The approach could be extended to test for biases tied to other identity dimensions such as age, class, or national origin that were not examined here.
- If the pipeline flags consistent biases, it would motivate targeted fine-tuning or retrieval-augmented methods that ground summaries more closely in the original narrative text.
- Social-science teams might begin treating LLM positionality audits as a standard pre-analysis step alongside traditional checks for inter-coder reliability.
Load-bearing premise
Observed differences in LLM summaries reflect the model's internal positionality biases rather than artifacts of prompt design, data selection, or summarization mechanics.
What would settle it
Applying the pipeline to the same set of life narratives after systematically removing or swapping all race and gender descriptors from the input, and finding that summary differences disappear, would indicate the detected biases arise from input artifacts rather than model positionality.
Figures











read the original abstract
Increasingly, studies are exploring using Large Language Models (LLMs) for accelerated or scaled qualitative analysis of text data. While we can compare LLM accuracy against human labels directly for deductive coding, or labeling text, it is more challenging to judge the ethics and effectiveness of using LLMs in abstractive methods such as inductive thematic analysis. We collaborate with psychologists to study the abstractive claims LLMs make about human life stories, asking, how does using an LLM as an interpreter of meaning affect the conclusions and perspectives of a study? We propose a summarization-based pipeline for surfacing biases in perspective-taking an LLM might employ in interpreting these life stories. We demonstrate that our pipeline can identify both race and gender bias with the potential for representational harm. Finally, we encourage the use of this analysis in future studies involving LLM-based interpretation of study participants' written text or transcribed speech to characterize a positionality portrait for the study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a summarization-based pipeline for detecting positionality biases (specifically race and gender) in how LLMs interpret and summarize human life narratives. It claims this pipeline can identify biases with potential for representational harm and recommends its use to generate 'positionality portraits' for studies employing LLMs in qualitative analysis of participant text or speech.
Significance. If the pipeline can be shown to isolate LLM-internal biases from prompt artifacts and summarization mechanics, the work would offer a practical diagnostic for ethical LLM use in inductive qualitative methods, where direct accuracy checks against humans are difficult. The collaboration with psychologists and focus on abstractive claims are positive elements, but the absence of verifiable methods, data, or controls limits the current contribution.
major comments (2)
- [Abstract] Abstract and pipeline description: the central claim that the pipeline 'can identify both race and gender bias with the potential for representational harm' is load-bearing yet unsupported by any reported methods, dataset details, prompt templates, bias metrics, or ablation studies. Without controls for prompt phrasing, data selection, or abstractive summarization mechanics, observed summary differences cannot be confidently attributed to model positionality rather than experimental setup.
- [Pipeline description (inferred from abstract)] The weakest assumption—that summary disparities reflect the LLM's internal positionality—is not tested via the required ablations (e.g., neutral vs. loaded prompts, multiple templates, or human baseline comparisons). This directly undermines the demonstration of representational harm and the recommendation for future use in positionality characterization.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies important areas for strengthening the presentation of our methods and controls. We address each major comment below and will revise the manuscript to provide the requested details, ablations, and clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract and pipeline description: the central claim that the pipeline 'can identify both race and gender bias with the potential for representational harm' is load-bearing yet unsupported by any reported methods, dataset details, prompt templates, bias metrics, or ablation studies. Without controls for prompt phrasing, data selection, or abstractive summarization mechanics, observed summary differences cannot be confidently attributed to model positionality rather than experimental setup.
Authors: We agree that the abstract is high-level and does not report these specifics. The full manuscript provides an overview of the pipeline and demonstrates bias detection through summary disparities, but we acknowledge that verifiable details on the dataset (public life narratives), exact prompt templates, quantitative bias metrics, and ablations are not sufficiently explicit. In revision, we will expand the methods section with full dataset descriptions, all prompt templates (including variations), the bias metrics and statistical analyses used, and explicit controls for prompt phrasing and data selection to demonstrate that differences are not due to experimental artifacts. revision: yes
-
Referee: [Pipeline description (inferred from abstract)] The weakest assumption—that summary disparities reflect the LLM's internal positionality—is not tested via the required ablations (e.g., neutral vs. loaded prompts, multiple templates, or human baseline comparisons). This directly undermines the demonstration of representational harm and the recommendation for future use in positionality characterization.
