Recognition: unknown
An Explainable Approach to Document-level Translation Evaluation with Topic Modeling
Pith reviewed 2026-05-09 23:08 UTC · model grok-4.3
The pith
Topic modeling compares latent themes to evaluate document translations without references.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By independently extracting and comparing latent topic structures within source and translated texts with LSA, LDA, and BERTopic, aligning key tokens via a bilingual dictionary, and measuring thematic consistency with cosine similarity, the framework evaluates document-level translation quality by assessing preservation of thematic integrity even in the absence of reference translations, as shown on a large Korean-English dataset where it measures a differentiated attribute compared with BLEU and CometKiwi.
What carries the argument
Cross-lingual topic alignment and cosine similarity on latent topic representations extracted by LSA, LDA, or BERTopic from source and target documents.
If this is right
- Translation quality can be assessed without reference texts at the full-document scale.
- The metric isolates preservation of document-level thematic units, a property distinct from sentence-level overlap measures.
- Visualization of the contributing topic tokens supplies an immediate explanation for any given score.
- The framework can serve as a complement to existing sentence-level metrics in comprehensive evaluation pipelines.
Where Pith is reading between the lines
- The same topic-alignment pipeline could be tested on additional language pairs once suitable bilingual dictionaries exist.
- If the scores prove reliable, they might supply training signals for neural machine translation systems that aim to maintain document themes.
- Human reviewers could use the token visualizations to locate thematic drift quickly during post-editing.
Load-bearing premise
That latent topic structures extracted by LSA, LDA, and BERTopic, after alignment via bilingual dictionary, accurately represent and allow reliable measurement of the thematic integrity preserved in the translation.
What would settle it
A collection of document translations where human raters find strong thematic preservation yet the topic-similarity scores are low (or the reverse) would falsify the central claim.
Figures



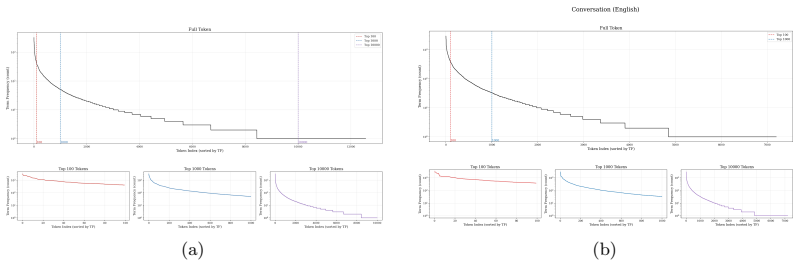
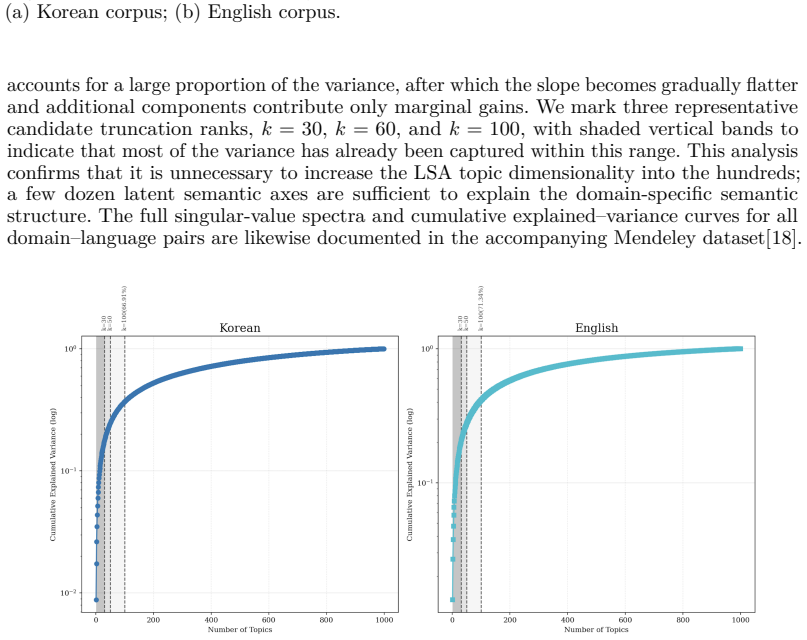



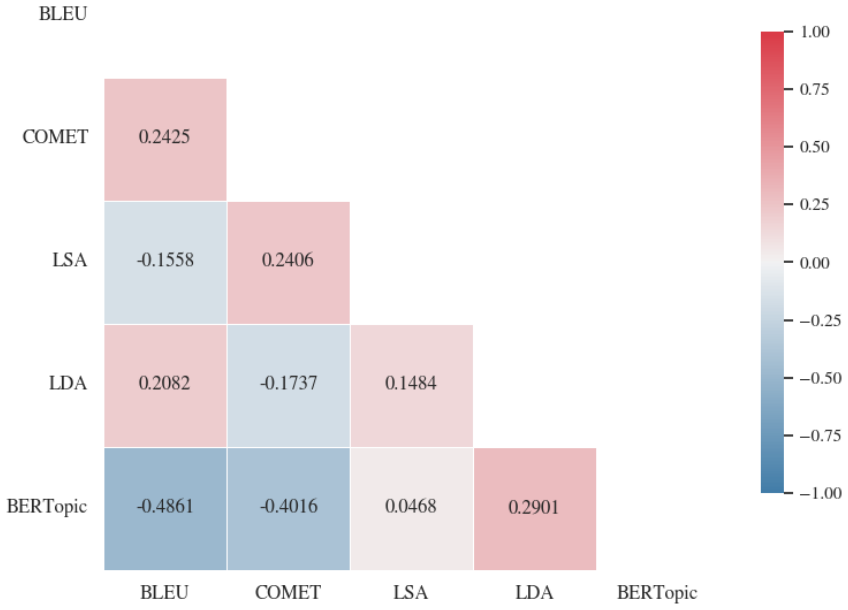
read the original abstract
The advent of NMT has expanded the scope of translation beyond isolated sentences, enabling context to be preserved across paragraphs and documents. However, current evaluation metrics largely remain restricted to the sentence level and typically depend on reference translations. Without references, existing metrics cannot provide a clear basis for their quality assessments. To address these limitations, we propose an evaluation framework that independently extracts and compares latent topic structures within source