Recognition: unknown
Stability-Driven Motion Generation for Object-Guided Human-Human Co-Manipulation
Pith reviewed 2026-05-10 01:04 UTC · model grok-4.3
The pith
A flow-matching framework integrates stability-driven simulation to generate realistic motions for two humans jointly manipulating objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
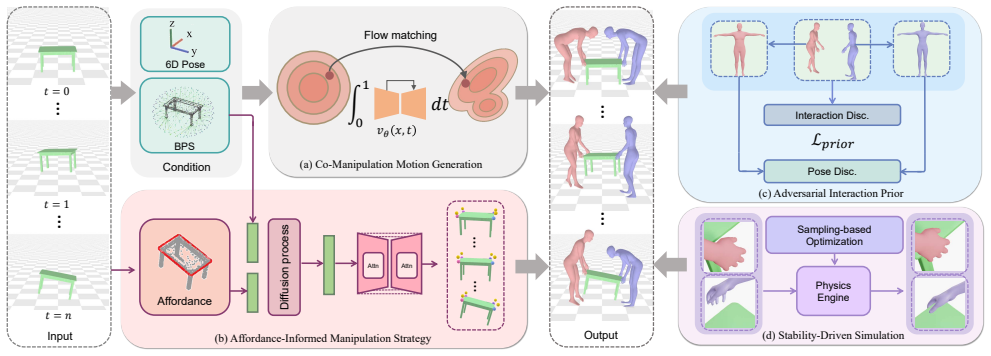
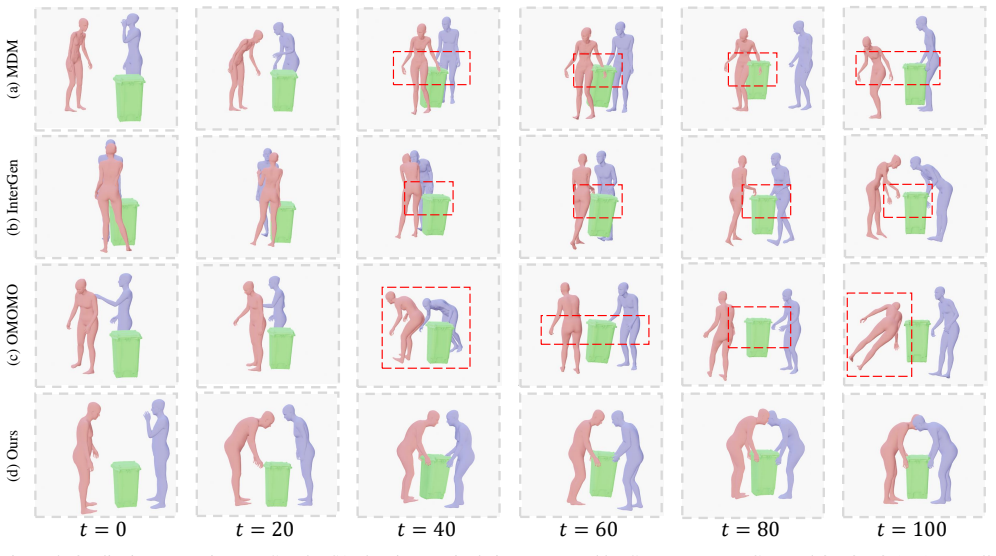
The central claim is that a generative flow-matching model guided by object affordance and spatial configuration, combined with an adversarial interaction prior and a stability-driven simulation that refines unstable states through sampling-based optimization, produces co-manipulation motions with higher contact accuracy, lower penetration, and improved distributional fidelity relative to existing human-object interaction baselines.
What carries the argument
The stability-driven simulation inserted into the flow matching process, which uses sampling-based optimization to refine unstable interaction states and directly modifies the vector field regression.
If this is right
- Motions achieve higher accuracy in object contacts and lower rates of interpenetration.
- Generated sequences exhibit better statistical match to real human co-manipulation data.
- Manipulation strategies are explicitly derived from the object's affordance and spatial setup.
