Recognition: unknown
Object Referring-Guided Scanpath Prediction with Perception-Enhanced Vision-Language Models
Pith reviewed 2026-05-10 00:39 UTC · model grok-4.3
The pith
ScanVLA uses a vision-language model plus historical fixations and frozen object localization to predict human eye scanpaths for linguistically described targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
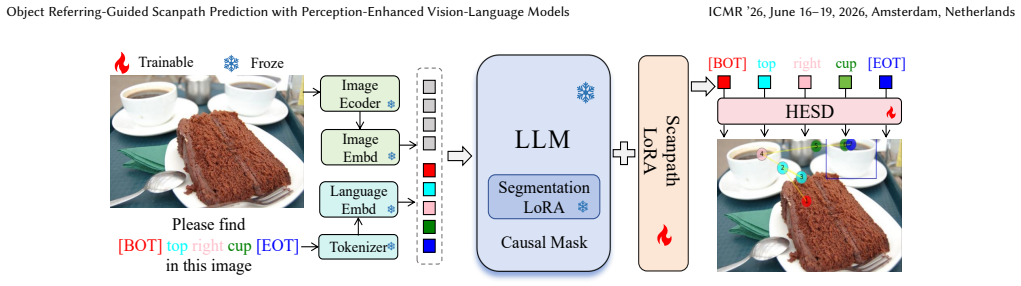
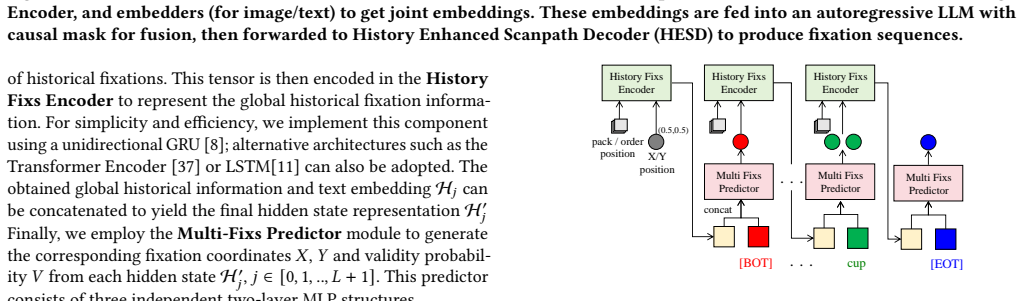
ScanVLA first exploits a Vision-Language Model to extract and fuse inherently aligned visual and linguistic feature representations from the input image and referring expression. Next, a History Enhanced Scanpath Decoder directly takes historical fixations' position information as input to help predict a more reasonable position for the current fixation, while a frozen Segmentation LoRA serves as an auxiliary component to localize the referred object more precisely, improving scanpath prediction without incurring additional large computational and time costs.
What carries the argument
ScanVLA model that fuses aligned features from a vision-language model, then routes them through a History Enhanced Scanpath Decoder (which ingests prior fixation coordinates) and a frozen Segmentation LoRA (for precise target localization).
If this is right
- ScanVLA significantly outperforms existing scanpath prediction methods under object referring.
- The History Enhanced Scanpath Decoder produces more reasonable current-fixation predictions by conditioning on historical positions.
- The frozen Segmentation LoRA improves referred-object localization at negligible extra computational cost.
- Inherently aligned vision-language features support effective multimodal fusion for this prediction task.
Where Pith is reading between the lines
- The same history-injection and frozen-adapter pattern could be tested on video or dynamic scenes where fixation sequences span longer time windows.
- Freezing the localization component suggests a general route for adapting large multimodal models to attention tasks while keeping training budgets low.
- The method may support downstream systems that anticipate user gaze during language-guided image search, such as assistive interfaces or content recommendation.
Load-bearing premise
That the vision-language model's aligned features together with the History Enhanced Scanpath Decoder and frozen Segmentation LoRA will deliver consistent accuracy gains on new data without overfitting or hidden performance costs.
What would settle it
Tests on additional datasets with object-referring expressions in which ScanVLA fails to exceed prior methods on standard scanpath metrics such as AUC or NSS would show the claimed improvements do not hold.
Figures


read the original abstract
Object Referring-guided Scanpath Prediction (ORSP) aims to predict the human attention scanpath when they search for a specific target object in a visual scene according to a linguistic description describing the object. Multimodal information fusion is a key point of ORSP. Therefore, we propose a novel model, ScanVLA, to first exploit a Vision-Language Model (VLM) to extract and fuse inherently aligned visual and linguistic feature representations from the input image and referring expression. Next, to enhance the ScanVLA's perception of fine-grained positional information, we not only propose a novel History Enhanced Scanpath Decoder (HESD) that directly takes historical fixations' position information as input to help predict a more reasonable position for the current fixation, but also adopt a frozen Segmentation LoRA as an auxiliary component to help localize the referred object more precisely, which improves the scanpath prediction task without incurring additional large computational and time costs. Extensive experimental results demonstrate that ScanVLA can significantly outperform existing scanpath prediction methods under object referring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ScanVLA for Object Referring-guided Scanpath Prediction (ORSP). It first uses a Vision-Language Model to extract and fuse aligned visual and linguistic features from an input image and referring expression. It then introduces a History Enhanced Scanpath Decoder (HESD) that conditions on historical fixation positions to predict the next fixation, and incorporates a frozen Segmentation LoRA auxiliary component to improve referred-object localization without large added compute. The central claim is that extensive experiments show ScanVLA significantly outperforms prior scanpath prediction methods on ORSP tasks.