and translated texts. This framework utilises various topic modelling techniques, including LSA, LDA and BERTopic, to achieve this. Our methodology captures statistical frequency information and semantic context, providing a comprehensive evaluation of the entire document. It aligns key topic tokens across languages using a bilingual dictionary and quantifies thematic consistency via cosine similarity. This allows us to evaluate how faithfully the translation maintains the thematic integrity of the source text, even in the absence of reference translations. To this end, we used a large scale dataset of 9.38 million Korean to English sentence pairs from AI Hub, which includes pre evaluated BLEU scores. We also calculated CometKiwi, a state of the art, reference free metric for this dataset, in order to conduct a comparative analysis with our proposed, topic based framework. Through this analysis, we confirmed that, unlike existing metrics, our framework evaluates the differentiated attribute of document level thematic units. Furthermore, visualising the key tokens that underpin the quantitative evaluation score provides clear insight into translation quality. Consequently, this study contributes to effectively complementing the existing translation evaluation system by proposing a new metric that intuitively identifies whether the document's theme has been preserved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reference-free, explainable framework for document-level machine translation evaluation. It independently extracts latent topic structures from source and translated documents using LSA, LDA, and BERTopic, aligns key tokens via a bilingual dictionary, and quantifies thematic consistency through cosine similarity of the resulting topic distributions. The approach is applied to a large Korean-English dataset of 9.38 million sentence pairs (with pre-computed BLEU scores), compared against CometKiwi, and claimed to uniquely capture document-level thematic units while providing interpretability via visualization of key tokens underpinning the scores.
Significance. If the empirical differentiation holds, the framework could usefully complement existing metrics by targeting thematic integrity at the document level in a reference-free manner, with the added benefit of built-in explainability. The scale of the dataset and the inclusion of multiple topic models (including embedding-based BERTopic) are strengths that support broader applicability claims.
major comments (2)
- [Abstract] Abstract: The central claim that 'we confirmed that, unlike existing metrics, our framework evaluates the differentiated attribute of document level thematic units' is presented as the outcome of analysis on the 9.38M-pair dataset, yet no quantitative results (correlation values with human judgments, score distributions, ablation studies, or direct statistical comparisons to BLEU/CometKiwi) are reported. This is load-bearing for the differentiation assertion.
