Recognition: unknown
Temporal Difference Calibration in Sequential Tasks: Application to Vision-Language-Action Models
Pith reviewed 2026-05-09 23:56 UTC · model grok-4.3
The pith
The sequential Brier score risk minimizer equals the value function of a VLA policy for binary episodic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a sequential extension of the Brier score and show that, for binary outcomes, its risk minimizer coincides with the VLA policy's value function. This connection bridges uncertainty calibration and reinforcement learning, enabling the use of temporal-difference (TD) value estimation as a principled calibration mechanism over time. Empirically, TD calibration improves performance relative to the state-of-the-art on simulated and real-robot data, and single-step action probabilities yield competitive uncertainty estimates.
What carries the argument
Sequential Brier score whose risk minimizer equals the policy value function, allowing TD estimation to serve as calibration.
If this is right
- TD calibration improves uncertainty estimates and task performance on both simulated and real-robot VLA data.
- Single-step action probabilities from a TD-calibrated VLA become competitive sources of uncertainty.
- Calibration and value estimation can be treated as the same optimization problem in binary sequential settings.
- Partial trajectories suffice for calibration because the sequential risk minimizer matches the value function.
Where Pith is reading between the lines
- The same TD mechanism could be tested on non-episodic or non-binary tasks to see whether the equivalence generalizes.
- Other calibration losses might admit similar value-function interpretations, opening a route to RL-style calibration in broader sequential models.
- If the equivalence holds, existing value-function approximators in robotics could be repurposed directly as calibrated uncertainty models without extra heads.
Load-bearing premise
Tasks are episodic and outcomes are binary success signals observed only at episode termination.
What would settle it
A binary episodic task where optimizing the sequential Brier score produces probabilities that differ from the value function computed by TD learning, or where TD calibration shows no improvement over non-TD baselines.
Figures



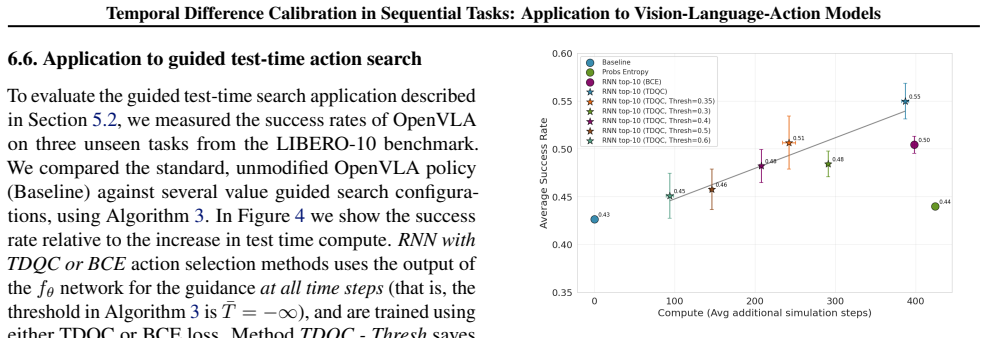




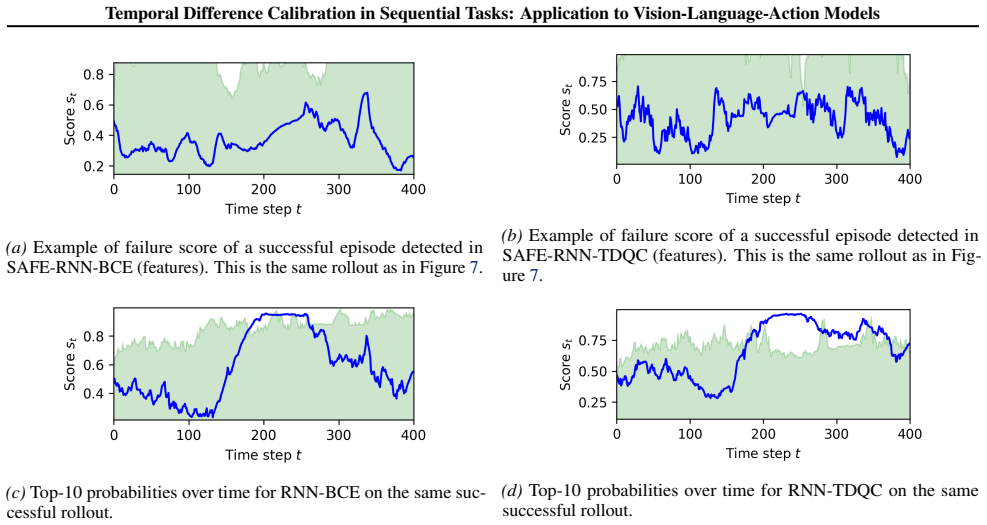






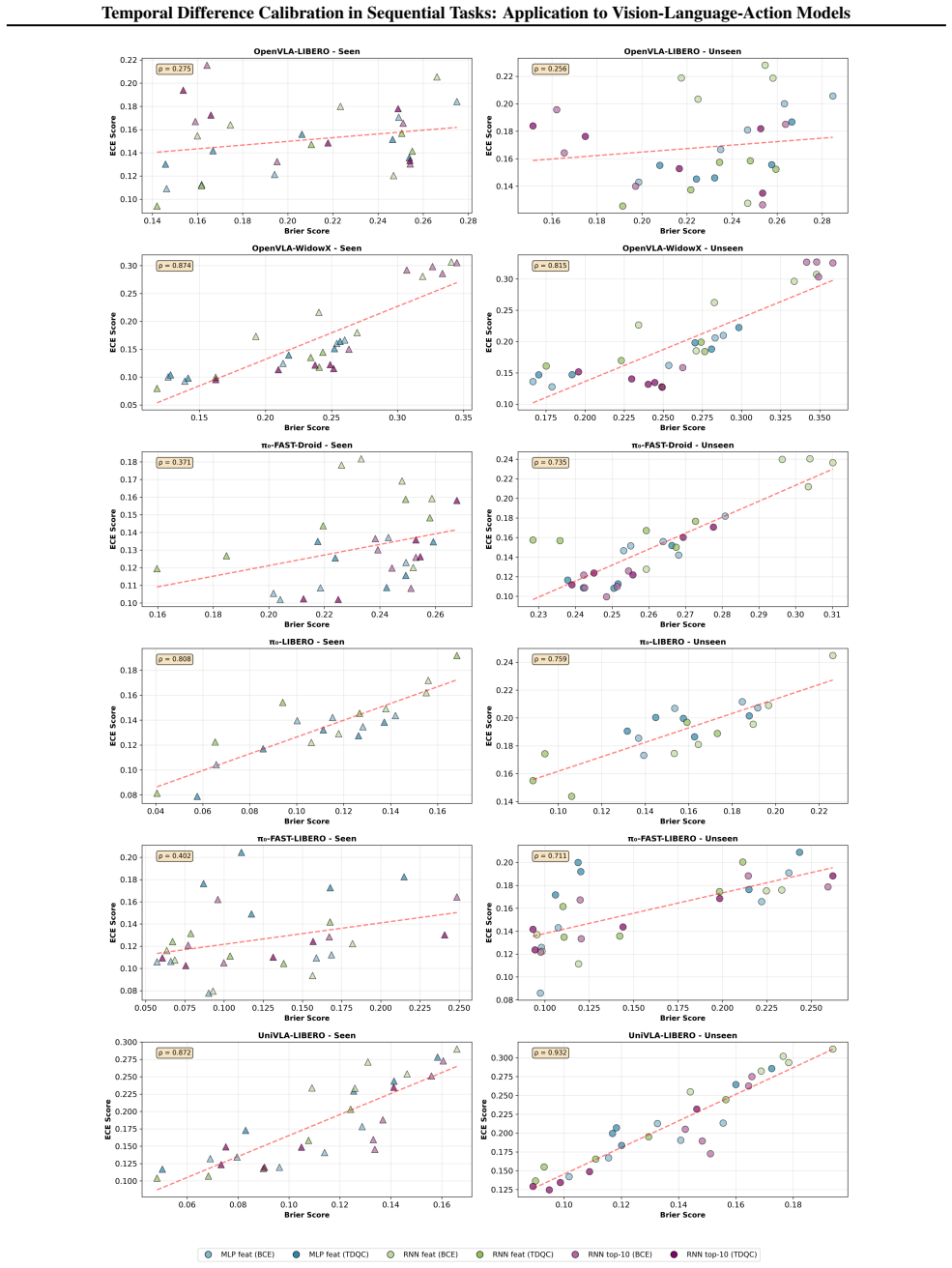
read the original abstract
