Recognition: unknown
Break the Optimization Barrier of LLM-Enhanced Recommenders: A Theoretical Analysis and Practical Framework
Pith reviewed 2026-05-09 23:15 UTC · model grok-4.3
The pith
Normalizing item embeddings and reducing LLM representations with a collaborative co-occurrence graph removes the training barrier in LLM-enhanced recommenders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
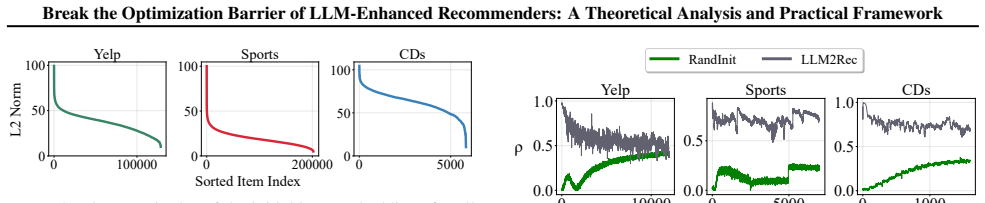
The central claim is that the optimization barrier arises specifically from norm disparity and semantic-collaboration misaligned angular clustering in LLM representations. The authors derive this through analysis of local optimization curvature and confirm it with experiments. They address it via item embedding normalization, which provably controls conditioning, and Rec-PCA, which performs dimensionality reduction while penalizing total variation over an item-item co-occurrence graph built from interaction histories to align semantic and collaborative structures. Both the theory and results show that this lightweight framework enables effective training and outperforms prior LLM-enhanced方法.
What carries the argument
TF-LLMER framework, whose core mechanisms are embedding normalization to eliminate norm-driven instability and Rec-PCA to inject collaborative structure from an item-item co-occurrence graph into the representation transformation.
Load-bearing premise
The two identified causes of norm disparity and angular misalignment are the primary and sufficient explanations for the optimization barrier, and the interaction-derived co-occurrence graph faithfully represents the collaborative structure needed for alignment.
What would settle it
Train the same LLM-enhanced backbone with and without the normalization plus Rec-PCA steps on multiple public datasets and check whether the training loss drops to the level of non-LLM baselines only when both components are active.
Figures












read the original abstract
Large language model (LLM)-enhanced recommendation models inject LLM representations into backbone recommenders to exploit rich item text without inference-time LLM cost. However, we find that existing LLM-enhanced methods significantly hinder the optimization of backbone models, resulting in high training losses that are difficult to reduce. To address it, we establish a comprehensive theoretical analysis of local optimization curvature and identify two key causes: 1) large norm disparity and 2) semantic-collaboration misaligned angular clustering of LLM representations. Guided by these insights, we propose Training-Friendly LLM-Enhanced Recommender (TF-LLMER), a lightweight framework with two key components. First, we highlight the necessity of item embedding normalization to eliminate norm-driven instability and achieve provable control over optimization conditioning. Second, we introduce Rec-PCA, a recommendation-aware dimensionality reduction method that injects collaborative structure into the representation transformation to resolve semantic-collaboration misaligned angular clustering. It jointly optimizes semantic information retention and alignment with an item-item co-occurrence graph constructed from interaction histories. The graph captures collaborative structure, and alignment is promoted by penalizing total variation over the graph. Both theory and extensive experiments demonstrate that TF-LLMER significantly outperforms state-of-the-art methods. Our code is available at https://github.com/woriazzc/TF-LLMER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that LLM-enhanced recommenders suffer from an optimization barrier caused by large norm disparity and semantic-collaboration misaligned angular clustering in LLM representations. It provides a theoretical analysis of local optimization curvature to identify these two causes, then introduces the TF-LLMER framework with item embedding normalization (for provable conditioning control) and Rec-PCA (a graph-based dimensionality reduction using item-item co-occurrence from interactions and total variation penalty for alignment). Both the theory and experiments are asserted to show that TF-LLMER significantly outperforms state-of-the-art methods, with code released.
Significance. If the curvature analysis holds and the framework generalizes, the work is significant for the LLM-recommender integration literature: it isolates concrete representation properties that hinder training and supplies a lightweight, theoretically motivated fix. The explicit code release is a strength that supports reproducibility and follow-on work.
major comments (3)
- [Theoretical Analysis] Theoretical Analysis section: the local-curvature derivation identifies norm disparity and angular misalignment as the dominant causes but does not quantify or bound their contribution relative to other loss-landscape factors (e.g., non-convexity of the backbone recommender loss, interaction between frozen LLM vectors and trainable embeddings, or sparsity-induced variance in the co-occurrence graph). Without such isolation, the claim that these two factors are primary and sufficient remains unproven.