Authors: We agree that isolating internal positionality requires targeted ablations beyond what is currently shown. The manuscript includes cross-model comparisons to indicate consistent patterns, but we will add the requested experiments in revision: neutral prompt variants, multiple template phrasings, and human-generated summary baselines for direct comparison. These will quantify how much of the observed race and gender disparities persist independently of prompt or summarization mechanics, thereby supporting the claim of potential representational harm and the pipeline's utility for positionality characterization in future work. revision: yes
Circularity Check
No significant circularity in proposed diagnostic pipeline
full rationale
The paper proposes a summarization-based pipeline for surfacing positionality biases in LLM interpretations of life narratives and demonstrates its application to detect race and gender differences. No equations, fitted parameters, or derivation steps are present that reduce by construction to the paper's own inputs. The central claim is an empirical demonstration of the pipeline's utility rather than a mathematical or self-referential reduction, and the work is self-contained without load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can perform abstractive summarization of life narratives in a manner that reveals interpretable positionality
Reference graph
Works this paper leans on
-
[1]
CoRR , volume =
Joshua Goodman , title =. CoRR , volume =. 2001 , url =
2001
-
[2]
Social cognition , pages=
A model of (often mixed) stereotype content: Competence and warmth respectively follow from perceived status and competition , author=. Social cognition , pages=. 2018 , publisher=
2018
-
[3]
Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments , author=. Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
-
[4]
2008 , publisher=
The life story interview , author=. 2008 , publisher=
2008
-
[5]
doi: 10.18653/v1/2023.acl-long.84
Cheng, Myra and Durmus, Esin and Jurafsky, Dan. Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.84
-
[6]
Gurung, Alexander and Lapata, Mirella , month = jun, year =
-
[7]
Automatically
Louis, Annie and Nenkova, Ani , editor =. Automatically. Proceedings of the 2009. 2009 , pages =
2009
-
[8]
Evaluating
Nenkova, Ani and Passonneau, Rebecca , month = may, year =. Evaluating. Proceedings of the
-
[9]
Yin, Fangcong and Ye, Xi and Durrett, Greg , month = jun, year =
-
[10]
Karpinska, Marzena and Thai, Katherine and Lo, Kyle and Goyal, Tanya and Iyyer, Mohit , month = jun, year =. One
-
[11]
Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, and Dragomir Radev
Transactions of the Association for Computational Linguistics , author =. 2021 , pages =. doi:10.1162/tacl_a_00373 , abstract =
-
[12]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , month = may, year =. G-
-
[13]
Huang, Dandan and Cui, Leyang and Yang, Sen and Bao, Guangsheng and Wang, Kun and Xie, Jun and Zhang, Yue , month = oct, year =. What. doi:10.48550/arXiv.2010.04529 , abstract =
-
[14]
Prometheus 2:
Kim, Seungone and Suk, Juyoung and Longpre, Shayne and Lin, Bill Yuchen and Shin, Jamin and Welleck, Sean and Neubig, Graham and Lee, Moontae and Lee, Kyungjae and Seo, Minjoon , month = may, year =. Prometheus 2:
-
[15]
and Xiong, Caiming and Wu, Chien-Sheng , month = jul, year =
Laban, Philippe and Fabbri, Alexander R. and Xiong, Caiming and Wu, Chien-Sheng , month = jul, year =. Summary of a
-
[17]
Learning to
Wadhwa, Manya and Zhao, Xinyu and Li, Junyi Jessy and Durrett, Greg , month = jul, year =. Learning to
-
[18]
Lake, Thom and Choi, Eunsol and Durrett, Greg , month = jun, year =. From
-
[19]
Molecular
Gunjal, Anisha and Durrett, Greg , month = jun, year =. Molecular
-
[20]
Hosking, Tom and Blunsom, Phil and Bartolo, Max , year =
-
[21]
