Recognition: unknown
Where Reasoning Breaks: Logic-Aware Path Selection by Controlling Logical Connectives in LLMs Reasoning Chains
Pith reviewed 2026-05-10 00:09 UTC · model grok-4.3
The pith
Intervening only at logical connectives guides LLMs to more reliable multi-step reasoning with lower compute cost than global search methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
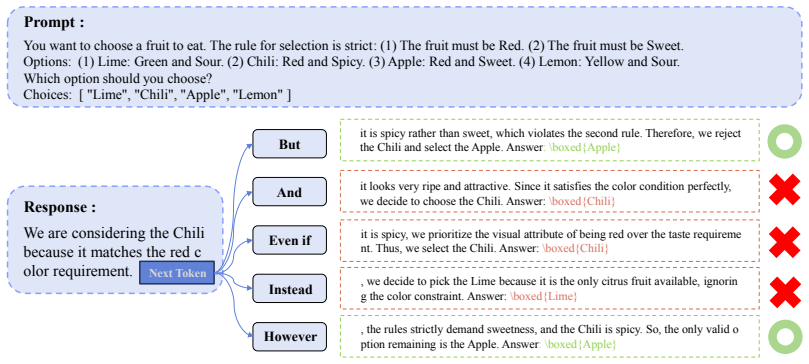
Logical connectives act as high-entropy forking points in reasoning chains where models frequently select incorrect logical directions. A multi-layered intervention framework addresses this by applying gradient-based logical steering to shift internal representations toward valid subspaces, localized branching to resolve ambiguity through limited look-ahead, and targeted transition preference optimization to refine single-token choices at logical pivots, thereby reducing error propagation and improving overall chain correctness.
What carries the argument
Logical connectives as high-entropy forking points, handled by a three-component intervention framework of gradient-based steering, localized branching, and surgical single-token preference optimization.
If this is right
- Error propagation through multi-step deduction can be limited by correcting decisions only at connective transitions.
- The framework yields a better accuracy-efficiency balance than beam search or self-consistency by avoiding full-path exploration.
- Single-token preference optimization at pivots is sufficient to steer models into valid reasoning subspaces.
- Ambiguities at logic-critical points can be resolved with limited look-ahead rather than exhaustive search.
Where Pith is reading between the lines
- Reasoning fragility appears localized at specific token types rather than distributed uniformly across the chain.
- The same targeted-intervention logic could be tested on other high-uncertainty tokens beyond connectives.
- Dynamic detection of forking points during generation might allow adaptive, on-the-fly corrections without pre-defined rules.
Load-bearing premise
Logical connectives are the primary locations where models choose wrong logical directions, and fixing choices there will improve the full chain without creating new errors or instabilities at other steps.
What would settle it
Experiments that apply the interventions at logical connectives yet show no gain in final accuracy or an increase in downstream errors relative to baseline or global scaling methods.
Figures







read the original abstract
While LLMs demonstrate impressive reasoning capabilities, they remain fragile in multi-step logical deduction, where a single transition error can propagate through the entire reasoning chain, leading to unstable performance. In this work, we identify logical connectives as primary points of this structural fragility. Through empirical analysis, we show that connective tokens function as high entropy forking points, at which models frequently struggle to determine the correct logical direction. Motivated by this observation, we hypothesize that intervening in logical connective selection can guide LLMs toward more correct logical direction, thereby improving the overall reasoning chain. To validate this hypothesis, we propose a multi-layered framework that intervenes specifically at these logic-critical junctions in the reasoning process. Our framework includes (1) Gradient-based Logical Steering to guide LLMs internal representations towards valid reasoning subspaces, (2) Localized Branching to resolve ambiguity via targeted look-ahead search, and (3) Targeted Transition Preference Optimization, a surgical reinforcement learning objective that selectively optimizes single-token preferences at logical pivots. Crucially, by concentrating intervention solely on logic-critical transitions, our framework achieves a favorable accuracy--efficiency trade-off compared to global inference time scaling methods like beam search and self-consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies logical connectives as primary fragility points in LLM multi-step reasoning chains, arguing they function as high-entropy forking points where models struggle to select correct logical directions. Motivated by this, it proposes a multi-layered intervention framework consisting of (1) Gradient-based Logical Steering to guide internal representations, (2) Localized Branching for targeted look-ahead, and (3) Targeted Transition Preference Optimization for surgical RL at single-token pivots. The central claim is that concentrating interventions at these logic-critical transitions yields a superior accuracy-efficiency trade-off relative to global inference-time scaling methods such as beam search and self-consistency.