- [Rec-PCA] Rec-PCA subsection: the total-variation penalty on the interaction-derived graph is said to resolve angular misalignment while jointly retaining semantics, yet no explicit objective function, trade-off parameter analysis, or proof that semantic content is not distorted is supplied. This is load-bearing for the “provable control” claim.
- [Experiments] Experimental Evaluation: the manuscript asserts extensive experiments and outperformance, but quantitative results (effect sizes, statistical significance), baseline details, ablation studies isolating normalization versus Rec-PCA, and verification that the co-occurrence graph faithfully captures collaborative structure are not presented at a level that allows independent confirmation of the central claims.
minor comments (2)
- [Abstract] Abstract: the phrase “provable control over optimization conditioning” should be qualified by the exact statement that is proven (e.g., a bound on the condition number after normalization).
- [Notation] Notation: ensure consistent symbols for LLM embeddings, normalized embeddings, and the transformed Rec-PCA outputs across equations and text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, providing clarifications and indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical Analysis section: the local-curvature derivation identifies norm disparity and angular misalignment as the dominant causes but does not quantify or bound their contribution relative to other loss-landscape factors (e.g., non-convexity of the backbone recommender loss, interaction between frozen LLM vectors and trainable embeddings, or sparsity-induced variance in the co-occurrence graph). Without such isolation, the claim that these two factors are primary and sufficient remains unproven.
Authors: We appreciate the referee's point on the need for stronger isolation. Our local-curvature analysis approximates the Hessian of the recommendation loss with respect to the injected LLM representations and explicitly decomposes the leading eigenvalues into contributions from norm disparity (scaling the gradient magnitude) and angular misalignment (affecting the off-diagonal coupling terms). While the backbone loss is non-convex, the analysis shows these representation-induced terms dominate the condition number in the early training phase. To address the concern, we will add a new paragraph in the Theoretical Analysis section that bounds the relative magnitude of these terms against the backbone Hessian and interaction sparsity effects, using a simplified linear model for illustration. revision: partial
-
Referee: [Rec-PCA] Rec-PCA subsection: the total-variation penalty on the interaction-derived graph is said to resolve angular misalignment while jointly retaining semantics, yet no explicit objective function, trade-off parameter analysis, or proof that semantic content is not distorted is supplied. This is load-bearing for the “provable control” claim.
Authors: We agree that the mathematical formulation requires explicit presentation. Rec-PCA solves the optimization problem min_W ||X - X W||_F^2 + λ TV(W; G), where X are the LLM embeddings, W is the projection matrix, G is the item-item co-occurrence graph, and TV is the total variation penalty. The hyperparameter λ trades off semantic fidelity (first term) against collaborative alignment (second term). We will insert the full objective, a sensitivity analysis over λ, and a brief argument (leveraging the fact that the graph Laplacian eigenvectors preserve low-frequency semantic clusters) showing that semantic content is not distorted beyond a controllable error bound. These additions will appear in the revised Rec-PCA subsection. revision: yes
-
Referee: [Experiments] Experimental Evaluation: the manuscript asserts extensive experiments and outperformance, but quantitative results (effect sizes, statistical significance), baseline details, ablation studies isolating normalization versus Rec-PCA, and verification that the co-occurrence graph faithfully captures collaborative structure are not presented at a level that allows independent confirmation of the central claims.
Authors: We acknowledge that the experimental reporting can be strengthened for reproducibility. In the revised manuscript we will expand the Experimental Evaluation section to include: (i) tables reporting relative improvements with 95% confidence intervals and paired t-test p-values; (ii) complete baseline hyperparameter settings and implementation details; (iii) dedicated ablation tables separating the effects of normalization and Rec-PCA; and (iv) an additional figure and analysis comparing the co-occurrence graph's spectrum to random and content-only graphs to confirm it encodes collaborative signals. The code release already contains the full experimental pipeline, which will be further documented. revision: yes
Circularity Check
No significant circularity; theoretical analysis and framework are self-contained against external benchmarks.
full rationale
The paper's derivation begins with an external observation of optimization barriers in LLM-enhanced recommenders, followed by a claimed local-curvature analysis that isolates norm disparity and angular misalignment as causes. These motivate normalization (to control conditioning) and Rec-PCA (to align via co-occurrence graph total variation). Neither step reduces by construction to a fitted parameter renamed as prediction, nor relies on self-citation chains or imported uniqueness theorems. The co-occurrence graph is constructed directly from interaction data (independent of the target loss landscape), and performance is evaluated on held-out recommendation metrics. No equations equate the claimed improvement to its own inputs; the analysis remains falsifiable via external datasets and does not smuggle ansatzes via prior self-work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Local optimization curvature analysis correctly diagnoses the sources of high training loss in LLM-enhanced models.
