Recognition: unknown
MedSkillAudit: A Domain-Specific Audit Framework for Medical Research Agent Skills
Pith reviewed 2026-05-10 00:19 UTC · model grok-4.3
The pith
A domain-specific audit framework for medical research agent skills demonstrates higher consistency than human expert review.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
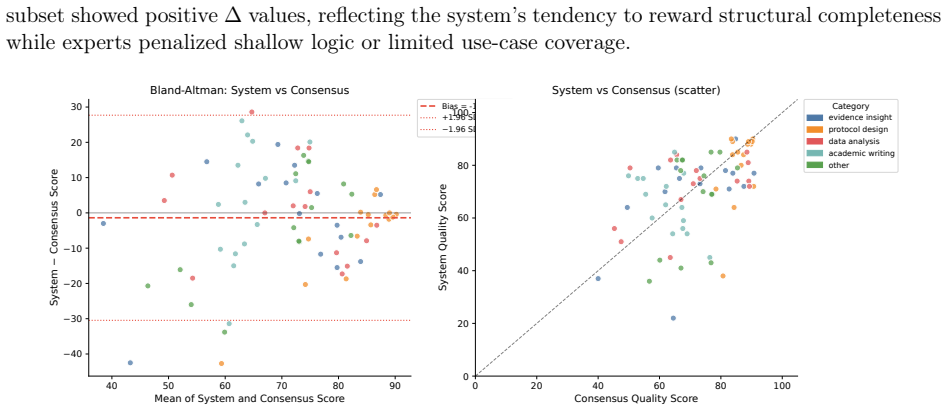
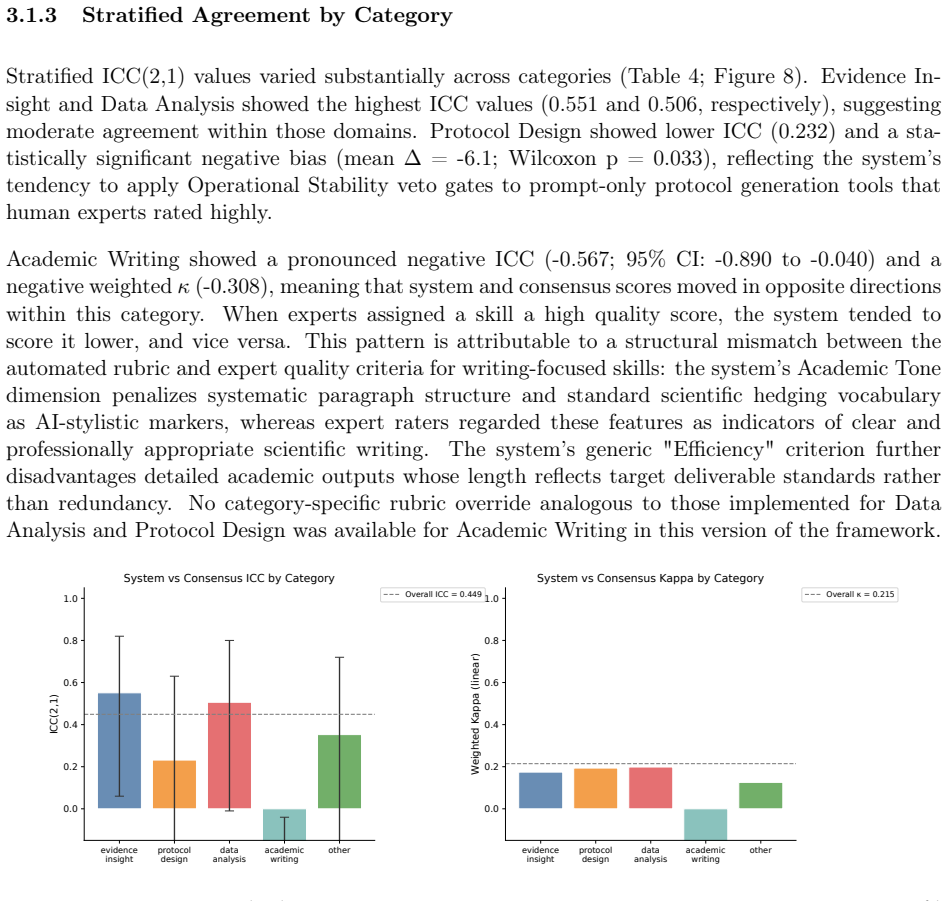
MedSkillAudit, when applied to 75 medical research agent skills, produced assessments that aligned more closely with the consensus of two experts than the experts aligned with each other. Specifically, the framework reached an ICC(2,1) of 0.449 (exceeding the human inter-rater ICC of 0.300), showed smaller divergence in scores (SD 9.5 vs 12.4), and exhibited no directional bias, although agreement varied by category with Protocol Design performing best and Academic Writing showing negative agreement.
