Recognition: unknown
Synthetic Flight Data Generation Using Generative Models
Pith reviewed 2026-05-10 00:39 UTC · model grok-4.3
The pith
Generative models produce synthetic flight data that trains delay prediction models to accuracy levels comparable to real records.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tabular Variational Autoencoder and Gaussian Copula models are adapted to generate synthetic flight information. Gaussian Copula achieves higher statistical similarity and fidelity but incurs higher computational cost, while Tabular Variational Autoencoder scales efficiently to large datasets. Both produce data that supports flight delay prediction models with accuracy comparable to models trained on real data, as confirmed through the four-stage assessment.
What carries the argument
The four-stage evaluation framework that quantifies statistical similarity, fidelity, diversity, and predictive utility of synthetic flight data generated by Tabular Variational Autoencoder and Gaussian Copula.
If this is right
- Synthetic data can replace or supplement confidential real flight records in model development.
- Rare events such as delays can be augmented in training sets without violating data restrictions.
- Tabular Variational Autoencoder enables practical generation at scales where Gaussian Copula becomes impractical.
- Prediction systems for critical aviation events can be trained and validated without direct access to full real datasets.
Where Pith is reading between the lines
- The same generation process could be applied to other sparse outcomes like cancellations or diversions.
- Public release of synthetic flight datasets might accelerate collaborative research while preserving confidentiality.
- Further tests on datasets with even lower frequencies of rare events would clarify the limits of the current evaluation.
Load-bearing premise
That matching statistical similarity, fidelity, diversity, and predictive utility in synthetic data guarantees reliable performance when predicting rare aviation events on real data.
What would settle it
A controlled test in which a flight delay classifier trained solely on synthetic data shows substantially lower accuracy on a held-out set of real flight records than an identical classifier trained on real data.
Figures






read the original abstract
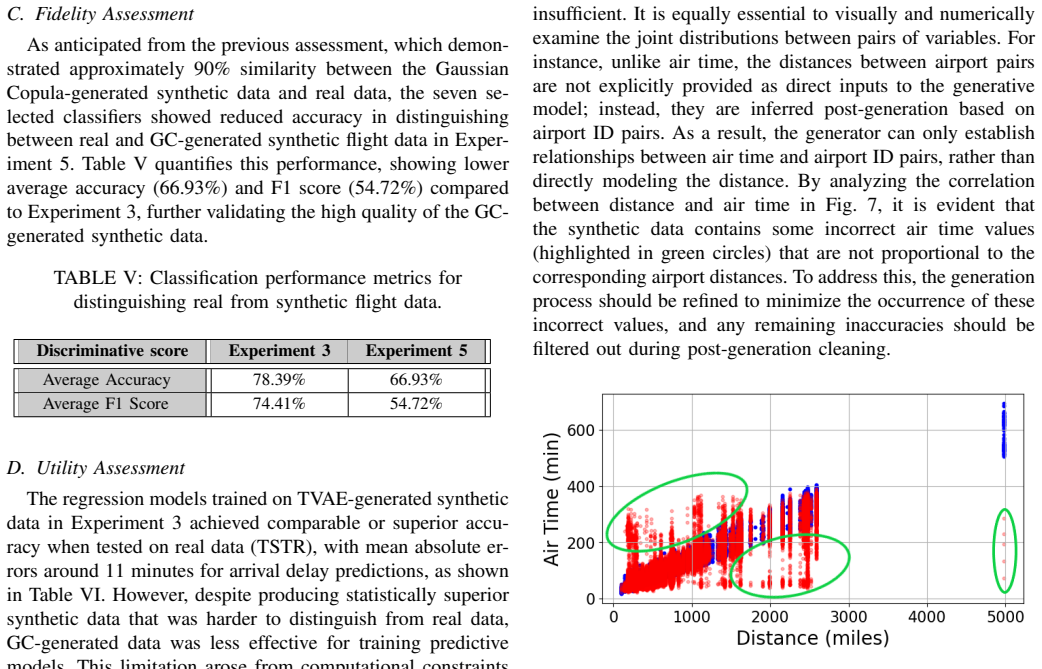
The increasing adoption of synthetic data in aviation research offers a promising solution to data scarcity and confidentiality challenges. This study investigates the potential of generative models to produce realistic synthetic flight data and evaluates their quality through a comprehensive four-stage assessment framework. The need for synthetic flight data arises from their potential to serve as an alternative to confidential real-world records and to augment rare events in historical datasets. These enhanced datasets can then be used to train machine learning models that predict critical events, such as flight delays, cancellations, diversions, and turnaround times. Two generative models, Tabular Variational Autoencoder (TVAE) and Gaussian Copula (GC), are adapted to generate synthetic flight information and compared based on their ability to preserve statistical similarity, fidelity, diversity, and predictive utility. Results indicate that while GC achieves higher statistical similarity and fidelity, its computational cost hinders its applicability to large datasets. In contrast, TVAE efficiently handles large datasets and enables scalable synthetic data generation. The findings demonstrate that synthetic data can support flight delay prediction models with accuracy comparable to those trained on real data. These results pave the way for leveraging synthetic flight data to enhance predictive modeling in air transportation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the use of generative models, TVAE and Gaussian Copula, to create synthetic flight data for addressing data scarcity and confidentiality in aviation research. It proposes a four-stage evaluation framework covering statistical similarity, fidelity, diversity, and predictive utility. The key finding is that synthetic data can train flight delay prediction models with accuracy comparable to real data, with TVAE offering better scalability than GC for large datasets.
