Recognition: unknown
FASER: Fine-Grained Phase Management for Speculative Decoding in Dynamic LLM Serving
Pith reviewed 2026-05-09 22:53 UTC · model grok-4.3
The pith
FASER dynamically adjusts speculative token lengths per request and overlaps draft and verification phases in chunks to handle volatile LLM inference loads more efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
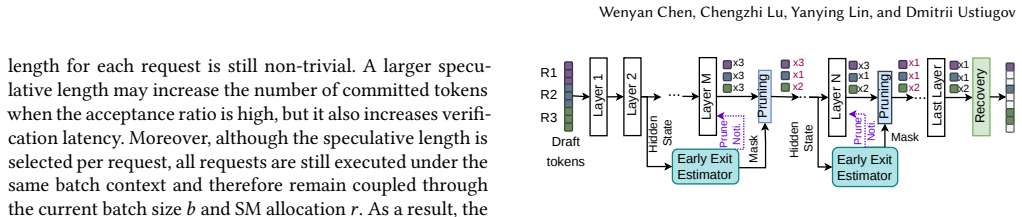
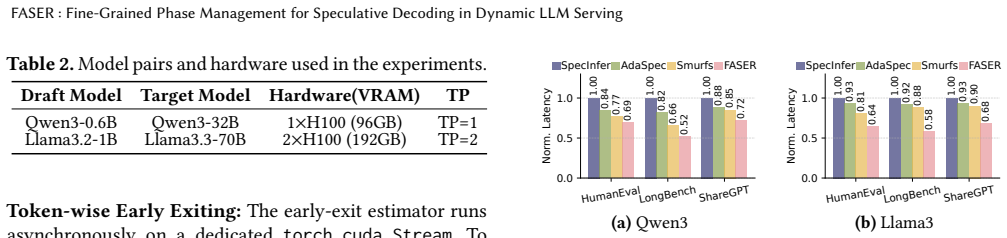
FASER introduces fine-grained SD phase management. It minimizes computational waste by dynamically adjusting the speculative length for each request within a continuous batch and by performing early pruning of rejected tokens inside the verification phase. It also breaks the verification phase into frontiers, or chunks, to overlap them with the draft phase. This overlap is achieved via fine-grained spatial multiplexing with minimal resource interference. The prototype improves throughput by up to 53% and reduces latency by up to 1.92 times compared to state-of-the-art systems.
What carries the argument
fine-grained SD phase management that combines per-request speculative length adjustment, early pruning of rejected tokens, and frontier-based overlap of draft and verification phases through spatial multiplexing
Load-bearing premise
That fine-grained per-request length adjustment and frontier-based overlap via spatial multiplexing can be implemented with negligible overhead and will adapt effectively to volatile online traffic patterns without introducing new bottlenecks or correctness issues.
What would settle it
A side-by-side run of the system against prior speculative decoding implementations on a trace of real requests that suddenly changes load level, checking whether throughput and latency improvements reach the stated levels.
Figures











read the original abstract
Speculative decoding (SD) is a widely used approach for accelerating decode-heavy LLM inference workloads. While online inference workloads are highly dynamic, existing SD systems are rigid and take a coarse-grained approach to SD management. They typically set the speculative token length for an entire batch and serialize the execution of the draft and verification phases. Consequently, these systems fall short at adapting to volatile online inference traffic. Under low load, they exhibit prolonged latency because the draft phase blocks the verification phase for the entire batch, leaving GPU computing resources underutilized. Conversely, under high load, they waste computation on rejected tokens during the verification phase, overloading GPU resources. We introduce FASER, a novel system that features fine-grained SD phase management. First, FASER minimizes computational waste by dynamically adjusting the speculative length for each request within a continuous batch and by performing early pruning of rejected tokens inside the verification phase. Second, FASER breaks the verification phase into frontiers, or chunks, to overlap them with the draft phase. This overlap is achieved via fine-grained spatial multiplexing with minimal resource interference. Our FASER prototype in vLLM improves throughput by up to 53% and reduces latency by up to 1.92$\times$ compared to state-of-the-art systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FASER, a system for fine-grained phase management in speculative decoding (SD) for dynamic LLM serving. It replaces the rigid, coarse-grained batch-level speculative lengths and serialized draft/verification execution of prior SD systems with three mechanisms: per-request dynamic adjustment of speculative token length, early pruning of rejected tokens within the verification phase, and decomposition of verification into frontiers that are overlapped with the draft phase via fine-grained spatial multiplexing on the GPU. The vLLM prototype is claimed to deliver up to 53% higher throughput and up to 1.92× lower latency than state-of-the-art SD systems under volatile online workloads.
