Recognition: unknown
Where are they looking in the operating room?
Pith reviewed 2026-05-10 00:38 UTC · model grok-4.3
The pith
Gaze heatmaps alone can predict clinical roles and surgical phases in operating room videos with F1 scores of 0.92 and 0.95.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
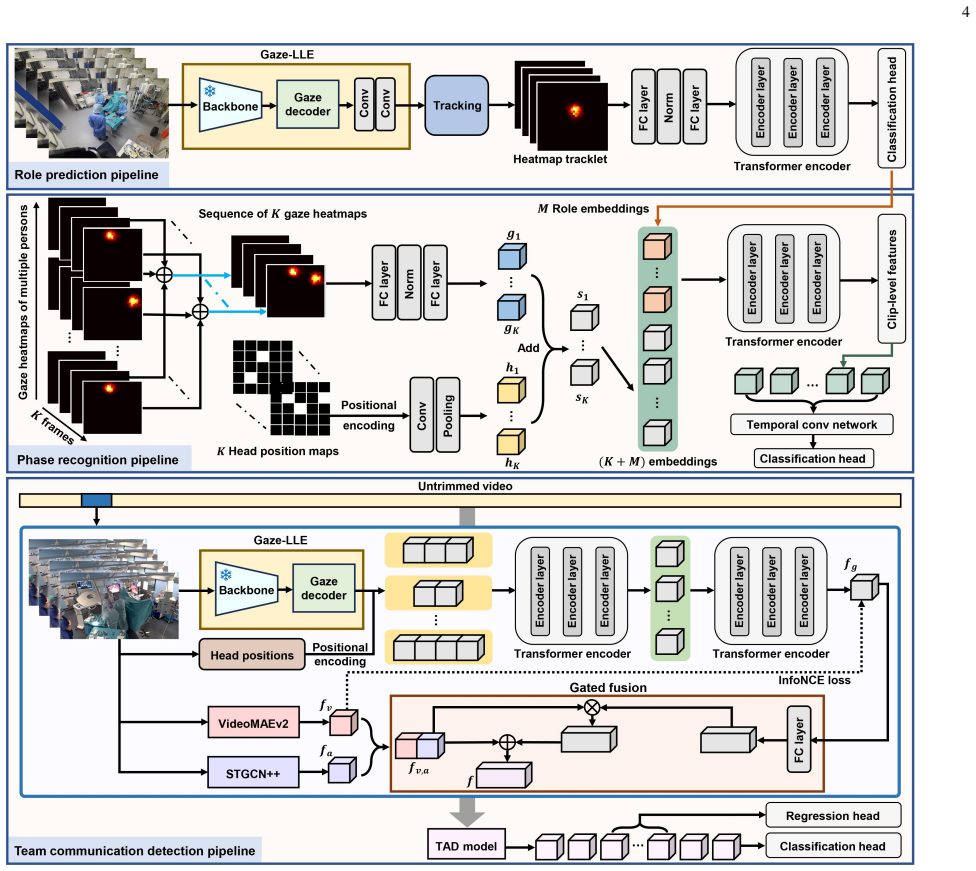
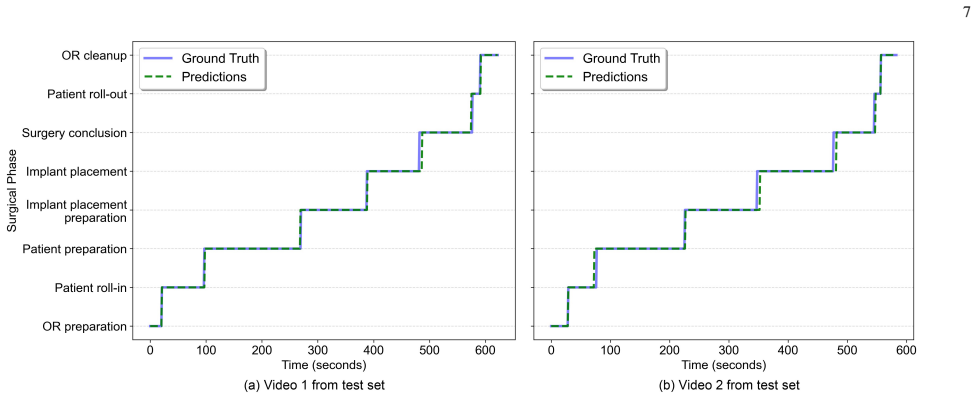
We introduce gaze-following to the surgical domain by extending the 4D-OR dataset with gaze annotations and the Team-OR dataset with both gaze and team communication annotations. For clinical role prediction and surgical phase recognition we use a gaze heatmap approach that relies solely on the predicted gaze locations; for team communication detection we train a spatial-temporal model in a self-supervised manner on gaze-based clip features before feeding them to a temporal activity detector. Experiments on the two datasets show state-of-the-art performance, with F1 scores of 0.92 for role prediction and 0.95 for phase recognition, plus more than 30 percent improvement on communication tasks
What carries the argument
Gaze heatmaps generated by a gaze-following model that are used directly as input for role and phase classifiers, combined with self-supervised spatial-temporal encoding of gaze features for communication detection.
If this is right
- Clinical role prediction becomes possible from gaze information without additional visual or motion cues.