What carries the argument
MedSkillAudit (skill-auditor@1.0), a layered framework that assesses skill release readiness through structured evaluation of quality, release disposition, and high-risk flags tailored to medical research needs.
If this is right
- Domain-specific pre-deployment audits can serve as a practical complement to general-purpose quality checks for medical AI agents.
- Over 57 percent of the evaluated skills fell below the Limited Release threshold, indicating potential widespread need for refinement before deployment.
- Agreement is strongest in categories like Protocol Design (ICC 0.551) but weaker or negative in others like Academic Writing, pointing to areas for rubric improvement.
- The framework shows no directional bias relative to experts, supporting its use as a neutral evaluator.
- Structured audit workflows tailored to scientific use cases may help govern the deployment of medical research agent skills.
Where Pith is reading between the lines
- Integrating such audit frameworks into agent development pipelines could enable more scalable safety checks in high-stakes domains like medicine.
- The observed mismatch in certain categories suggests that refining the rubric to better align with expert expectations in writing tasks could further improve reliability.
- Future work might test the framework against a larger panel of experts to strengthen the ground truth baseline.
- This approach could be adapted to other specialized domains requiring integrity and boundary safety, such as legal or financial AI agents.
Load-bearing premise
That the independent quality scores and dispositions from just two experts form a reliable, unbiased ground truth for validating the audit framework.
What would settle it
A follow-up study with a larger group of experts or an independent validation method that finds the framework's scores diverge substantially from a broader expert consensus or fails to identify risks that additional reviewers flag.
Figures







read the original abstract
Background: Agent skills are increasingly deployed as modular, reusable capability units in AI agent systems. Medical research agent skills require safeguards beyond general-purpose evaluation, including scientific integrity, methodological validity, reproducibility, and boundary safety. This study developed and preliminarily evaluated a domain-specific audit framework for medical research agent skills, with a focus on reliability against expert review. Methods: We developed MedSkillAudit (skill-auditor@1.0), a layered framework assessing skill release readiness before deployment. We evaluated 75 skills across five medical research categories (15 per category). Two experts independently assigned a quality score (0-100), an ordinal release disposition (Production Ready / Limited Release / Beta Only / Reject), and a high-risk failure flag. System-expert agreement was quantified using ICC(2,1) and linearly weighted Cohen's kappa, benchmarked against the human inter-rater baseline. Results: The mean consensus quality score was 72.4 (SD = 13.0); 57.3% of skills fell below the Limited Release threshold. MedSkillAudit achieved ICC(2,1) = 0.449 (95% CI: 0.250-0.610), exceeding the human inter-rater ICC of 0.300. System-consensus score divergence (SD = 9.5) was smaller than inter-expert divergence (SD = 12.4), with no directional bias (Wilcoxon p = 0.613). Protocol Design showed the strongest category-level agreement (ICC = 0.551); Academic Writing showed a negative ICC (-0.567), reflecting a structural rubric-expert mismatch. Conclusions: Domain-specific pre-deployment audit may provide a practical foundation for governing medical research agent skills, complementing general-purpose quality checks with structured audit workflows tailored to scientific use cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MedSkillAudit (skill-auditor@1.0), a layered domain-specific audit framework for evaluating the release readiness of medical research agent skills. It applies the framework to 75 skills (15 per category) across five categories, has two experts independently score quality (0-100), assign ordinal release dispositions, and flag high-risk failures, then quantifies system-expert agreement via ICC(2,1) and weighted kappa. The central claim is that the framework achieves ICC(2,1)=0.449 (exceeding human inter-rater ICC=0.300), with smaller score divergence (SD=9.5 vs 12.4) and no bias (Wilcoxon p=0.613), while noting category variation including negative ICC in Academic Writing, positioning the framework as a practical pre-deployment governance tool.