Siledar, Tejpalsingh and Nath, Swaroop and Muddu, Sankara Sri Raghava Ravindra and Rangaraju, Rupasai and Nath, Swaprava and Bhattacharyya, Pushpak and Banerjee, Suman and Patil, Amey and Singh, Sudhanshu Shekhar and Chelliah, Muthusamy and Garera, Nikesh , month = jun, year =. One
-
[22]
Zhao, Wenting and Goyal, Tanya and Chiu, Yu Ying and Jiang, Liwei and Newman, Benjamin and Ravichander, Abhilasha and Chandu, Khyathi and Bras, Ronan Le and Cardie, Claire and Deng, Yuntian and Choi, Yejin , month = jul, year =
-
[23]
When the
Fleisig, Eve and Abebe, Rediet and Klein, Dan , month = mar, year =. When the
-
[24]
and Laban, Philippe and Xu, Jiacheng and Yavuz, Semih and Kryściński, Wojciech and Rousseau, Justin F
Tang, Liyan and Goyal, Tanya and Fabbri, Alexander R. and Laban, Philippe and Xu, Jiacheng and Yavuz, Semih and Kryściński, Wojciech and Rousseau, Justin F. and Durrett, Greg , month = may, year =. Understanding
-
[25]
An, Chenxin and Gong, Shansan and Zhong, Ming and Zhao, Xingjian and Li, Mukai and Zhang, Jun and Kong, Lingpeng and Qiu, Xipeng , month = oct, year =. L-
-
[26]
Tang, Liyan and Laban, Philippe and Durrett, Greg , month = apr, year =
-
[27]
Computer Methods and Programs in Biomedicine , volume=
Inductive thematic analysis of healthcare qualitative interviews using open-source large language models: How does it compare to traditional methods? , author=. Computer Methods and Programs in Biomedicine , volume=. 2024 , publisher=
2024
-
[28]
Dai, Shih-Chieh and Xiong, Aiping and Ku, Lun-Wei , month = oct, year =
-
[29]
Automating
Khan, Awais Hameed and Kegalle, Hiruni and D'Silva, Rhea and Watt, Ned and Whelan-Shamy, Daniel and Ghahremanlou, Lida and Magee, Liam , month = may, year =. Automating
-
[30]
Social Science Computer Review , author =
Performing an. Social Science Computer Review , author =. 2024 , note =. doi:10.1177/08944393231220483 , abstract =
-
[31]
Eschrich, James and Sterman, Sarah , month = jul, year =. A
-
[32]
1991 , publisher=
Whose Science? Whose Knowledge?: Thinking from Women’s Lives , author=. 1991 , publisher=
1991
-
[33]
British Journal of Occupational Therapy , volume=
Reflexivity: an essential component for all research? , author=. British Journal of Occupational Therapy , volume=. 1998 , publisher=
1998
-
[34]
, author=
Introduction: Ethics, Reflexivity and Voice. , author=. Qualitative sociology , volume=
-
[35]
ethically important moments
Ethics, reflexivity, and “ethically important moments” in research , author=. Qualitative inquiry , volume=. 2004 , publisher=
2004
-
[36]
International Journal of Qualitative Methods , volume=
Social identity map: A reflexivity tool for practicing explicit positionality in critical qualitative research , author=. International Journal of Qualitative Methods , volume=. 2019 , publisher=
2019
-
[37]
Perspectives on Psychological Science , volume=
The pandemic as a portal: Reimagining psychological science as truly open and inclusive , author=. Perspectives on Psychological Science , volume=. 2022 , publisher=
2022
-
[38]
and Lustick, Hilary and Meyer, Melanie S
Steltenpohl, Crystal N. and Lustick, Hilary and Meyer, Melanie S. and Lee, Lindsay Ellis and Stegenga, Sondra M. and Reyes, Laurel Standiford and Renbarger, Rachel L. , journal =. Rethinking. 2023 , month =
2023
-
[39]
International Conference on Machine Learning , pages=
Whose opinions do language models reflect? , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[40]
Action in Teacher Education , volume=
Plain talk: Recognizing positivism and constructivism in practice , author=. Action in Teacher Education , volume=. 1992 , publisher=
1992
-
[41]
, author=
How novelists use generative language models: An exploratory user study. , author=. HAI-GEN+ user2agent@ IUI , year=
-
[42]
Exploring
Bano, Muneera and Zowghi, Didar and Whittle, Jon , year =. Exploring
-
[43]
Critical Perspectives on Accounting , author =
Artificial intelligence and qualitative research:. Critical Perspectives on Accounting , author =. 2024 , keywords =. doi:10.1016/j.cpa.2024.102722 , abstract =