- Natural individual poses and realistic inter-person interactions are promoted by the adversarial prior.
- The overall framework aligns generated flows with successful manipulation goals.
Where Pith is reading between the lines
- The same stability integration could be tested on tasks with more than two agents or with changing object weights.
- Robotic systems performing collaborative lifting or transport might adopt analogous simulation-in-the-loop training.
- Improved fidelity in generated motions could supply higher-quality synthetic data for training perception models.
- The technique suggests a template for embedding physical stability checks inside other generative motion frameworks.
Load-bearing premise
The stability-driven simulation will reliably correct unstable interaction states during flow matching without introducing new artifacts or requiring extensive manual tuning of the sampling optimization.
What would settle it
An ablation experiment that generates the same set of co-manipulation sequences with and without the stability-driven simulation component and directly compares the resulting contact accuracy, penetration volumes, and distributional metrics against ground-truth captures.
Figures




read the original abstract
Co-manipulation requires multiple humans to synchronize their motions with a shared object while ensuring reasonable interactions, maintaining natural poses, and preserving stable states. However, most existing motion generation approaches are designed for single-character scenarios or fail to account for payload-induced dynamics. In this work, we propose a flow-matching framework that ensures the generated co-manipulation motions align with the intended goals while maintaining naturalness and effectiveness. Specifically, we first introduce a generative model that derives explicit manipulation strategies from the object's affordance and spatial configuration, which guide the motion flow toward successful manipulation. To improve motion quality, we then design an adversarial interaction prior that promotes natural individual poses and realistic inter-person interactions during co-manipulation. In addition, we also incorporate a stability-driven simulation into the flow matching process, which refines unstable interaction states through sampling-based optimization and directly adjusts the vector field regression to promote more effective manipulation. The experimental results demonstrate that our method achieves higher contact accuracy, lower penetration, and better distributional fidelity compared to state-of-the-art human-object interaction baselines. The code is available at https://github.com/boycehbz/StaCOM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a flow-matching framework for object-guided human-human co-manipulation motion generation. It derives explicit manipulation strategies from object affordances to guide the flow, adds an adversarial interaction prior for natural poses and inter-person interactions, and integrates a stability-driven simulation that refines unstable states via sampling-based optimization to directly adjust the vector field regression. The central claim is that this yields higher contact accuracy, lower penetration, and better distributional fidelity than state-of-the-art human-object interaction baselines, with code released for reproducibility.
Significance. If the experimental superiority holds after proper validation, the work would advance multi-agent motion synthesis by addressing payload-induced dynamics and stability constraints that are often overlooked in single-character or non-physical models. The explicit coupling of simulation-based refinement into the generative vector field is a concrete technical contribution that could influence downstream applications in robotics and animation. Releasing code is a positive step toward reproducibility.
major comments (3)
- [Experiments section] Experiments section: The quantitative claims of improved contact accuracy, lower penetration, and better distributional fidelity are presented without ablation studies that isolate the stability-driven simulation's effect on vector field regression (e.g., comparing the full model against variants without the sampling-based optimization). This is load-bearing for attributing gains specifically to the stability component rather than affordance guidance or the adversarial prior.
- [Method section (stability integration)] Method section (stability integration): The description states that the stability-driven simulation 'refines unstable interaction states through sampling-based optimization and directly adjusts the vector field regression,' but provides no details on the optimization procedure, number of samples, convergence criteria, or analysis of introduced artifacts or hyperparameter sensitivity. Without this, the reliability of the claimed refinement mechanism cannot be assessed.
- [Experiments section] Experiments section: Metric definitions (contact accuracy, penetration depth) and baseline implementations are not fully specified, nor are dataset splits, evaluation protocols, or statistical significance tests reported. This prevents independent verification of the distributional fidelity and physical plausibility improvements.
minor comments (2)
- [Method section] The notation distinguishing the affordance-guided vector field from the stability-adjusted field could be made more explicit with consistent symbols across equations.