Recent advances in vision-language-action (VLA) models for robotics have highlighted the importance of reliable uncertainty quantification in sequential tasks. However, assessing and improving calibration in such settings remains mostly unexplored, especially when only partial trajectories are observed. In this work, we formulate sequential calibration for episodic tasks, where task-success confidence is produced along an episode, while success is determined at the end of it. We introduce a sequential extension of the Brier score and show that, for binary outcomes, its risk minimizer coincides with the VLA policy's value function. This connection bridges uncertainty calibration and reinforcement learning, enabling the use of temporal-difference (TD) value estimation as a principled calibration mechanism over time. We empirically show that TD calibration improves performance relative to the state-of-the-art on simulated and real-robot data. Interestingly, we show that when calibrated using TD, the VLA's single-step action probabilities can yield competitive uncertainty estimates, in contrast to recent findings that employed different calibration techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a sequential extension of the Brier score for calibrating uncertainty estimates produced along trajectories in episodic vision-language-action (VLA) tasks, where success is binary and observed only at termination. It claims that the risk minimizer of this score coincides with the policy's value function, thereby justifying the use of temporal-difference (TD) value estimation as a calibration method. Empirical results on simulated and real-robot data show performance gains over prior calibration techniques, and that TD-calibrated single-step action probabilities become competitive for uncertainty quantification.
Significance. If the claimed equivalence holds, the work supplies a direct theoretical link between proper scoring rules and RL value functions that is specific to binary episodic settings; this is a clean bridge with potential utility for uncertainty-aware robotics. The empirical demonstration on real-robot data is a concrete strength, as is the observation that TD calibration can rehabilitate single-step probabilities. The result is internally consistent within its stated scope but does not claim generality beyond episodic binary success.
major comments (2)
- [theoretical development (abstract and §3)] The central claim that the sequential Brier score's risk minimizer equals the value function is load-bearing for the entire contribution, yet the manuscript supplies neither the explicit derivation steps nor the intermediate equations showing that the unique minimizer is the conditional expectation of the terminal outcome given the history. This omission leaves the mathematical bridge without verifiable support.