- [Methodology] Methodology section: The cross-lingual alignment step maps tokens from source and translation topic models using a bilingual dictionary before cosine similarity computation. No details are given on dictionary coverage for Korean-English technical terms or proper nouns, out-of-vocabulary handling, or any validation of alignment fidelity. Because LDA/LSA rely on bag-of-words distributions while BERTopic uses embeddings, unvalidated alignment risks reducing the metric to lexical overlap rather than preserved discourse themes, directly affecting the thematic-integrity claim.
minor comments (2)
- [Abstract] Abstract: The dataset is described as '9.38 million Korean to English sentence pairs' yet topic modeling is applied at the document level; clarify how documents are segmented or aggregated from the sentence pairs.
- [Abstract] The abstract states that the framework 'provides clear insight into translation quality' via visualization, but no example visualizations or quantitative assessment of their utility (e.g., inter-annotator agreement on interpretability) are referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the presentation of our quantitative findings and the transparency of our cross-lingual alignment procedure. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'we confirmed that, unlike existing metrics, our framework evaluates the differentiated attribute of document level thematic units' is presented as the outcome of analysis on the 9.38M-pair dataset, yet no quantitative results (correlation values with human judgments, score distributions, ablation studies, or direct statistical comparisons to BLEU/CometKiwi) are reported. This is load-bearing for the differentiation assertion.
Authors: We agree that the abstract claim requires more explicit quantitative backing to stand on its own. The results section already contains comparative analysis of our topic-model scores against BLEU and CometKiwi across the full 9.38 million pairs, including score distributions that illustrate how our framework identifies thematic inconsistencies not reflected in the other metrics. However, human judgment correlations cannot be provided because the dataset contains no human annotations. We will revise the abstract to summarize the key statistical comparisons and distributions already computed, and we will add a brief ablation discussion on the choice of topic models (LSA, LDA, BERTopic) to further support the differentiation claim. revision: partial
-
Referee: [Methodology] Methodology section: The cross-lingual alignment step maps tokens from source and translation topic models using a bilingual dictionary before cosine similarity computation. No details are given on dictionary coverage for Korean-English technical terms or proper nouns, out-of-vocabulary handling, or any validation of alignment fidelity. Because LDA/LSA rely on bag-of-words distributions while BERTopic uses embeddings, unvalidated alignment risks reducing the metric to lexical overlap rather than preserved discourse themes, directly affecting the thematic-integrity claim.
Authors: We accept this criticism and will expand the Methodology section with the requested details. Specifically, we will describe the bilingual dictionary used (including its provenance and approximate coverage for technical and named-entity terms in the AI Hub corpus), the OOV strategy (exclusion with fallback to character-level matching where feasible), and any post-hoc checks performed on alignment quality. While we acknowledge that the alignment remains token-based, the subsequent cosine similarity operates on the full topic distributions, which for BERTopic incorporate embedding-derived semantics; we will clarify this distinction to avoid any implication that the metric collapses to pure lexical overlap. revision: yes
- Correlation values with human judgments, because the 9.38 million sentence-pair dataset provides no human evaluation annotations.
Circularity Check
No circularity: metric defined by explicit construction and validated externally
full rationale
The paper defines its evaluation score directly via topic extraction (LSA/LDA/BERTopic) on source/translation texts followed by dictionary alignment and cosine similarity. This is an explicit heuristic construction rather than a derivation that reduces to itself. The central claim of measuring a 'differentiated attribute' is supported by comparative analysis against BLEU and CometKiwi on the 9.38M-pair AI Hub dataset, providing external grounding. No equations, self-citations, fitted subsets, or uniqueness theorems appear in the provided text that would create a self-referential loop. The method is self-contained as a proposed metric with observable outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of topics
axioms (2)
- domain assumption Topic models extract latent structures that correspond to document themes.
- domain assumption Bilingual dictionary provides accurate cross-language token alignment for topics.
Reference graph
Works this paper leans on
-
[1]
Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau. Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473, 2014
work page internal anchor Pith review arXiv 2014
-
[2]
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Jade Goldstein, Alon Lavie, Chin-Yew Lin, and Clare Voss, editors,Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, Ann Arbor, Michigan, ...