Significance. This work could have practical significance in enabling machine learning applications in air transportation by mitigating privacy concerns and allowing augmentation of rare events. The explicit comparison of two generative approaches and their trade-offs in quality versus efficiency provides useful guidance. However, the absence of detailed quantitative results in the provided abstract limits the immediate impact assessment.
major comments (2)
- [Abstract] The assertion that 'synthetic data can support flight delay prediction models with accuracy comparable to those trained on real data' lacks any supporting quantitative metrics, error bars, specific accuracy values, baseline comparisons, or information on data splits and handling of rare events. This omission is critical as it prevents evaluation of whether the predictive utility stage truly validates the central claim or if issues like overfitting are present.
- [Four-stage evaluation framework] While the framework includes predictive utility, it is unclear if it tests the preservation of conditional distributions P(delay | covariates) rather than just overall accuracy. Statistical similarity and fidelity metrics (marginals, pairwise) do not guarantee that higher-order dependencies relevant to rare delay events are maintained, which could cause the downstream models to underperform on real data despite passing the four stages.
minor comments (2)
- [Abstract] The computational cost comparison for GC is stated qualitatively ('hinders its applicability') without numerical benchmarks such as runtime or memory usage on the dataset size.
- Ensure that all acronyms (TVAE, GC) are defined at first use and that the data source and preprocessing pipeline are described in sufficient detail for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of clarity and evaluation rigor that we have addressed through targeted revisions.
read point-by-point responses
-
Referee: [Abstract] The assertion that 'synthetic data can support flight delay prediction models with accuracy comparable to those trained on real data' lacks any supporting quantitative metrics, error bars, specific accuracy values, baseline comparisons, or information on data splits and handling of rare events. This omission is critical as it prevents evaluation of whether the predictive utility stage truly validates the central claim or if issues like overfitting are present.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports these details in the predictive utility experiments (including accuracy comparisons between real and synthetic training data, data split procedures, and handling of the dataset). To address the concern directly, we have revised the abstract to incorporate specific accuracy values, baseline comparisons, and a brief note on the evaluation protocol. revision: yes
-
Referee: [Four-stage evaluation framework] While the framework includes predictive utility, it is unclear if it tests the preservation of conditional distributions P(delay | covariates) rather than just overall accuracy. Statistical similarity and fidelity metrics (marginals, pairwise) do not guarantee that higher-order dependencies relevant to rare delay events are maintained, which could cause the downstream models to underperform on real data despite passing the four stages.