Significance. If the reported gains prove robust, the work would usefully demonstrate how VLMs can be adapted for sequential attention modeling via lightweight, task-specific modules (HESD and frozen LoRA). The efficiency emphasis and focus on fine-grained positional history address real limitations in current scanpath models. This could influence multimodal attention research and applications such as visual search interfaces, provided the improvements generalize beyond the evaluated setups.
major comments (1)
- Experimental section: the central claim of 'significant outperformance' is load-bearing yet the abstract (and available description) provides no concrete information on datasets, baselines, metrics (e.g., AUC, NSS, scanpath similarity), ablation results, or statistical tests. Without these, the contribution of HESD and the Segmentation LoRA cannot be verified as the source of gains rather than implementation details or evaluation choices.
minor comments (2)
- Model architecture description: the integration of HESD outputs with the VLM features and the precise conditioning mechanism on historical positions should be formalized (e.g., with an equation or diagram) to allow reproduction.
- Notation and terminology: 'inherently aligned' features and 'perception-enhanced' are used without explicit definition; a short clarification of what alignment is assumed from the VLM would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract should be revised to include more concrete details on the experimental setup, which will strengthen the presentation of our claims regarding the contributions of HESD and the frozen Segmentation LoRA.
read point-by-point responses
-
Referee: Experimental section: the central claim of 'significant outperformance' is load-bearing yet the abstract (and available description) provides no concrete information on datasets, baselines, metrics (e.g., AUC, NSS, scanpath similarity), ablation results, or statistical tests. Without these, the contribution of HESD and the Segmentation LoRA cannot be verified as the source of gains rather than implementation details or evaluation choices.
Authors: We acknowledge that the abstract does not currently summarize specific details on datasets, baselines, metrics, ablation studies, or statistical tests. The full experimental section of the manuscript provides these elements to support the outperformance claims and isolate the effects of the proposed components. To address the concern directly and improve accessibility, we will revise the abstract to concisely include key information on the evaluation datasets, baselines, metrics (including AUC, NSS, and scanpath similarity), summaries of ablation results demonstrating the roles of HESD and the Segmentation LoRA, and any statistical tests. This change will make the source of the gains clearer without altering the underlying experiments or results. revision: yes
Circularity Check
No significant circularity; empirical architecture with experimental validation
full rationale
The paper presents ScanVLA as a multimodal architecture that fuses VLM features, adds a History Enhanced Scanpath Decoder taking historical fixations as input, and incorporates a frozen Segmentation LoRA for auxiliary localization. The central claim of significant outperformance rests on reported experimental comparisons against baselines on ORSP metrics. No mathematical derivation chain, self-definitional quantities, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described components. The argument is self-contained via empirical results rather than reducing any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-trained vision-language models produce inherently aligned visual and linguistic representations suitable for downstream fusion.
- domain assumption Historical fixation positions provide useful context for predicting the next fixation in object-referring search.