- [Related work] Related work could include additional citations on recent flow-matching applications to physical interaction tasks for better context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to improve experimental validation, methodological clarity, and reproducibility.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: The quantitative claims of improved contact accuracy, lower penetration, and better distributional fidelity are presented without ablation studies that isolate the stability-driven simulation's effect on vector field regression (e.g., comparing the full model against variants without the sampling-based optimization). This is load-bearing for attributing gains specifically to the stability component rather than affordance guidance or the adversarial prior.
Authors: We agree that ablation studies isolating the stability-driven simulation are necessary to properly attribute performance gains. In the revised manuscript, we will add these ablations, including direct comparisons of the full model against variants without the sampling-based optimization, while keeping affordance guidance and the adversarial prior fixed. revision: yes
-
Referee: [Method section (stability integration)] Method section (stability integration): The description states that the stability-driven simulation 'refines unstable interaction states through sampling-based optimization and directly adjusts the vector field regression,' but provides no details on the optimization procedure, number of samples, convergence criteria, or analysis of introduced artifacts or hyperparameter sensitivity. Without this, the reliability of the claimed refinement mechanism cannot be assessed.
Authors: We acknowledge that the current method description lacks sufficient implementation details on the stability integration. We will expand this section in the revision to specify the sampling-based optimization procedure, number of samples, convergence criteria, analysis of potential artifacts, and hyperparameter sensitivity, enabling full assessment and reproducibility of the refinement mechanism. revision: yes
-
Referee: [Experiments section] Experiments section: Metric definitions (contact accuracy, penetration depth) and baseline implementations are not fully specified, nor are dataset splits, evaluation protocols, or statistical significance tests reported. This prevents independent verification of the distributional fidelity and physical plausibility improvements.
Authors: We agree that additional experimental details are required for independent verification. In the revised manuscript, we will provide complete metric definitions, describe baseline implementations, specify dataset splits and evaluation protocols, and include statistical significance tests for the reported improvements. revision: yes
Circularity Check
No significant circularity; derivation chain introduces independent additive components without reduction to inputs.
full rationale
The paper's core flow-matching framework is augmented by three separately motivated modules (affordance-guided strategy derivation, adversarial interaction prior, and stability-driven simulation with sampling-based optimization). None of these are defined circularly in terms of the outputs they produce, nor do any 'predictions' reduce to fitted parameters by construction. The stability adjustment is described as an external refinement step that modifies the vector field regression, not as a self-referential tautology. No self-citations, uniqueness theorems, or ansatzes imported from prior author work appear load-bearing in the provided description. Experimental superiority claims rest on external baselines rather than internal consistency alone, satisfying the criteria for a self-contained, non-circular derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large-scale multi-character interaction synthesis
Ziyi Chang, He Wang, George Koulieris, and Hubert PH Shum. Large-scale multi-character interaction synthesis. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–10, 2025. 2
2025
-
[2]