-
[44]
Chew, Robert and Bollenbacher, John and Wenger, Michael and Speer, Jessica and Kim, Annice , month = jun, year =
-
[45]
Handbook of methodological approaches to community-based research: Qualitative, quantitative, and mixed methods , pages=
Thematic analysis , author=. Handbook of methodological approaches to community-based research: Qualitative, quantitative, and mixed methods , pages=. 2016 , publisher=
2016
-
[46]
arXiv preprint arXiv:2310.15100 , year=
LLM-in-the-loop: Leveraging large language model for thematic analysis , author=. arXiv preprint arXiv:2310.15100 , year=
-
[47]
arXiv preprint arXiv:2407.11198 , year=
A Framework For Discussing LLMs as Tools for Qualitative Analysis , author=. arXiv preprint arXiv:2407.11198 , year=
-
[48]
Social Science Computer Review , volume=
Performing an inductive thematic analysis of semi-structured interviews with a large language model: an exploration and provocation on the limits of the approach , author=. Social Science Computer Review , volume=. 2024 , publisher=
2024
-
[49]
2008 , publisher=
The science of stories: An introduction to narrative psychology , author=. 2008 , publisher=
2008
-
[50]
Quality & Quantity , pages=
Reflections on inductive thematic saturation as a potential metric for measuring the validity of an inductive thematic analysis with LLMs , author=. Quality & Quantity , pages=. 2024 , publisher=
2024
-
[51]
Companion proceedings of the 28th international conference on intelligent user interfaces , pages=
Supporting qualitative analysis with large language models: Combining codebook with GPT-3 for deductive coding , author=. Companion proceedings of the 28th international conference on intelligent user interfaces , pages=
-
[52]
Robert H. Tai and Lillian R. Bentley and Xin Xia and Jason M. Sitt and Sarah C. Fankhauser and Ana M. Chicas-Mosier and Barnas G. Monteith , title =. International Journal of Qualitative Methods , volume =. 2024 , doi =. https://doi.org/10.1177/16094069241231168 , abstract =
-
[53]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[54]
Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
A web-based collaborative annotation and consolidation tool , author=. Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
-
[55]
Standardizing the Measurement of Text Diversity: A Tool and a Comparative Analysis of Scores , author=. arXiv preprint arXiv:2403.00553 , year=
-
[56]
Tang, Liyan and Laban, Philippe and Durrett, Greg , journal=
-
[57]
Towards a Unified Multi-Dimensional Evaluator for Text Generation
Zhong, Ming and Liu, Yang and Yin, Da and Mao, Yuning and Jiao, Yizhu and Liu, Pengfei and Zhu, Chenguang and Ji, Heng and Han, Jiawei. Towards a Unified Multi-Dimensional Evaluator for Text Generation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.131
-
[58]
AlignScore : Evaluating factual consistency with a unified alignment function
Zha, Yuheng and Yang, Yichi and Li, Ruichen and Hu, Zhiting. A lign S core: Evaluating Factual Consistency with A Unified Alignment Function. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.634
-
[59]
Fables: Evaluating faithfulness and content selection in book-length summarization,
FABLES: Evaluating faithfulness and content selection in book-length summarization , author=. arXiv preprint arXiv:2404.01261 , year=
-
[60]
arXiv preprint arXiv:2309.09558 , year=
Summarization is (almost) dead , author=. arXiv preprint arXiv:2309.09558 , year=
-
[61]
Benchmarking Generation and Evaluation Capabilities of Large Language Models for Instruction Controllable Summarization
Liu, Yixin and Fabbri, Alexander and Chen, Jiawen and Zhao, Yilun and Han, Simeng and Joty, Shafiq and Liu, Pengfei and Radev, Dragomir and Wu, Chien-Sheng and Cohan, Arman. Benchmarking Generation and Evaluation Capabilities of Large Language Models for Instruction Controllable Summarization. Findings of the Association for Computational Linguistics: NAA...