2005
-
[3]
Latent dirichlet allocation.Journal of machine Learning research, 3(Jan):993–1022, 2003
David M Blei, Andrew Y Ng, and Michael I Jordan. Latent dirichlet allocation.Journal of machine Learning research, 3(Jan):993–1022, 2003
2003
-
[4]
Effective graph context representation for document-level machine translation
Kehai Chen, Muyun Yang, Masao Utiyama, Eiichiro Sumita, Rui Wang, and Min Zhang. Effective graph context representation for document-level machine translation. InIJCAI, pages 4079–4085, 2022
2022
-
[5]
University of Chicago press, 1989
Bernard Comrie.Language universals and linguistic typology: Syntax and morphology. University of Chicago press, 1989
1989
-
[6]
Sugyeong Eo, Chanjun Park, Hyeonseok Moon, Jaehyung Seo, Gyeongmin Kim, Jungseob Lee, and Heuiseok Lim. Quak: A synthetic quality estimation dataset for korean-english neural machine translation.arXiv preprint arXiv:2209.15285, 2022
-
[7]
Results of the wmt21 metrics shared task: Evaluating metrics with expert-based human evaluations on ted and news domain
Markus Freitag, Ricardo Rei, Nitika Mathur, Chi-kiu Lo, Craig Stewart, George Foster, Alon Lavie, and Ondřej Bojar. Results of the wmt21 metrics shared task: Evaluating metrics with expert-based human evaluations on ted and news domain. InProceedings of the Sixth Conference on Machine Translation, pages 733–774, 2021. 27
2021
-
[8]
Evaluate models (automl translation advanced) — cloud translation.https: //cloud.google.com/translate/docs/advanced/automl-evaluate, 2025
Google Cloud. Evaluate models (automl translation advanced) — cloud translation.https: //cloud.google.com/translate/docs/advanced/automl-evaluate, 2025
2025
-
[9]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
Maarten Grootendorst. Bertopic: Neural topic modeling with a class-based tf-idf procedure. arXiv preprint arXiv:2203.05794, 2022
work page internal anchor Pith review arXiv 2022
-
[10]
xcomet: Transparent machine translation evaluation through fine-grained error detection.Transactions of the Association for Computational Linguistics, 12:979–995, 2024
Nuno M Guerreiro, Ricardo Rei, Daan van Stigt, Luisa Coheur, Pierre Colombo, and André FT Martins. xcomet: Transparent machine translation evaluation through fine-grained error detection.Transactions of the Association for Computational Linguistics, 12:979–995, 2024
2024
-
[11]
Achieving Human Parity on Automatic Chinese to English News Translation
Hany Hassan, Anthony Aue, Chang Chen, Vishal Chowdhary, Jonathan Clark, Christian Federmann, Xuedong Huang, Marcin Junczys-Dowmunt, William Lewis, Mu Li, et al. Achieving human parity on automatic chinese to english news translation.arXiv preprint arXiv:1803.05567, 2018
work page Pith review arXiv 2018
-
[12]
Enhancing lexical translation consistency for document-level neural machine translation.Transactions on Asian and Low- Resource Language Information Processing, 21(3):1–21, 2021
Xiaomian Kang, Yang Zhao, Jiajun Zhang, and Chengqing Zong. Enhancing lexical translation consistency for document-level neural machine translation.Transactions on Asian and Low- Resource Language Information Processing, 21(3):1–21, 2021
2021
-
[13]
Tom Kocmi and Christian Federmann. Large language models are state-of-the-art evaluators of translation quality.arXiv preprint arXiv:2302.14520, 2023
-
[14]
Shaohui Kuang, Deyi Xiong, Weihua Luo, and Guodong Zhou. Modeling coherence for neural machine translation with dynamic and topic caches.arXiv preprint arXiv:1711.11221, 2017
-
[15]
Packt Publishing Ltd, 2023
Chris Kuo.The Handbook of NLP with Gensim: Leverage topic modeling to uncover hidden patterns, themes, and valuable insights within textual data. Packt Publishing Ltd, 2023
2023
-
[16]
An introduction to latent semantic analysis.Discourse processes, 25(2-3):259–284, 1998
Thomas K Landauer, Peter W Foltz, and Darrell Laham. An introduction to latent semantic analysis.Discourse processes, 25(2-3):259–284, 1998