Authors: The predictive utility stage trains delay prediction models exclusively on synthetic data and evaluates them on real held-out data. This cross-evaluation directly measures whether the synthetic data preserves the dependencies required for accurate downstream prediction, including those involving delay events. We acknowledge that marginal and pairwise metrics alone do not fully capture higher-order conditionals; the predictive utility step serves as the primary safeguard against this. In the revision we have added an explicit discussion of this limitation together with supplementary conditional distribution checks for rare delay events to further substantiate the framework. revision: partial
Circularity Check
No circularity detected in empirical generative modeling study
full rationale
The paper conducts an empirical comparison of TVAE and Gaussian Copula models for synthetic flight data generation. It applies a four-stage evaluation (statistical similarity, fidelity, diversity, predictive utility) by training delay predictors on synthetic vs. real data and measuring accuracy on held-out real data. No derivation chain, fitted parameters renamed as predictions, self-definitional metrics, or load-bearing self-citations appear in the described methodology or results. The central claim rests on direct experimental outcomes against external real data benchmarks rather than reducing to its own inputs by construction. This is a standard, non-circular empirical ML evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Survey on synthetic data generation, evaluation methods and gans,
A. Figueira and B. Vaz, “Survey on synthetic data generation, evaluation methods and gans,”Mathematics, vol. 10, no. 15, 2022. [Online]. Available: https://www.mdpi.com/2227-7390/10/15/2733
2022
-
[2]
The synthetic data vault,
N. Patki, R. Wedge, and K. Veeramachaneni, “The synthetic data vault,” in2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), 2016, pp. 399–410
2016
-
[3]
Modeling tabular data using conditional gan,
L. Xu, M. Skoularidou, A. Cuesta-Infante, and K. Veeramachaneni, “Modeling tabular data using conditional gan,” inAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch ´e-Buc, E. Fox, and R. Garnett, Eds., vol. 32. Curran Associates, Inc., 2019. [Online]. Available: https://proceedings.neurips.cc/paper fil...
2019
-
[4]
Smote: synthetic minority over-sampling technique,
N. V . Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: synthetic minority over-sampling technique,”Journal of artificial intel- ligence research, vol. 16, pp. 321–357, 2002
2002
-
[5]
Adasyn: Adaptive synthetic sampling approach for imbalanced learning,
H. He, Y . Bai, E. A. Garcia, and S. Li, “Adasyn: Adaptive synthetic sampling approach for imbalanced learning,” in2008 IEEE interna- tional joint conference on neural networks (IEEE world congress on computational intelligence). Ieee, 2008, pp. 1322–1328
2008
-
[6]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in International Conference on Learning Representations (ICLR), 2013. [Online]. Available: https://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[7]
Generative adversarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” inAdvances in Neural Information Processing Systems, vol. 27. Curran Associates, Inc., June 2014. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
2014
-
[8]
arXiv preprint arXiv:1806.03384 (2018)
N. Park, M. Mohammadi, K. Gorde, S. Jajodia, H. Park, and Y . Kim, “Data synthesis based on generative adversarial networks,”arXiv preprint arXiv:1806.03384, 2018
-
[9]
Synthesizing Tabular Data using Generative Adversarial Networks
L. Xu and K. Veeramachaneni, “Synthesizing tabular data using gener- ative adversarial networks,”arXiv preprint arXiv:1811.11264, 2018
work page Pith review arXiv 2018
-
[10]
Gen- erating multi-label discrete patient records using generative adversarial networks,
E. Choi, S. Biswal, B. Malin, J. Duke, W. F. Stewart, and J. Sun, “Gen- erating multi-label discrete patient records using generative adversarial networks,” inMachine learning for healthcare conference. PMLR, 2017, pp. 286–305
2017
-
[11]
Veegan: Reducing mode collapse in gans using implicit variational learning,
A. Srivastava, L. Valkov, C. Russell, M. U. Gutmann, and C. Sutton, “Veegan: Reducing mode collapse in gans using implicit variational learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[12]
Deep-learning-aided packet routing in aeronautical ad hoc networks relying on real flight data: From single-objective to near-pareto multiobjective optimization,