- [§5] §5 (Experiments): performance gains are reported relative to SOTA, but the text does not describe experimental controls such as matched training budgets, hyperparameter search effort, or whether the TD calibration is applied on-policy versus off-policy in a manner comparable to the baselines. Without these, the empirical superiority claim cannot be assessed.
minor comments (2)
- [§3] The definition of the sequential Brier score should be stated as an explicit equation (with a numbered label) rather than described only in prose, to allow readers to verify the risk-minimizer argument directly.
- [§5] Results tables or figures should include error bars or statistical significance indicators for the reported improvements on both simulated and real-robot data.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We appreciate the recognition of the theoretical link between proper scoring rules and value functions in episodic binary settings, as well as the strengths identified in the empirical evaluation on real-robot data. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and expansions.
read point-by-point responses
-
Referee: [theoretical development (abstract and §3)] The central claim that the sequential Brier score's risk minimizer equals the value function is load-bearing for the entire contribution, yet the manuscript supplies neither the explicit derivation steps nor the intermediate equations showing that the unique minimizer is the conditional expectation of the terminal outcome given the history. This omission leaves the mathematical bridge without verifiable support.
Authors: We agree that the derivation requires more explicit steps for verifiability. In the revised manuscript, we will expand Section 3 (and the abstract if needed for clarity) to include the complete proof. The argument proceeds by first writing the expected sequential Brier score as an expectation over full trajectories, then showing via the law of total expectation and the properness of the Brier score that the unique minimizer at each history is the conditional probability of eventual success given that history—which is exactly the policy value function in this binary episodic setting. All intermediate equations will be provided, along with a note on uniqueness for binary outcomes. revision: yes
-
Referee: [§5] §5 (Experiments): performance gains are reported relative to SOTA, but the text does not describe experimental controls such as matched training budgets, hyperparameter search effort, or whether the TD calibration is applied on-policy versus off-policy in a manner comparable to the baselines. Without these, the empirical superiority claim cannot be assessed.