Col- lage: Collaborative human-agent interaction generation us- ing hierarchical latent diffusion and language models
Divyanshu Daiya, Damon Conover, and Aniket Bera. Col- lage: Collaborative human-agent interaction generation us- ing hierarchical latent diffusion and language models. In 2025 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 8203–8210. IEEE, 2025. 2
2025
-
[3]
Cg-hoi: Contact-guided 3d human-object interaction generation
Christian Diller and Angela Dai. Cg-hoi: Contact-guided 3d human-object interaction generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19888–19901, 2024. 2
2024
-
[4]
Coohoi: Learning cooperative human-object interac- tion with manipulated object dynamics.Advances in Neural Information Processing Systems, 37:79741–79763, 2024
Jiawei Gao, Ziqin Wang, Zeqi Xiao, Jingbo Wang, Tai Wang, Jinkun Cao, Xiaolin Hu, Si Liu, Jifeng Dai, and Jiangmiao Pang. Coohoi: Learning cooperative human-object interac- tion with manipulated object dynamics.Advances in Neural Information Processing Systems, 37:79741–79763, 2024. 2, 5
2024
-
[5]
Trajectory optimization for physics-based re- construction of 3d human pose from monocular video
Erik G ¨artner, Mykhaylo Andriluka, Hongyi Xu, and Cristian Sminchisescu. Trajectory optimization for physics-based re- construction of 3d human pose from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 13106–13115, 2022. 6
2022
-
[6]
Humans in 4d: Re- constructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Re- constructing and tracking humans with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023. 2
2023
-
[7]
2016, arXiv e-prints, arXiv:1604.00772, doi: 10.48550/arXiv.1604.00772
Nikolaus Hansen. The cma evolution strategy: A tutorial. arXiv preprint arXiv:1604.00772, 2016. 6
-
[8]
Synthesizing phys- ical character-scene interactions
Mohamed Hassan, Yunrong Guo, Tingwu Wang, Michael Black, Sanja Fidler, and Xue Bin Peng. Synthesizing phys- ical character-scene interactions. InACM SIGGRAPH 2023 Conference Proceedings, pages 1–9, 2023. 3
2023
-
[9]
Syncdiff: Syn- chronized motion diffusion for multi-body human-object in- teraction synthesis
Wenkun He, Yun Liu, Ruitao Liu, and Li Yi. Syncdiff: Syn- chronized motion diffusion for multi-body human-object in- teraction synthesis. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 11731– 11743, 2025. 2
2025
-
[10]
Neural mocon: Neural motion control for phys- ically plausible human motion capture
Buzhen Huang, Liang Pan, Yuan Yang, Jingyi Ju, and Yan- gang Wang. Neural mocon: Neural motion control for phys- ically plausible human motion capture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6417–6426, 2022. 3, 6
2022
-
[11]
Closely interactive human reconstruction with proxemics and physics-guided adaption
Buzhen Huang, Chen Li, Chongyang Xu, Liang Pan, Yan- gang Wang, and Gim Hee Lee. Closely interactive human reconstruction with proxemics and physics-guided adaption. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1011–1021, 2024. 3, 6
2024
-
[12]
Muhammad Gohar Javed, Chuan Guo, Li Cheng, and Xingyu Li. Intermask: 3d human interaction genera- tion via collaborative masked modeling.arXiv preprint arXiv:2410.10010, 2024. 3
-
[13]
Towards immersive human-x interaction: A real-time framework for physically plausible motion synthesis
Kaiyang Ji, Ye Shi, Zichen Jin, Kangyi Chen, Lan Xu, Yuexin Ma, Jingyi Yu, and Jingya Wang. Towards immersive human-x interaction: A real-time framework for physically plausible motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10173– 10183, 2025. 2
2025
-
[14]
Onlinehoi: Towards on- line human-object interaction generation and perception
Yihong Ji, Yunze Liu, Yiyao Zhuo, Weijiang Yu, Fei Ma, Joshua Zhexue Huang, and Fei Yu. Onlinehoi: Towards on- line human-object interaction generation and perception. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 9395–9403, 2025. 2
2025
-
[15]
End-to-end recovery of human shape and pose
Angjoo Kanazawa, Michael J Black, David W Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7122–7131, 2018. 2
2018
-
[16]
Nifty: Neural object interaction fields for guided human mo- tion synthesis