2024
-
[62]
Israt Jahan and Md Tahmid Rahman Laskar and Chun Peng and Jimmy Xiangji Huang , keywords =. A comprehensive evaluation of large Language models on benchmark biomedical text processing tasks , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.compbiomed.2024.108189 , url =
-
[63]
2021 , eprint=
SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization , author=. 2021 , eprint=
2021
-
[64]
Goyal, Tanya and Li, Junyi Jessy and Durrett, Greg , journal=
-
[65]
FALTE : A Toolkit for Fine-grained Annotation for Long Text Evaluation
Goyal, Tanya and Li, Junyi Jessy and Durrett, Greg. FALTE : A Toolkit for Fine-grained Annotation for Long Text Evaluation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2022. doi:10.18653/v1/2022.emnlp-demos.35
-
[66]
Frontiers in Artificial Intelligence , volume=
Zero-shot stance detection: Paradigms and challenges , author=. Frontiers in Artificial Intelligence , volume=. 2023 , publisher=
2023
-
[67]
Columbia University COMS W3998: UNDERGRADUATE PROJECTS IN COMPUTER SCIENCE , year=
DATASET: IDENTITY SIGNALING IN ONLINE DEBATES , author=. Columbia University COMS W3998: UNDERGRADUATE PROJECTS IN COMPUTER SCIENCE , year=
-
[68]
L-eval: Instituting standardized evaluation for long context language models , author=. arXiv preprint arXiv:2307.11088 , year=
-
[69]
One Thousand and One Pairs: A" novel" challenge for long-context language models , author=. arXiv preprint arXiv:2406.16264 , year=
-
[70]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
STORYSUMM: Evaluating Faithfulness in Story Summarization , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
2024
-
[71]
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs , author=. arXiv preprint arXiv:1903.00161 , year=
work page Pith review arXiv 1903
-
[72]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
PALS: Personalized Active Learning for Subjective Tasks in NLP , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[73]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[74]
Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors
Tang, Liyan and Goyal, Tanya and Fabbri, Alex and Laban, Philippe and Xu, Jiacheng and Yavuz, Semih and Kryscinski, Wojciech and Rousseau, Justin and Durrett, Greg. Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1...
-
[75]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Mug: A general meeting understanding and generation benchmark , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[77]
Advances in neural information processing systems , volume=
Teaching machines to read and comprehend , author=. Advances in neural information processing systems , volume=
-
[78]
2022 , publisher=
The Black side of the river: Race, language, and belonging in Washington, DC , author=. 2022 , publisher=
2022
-
[79]
Chakrabarty, Tuhin and Laban, Philippe and Agarwal, Divyansh and Muresan, Smaranda and Wu, Chien-Sheng , booktitle=
-
[80]
Huang, Chieh-Yang and Gautam, Sanjana and Brooks, Shannon McClellan and Lin, Ya-Fang and Huang, Ting-Hao `Kenneth' , journal=
-
[81]
arXiv preprint arXiv:2309.12570 , year=
Creativity support in the age of large language models: An empirical study involving emerging writers , author=. arXiv preprint arXiv:2309.12570 , year=
-
[82]
Yeh, Catherine and Ramos, Gonzalo and Ng, Rachel and Huntington, Andy and Banks, Richard , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.