- domain assumption The item-item co-occurrence graph from interaction histories accurately reflects collaborative filtering structure.
Reference graph
Works this paper leans on
-
[1]
2013 , publisher=
Introductory lectures on convex optimization: A basic course , author=. 2013 , publisher=
2013
-
[2]
International Conference on Machine Learning , pages=
A statistical perspective on distillation , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[3]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Semi-supervised learning with graph learning-convolutional networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[4]
arXiv preprint arXiv:2010.04261 , year=
Dissecting hessian: Understanding common structure of hessian in neural networks , author=. arXiv preprint arXiv:2010.04261 , year=
-
[5]
2005 , publisher=
Regression diagnostics: Identifying influential data and sources of collinearity , author=. 2005 , publisher=
2005
-
[6]
New Jersey , volume=
Iterative analysis , author=. New Jersey , volume=. 1962 , publisher=
1962
-
[7]
The American Mathematical Monthly , volume=
The monotonicity theorem, Cauchy's interlace theorem, and the Courant-Fischer theorem , author=. The American Mathematical Monthly , volume=. 1987 , publisher=
1987
-
[8]
Proceedings of the 28th ACM international conference on information and knowledge management , pages=
BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer , author=. Proceedings of the 28th ACM international conference on information and knowledge management , pages=
-
[9]
arXiv preprint arXiv:2402.06216 , year=
Understanding the role of cross-entropy loss in fairly evaluating large language model-based recommendation , author=. arXiv preprint arXiv:2402.06216 , year=
-
[10]
Proceedings of the 17th ACM Conference on Recommender Systems , pages=
Turning dross into gold loss: is bert4rec really better than sasrec? , author=. Proceedings of the 17th ACM Conference on Recommender Systems , pages=
-
[11]
Decoding matters: Addressing amplification bias and homogeneity issue for llm-based recommendation , author=. arXiv preprint arXiv:2406.14900 , year=
-
[12]
Proceedings of the 17th ACM Conference on Recommender Systems , pages=
Uncovering chatgpt’s capabilities in recommender systems , author=. Proceedings of the 17th ACM Conference on Recommender Systems , pages=
-
[13]
Reinforced latent reasoning for llm-based recommendation,
Reinforced Latent Reasoning for LLM-based Recommendation , author=. arXiv preprint arXiv:2505.19092 , year=
-
[14]
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages=
Large language models enhanced collaborative filtering , author=. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages=
-
[15]
ICLR , year=
SLMRec: Distilling Large Language Models into Small for Sequential Recommendation , author=. ICLR , year=
-
[16]
arXiv preprint arXiv:2406.08477 , year=
Improving llms for recommendation with out-of-vocabulary tokens , author=. arXiv preprint arXiv:2406.08477 , year=
-
[17]
arXiv preprint arXiv:2503.24289 , year=
Rec-r1: Bridging generative large language models and user-centric recommendation systems via reinforcement learning , author=. arXiv preprint arXiv:2503.24289 , year=
-
[18]
2025 IEEE 41st International Conference on Data Engineering (ICDE) , pages=
Darec: A disentangled alignment framework for large language model and recommender system , author=. 2025 IEEE 41st International Conference on Data Engineering (ICDE) , pages=. 2025 , organization=
2025
-
[19]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Llmemb: Large language model can be a good embedding generator for sequential recommendation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[20]
Advances in Neural Information Processing Systems , volume=
Llm-esr: Large language models enhancement for long-tailed sequential recommendation , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
arXiv preprint arXiv:2503.01814 , year=
Llminit: A free lunch from large language models for selective initialization of recommendation , author=. arXiv preprint arXiv:2503.01814 , year=
-
[22]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Llm2rec: Large language models are powerful embedding models for sequential recommendation , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[23]
Session-based Recommendations with Recurrent Neural Networks
Session-based recommendations with recurrent neural networks , author=. arXiv preprint arXiv:1511.06939 , year=
work page internal anchor Pith review arXiv
-
[24]
2018 IEEE international conference on data mining (ICDM) , pages=
Self-attentive sequential recommendation , author=. 2018 IEEE international conference on data mining (ICDM) , pages=. 2018 , organization=
2018
-
[25]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[26]
Semi-Supervised Classification with Graph Convolutional Networks
Semi-supervised classification with graph convolutional networks , author=. arXiv preprint arXiv:1609.02907 , year=
work page internal anchor Pith review arXiv
-
[27]
Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
Lightgcn: Simplifying and powering graph convolution network for recommendation , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[28]
Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
How powerful is graph filtering for recommendation , author=. Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[29]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Large Language Model Enhanced Recommender Systems: Methods, Applications and Trends , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[30]
2024 IEEE 40th International Conference on Data Engineering (ICDE) , pages=
Are id embeddings necessary? whitening pre-trained text embeddings for effective sequential recommendation , author=. 2024 IEEE 40th International Conference on Data Engineering (ICDE) , pages=. 2024 , organization=
2024
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Dual-view whitening on pre-trained text embeddings for sequential recommendation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
Companion Proceedings of the ACM Web Conference 2024 , pages=
Enhancing sequential recommendation via llm-based semantic embedding learning , author=. Companion Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[33]
Language models encode collaborative signals in recommendation , author=
-
[34]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Alphafuse: Learn id embeddings for sequential recommendation in null space of language embeddings , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[35]
What Matters in LLM-Based Feature Extractor for Recommender? A Systematic Analysis of Prompts, Models, and Adaptation , author=. arXiv preprint arXiv:2509.14979 , year=
-
[36]
IEEE transactions on neural networks and learning systems , volume=
A comprehensive survey on graph neural networks , author=. IEEE transactions on neural networks and learning systems , volume=. 2020 , publisher=
2020
-
[37]
How Powerful are Graph Neural Networks?
How powerful are graph neural networks? , author=. arXiv preprint arXiv:1810.00826 , year=
work page internal anchor Pith review arXiv
-
[38]
IEEE transactions on neural networks , volume=
The graph neural network model , author=. IEEE transactions on neural networks , volume=. 2008 , publisher=
2008
-
[39]
Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Heterogeneous graph neural network , author=. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[40]
ACM Computing Surveys , volume=
Graph neural networks in recommender systems: a survey , author=. ACM Computing Surveys , volume=. 2022 , publisher=
2022
-
[41]
Recommender systems handbook , pages=
Recommender systems: Techniques, applications, and challenges , author=. Recommender systems handbook , pages=. 2021 , publisher=
2021
-
[42]
ACM Computing Surveys (CSUR) , volume=
A survey on session-based recommender systems , author=. ACM Computing Surveys (CSUR) , volume=. 2021 , publisher=
2021
-
[43]
Proceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval , pages=
Neural graph collaborative filtering , author=. Proceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval , pages=
-
[44]
Proceedings of the 30th ACM international conference on information & knowledge management , pages=
How powerful is graph convolution for recommendation? , author=. Proceedings of the 30th ACM international conference on information & knowledge management , pages=
-
[45]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Extracting low-/high-frequency knowledge from graph neural networks and injecting it into MLPs: an effective GNN-to-MLP distillation framework , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[46]
Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Less is more: Reweighting important spectral graph features for recommendation , author=. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[47]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Exploring feature-based knowledge distillation for recommender system: A frequency perspective , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , pages=
-
[48]
Proceedings of the AAAI conference on artificial intelligence , volume=
Session-based recommendation with graph neural networks , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[49]
2022 , publisher=
Introduction to graph signal processing , author=. 2022 , publisher=
2022
-
[50]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
On Manipulating Signals of User-Item Graph: A Jacobi Polynomial-based Graph Collaborative Filtering , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[51]
Proceedings of the 31st ACM international conference on information & knowledge management , pages=
SVD-GCN: A simplified graph convolution paradigm for recommendation , author=. Proceedings of the 31st ACM international conference on information & knowledge management , pages=
-
[52]
2012 , publisher=
Matrix analysis , author=. 2012 , publisher=
2012
-
[53]
, author=
Deep learning via hessian-free optimization. , author=. Icml , volume=
-
[54]
International Conference on Machine Learning , pages=
Practical Gauss-Newton optimisation for deep learning , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[55]
Canadian Journal of Mathematics , volume=
On the maximum principle of Ky Fan , author=. Canadian Journal of Mathematics , volume=. 1957 , publisher=
1957
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.