Nilesh Kulkarni, Davis Rempe, Kyle Genova, Abhijit Kundu, Justin Johnson, David Fouhey, and Leonidas Guibas. Nifty: Neural object interaction fields for guided human mo- tion synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 947– 957, 2024. 2
2024
-
[17]
Nap: Neural 3d articulated object prior.Advances in Neural Information Processing Systems, 36:31878–31894, 2023
Jiahui Lei, Congyue Deng, William B Shen, Leonidas J Guibas, and Kostas Daniilidis. Nap: Neural 3d articulated object prior.Advances in Neural Information Processing Systems, 36:31878–31894, 2023. 2
2023
-
[18]
Two-person interaction augmentation with skeleton priors
Baiyi Li, Edmond SL Ho, Hubert PH Shum, and He Wang. Two-person interaction augmentation with skeleton priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2024. 2
1900
-
[19]
Two-in-one: Unified multi-person interactive motion gen- eration by latent diffusion transformer
Boyuan Li, Xihua Wang, Ruihua Song, and Wenbing Huang. Two-in-one: Unified multi-person interactive motion gen- eration by latent diffusion transformer. InICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025. 3
2025
-
[20]
Object motion guided human motion synthesis.ACM Transactions on Graphics (TOG), 42(6):1–11, 2023
Jiaman Li, Jiajun Wu, and C Karen Liu. Object motion guided human motion synthesis.ACM Transactions on Graphics (TOG), 42(6):1–11, 2023. 2, 7
2023
-
[21]
Controllable human-object interaction synthesis
Jiaman Li, Alexander Clegg, Roozbeh Mottaghi, Jiajun Wu, Xavier Puig, and C Karen Liu. Controllable human-object interaction synthesis. InEuropean Conference on Computer Vision, pages 54–72. Springer, 2024. 2
2024
-
[22]
Ronghui Li, Youliang Zhang, Yachao Zhang, Yuxiang Zhang, Mingyang Su, Jie Guo, Ziwei Liu, Yebin Liu, and Xiu Li. Interdance: Reactive 3d dance generation with re- alistic duet interactions.arXiv preprint arXiv:2412.16982,
-
[23]
Laso: Language-guided affordance seg- mentation on 3d object
Yicong Li, Na Zhao, Junbin Xiao, Chun Feng, Xiang Wang, and Tat-seng Chua. Laso: Language-guided affordance seg- mentation on 3d object. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14251–14260, 2024. 4
2024
-
[24]
Intergen: Diffusion-based multi-human motion genera- tion under complex interactions.International Journal of Computer Vision, 132(9):3463–3483, 2024
Han Liang, Wenqian Zhang, Wenxuan Li, Jingyi Yu, and Lan Xu. Intergen: Diffusion-based multi-human motion genera- tion under complex interactions.International Journal of Computer Vision, 132(9):3463–3483, 2024. 2, 3, 6, 7
2024
-
[25]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Improving sampling-based motion control
Libin Liu, KangKang Yin, and Baining Guo. Improving sampling-based motion control. InComputer Graphics Fo- rum, pages 415–423. Wiley Online Library, 2015. 3, 6
2015
-
[27]
Pon- imator: Unfolding interactive pose for versatile human- human interaction animation
Shaowei Liu, Chuan Guo, Bing Zhou, and Jian Wang. Pon- imator: Unfolding interactive pose for versatile human- human interaction animation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12068–12077, 2025. 3
2025
-
[28]
Yun Liu, Bowen Yang, Licheng Zhong, He Wang, and Li Yi. Mimicking-bench: A benchmark for generalizable humanoid-scene interaction learning via human mimicking. arXiv preprint arXiv:2412.17730, 2024. 2
-
[29]
Core4d: A 4d human-object-human interaction dataset for collaborative object rearrangement
Yun Liu, Chengwen Zhang, Ruofan Xing, Bingda Tang, Bowen Yang, and Li Yi. Core4d: A 4d human-object-human interaction dataset for collaborative object rearrangement. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 1769–1782, 2025. 2, 6
2025
-
[30]
Perpetual humanoid control for real-time simulated avatars
Zhengyi Luo, Jinkun Cao, Kris Kitani, Weipeng Xu, et al. Perpetual humanoid control for real-time simulated avatars. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10895–10904, 2023. 3
2023
-
[31]
Universal humanoid motion representations for physics-based control,