Significance. If the empirical gains are reproducible, the work would be significant for LLM inference systems. Existing SD approaches suffer from under-utilization at low load and wasted computation at high load; FASER’s per-request adaptation and frontier-based overlap directly target these issues. The engineering contributions in phase management and low-interference multiplexing could influence the design of future serving frameworks and speculative-decoding extensions.
major comments (2)
- [Evaluation section] Evaluation section: The central claims of 53% throughput improvement and 1.92× latency reduction are load-bearing yet presented without the experimental setup, workload traces, baseline implementations, hardware configuration, number of runs, or error bars. This prevents assessment of whether the reported gains are robust or reproducible.
- [§3.3] §3.3 (Frontier-based spatial multiplexing): The claim that frontier overlap incurs negligible resource interference rests on the unverified assumption that fine-grained per-request length adjustment and spatial multiplexing adapt to volatile traffic without introducing new bottlenecks or correctness issues. No ablation or overhead measurements are provided to support this.
minor comments (1)
- The abstract and introduction refer to “state-of-the-art systems” without naming them; the evaluation section should explicitly list the compared baselines and their configurations for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of reproducibility and empirical validation. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Evaluation section] The central claims of 53% throughput improvement and 1.92× latency reduction are load-bearing yet presented without the experimental setup, workload traces, baseline implementations, hardware configuration, number of runs, or error bars. This prevents assessment of whether the reported gains are robust or reproducible.
Authors: We agree that additional details are needed for full reproducibility assessment. The original manuscript's Evaluation section (§4) describes the vLLM prototype, workloads, and baselines at a high level but omits explicit subsections on hardware (NVIDIA A100 80GB GPUs), workload traces (synthetic Poisson arrivals plus production traces with burstiness), baseline versions (vLLM 0.4.2 with SpecInfer and standard SD), run count (5 independent runs per point with different random seeds), and error bars (standard deviation shown in figures). In the revised version we will add a dedicated §4.1 'Experimental Setup' subsection containing this information, plus a table summarizing configurations. All reported gains (53% throughput, 1.92× latency) will be accompanied by error bars and the raw data will be referenced for reproducibility. revision: yes
-
Referee: [§3.3] §3.3 (Frontier-based spatial multiplexing): The claim that frontier overlap incurs negligible resource interference rests on the unverified assumption that fine-grained per-request length adjustment and spatial multiplexing adapt to volatile traffic without introducing new bottlenecks or correctness issues. No ablation or overhead measurements are provided to support this.
Authors: We acknowledge that §3.3 would benefit from explicit ablation and overhead data. The manuscript argues negligible interference based on the prototype's measured end-to-end gains and the design of frontier decomposition (which keeps per-request state isolated), but does not present separate micro-benchmarks. In revision we will add §4.5 'Ablation and Overhead Analysis' containing: (i) GPU resource utilization (SM occupancy and memory bandwidth) with/without multiplexing under varying load, (ii) latency breakdown isolating frontier overhead, and (iii) a correctness check confirming identical output tokens versus non-overlapped execution. These measurements will directly support the claim that dynamic per-request adjustment prevents new bottlenecks under volatile traffic. revision: yes
Circularity Check
No significant circularity; empirical systems paper
full rationale
The paper presents an engineering systems contribution for fine-grained speculative decoding management in dynamic LLM serving. It describes mechanisms including per-request speculative length adjustment, early pruning of rejected tokens, and frontier-based spatial multiplexing to overlap draft and verification phases. All performance claims (throughput up to 53%, latency reduction up to 1.92×) rest on prototype implementation in vLLM and direct empirical measurements against baselines, with no mathematical derivation chain, no equations, no fitted parameters renamed as predictions, and no load-bearing self-citations in a theoretical sense. The work is self-contained via implementation details and runtime evaluation under volatile traffic.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Online inference traffic is volatile and benefits from per-request adaptation rather than batch-wide fixed parameters.