D. Liu, J. Zhang, J. Cui, S. X. Ng, R. G. Maunder, and L. H. Hanzo, “Deep-learning-aided packet routing in aeronautical ad hoc networks relying on real flight data: From single-objective to near-pareto multiobjective optimization,”IEEE Internet of Things Journal, vol. 9, pp. 4598–4614, 2021. [Online]. Available: https: //api.semanticscholar.org/CorpusID:238673995
2021
-
[13]
An exploratory assessment of llm’s potential toward flight trajectory reconstruction analysis,
Q. Zhang and J. H. Mott, “An exploratory assessment of llm’s potential toward flight trajectory reconstruction analysis,”ArXiv, vol. abs/2401.06204, 2024. [Online]. Available: https://api.semanticscholar. org/CorpusID:266977542
-
[14]
S. Wijnands, A. Sharpanskykh, and K. Aly, “Generation of synthetic aircraft landing trajectories using generative adversarial networks,” 2024. [Online]. Available: https://zenodo.org/doi/10.5281/zenodo.14774664
-
[15]
Transtats database for airline on-time performance,
B. of Transportation Statistics, “Transtats database for airline on-time performance,” 2023, accessed: 2025-01-23. [Online]. Available: https: //transtats.bts.gov/Tables.asp?QO VQ=EFD&QO anzr=Nv4yv0r% FDb0-gvzr%FDcr4s14zn0pr%FDQn6n&QO fu146 anzr=b0-gvzr
2023
-
[16]
Department of Transportation
U.S. Department of Transportation. Bureau of transportation statistics. [Online]. Available: https://www.bts.gov/
-
[17]
Towards autonomous cybersecurity: An intelligent automl framework for autonomous intrusion detection,
L. Yang and A. Shami, “Towards autonomous cybersecurity: An intelligent automl framework for autonomous intrusion detection,” inAutonomousCyber@CCS, 2023. [Online]. Available: https://api. semanticscholar.org/CorpusID:272423857
2023
-
[18]
Y . Shen, A. Sudjianto, R. ArunPrakash, A. Bhattacharyya, M. Rao, Y . Wang, J. Vaughan, and N. Zhou, “Towards a framework on tabular synthetic data generation: a minimalist approach: theory, use cases, and limitations,”ArXiv, vol. abs/2411.10982, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:274131324
-
[19]
The intriguing properties of model explanations,
M. Al-Shedivat, A. Dubey, and E. P. Xing, “The intriguing properties of model explanations,”arXiv preprint arXiv:1801.09808, 2018
-
[20]
Robust variational autoencoder for tabular data with beta divergence,
H. Akrami, S. Ayd ¨ore, R. M. Leahy, and A. A. Joshi, “Robust variational autoencoder for tabular data with beta divergence,” ArXiv, vol. abs/2006.08204, 2020. [Online]. Available: https://api. semanticscholar.org/CorpusID:219687586
-
[21]
R. B. Nelsen,An introduction to copulas. Springer, 2006
2006
-
[22]
H. Khosravi, S. Das, A. Al-Mamun, and I. Ahmed, “Binary gaussian copula synthesis: A novel data augmentation technique to advance ml- based clinical decision support systems for early prediction of dialysis among ckd patients,”ArXiv, vol. abs/2403.00965, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:268230538
-
[23]
Differentially private release of high-dimensional datasets using the gaussian copula,
H. J. Asghar, M. Ding, T. Rakotoarivelo, S. Mrabet, and M. A. Kˆaafar, “Differentially private release of high-dimensional datasets using the gaussian copula,”ArXiv, vol. abs/1902.01499, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:59604403
-
[24]
Measuring re-identification risk using a synthetic estimator to enable data sharing,
Y . Jiang, L. Mosquera, B. Jiang, L. Kong, and K. E. Emam, “Measuring re-identification risk using a synthetic estimator to enable data sharing,”PLoS ONE, vol. 17, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:249748022
2022
-
[25]
Copulas documentation,
S. D. Vault, “Copulas documentation,” 2025, accessed: 2025-01-27. [Online]. Available: https://sdv.dev/Copulas/index.html
2025
-
[26]
Principal component analysis,
S. Wold, K. Esbensen, and P. Geladi, “Principal component analysis,” Chemometrics and intelligent laboratory systems, vol. 2, no. 1-3, pp. 37–52, 1987
1987
-
[27]
Robust bayesian inference for discrete outcomes with the total variation distance,
J. Knoblauch and L. V omfell, “Robust bayesian inference for discrete outcomes with the total variation distance,”ArXiv, vol. abs/2010.13456,
-
[28]
Available: https://api.semanticscholar.org/CorpusID: 225066970
[Online]. Available: https://api.semanticscholar.org/CorpusID: 225066970
-
[29]
Numerically more stable computation of the p- values for the two-sample kolmogorov-smirnov test,
T. Viehmann, “Numerically more stable computation of the p- values for the two-sample kolmogorov-smirnov test,”arXiv preprint arXiv:2102.08037, 2021
-
[30]
Correlationsimilarity,
S. Developers, “Correlationsimilarity,” 2023, accessed: 2025- 02-03. [Online]. Available: https://docs.sdv.dev/sdmetrics/metrics/ metrics-glossary/correlationsimilarity
2023
-
[31]
Contingencysimilarity,