Significance. If the empirical identification of connectives as load-bearing fragility points and the effectiveness of the targeted interventions are validated, the work could advance more efficient and reliable multi-step logical deduction in LLMs by avoiding the overhead of exhaustive global search while mitigating error propagation. This localized approach, if shown to be robust, would represent a practical alternative to scaling inference compute.
major comments (2)
- Abstract: The manuscript describes an empirical analysis identifying logical connectives as high-entropy forking points and presents the framework as validated, yet provides no quantitative results, datasets, performance metrics, error analysis, or ablation studies to support the accuracy-efficiency trade-off claim or the hypothesis that targeted interventions improve the full chain without new instabilities.
- Framework (components 1-3): The description of Gradient-based Logical Steering, Localized Branching, and Targeted Transition Preference Optimization does not include concrete implementation details, hyperparameter choices, or evidence that these localized changes do not introduce offsetting errors or instabilities elsewhere in the reasoning chain, which is load-bearing for the central claim.
minor comments (2)
- Provide explicit examples of logical connectives (e.g., 'and', 'or', 'if-then') and their token-level entropy measurements early in the paper to ground the 'high-entropy forking points' observation.
- Clarify the precise objective function and loss formulation for 'Targeted Transition Preference Optimization' to distinguish it from standard RLHF or DPO.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify how to strengthen the presentation of our work. We respond to each major comment below and have made revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: Abstract: The manuscript describes an empirical analysis identifying logical connectives as high-entropy forking points and presents the framework as validated, yet provides no quantitative results, datasets, performance metrics, error analysis, or ablation studies to support the accuracy-efficiency trade-off claim or the hypothesis that targeted interventions improve the full chain without new instabilities.
Authors: The abstract serves as a concise overview of the core hypothesis and framework. The full manuscript contains dedicated Experimental Setup, Results, and Analysis sections that report quantitative evaluations on standard logical reasoning benchmarks, direct comparisons of accuracy and inference efficiency against beam search and self-consistency, error propagation analysis, and component-wise ablations. To address the concern, we have revised the abstract to include key quantitative highlights from these sections, such as the observed accuracy gains and efficiency improvements. revision: yes
-
Referee: Framework (components 1-3): The description of Gradient-based Logical Steering, Localized Branching, and Targeted Transition Preference Optimization does not include concrete implementation details, hyperparameter choices, or evidence that these localized changes do not introduce offsetting errors or instabilities elsewhere in the reasoning chain, which is load-bearing for the central claim.
Authors: The Methodology section provides the mathematical formulations and high-level procedures for the three components. We acknowledge that additional specificity would improve clarity and have expanded this section with concrete implementation details, including hyperparameter settings (steering vector magnitudes, branching depth and width, preference optimization learning rate and regularization), algorithmic pseudocode, and supporting experimental evidence from our stability and ablation studies showing that the localized interventions at connectives do not create new instabilities or error propagation in the remainder of the chain. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central contribution is an empirical observation that logical connectives act as high-entropy forking points, followed by a descriptive proposal for targeted interventions (gradient steering, localized branching, and targeted RL). No equations, derivations, fitted parameters, or first-principles claims are present that could reduce to their own inputs by construction. The framework is motivated directly by the stated observation and evaluated against external baselines such as beam search; no self-citation chain, ansatz smuggling, or renaming of known results is used to justify the core hypothesis. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs possess internal representations that can be influenced toward valid reasoning subspaces via gradient-based methods
- ad hoc to paper Targeted intervention at logical connectives is sufficient to prevent error propagation through the full reasoning chain
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2205.09712 , year=
Selection-inference: Exploiting large language models for interpretable logical reasoning.arXiv preprint arXiv:2205.09712. Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. 2025. Deep think with confidence.arXiv preprint arXiv:2508.15260. Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhu- rina, Jean M...