- domain assumption Spatial multiplexing of draft and verification frontiers on the same GPU can be performed with negligible resource interference.
Reference graph
Works this paper leans on
-
[1]
Green Contexts
2025. Green Contexts. https://docs.nvidia.com/cuda/cuda- programming-guide/04-special-topics/green-contexts.html#green- contexts
2025
-
[2]
Anon8231489123. 2024. ShareGPT dataset. https://huggingface.co/ datasets/anon8231489123/ShareGPT_Vicuna_unfiltered
2024
-
[3]
Azure. 2024. Azure LLM inference trace 2024. https://github.com/ Azure/AzurePublicDataset
2024
- [4]
-
[5]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhid- ian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. 2023. Longbench: A bilingual, multitask benchmark for long context under- standing.arXiv preprint arXiv:2308.14508(2023)
work page internal anchor Pith review arXiv 2023
-
[6]
Branden Butler, Sixing Yu, Arya Mazaheri, and Ali Jannesari. 2024. Pipeinfer: Accelerating llm inference using asynchronous pipelined speculation. InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–19
2024
-
[7]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple llm inference ac- celeration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774(2024)
work page internal anchor Pith review arXiv 2024
-
[8]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318(2023)
work page internal anchor Pith review arXiv 2023
-
[9]
Wenyan Chen, Chengzhi Lu, Huanle Xu, Kejiang Ye, and Chengzhong Xu. 2025. Multiplexing Dynamic Deep Learning Workloads with SLO- awareness in GPU Clusters. InProceedings of EuroSys
2025
-
[10]
Seungbeom Choi, Sunho Lee, Yeonjae Kim, Jongse Park, Youngjin Kwon, and Jaehyuk Huh. 2022. Serving heterogeneous machine learn- ing models on Multi-GPU servers with Spatio-Temporal sharing. In Proceedings of ATC
2022
-
[11]
Dennis D Cox and Susan John. 1992. A statistical method for global optimization. In[Proceedings] 1992 IEEE international conference on systems, man, and cybernetics. IEEE, 1241–1246
1992
-
[12]
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hos- mer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, et al. 2024. LayerSkip: Enabling early exit inference and self-speculative decoding.arXiv preprint arXiv:2404.16710(2024). 12 FASER : Fine-Grained Phase Management for Speculative Decoding in Dynamic LLM Serving
- [13]
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [15]
-
[16]
Kaiyu Huang, Hao Wu, Zhubo Shi, Han Zou, Minchen Yu, and Qingjiang Shi. 2025. AdaSpec: Adaptive Speculative Decoding for Fast, SLO-Aware Large Language Model Serving. InProceedings of SoCC
2025
- [17]
- [18]
-
[19]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[20]
InProceedings of SOSP
Efficient memory management for large language model serv- ing with pagedattention. InProceedings of SOSP
- [21]
-
[22]
Seonho Lee, Amar Phanishayee, and Divya Mahajan. 2025. Forecast- ing GPU Performance for Deep Learning Training and Inference. In Proceedings of ASPLOS
2025
-
[23]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast infer- ence from transformers via speculative decoding. InProceedings of ICML
2023
- [24]
-
[25]
X Li, DG Wang, S Wang, S Wang, Y Wang, Y Wang, Y Wang, Y Wang, Z Wang, Z Wang, et al. 2022. Evaluating large language models trained on code. InProceedings of EMNLP
2022
-
[26]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024. EA- GLE: Speculative Sampling Requires Rethinking Feature Uncertainty. InProceedings of ICML
2024
- [27]
- [28]
-
[29]
Fangcheng Liu, Yehui Tang, Zhenhua Liu, Yunsheng Ni, Duyu Tang, Kai Han, and Yunhe Wang. 2024. Kangaroo: Lossless self-speculative decoding for accelerating llms via double early exiting.Advances in Neural Information Processing Systems37 (2024), 11946–11965
2024
-
[30]
Jiahao Liu, Qifan Wang, Jingang Wang, and Xunliang Cai. 2024. Spec- ulative decoding via early-exiting for faster llm inference with thomp- son sampling control mechanism. InFindings of the Association for Computational Linguistics: ACL 2024. 3027–3043