——, “Contingencysimilarity,” 2023, accessed: 2025-02-03. [On- line]. Available: https://docs.sdv.dev/sdmetrics/metrics/metrics-glossary/ contingencysimilarity
2023
-
[32]
Random forests,
L. Breiman, “Random forests,”Machine learning, vol. 45, pp. 5–32, 2001
2001
-
[33]
Greedy function approximation: a gradient boosting machine,
J. H. Friedman, “Greedy function approximation: a gradient boosting machine,”Annals of statistics, pp. 1189–1232, 2001
2001
-
[34]
Nearest neighbor pattern classification,
T. Cover and P. Hart, “Nearest neighbor pattern classification,”IEEE transactions on information theory, vol. 13, no. 1, pp. 21–27, 1967
1967
-
[35]
Breiman,Classification and regression trees
L. Breiman,Classification and regression trees. Routledge, 2017
2017
-
[36]
Naive (bayes) at forty: The independence assumption in information retrieval,
D. D. Lewis, “Naive (bayes) at forty: The independence assumption in information retrieval,” inEuropean conference on machine learning. Springer, 1998, pp. 4–15
1998
-
[37]
The regression analysis of binary sequences,
D. R. Cox, “The regression analysis of binary sequences,”Journal of the Royal Statistical Society Series B: Statistical Methodology, vol. 20, no. 2, pp. 215–232, 1958
1958
-
[38]
Sgdclassifier - scikit-learn 1.3.0 documentation,
S. learn Developers, “Sgdclassifier - scikit-learn 1.3.0 documentation,” n.d., accessed: 2025-01-31. [Online]. Available: https://scikit-learn.org/ stable/modules/generated/sklearn.linear model.SGDClassifier.html
2025
-
[39]
A comparative study of sampling methods with cross-validation in the fedhome framework,
A. Ahmadi, S. S. Sharif, and Y . M. Banad, “A comparative study of sampling methods with cross-validation in the fedhome framework,”ArXiv, vol. abs/2406.01950, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:270226221
-
[40]
A systematic analysis of performance measures for classification tasks,
M. Sokolova and G. Lapalme, “A systematic analysis of performance measures for classification tasks,”Information processing & manage- ment, vol. 45, no. 4, pp. 427–437, 2009
2009
-
[41]
Advantages of the mean absolute error (mae) over the root mean square error (rmse) in assessing average model performance,
C. J. Willmott and K. Matsuura, “Advantages of the mean absolute error (mae) over the root mean square error (rmse) in assessing average model performance,”Climate research, vol. 30, no. 1, pp. 79–82, 2005
2005
-
[42]
Quantifying uncertainty in random forests via confidence intervals and hypothesis tests,
L. Mentch and G. Hooker, “Quantifying uncertainty in random forests via confidence intervals and hypothesis tests,”Journal of Machine Learning Research, vol. 17, no. 26, pp. 1–41, 2016
2016
-
[43]
An r-squared measure of goodness of fit for some common nonlinear regression models,
A. C. Cameron and F. A. Windmeijer, “An r-squared measure of goodness of fit for some common nonlinear regression models,”Journal of econometrics, vol. 77, no. 2, pp. 329–342, 1997
1997
-
[44]
Discretized bottleneck in vae: Posterior-collapse-free sequence-to- sequence learning,
Y . Zhao, P. Yu, S. Mahapatra, Q. Su, and C. Chen, “Discretized bottleneck in vae: Posterior-collapse-free sequence-to- sequence learning,”ArXiv, vol. abs/2004.10603, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:216056569
-
[45]
Invaert networks: A data-driven framework for model synthesis and identifiability analysis,
G. G. Tong, C. A. S. Long, and D. E. Schiavazzi, “Invaert networks: A data-driven framework for model synthesis and identifiability analysis,”Computer Methods in Applied Mechanics and Engineering,
-
[46]
Available: https://api.semanticscholar.org/CorpusID: 261697481
[Online]. Available: https://api.semanticscholar.org/CorpusID: 261697481
-
[47]
Meta-optimized joint generative and contrastive learning for sequential recommendation,
Y . Hao, P. Zhao, J. Fang, J. Qu, G. Liu, F. Zhuang, V . S. Sheng, and X. Zhou, “Meta-optimized joint generative and contrastive learning for sequential recommendation,”2024 IEEE 40th International Conference on Data Engineering (ICDE), pp. 705–718, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:264426259
2024
-
[48]
J. He, D. M. Spokoyny, G. Neubig, and T. Berg-Kirkpatrick, “Lagging inference networks and posterior collapse in variational autoencoders,”ArXiv, vol. abs/1901.05534, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:58014132
-
[49]
Discouraging posterior collapse in hierarchical variational autoencoders using context,
A. Kuzina and J. M. Tomczak, “Discouraging posterior collapse in hierarchical variational autoencoders using context,”arXiv preprint arXiv:2302.09976, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.