Authors: We concur that additional experimental details are necessary for reproducibility and fair assessment. In the revised Section 5, we will insert a dedicated paragraph (or subsection) specifying: (i) matched training budgets and total environment steps across all methods, (ii) the hyperparameter search protocol (including ranges, number of trials, and selection metric), and (iii) confirmation that TD calibration is applied off-policy on the same rollout data used by the baselines, with on-policy variants also reported for completeness where relevant. Any differences in compute will be noted. revision: yes
Circularity Check
No significant circularity
full rationale
The central claim is a direct mathematical consequence of defining the sequential Brier score as the expected squared deviation from the terminal binary outcome: its unique risk minimizer is necessarily the conditional expectation of that outcome, which is exactly the policy value function in the episodic setting. The paper introduces the sequential Brier extension explicitly and then states the equivalence as a derived property rather than an assumption or fit. TD estimation is then the standard off-policy method for estimating this quantity. No load-bearing step reduces to a self-citation, a fitted parameter renamed as prediction, or an ansatz smuggled from prior work; the derivation is self-contained and holds under the stated episodic binary-success assumptions without tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Episodic tasks with binary success outcomes determined at the end of the episode.
Reference graph
Works this paper leans on
-
[1]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[2]
Nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. Nature , volume=
-
[3]
Nature , volume=
Mastering atari, go, chess and shogi by planning with a learned model , author=. Nature , volume=. 2020 , publisher=
2020
-
[4]
2026 , publisher =
Mannor, Shie and Mansour, Yishay and Tamar, Aviv , title =. 2026 , publisher =
2026
-
[5]
Conference on Learning Theory , year=
On the distance from calibration in sequential prediction , author=. Conference on Learning Theory , year=
-
[6]
arXiv preprint arXiv:2002.02644 , year=
Temporal probability calibration , author=. arXiv preprint arXiv:2002.02644 , year=
-
[7]
Journal of Machine Learning Research , volume =
Effective Ways to Build and Evaluate Individual Survival Distributions , author =. Journal of Machine Learning Research , volume =
-
[8]
Bellman Calibration for $V$-Learning in Offline Reinforcement Learning
Bellman Calibration for V-Learning in Offline Reinforcement Learning , author=. arXiv preprint arXiv:2512.23694 , year=
work page internal anchor Pith review arXiv
-
[9]
Journal of the American Statistical Association , volume =
Strictly Proper Scoring Rules, Prediction, and Estimation , author =. Journal of the American Statistical Association , volume =
-
[10]
Journal of Mathematical Psychology , volume=
The Area Above the Ordinal Dominance Graph and the Area Below the Receiver Operating Characteristic Graph , author=. Journal of Mathematical Psychology , volume=
-
[11]
Machine Learning , volume=
A Simple Generalisation of the Area Under the ROC Curve for Multiple Class Classification Problems , author=. Machine Learning , volume=
-
[12]
Statistical Methods in the Atmospheric Sciences , author=
-
[13]
Journal of Applied Meteorology and Climatology , volume=
A new vector partition of the probability score , author=. Journal of Applied Meteorology and Climatology , volume=
-
[14]
The Annals of Applied Statistics , volume=
Learn then test: Calibrating predictive algorithms to achieve risk control , author=. The Annals of Applied Statistics , volume=. 2025 , publisher=
2025
-
[15]
Statistics in medicine , volume=
Multiple testing in clinical trials , author=. Statistics in medicine , volume=. 1991 , publisher=
1991
-
[16]
Econometrica: journal of the Econometric Society , pages=
Regression quantiles , author=. Econometrica: journal of the Econometric Society , pages=. 1978 , publisher=
1978
-
[17]
Advances in neural information processing systems , volume=
Conformalized quantile regression , author=. Advances in neural information processing systems , volume=
-
[18]
MIT press , year=
Reinforcement learning: An introduction , author=. MIT press , year=
-
[19]
RT-1: Robotics Transformer for Real-World Control at Scale
Rt-1: Robotics transformer for real-world control at scale , author=. arXiv preprint arXiv:2212.06817 , year=
work page internal anchor Pith review arXiv
-
[20]
Conference on Robot Learning , year=
Openvla: An open-source vision-language-action model , author=. Conference on Robot Learning , year=
-
[21]
Octo: An Open-Source Generalist Robot Policy
Octo: An open-source generalist robot policy , author=. arXiv preprint arXiv:2405.12213 , year=
work page internal anchor Pith review arXiv
-
[22]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
pi\_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. arXiv preprint arXiv:2410.24164 , year=