Zhengyi Luo, Jinkun Cao, Josh Merel, Alexander Winkler, Jing Huang, Kris Kitani, and Weipeng Xu. Universal hu- manoid motion representations for physics-based control. arXiv preprint arXiv:2310.04582, 2023. 3
-
[32]
Pino: Person-interaction noise optimization for long-duration and customizable motion generation of arbitrary-sized groups
Sakuya Ota, Qing Yu, Kent Fujiwara, Satoshi Ikehata, and Ikuro Sato. Pino: Person-interaction noise optimization for long-duration and customizable motion generation of arbitrary-sized groups. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 10676– 10685, 2025. 2
2025
-
[33]
To- kenhsi: Unified synthesis of physical human-scene inter- actions through task tokenization
Liang Pan, Zeshi Yang, Zhiyang Dou, Wenjia Wang, Buzhen Huang, Bo Dai, Taku Komura, and Jingbo Wang. To- kenhsi: Unified synthesis of physical human-scene inter- actions through task tokenization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5379–5391, 2025. 3, 5
2025
-
[34]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019. 3
2019
-
[35]
Deepmimic: Example-guided deep reinforce- ment learning of physics-based character skills.ACM Trans- actions On Graphics (TOG), 37(4):1–14, 2018
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel Van de Panne. Deepmimic: Example-guided deep reinforce- ment learning of physics-based character skills.ACM Trans- actions On Graphics (TOG), 37(4):1–14, 2018. 3, 6
2018
-
[36]
Amp: Adversarial motion priors for styl- ized physics-based character control.ACM Transactions on Graphics (ToG), 40(4):1–20, 2021
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for styl- ized physics-based character control.ACM Transactions on Graphics (ToG), 40(4):1–20, 2021. 3
2021
-
[37]
Hierarchical generation of human-object inter- actions with diffusion probabilistic models
Huaijin Pi, Sida Peng, Minghui Yang, Xiaowei Zhou, and Hujun Bao. Hierarchical generation of human-object inter- actions with diffusion probabilistic models. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 15061–15073, 2023. 2
2023
-
[38]
Ef- ficient learning on point clouds with basis point sets
Sergey Prokudin, Christoph Lassner, and Javier Romero. Ef- ficient learning on point clouds with basis point sets. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 4332–4341, 2019. 2, 3
2019
-
[39]
H” denotes the number of heads; “C
Yonatan Shafir, Guy Tevet, Roy Kapon, and Amit H Bermano. Human motion diffusion as a generative prior. arXiv preprint arXiv:2303.01418, 2023. 6, 7
-
[40]
Interactive character control with auto- regressive motion diffusion models.ACM Transactions on Graphics (TOG), 43(4):1–14, 2024
Yi Shi, Jingbo Wang, Xuekun Jiang, Bingkun Lin, Bo Dai, and Xue Bin Peng. Interactive character control with auto- regressive motion diffusion models.ACM Transactions on Graphics (TOG), 43(4):1–14, 2024. 3
2024
-
[41]
Maskedmimic: Unified physics-based char- acter control through masked motion inpainting.ACM Trans- actions on Graphics (TOG), 43(6):1–21, 2024
Chen Tessler, Yunrong Guo, Ofir Nabati, Gal Chechik, and Xue Bin Peng. Maskedmimic: Unified physics-based char- acter control through masked motion inpainting.ACM Trans- actions on Graphics (TOG), 43(6):1–21, 2024. 3
2024
-
[42]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion dif- fusion model.arXiv preprint arXiv:2209.14916, 2022. 2, 4
work page internal anchor Pith review arXiv 2022
-
[43]
Guy Tevet, Sigal Raab, Setareh Cohan, Daniele Reda, Zhengyi Luo, Xue Bin Peng, Amit H Bermano, and Michiel van de Panne. Closd: Closing the loop between simulation and diffusion for multi-task character control.arXiv preprint arXiv:2410.03441, 2024. 3
-
[44]
Intercontrol: Zero-shot human interaction generation by controlling every joint.Advances in Neural Information Processing Systems, 37:105397–105424, 2024
Zhenzhi Wang, Jingbo Wang, Yixuan Li, Dahua Lin, and Bo Dai. Intercontrol: Zero-shot human interaction generation by controlling every joint.Advances in Neural Information Processing Systems, 37:105397–105424, 2024. 3
2024
-
[45]
Hoi-dyn: Learn- ing interaction dynamics for human-object motion diffusion