Significance. If the validation holds after addressing ground-truth reliability, the work could supply a structured, domain-tailored complement to general AI agent evaluations, helping enforce scientific integrity, methodological validity, and boundary safety in medical research skills. The explicit category-level breakdowns, statistical benchmarks against human agreement, and preliminary scope provide a reproducible starting point for responsible deployment research in AI-for-healthcare.
major comments (2)
- [Results] Results section (category-level ICCs): The negative ICC of -0.567 in Academic Writing indicates systematic rubric-expert mismatch rather than random disagreement. This directly weakens the central claim that the framework's overall ICC(2,1)=0.449 demonstrates meaningful superiority over the human baseline of 0.300, because the expert scores used as ground truth lack reliability in at least one category. The manuscript must either re-analyze excluding or adjusting for this category, revise the rubric, or reinterpret the superiority claim to account for the mismatch.
- [Methods] Methods section: The criteria for sampling the 75 skills, the exact items comprising the five-category rubric, and the operational definitions of quality score, release disposition, and high-risk flag are not specified in sufficient detail. Without these, the reported agreement metrics cannot be independently reproduced or generalized, which is load-bearing for any claim that the framework offers a practical, domain-specific audit standard.
minor comments (2)
- [Abstract] Abstract: The phrase 'skill-auditor@1.0' is introduced without clarifying whether it denotes a software version, model identifier, or framework release; this notation should be defined on first use.
- The manuscript would benefit from a supplementary table listing all rubric items and scoring anchors to support transparency and future replication.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important areas for improving the manuscript's clarity, reproducibility, and interpretive balance. We address each major comment point-by-point below, with revisions planned where the manuscript requires strengthening.
read point-by-point responses
-
Referee: [Results] Results section (category-level ICCs): The negative ICC of -0.567 in Academic Writing indicates systematic rubric-expert mismatch rather than random disagreement. This directly weakens the central claim that the framework's overall ICC(2,1)=0.449 demonstrates meaningful superiority over the human baseline of 0.300, because the expert scores used as ground truth lack reliability in at least one category. The manuscript must either re-analyze excluding or adjusting for this category, revise the rubric, or reinterpret the superiority claim to account for the mismatch.
Authors: We agree that the negative ICC in Academic Writing reflects a systematic rubric-expert mismatch rather than random variation, and we already flag this in the original manuscript as a 'structural rubric-expert mismatch.' This category-level heterogeneity does qualify the interpretation of the aggregate ICC. In the revision, we will reinterpret the central claim to state that the overall ICC of 0.449 exceeds the human baseline while explicitly noting substantial category variation as a limitation. We will add a supplementary re-analysis computing the ICC after excluding the Academic Writing category (and report the resulting value with confidence interval) to demonstrate performance in domains with better alignment. We will also outline targeted rubric refinements for Academic Writing in the Discussion. These changes preserve the core finding while transparently addressing ground-truth reliability concerns. revision: yes
-
Referee: [Methods] Methods section: The criteria for sampling the 75 skills, the exact items comprising the five-category rubric, and the operational definitions of quality score, release disposition, and high-risk flag are not specified in sufficient detail. Without these, the reported agreement metrics cannot be independently reproduced or generalized, which is load-bearing for any claim that the framework offers a practical, domain-specific audit standard.