invented entities (2)
-
History Enhanced Scanpath Decoder (HESD)
no independent evidence
-
Frozen Segmentation LoRA auxiliary component
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reuben M Aronson and Henny Admoni. 2022. Gaze complements control input for goal prediction during assisted teleoperation. InRobotics science and systems
2022
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
- [5]
-
[6]
Xianyu Chen, Ming Jiang, and Qi Zhao. 2021. Predicting human scanpaths in visual question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10876–10885
2021
-
[7]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al . 2024. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271(2024)
work page internal anchor Pith review arXiv 2024
-
[8]
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555(2014)
work page internal anchor Pith review arXiv 2014
-
[9]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT). 4171– 4186
2019
-
[10]
Peng Gao, Brian Reily, Savannah Paul, and Hao Zhang. 2020. Visual reference of ambiguous objects for augmented reality-powered human-robot communi- cation in a shared workspace. InInternational Conference on Human-Computer Interaction (HCII). Springer, 550–561
2020
-
[11]
Alex Graves. 2012. Long short-term memory.Supervised sequence labelling with recurrent neural networks(2012), 37–45
2012
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770–778
2016
-
[13]
Derek Hoiem, Rahul Sukthankar, Henry Schneiderman, and Larry Huston. 2004. Object-based image retrieval using the statistical structure of images. InProceed- ings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Vol. 2. IEEE, II–II
2004
-
[14]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[15]
Zhixin Huang, Yuchen Zhou, Jie Zhu, and Chao Gou. 2024. Driver scanpath prediction based on inverse reinforcement learning. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 8306–8310
2024
- [16]
-
[17]
Ewen Lavoie, Jacqueline S Hebert, and Craig S Chapman. 2024. Comparing eye– hand coordination between controller-mediated virtual reality, and a real-world object interaction task.Journal of Vision24, 2 (2024), 9–9
2024
-
[18]
Daeun Lee, Subhojyoti Mukherjee, Branislav Kveton, Ryan A Rossi, Viet Dac Lai, Seunghyun Yoon, Trung Bui, Franck Dernoncourt, and Mohit Bansal. 2025. StreamGaze: Gaze-Guided Temporal Reasoning and Proactive Understanding in Streaming Videos.arXiv preprint arXiv:2512.01707(2025)
work page internal anchor Pith review arXiv 2025
-
[19]
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2017. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Computer Vision (ICCV). 2980–2988
2017
-
[20]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InEuropean Conference on Computer Vision (ECCV). Springer, 740–755
2014
-
[21]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in Neural Information Processing systems (NeurIPs)36 (2023), 34892–34916
2023
-
[22]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Yifei Liu and Rong Quan. 2025. Effective Text-Directed Scanpath Prediction via Comprehensive Multi-modal Information Fusion. InChinese Conference on Pattern Recognition and Computer Vision (PRCV). Springer, 197–211
2025
-
[24]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Daniel Martin, Ana Serrano, Alexander W Bergman, Gordon Wetzstein, and Belen Masia. 2022. Scangan360: A generative model of realistic scanpaths for 360 images.IEEE Transactions on Visualization and Computer Graphics28, 5 (2022), 2003–2013
2022
-
[26]
Zihang Meng, Licheng Yu, Ning Zhang, Tamara L Berg, Babak Damavandi, Vikas Singh, and Amy Bearman. 2021. Connecting what to say with where to look by modeling human attention traces. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12679–12688
2021
-
[27]
Sounak Mondal, Seoyoung Ahn, Zhibo Yang, Niranjan Balasubramanian, Dimitris Samaras, Gregory Zelinsky, and Minh Hoai. 2024. Look Hear: Gaze Prediction for Speech-directed Human Attention. InEuropean Conference on Computer Vision (ECCV). Springer, 236–255
2024
-
[28]
Sounak Mondal, Zhibo Yang, Seoyoung Ahn, Dimitris Samaras, Gregory Zelinsky, and Minh Hoai. 2023. Gazeformer: Scalable, effective and fast prediction of goal- directed human attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1441–1450
2023
-
[29]
Yun Suen Pai, Benjamin Tag, Benjamin Outram, Noriyasu Vontin, Kazunori Sugiura, and Kai Kunze. 2016. GazeSim: simulating foveated rendering using depth in eye gaze for VR. InACM SIGGRAPH 2016 Posters. ACM, 1–2
2016
-
[30]
Mengyu Qiu, Quan Rong, Dong Liang, and Huawei Tu. 2023. Visual scanpath transformer: Guiding computers to see the world. In2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). IEEE, 223–232
2023
-
[31]
Rong Quan, Yantao Lai, Mengyu Qiu, and Dong Liang. 2024. Pathformer3D: A 3D Scanpath Transformer for 360°Images. InEuropean Conference on Computer Vision (ECCV). Springer, 73–90
2024
-
[32]
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M Anwer, Eric Xing, Ming-Hsuan Yang, and Fa- had S Khan. 2024. Glamm: Pixel grounding large multimodal model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13009–13018
2024
-
[33]
Akanksha Saran, Elaine Schaertl Short, Andrea Thomaz, and Scott Niekum. 2020. Understanding teacher gaze patterns for robot learning. InConference on Robot Learning. PMLR, 1247–1258
2020
-
[34]
Xiangjie Sui, Yuming Fang, Hanwei Zhu, Shiqi Wang, and Zhou Wang. 2023. Scandmm: A deep markov model of scanpath prediction for 360deg images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6989–6999
2023
- [35]
-
[36]
Arun Balajee Vasudevan, Dengxin Dai, and Luc Van Gool. 2018. Object refer- ring in visual scene with spoken language. In2018 IEEE winter conference on applications of computer vision (W ACV). IEEE, 1861–1870
2018
-
[37]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in Neural Information Processing systems (NeurIPs)30 (2017)
2017
-
[38]
Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. 2022. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. InInternational Conference on Machine Learning (ICML). 23318–23340
2022
-
[39]
Jiarui Xu, Xingyi Zhou, Shen Yan, Xiuye Gu, Anurag Arnab, Chen Sun, Xiaolong Wang, and Cordelia Schmid. 2024. Pixel-aligned language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13030–13039
2024
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.