work page internal anchor Pith review arXiv
-
[23]
Forty-first International Conference on Machine Learning , year=
Prismatic vlms: Investigating the design space of visually-conditioned language models , author=. Forty-first International Conference on Machine Learning , year=
-
[24]
International Conference on Robotics and Automation , year=
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0 , author=. International Conference on Robotics and Automation , year=
-
[25]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Droid: A large-scale in-the-wild robot manipulation dataset , author=. arXiv preprint arXiv:2403.12945 , year=
work page internal anchor Pith review arXiv
-
[26]
Conference on Robot Learning , pages=
Bridgedata v2: A dataset for robot learning at scale , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[27]
Monthly Weather Review, 78(1):1–3, 1950 , year=
Verification of forecasts expressed in terms of probability , author=. Monthly Weather Review, 78(1):1–3, 1950 , year=
1950
-
[28]
Robot Evaluation for the Real World , year=
Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies , author=. Robot Evaluation for the Real World , year=
-
[29]
Advances in Neural Information Processing Systems , year=
SAFE: Multitask Failure Detection for Vision-Language-Action Models , author=. Advances in Neural Information Processing Systems , year=
- [30]
-
[31]
The Thirteenth International Conference on Learning Representations , year=
Vision language models are in-context value learners , author=. The Thirteenth International Conference on Learning Representations , year=
-
[32]
Forty-first International Conference on Machine Learning , year=
Rediffuser: Reliable decision-making using a diffuser with confidence estimation , author=. Forty-first International Conference on Machine Learning , year=
-
[33]
International Conference on Machine Learning , year=
On calibration of modern neural networks , author=. International Conference on Machine Learning , year=
-
[34]
arXiv preprint arXiv:2102.06746 , year=
The importance of being a band: Finite-sample exact distribution-free prediction sets for functional data , author=. arXiv preprint arXiv:2102.06746 , year=
-
[35]
International Conference on Machine Learning , pages=
Why target networks stabilise temporal difference methods , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[36]
Journal of Mathematical Analysis and Applications , volume=
Optimal control of. Journal of Mathematical Analysis and Applications , volume=. 1965 , publisher=
1965
-
[37]
Confidence Calibration in Vision-Language-Action Models , author=. arXiv preprint arXiv:2507.17383 , year=
-
[38]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Fine-tuning vision-language-action models: Optimizing speed and success , author=. arXiv preprint arXiv:2502.19645 , year=
work page internal anchor Pith review arXiv
-
[39]
Conference on Robot Learning , year=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , year=
-
[40]
Vision-language foundation models as effective robot imitators,
Vision-language foundation models as effective robot imitators , author=. arXiv preprint arXiv:2311.01378 , year=
-
[41]
International Conference on Learning Representations , year=
Unified Vision-Language-Action Model , author=. International Conference on Learning Representations , year=
-
[42]
Discrete diffusion vla: Bringing discrete diffusion to action decoding in vision-language-action policies , author=. arXiv preprint arXiv:2508.20072 , year=
-
[43]
Nora: A small open-sourced generalist vision language action model for embodied tasks , author=. arXiv preprint arXiv:2504.19854 , year=
-
[44]
WACV , year =
Beyond Classification: Definition and Density-based Estimation of Calibration in Object Detection , author =. WACV , year =
-
[45]
International Conference on Machine Learning , year =
A Large-Scale Study of Probabilistic Calibration in Neural Network Regression , author =. International Conference on Machine Learning , year =
-
[46]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Fast: Efficient action tokenization for vision-language-action models , author=. arXiv preprint arXiv:2501.09747 , year=
work page internal anchor Pith review arXiv
-
[47]
Advances in Neural Information Processing Systems , year=
Libero: Benchmarking knowledge transfer for lifelong robot learning , author=. Advances in Neural Information Processing Systems , year=
-
[48]
Conference on Learning Representations , year=
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms , author=. Conference on Learning Representations , year=
-
[49]
Transactions of the Association for Computational Linguistics , volume=
How can we know when language models know? on the calibration of language models for question answering , author=. Transactions of the Association for Computational Linguistics , volume=. 2021 , publisher=
2021
-
[50]
Advances in large margin classifiers , volume=
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods , author=. Advances in large margin classifiers , volume=. 1999 , publisher=