Authors: We concur that the current Methods section lacks sufficient granularity for full reproducibility and generalization. In the revised manuscript, we will expand the Methods to include: (1) explicit sampling criteria for the 75 skills, such as selection rules, subdomain diversity targets, complexity stratification, and any exclusion criteria applied; (2) the complete rubric items for each of the five categories, including all sub-items, scoring descriptors, and weighting if applicable; and (3) precise operational definitions, including the 0-100 quality score anchors and calibration examples, the decision rules distinguishing the four ordinal release dispositions, and the specific conditions or thresholds triggering a high-risk failure flag. These additions will directly support independent reproduction of the ICC and kappa metrics. revision: yes
Circularity Check
No significant circularity; evaluation relies on independent expert judgments
full rationale
The paper develops MedSkillAudit as a new audit framework and validates it empirically by comparing its outputs (quality scores, release dispositions, high-risk flags) against independent ratings from two external experts on 75 skills. Agreement is quantified via standard ICC(2,1) and Cohen's kappa metrics benchmarked against the observed human inter-rater baseline; these are direct statistical comparisons to external data rather than any self-referential fit, parameter estimation, or derivation that reduces to the framework's own inputs by construction. No equations, self-citations, or uniqueness claims appear in the provided text that would force the reported ICC superiority or divergence results. The central claims rest on observable agreement with an external reference standard, rendering the evaluation self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inter-rater reliability statistics (ICC(2,1) and linearly weighted Cohen's kappa) provide a valid benchmark for comparing an automated audit system to human experts.
invented entities (1)
-
MedSkillAudit (skill-auditor@1.0) layered framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Li X, Chen W, Liu Y, Zheng S, Chen X, He Y, et al. SkillsBench: Benchmarking how well agent skills work across diverse tasks. arXiv preprint arXiv:2602.12670. 2026
work page internal anchor Pith review arXiv 2026
-
[2]
SkillNet: Create, evaluate, and connect AI skills,
Liang Y, Zhong R, Xu H, Jiang C, Zhong Y, Fang R, et al. SkillNet: Create, Evaluate, and Connect AI Skills. arXiv preprint arXiv:2603.04448. 2026
-
[3]
Artificial hallucinations in ChatGPT: implications in scientific writ- ing.Cureus
Alkaissi H, McFarlane SI. Artificial hallucinations in ChatGPT: implications in scientific writ- ing.Cureus. 2023;15(2):e35179
2023
-
[4]
Evaluating large language models and agents in healthcare: key challenges in clinical applications.Intelligent Medicine
Chen X, Xiang J, Lu S, Liu Y, He M, Shi D. Evaluating large language models and agents in healthcare: key challenges in clinical applications.Intelligent Medicine. 2025;5(2):151–163
2025
-
[5]
Survey of hallucination in natural language generation.ACM Computing Surveys
Ji Z, Lee N, Frieske R, Yu T, Su D, Xu Y, et al. Survey of hallucination in natural language generation.ACM Computing Surveys. 2023;55(12):1–38
2023
-
[6]
Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models
Kung TH, Cheatham M, Medenilla A, Sillos C, De Leon L, Elepano C, et al. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLOS Digital Health. 2023;2(2):e0000198
2023
-
[7]
Capa- bilities of gpt-4 on medical challenge problems
Nori H, King N, McKinney SM, Carignan D, Horvitz E. Capabilities of GPT-4 on medical challenge problems. arXiv preprint arXiv:2303.13375. 2023
-
[8]
Toward expert-level medical question answering with large language models.Nature Medicine
Singhal K, Tu T, Gottweis J, Sayres R, Wulczyn E, Amin M, et al. Toward expert-level medical question answering with large language models.Nature Medicine. 2025;31(3):943–950
2025
-
[9]
A novel evaluation benchmark for medical LLMs illuminating safety and effectiveness in clinical domains.npj Digital Medicine