2024
-
[31]
Tianyu Liu, Yun Li, Qitan Lv, Kai Liu, Jianchen Zhu, Winston Hu, and Xiao Sun. 2025. PEARL: Parallel Speculative Decoding with Adaptive Draft Length. InThe Thirteenth International Conference on Learning Representations
2025
- [32]
-
[33]
Shaoqiang Lu, Yangbo Wei, Junhong Qian, Dongge Qin, Shiji Gao, Yizhi Ding, Qifan Wang, Chen Wu, Xiao Shi, and Lei He. 2026. DFVG: A Heterogeneous Architecture for Speculative Decoding with Draft- on-FPGA and Verify-on-GPU. InProceedings of ASPLOS
2026
-
[34]
Bradley McDanel, Sai Qian Zhang, Yunhai Hu, and Zining Liu. 2025. Pipespec: Breaking stage dependencies in hierarchical LLM decoding. InFindings of the Association for Computational Linguistics: ACL 2025. 12909–12920
2025
-
[35]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xi- aoxiang Shi, et al. 2024. Specinfer: Accelerating large language model serving with tree-based speculative inference and verification. InPro- ceedings of ASPLOS
2024
-
[36]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
-
[37]
Yuhao Shen, Junyi Shen, Quan Kong, Tianyu Liu, Yao Lu, and Cong Wang. 2026. SpecBranch: Speculative Decoding via Hybrid Drafting and Rollback-Aware Branch Parallelism. InThe Fourteenth Interna- tional Conference on Learning Representations
2026
-
[38]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. 2025. Dynamollm: Designing llm inference clusters for per- formance and energy efficiency. InProceedings of HPCA. IEEE
2025
-
[39]
Ziteng Sun, Ananda Theertha Suresh, Jae Hun Ro, Ahmad Beirami, Himanshu Jain, and Felix Yu. 2024. Spectr: Fast speculative decoding via optimal transport.Proceedings of NIPS36 (2024)
2024
- [40]
-
[41]
vLLM Team. 2023. vLLM: Easy, fast, and cheap LLM serving for ev- eryone. https://github.com/vllm-project/vllm
2023
- [42]
-
[43]
Siqi Wang, Hailong Yang, Xuezhu Wang, Tongxuan Liu, Pengbo Wang, Yufan Xu, Xuning Liang, Kejie Ma, Tianyu Feng, Xin You, et al
-
[44]
InProceedings of SC
Towards Efficient LLM Inference via Collective and Adaptive Speculative Decoding. InProceedings of SC
-
[45]
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, et al. 2025. Burstgpt: A real-world workload dataset to optimize llm serving sys- tems. InProceedings of the 31st ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining V. 2. 5831–5841
2025
-
[46]
Zhaoxuan Wu, Zijian Zhou, Arun Verma, Alok Prakash, Daniela Rus, and Bryan Kian Hsiang Low. 2025. TETRIS: Optimal draft token se- lection for batch speculative decoding. InProceedings of ACL
2025
- [47]
-
[48]
Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, and Zhifang Sui. 2024. Unlocking efficiency in 13 Wenyan Chen, Chengzhi Lu, Yanying Lin, and Dmitrii Ustiugov large language model inference: A comprehensive survey of specula- tive decoding.arXiv preprint arXiv:2401.07851(2024)
- [49]
-
[50]
Jiaming Xu, Jiayi Pan, Yongkang Zhou, Siming Chen, Jinhao Li, Yaoxiu Lian, Junyi Wu, and Guohao Dai. 2025. Specee: Accelerat- ing large language model inference with speculative early exiting. In Proceedings of ISCA
2025
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al
-
[52]
Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guant- ing Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Kem- ing Lu, Keqin Chen, Kexin Yang,...
work page internal anchor Pith review arXiv 2024
- [54]
- [55]
-
[56]
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. 2024. Draft& verify: Lossless large language model acceleration via self-speculative decoding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 11263–11282
2024
- [57]
-
[58]
Ziyin Zhang, Jiahao Xu, Tian Liang, Xingyu Chen, Zhiwei He, Rui Wang, and Zhaopeng Tu. 2025. Draft Model Knows When to Stop: Self-Verification Speculative Decoding for Long-Form Generation. In Proceedings of EMNLP
2025
-
[59]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregat- ing prefill and decoding for goodput-optimized large language model serving. InProceedings of OSDI
2024
- [60]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.