1998
-
[17]
Samuel Läubli, Rico Sennrich, and Martin Volk. Has machine translation achieved human parity? a case for document-level evaluation.arXiv preprint arXiv:1808.07048, 2018
-
[18]
Domain-specific topic modeling configu- rations for explainable document-level translation evaluation
Hyeokmin Lee, Youngkyu Kim, and Byounghyun Yoo. Domain-specific topic modeling configu- rations for explainable document-level translation evaluation. Mendeley Data, V2, 2025
2025
-
[19]
More efficient topic modelling through a noun only approach
Fiona Martin and Mark Johnson. More efficient topic modelling through a noun only approach. InProceedings of the Australasian Language Technology Association Workshop 2015, pages 111–115, 2015
2015
-
[20]
Lesly Miculicich, Dhananjay Ram, Nikolaos Pappas, and James Henderson. Document-level neu- ral machine translation with hierarchical attention networks.arXiv preprint arXiv:1809.01576, 2018
-
[21]
Ai hub (portal).https://www.aihub.or.kr/, 2025
National Information Society Agency (NIA). Ai hub (portal).https://www.aihub.or.kr/, 2025
2025
-
[22]
Automatic evaluation of topic coherence
David Newman, Jey Han Lau, Karl Grieser, and Timothy Baldwin. Automatic evaluation of topic coherence. InHuman language technologies: The 2010 annual conference of the North American chapter of the association for computational linguistics, pages 100–108, 2010
2010
-
[23]
Matching results of latent dirichlet allocation for text
Andreas Niekler and Patrick Jähnichen. Matching results of latent dirichlet allocation for text. InProceedings of ICCM, pages 317–322, 2012. 28
2012
-
[24]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Pierre Isabelle, Eugene Charniak, and Dekang Lin, editors, Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Comput...
-
[25]
Chanjun Park, Midan Shim, Sugyeong Eo, Seolhwa Lee, Jaehyung Seo, Hyeonseok Moon, and Heuiseok Lim. Empirical analysis of korean public ai hub parallel corpora and in-depth analysis using liwc.arXiv preprint arXiv:2110.15023, 2021
-
[26]
Konlpy: Korean natural language processing in python
Eunjeong L Park and Sungzoon Cho. Konlpy: Korean natural language processing in python. In Proceedings of the 26th annual conference on human & cognitive language technology, volume 6, pages 133–136. Korean Institute of Information Scientists and Engineers, The Korean Society ..., 2014
2014
-
[27]
Klue: Korean language understanding evaluation.arXiv preprint arXiv:2105.09680, 2021
Sungjoon Park, Jihyung Moon, Sungdong Kim, Won Ik Cho, Jiyoon Han, Jangwon Park, Chisung Song, Junseong Kim, Yongsook Song, Taehwan Oh, et al. Klue: Korean language understanding evaluation.arXiv preprint arXiv:2105.09680, 2021
-
[28]
Ueli Reber. Overcoming language barriers: Assessing the potential of machine translation and topic modeling for the comparative analysis of multilingual text corpora.Communication methods and measures, 13(2):102–125, 2019
2019
-
[29]
Unbabel/wmt20-comet-qe-da
Ricardo Rei, André Martins, and Unbabel. Unbabel/wmt20-comet-qe-da. https:// huggingface.co/Unbabel/wmt20-comet-qe-da, 2020. Hugging Face model checkpoint
2020
-
[30]
Comet: A neural framework for mt evaluation.arXiv preprint arXiv:2009.09025, 2020
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. Comet: A neural framework for mt evaluation.arXiv preprint arXiv:2009.09025, 2020
-
[31]
Are references really needed? unbabel-ist 2021 submission for the metrics shared task
Ricardo Rei, Ana C Farinha, Chrysoula Zerva, Daan van Stigt, Craig Stewart, Pedro Ramos, Taisiya Glushkova, André FT Martins, and Alon Lavie. Are references really needed? unbabel-ist 2021 submission for the metrics shared task. InProceedings of the Sixth Conference on Machine Translation, pages 1030–1040, 2021
2021
-
[32]
Comet-22: Unbabel-ist 2022 submission for the metrics shared task