Wang S, Tang Z, Yang H, Gong Q, Gu T, Ma H, et al. A novel evaluation benchmark for medical LLMs illuminating safety and effectiveness in clinical domains.npj Digital Medicine. 2026;9:91
2026
-
[10]
Large language model agents for biomedicine: a comprehensive review of methods, evaluations, challenges, and future directions.Information
Xu X, Sankar R. Large language model agents for biomedicine: a comprehensive review of methods, evaluations, challenges, and future directions.Information. 2025;16(10):894
2025
-
[11]
MedAgentBench: a virtual EHR environment to benchmark medical LLM agents.NEJM AI
Jiang Y, Black KC, Geng G, Park D, Zou J, Ng AY, et al. MedAgentBench: a virtual EHR environment to benchmark medical LLM agents.NEJM AI. 2025;2(9):AIdbp2500144
2025
-
[12]
The clinicians’ guide to large language models: a general perspective with a focus on hallucinations.Interactive Journal of Medical Research
Roustan D, Bastardot F. The clinicians’ guide to large language models: a general perspective with a focus on hallucinations.Interactive Journal of Medical Research. 2025;14(1):e59823
2025
-
[13]
Human researchers are superior to large language models in writing a medical systematic review in a comparative multitask assessment.Scientific Reports
Sollini M, Pini C, Lazar A, Gelardi F, Ninatti G, Bauckneht M, et al. Human researchers are superior to large language models in writing a medical systematic review in a comparative multitask assessment.Scientific Reports. 2026;16:173
2026
-
[14]
Citation integrity in the age of AI: evaluating the risks of reference hallucination in maxillofacial literature.Journal of Cranio-Maxillofacial Surgery
Jain A, Nimonkar P, Jadhav P. Citation integrity in the age of AI: evaluating the risks of reference hallucination in maxillofacial literature.Journal of Cranio-Maxillofacial Surgery. 2025;53(10):1871–1872
2025
-
[15]
2025;12:e80371
LinardonJ,JarmanHK,McClureZ,AndersonC,LiuC,MesserM.Influenceoftopicfamiliarity and prompt specificity on citation fabrication in mental health research using large language models: experimental study.JMIR Mental Health. 2025;12:e80371
2025
-
[16]
Systems and software engineering — Systems and software Quality Re- quirements and Evaluation (SQuaRE) — System and software quality models
ISO/IEC 25010:2011. Systems and software engineering — Systems and software Quality Re- quirements and Evaluation (SQuaRE) — System and software quality models. International Organization for Standardization; 2011
2011
-
[17]
Data structures for statistical computing in Python.Proceedings of the 9th Python in Science Conference
McKinney W. Data structures for statistical computing in Python.Proceedings of the 9th Python in Science Conference. 2010:56–61
2010
-
[18]
Pingouin: statistics in Python.Journal of Open Source Software
Vallat R. Pingouin: statistics in Python.Journal of Open Source Software. 2018;3(31):1026
2018
-
[19]
SciPy 1.0: fundamental algorithms for scientific computing in Python.Nature Methods
Virtanen P, et al. SciPy 1.0: fundamental algorithms for scientific computing in Python.Nature Methods. 2020;17:261–272
2020
-
[20]
Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research
Pedregosa F, et al. Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research. 2011;12:2825–2830
2011
-
[21]
A guideline of selecting and reporting intraclass correlation coefficients for reliability research.Journal of Chiropractic Medicine
Koo TK, Li MY. A guideline of selecting and reporting intraclass correlation coefficients for reliability research.Journal of Chiropractic Medicine. 2016;15(2):155–163
2016
-
[22]
Weighted kappa: nominal scale agreement with provision for scaled disagreement or partial credit.Psychological Bulletin
Cohen J. Weighted kappa: nominal scale agreement with provision for scaled disagreement or partial credit.Psychological Bulletin. 1968;70(4):213–220
1968
-
[23]
Statistical methods for assessing agreement between two methods of clinical measurement.The Lancet
Bland JM, Altman DG. Statistical methods for assessing agreement between two methods of clinical measurement.The Lancet. 1986;327(8476):307–310
1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.