-
[2]
Zebralogic: On the scaling limits of llms for logical reasoning.arXiv preprint arXiv:2502.01100,
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. 2025. Zebralogic: On the scaling limits of llms for logical reasoning.arXiv preprint arXiv:2502.01100. Zicheng Lin, Tian Liang, Jiahao Xu, Qiuzhi ...
-
[3]
Lachlan McGinness and Peter Baumgartner
Code to think, think to code: A survey on code-enhanced reasoning and reasoning-driven code intelligence in llms. Lachlan McGinness and Peter Baumgartner. 2024. Automated theorem provers help improve large language model reasoning.arXiv preprint arXiv:2408.03492. Liangming Pan, Alon Albalak, Xinyi Wang, and William Wang. 2023. Logic-lm: Empowering large l...
-
[4]
Steering llama 2 via contrastive activation addition, 2024. 3. Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. 2024. Steer- ing llama 2 via contrastive activation addition. In Proceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (V olume 1: Long Papers), pages 15504–15522. Livi...
-
[6]
Select the answer in the format'/boxed{ ANSWER}'. for example, if the answer is option A, the output should be'/boxed{A}' Logical Relations Relation Connectives Conjunction as well as, as well, also, separately Alternative either, instead, alternatively, else, neither Restatement specifically, particularly, in particular, besides, additionally, in additio...
-
[8]
for example, if the answer is option A, the output should be'/boxed{A}' [User Prompt] # Hypothesis: [hypothesis] # Question: [question] # Options: A
Select the answer in the format'/boxed{ ANSWER}'. for example, if the answer is option A, the output should be'/boxed{A}' [User Prompt] # Hypothesis: [hypothesis] # Question: [question] # Options: A. not-entailment B. entailment Think step by step. Figure 8: Logi QA 2.0 prompt template D.3 ProntoQA ProntoQA Prompt [System Instruction] You are an expert in...
-
[10]
Output the answer in the format'/boxed {}'ANSWER is one of /boxed{A}, /boxed{B} [User Prompt] # Context: [context] # Question: [question] # Options: A. True B. False Think step by step. Figure 9: ProntoQA prompt template D.4 ZebraLogic ZebraLogic Prompt [System Instruction] You are an expert at solving puzzle problems. Follow these rules strictly:
-
[11]
Solve and think step by step
-
[12]
Do not explain anything else
-
[13]
Eric", "Bob
Give the final answer only inside /boxed {}. - Example : # Puzzle ... # Question ... # Choices [ "Eric", "Bob", "Alice", "Peter", "Carol", "Arnold" ] - Answer example # Reasoning ... # Answer /boxed{Bob} [User Prompt] # Puzzle [puzzle] # Question [question] # Choices [choices] Think step by step. Figure 10: ZebraLogic prompt template D.5 BIG-Bench Hard (d...
-
[14]
Reasoning step by step
-
[15]
for example, if the answer is option A, the output should be'/boxed{A}' [User Prompt] # Context: [context] # Question: [question] # Choices: [choices] Think step by step
Select the answer in the format'/boxed{ ANSWER}'. for example, if the answer is option A, the output should be'/boxed{A}' [User Prompt] # Context: [context] # Question: [question] # Choices: [choices] Think step by step. Figure 11: Big Bench Hard (deductive subset) prompt template E Efficiency Comparison We report an efficiency comparison between decod- i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.