Ricardo Rei, José GC De Souza, Duarte Alves, Chrysoula Zerva, Ana C Farinha, Taisiya Glushkova, Alon Lavie, Luisa Coheur, and André FT Martins. Comet-22: Unbabel-ist 2022 submission for the metrics shared task. InProceedings of the Seventh Conference on Machine Translation (WMT), pages 578–585, 2022
2022
-
[33]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks.arXiv preprint arXiv:1908.10084, 2019
work page internal anchor Pith review arXiv 1908
-
[34]
kneedle
Ville Satopaa, Jeannie Albrecht, David Irwin, and Barath Raghavan. Finding a" kneedle" in a haystack: Detecting knee points in system behavior. In2011 31st international conference on distributed computing systems workshops, pages 166–171. IEEE, 2011
2011
-
[35]
Authorship attribution based on a probabilistic topic model.Information Processing & Management, 49(1):341–354, 2013
Jacques Savoy. Authorship attribution based on a probabilistic topic model.Information Processing & Management, 49(1):341–354, 2013
2013
-
[36]
Document-level translation quality estimation: exploring discourse and pseudo-references
Carolina Scarton and Lucia Specia. Document-level translation quality estimation: exploring discourse and pseudo-references. InProceedings of the 17th Annual conference of the European Association for Machine Translation, pages 101–108, 2014
2014
-
[37]
Bleurt: Learning robust metrics for text gener- ation
Thibault Sellam, Dipanjan Das, and Ankur P Parikh. Bleurt: Learning robust metrics for text generation.arXiv preprint arXiv:2004.04696, 2020. 29
-
[38]
Research on high-performance english translation based on topic model.Digital Communications and Networks, 9(2):505–511, 2023
Yumin Shen and Hongyu Guo. Research on high-performance english translation based on topic model.Digital Communications and Networks, 9(2):505–511, 2023
2023
-
[39]
Routledge, 2006
Jae Jung Song.The Korean language: Structure, use and context. Routledge, 2006
2006
-
[40]
Trustrank: Inducing trust in automatic translations via ranking
Radu Soricut and Abdessamad Echihabi. Trustrank: Inducing trust in automatic translations via ranking. InProceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pages 612–621, 2010
2010
-
[41]
A context-aware topic model for statistical machine translation
Jinsong Su, Deyi Xiong, Yang Liu, Xianpei Han, Hongyu Lin, Junfeng Yao, and Min Zhang. A context-aware topic model for statistical machine translation. InProceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 229–238, 2015
2015
-
[42]
Rethinking document-level neural machine translation.arXiv preprint arXiv:2010.08961, 2020
Zewei Sun, Mingxuan Wang, Hao Zhou, Chengqi Zhao, Shujian Huang, Jiajun Chen, and Lei Li. Rethinking document-level neural machine translation.arXiv preprint arXiv:2010.08961, 2020
-
[43]
No Starch Press, 2020
Yuli Vasiliev.Natural language processing with Python and spaCy: A practical introduction. No Starch Press, 2020
2020
-
[44]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017
2017
-
[45]
Document-level machine translation with large language models.arXiv preprint arXiv:2304.02210, 2023
Longyue Wang, Chenyang Lyu, Tianbo Ji, Zhirui Zhang, Dian Yu, Shuming Shi, and Zhaopeng Tu. Document-level machine translation with large language models.arXiv preprint arXiv:2304.02210, 2023
-
[46]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675, 2019
work page internal anchor Pith review arXiv 1904
-
[47]
Smdt: Selective memory-augmented neural document translation.arXiv preprint arXiv:2201.01631, 2022
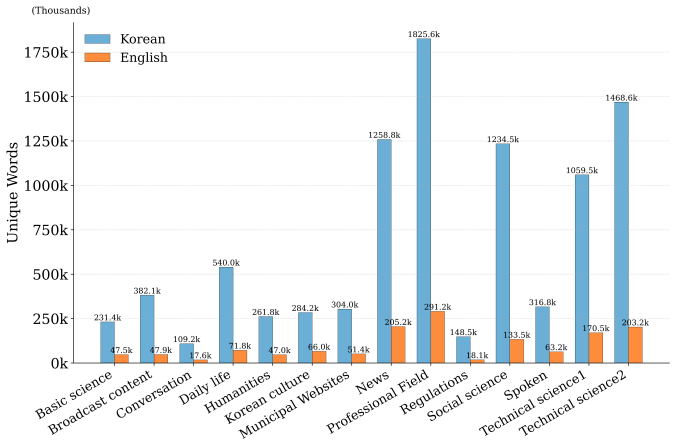
Xu Zhang, Jian Yang, Haoyang Huang, Shuming Ma, Dongdong Zhang, Jinlong Li, and Furu Wei. Smdt: Selective memory-augmented neural document translation.arXiv preprint arXiv:2201.01631, 2022. A Domain-specific dataset links The following table lists the official AI-Hub download pages for each Korean–English parallel corpus used in this study: •Basic science...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.