1999
-
[51]
Conference on Empirical Methods in Natural Language Processing , year=
Uncertainty in language models: Assessment through rank-calibration , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[52]
ACM Computing Surveys , year=
A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions , author=. ACM Computing Surveys , year=
-
[53]
Conference on Robot Learning , year=
Robots that ask for help: Uncertainty alignment for large language model planners , author=. Conference on Robot Learning , year=
-
[54]
Look before you leap: An exploratory study of uncertainty measurement for large language models,
Look before you leap: An exploratory study of uncertainty measurement for large language models , author=. arXiv preprint arXiv:2307.10236 , year=
-
[55]
Nature , volume=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , publisher=
2024
-
[56]
Findings of the Association for Computational Linguistics , year=
A survey of uncertainty estimation methods on large language models , author=. Findings of the Association for Computational Linguistics , year=
-
[58]
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations , year=
Orgad, Hadas and Toker, Michael and Gekhman, Zorik and Reichart, Roi and Szpektor, Idan and Kotek, Hadas and Belinkov, Yonatan , booktitle=. LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations , year=
-
[59]
Playing Atari with Deep Reinforcement Learning
Playing atari with deep reinforcement learning , author=. arXiv preprint arXiv:1312.5602 , year=
work page internal anchor Pith review arXiv
-
[60]
International Conference on Machine Learning , year=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International Conference on Machine Learning , year=
-
[61]
Conference on Learning Theory , year=
Bias-Variance Error Bounds for Temporal Difference Updates , author=. Conference on Learning Theory , year=
-
[62]
Journal of the American Statistical Association , volume=
Strictly proper scoring rules, prediction, and estimation , author=. Journal of the American Statistical Association , volume=. 2007 , publisher=
2007
-
[63]
, author=
A tutorial on conformal prediction. , author=. Journal of Machine Learning Research , volume=
-
[64]
International Conference on Learning Representations , year=
Decoupled weight decay regularization , author=. International Conference on Learning Representations , year=
-
[65]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
arXiv preprint arXiv:2503.14043 , year=
Learning on LLM Output Signatures for Gray-Box Behavior Analysis , author=. arXiv preprint arXiv:2503.14043 , year=
-
[67]
The Internal State of an
Azaria, Amos and Mitchell, Tom , booktitle=. The Internal State of an
-
[68]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review arXiv
-
[69]
Semantic entropy probes: Robust and cheap hallucination detection in llms , author=. arXiv preprint arXiv:2406.15927 , year=
-
[70]
arXiv preprint arXiv:2407.08735 , year=
Real-time anomaly detection and reactive planning with large language models , author=. arXiv preprint arXiv:2407.08735 , year=
-
[71]
Conference on Robot Learning , year=
Error-aware imitation learning from teleoperation data for mobile manipulation , author=. Conference on Robot Learning , year=
-
[72]
Conference on Robot Learning , year=
Predictive red teaming: Breaking policies without breaking robots , author=. Conference on Robot Learning , year=
-
[73]
International Conference on Robotics and Automation , year=
Asking for help: Failure prediction in behavioral cloning through value approximation , author=. International Conference on Robotics and Automation , year=
-
[74]
Advances in Neural Information Processing Systems , year=
When to ask for help: Proactive interventions in autonomous reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[75]
Robotics: Science and Systems , year=
Failure Prediction with Statistical Guarantees for Vision-Based Robot Control , author=. Robotics: Science and Systems , year=
-
[76]
arXiv preprint arXiv:2007.00245 , year=
Fighting failures with fire: Failure identification to reduce expert burden in intervention-based learning , author=. arXiv preprint arXiv:2007.00245 , year=
-
[77]
2005 , publisher=
Algorithmic learning in a random world , author=. 2005 , publisher=
2005
-
[78]
Evaluating gemini robotics policies in a veo world simulator, 2025
Evaluating Gemini Robotics Policies in a Veo World Simulator , author=. arXiv preprint arXiv:2512.10675 , year=
-
[79]
Reliable and scalable robot policy evaluation with imperfect simulators , author=. arXiv preprint arXiv:2510.04354 , year=
-
[80]
Calibrating LLM Judges: Linear Probes for Fast and Reliable Uncertainty Estimation , author=. arXiv preprint arXiv:2512.22245 , year=
-
[81]
International Conference on Machine Learning , year=
Stop Regressing: Training Value Functions via Classification for Scalable Deep RL , author=. International Conference on Machine Learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.