Lin Wu, Zhixiang Chen, and Jianglin Lan. Hoi-dyn: Learn- ing interaction dynamics for human-object motion diffusion. arXiv preprint arXiv:2507.01737, 2025. 2
-
[46]
Qingxuan Wu, Zhiyang Dou, Chuan Guo, Yiming Huang, Qiao Feng, Bing Zhou, Jian Wang, and Lingjie Liu. Text2interact: High-fidelity and diverse text-to-two-person interaction generation.arXiv preprint arXiv:2510.06504,
-
[47]
Human- object interaction from human-level instructions
Zhen Wu, Jiaman Li, Pei Xu, and C Karen Liu. Human- object interaction from human-level instructions. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 11176–11186, 2025. 2
2025
-
[48]
Inter-x: Towards versatile human- human interaction analysis
Liang Xu, Xintao Lv, Yichao Yan, Xin Jin, Shuwen Wu, Congsheng Xu, Yifan Liu, Yizhou Zhou, Fengyun Rao, Xingdong Sheng, et al. Inter-x: Towards versatile human- human interaction analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22260–22271, 2024. 3, 6
2024
-
[49]
Regennet: Towards human action-reaction synthesis
Liang Xu, Yizhou Zhou, Yichao Yan, Xin Jin, Wenhan Zhu, Fengyun Rao, Xiaokang Yang, and Wenjun Zeng. Regennet: Towards human action-reaction synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1759–1769, 2024. 3
2024
-
[50]
Perceiving and acting in first-person: A dataset and benchmark for egocentric human-object-human interactions
Liang Xu, Chengqun Yang, Zili Lin, Fei Xu, Yifan Liu, Con- gsheng Xu, Yiyi Zhang, Jie Qin, Xingdong Sheng, Yunhui Liu, et al. Perceiving and acting in first-person: A dataset and benchmark for egocentric human-object-human interactions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12535–12548, 2025. 2
2025
-
[51]
Interdiff: Generating 3d human-object interactions with physics-informed diffusion
Sirui Xu, Zhengyuan Li, Yu-Xiong Wang, and Liang-Yan Gui. Interdiff: Generating 3d human-object interactions with physics-informed diffusion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14928–14940, 2023. 2
2023
-
[52]
Interact: Advancing large-scale versatile 3d human-object interaction generation
Sirui Xu, Dongting Li, Yucheng Zhang, Xiyan Xu, Qi Long, Ziyin Wang, Yunzhi Lu, Shuchang Dong, Hezi Jiang, Akshat Gupta, et al. Interact: Advancing large-scale versatile 3d human-object interaction generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7048–7060, 2025. 2
2025
-
[53]
Multi-person interaction generation from two-person motion priors
Wenning Xu, Shiyu Fan, Paul Henderson, and Edmond SL Ho. Multi-person interaction generation from two-person motion priors. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Confer- ence Conference Papers, pages 1–11, 2025. 2
2025
-
[54]
Guiding human-object interactions with rich geometry and relations
Mengqing Xue, Yifei Liu, Ling Guo, Shaoli Huang, and Changxing Ding. Guiding human-object interactions with rich geometry and relations. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22714– 22723, 2025. 6
2025
-
[55]
Learning physically simulated tennis skills from broadcast videos.ACM Trans
Ye Yuan, Viktor Makoviychuk, Y Guo, S Fidler, X Peng, and K Fatahalian. Learning physically simulated tennis skills from broadcast videos.ACM Trans. Graph, 42(4):66, 2023. 3
2023
-
[56]
Physdiff: Physics-guided human motion diffusion model
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz. Physdiff: Physics-guided human motion diffusion model. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 16010–16021, 2023. 3
2023
-
[57]
Physics-based motion imitation with adversarial differential discriminators
Ziyu Zhang, Sergey Bashkirov, Dun Yang, Yi Shi, Michael Taylor, and Xue Bin Peng. Physics-based motion imitation with adversarial differential discriminators. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1– 12, 2025. 3
2025
-
[58]
On the continuity of rotation representations in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5753,
-
[59]
Chen Zhu, Buzhen Huang, Zijing Wu, Binghui Zuo, and Yangang Wang. E-react: Towards emotionally con- trolled synthesis of human reactions.arXiv preprint arXiv:2508.06093, 2025. 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.