- Surgical phase recognition reaches 0.95 F1 score using only predicted gaze heatmaps.
- Team communication detection improves by over 30 percent relative to previous best methods.
- Gaze-following becomes a viable new direction for surgical workflow analysis in computer-assisted interventions.
Where Pith is reading between the lines
- Post-operative review of attention patterns could help train surgical teams on communication lapses.
- Real-time gaze monitoring might enable automated alerts when attention drifts during critical steps.
- The self-supervised gaze encoding could lower labeling costs for activity detection in other video domains.
- Similar gains might appear in other high-stakes team environments such as trauma bays or control rooms.
Load-bearing premise
The gaze predictions are accurate enough that heatmaps alone suffice for role and phase recognition, and the newly added gaze and communication annotations are reliable and unbiased enough to support the reported performance gains.
What would settle it
A new set of operating room videos recorded with independent eye-tracking hardware, where the reported F1 scores for role and phase prediction drop below 0.85 or the communication detection gains fall below 20 percent.
Figures



read the original abstract
Purpose: Gaze-following, the task of inferring where individuals are looking, has been widely studied in computer vision, advancing research in visual attention modeling, social scene understanding, and human-robot interaction. However, gaze-following has never been explored in the operating room (OR), a complex, high-stakes environment where visual attention plays an important role in surgical workflow analysis. In this work, we introduce the concept of gaze-following to the surgical domain, and demonstrate its great potential for understanding clinical roles, surgical phases, and team communications in the OR. Methods: We extend the 4D-OR dataset with gaze-following annotations, and extend the Team-OR dataset with gaze-following and a new team communication activity annotations. Then, we propose novel approaches to address clinical role prediction, surgical phase recognition, and team communication detection using a gaze-following model. For role and phase recognition, we propose a gaze heatmap-based approach that uses gaze predictions solely; for team communication detection, we train a spatial-temporal model in a self-supervised way that encodes gaze-based clip features, and then feed the features into a temporal activity detection model. Results: Experimental results on the 4D-OR and Team-OR datasets demonstrate that our approach achieves state-of-the-art performance on all downstream tasks. Quantitatively, our approach obtains F1 scores of 0.92 for clinical role prediction and 0.95 for surgical phase recognition. Furthermore, it significantly outperforms existing baselines in team communication detection, improving previous best performances by over 30%. Conclusion: We introduce gaze-following in the OR as a novel research direction in surgical data science, highlighting its great potential to advance surgical workflow analysis in computer-assisted interventions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces gaze-following to the operating room (OR) for surgical workflow analysis. It extends the 4D-OR dataset with gaze annotations and the Team-OR dataset with gaze and new team communication annotations. The authors propose a gaze heatmap-based method for clinical role prediction and surgical phase recognition, plus a self-supervised spatial-temporal model that encodes gaze-based clip features for team communication detection. Experimental results claim state-of-the-art performance, with F1 scores of 0.92 for role prediction and 0.95 for phase recognition, plus over 30% improvement on communication detection over baselines.
Significance. If the results hold after verification of the prerequisites, the work opens a new direction in surgical data science by showing how inferred gaze can support automated analysis of roles, phases, and communications in high-stakes OR settings. The quantitative gains on extended datasets suggest utility for computer-assisted interventions, with the self-supervised feature encoding for communication being a potentially reusable contribution.
major comments (2)
- [Abstract] Abstract: The reported F1 scores of 0.92 (role) and 0.95 (phase) and the >30% gain on communication detection are produced by feeding gaze heatmaps or gaze-derived features directly into the downstream models, yet no quantitative metrics for the underlying gaze-following network (e.g., AUC, angular error, or success rate at 10° threshold) are supplied on the extended 4D-OR or Team-OR data; without these, the downstream SOTA claims cannot be attributed to accurate gaze predictions.
- [Dataset extension and annotation sections] Dataset extension and annotation sections: The newly added gaze and communication labels on 4D-OR and Team-OR are used as ground truth for all reported results, but no inter-annotator agreement statistics, annotation guidelines, or validation splits are described; if annotator consistency is low, the performance numbers and the claimed improvements become unreliable.
minor comments (1)
- [Abstract] Abstract: The phrase 'significantly outperforms existing baselines' would be clearer if the specific prior best F1 or mAP values were stated alongside the >30% relative improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit validation of the gaze-following component and the annotation process. We address each major comment below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported F1 scores of 0.92 (role) and 0.95 (phase) and the >30% gain on communication detection are produced by feeding gaze heatmaps or gaze-derived features directly into the downstream models, yet no quantitative metrics for the underlying gaze-following network (e.g., AUC, angular error, or success rate at 10° threshold) are supplied on the extended 4D-OR or Team-OR data; without these, the downstream SOTA claims cannot be attributed to accurate gaze predictions.
Authors: We agree that reporting standalone gaze-following metrics on the extended datasets is necessary to fully attribute the downstream gains to accurate gaze predictions rather than other factors. The original manuscript emphasized the novel OR applications and reused a gaze-following backbone whose performance had been established on prior benchmarks; however, we did not include per-dataset evaluation for the extended 4D-OR and Team-OR splits. In the revision we will add a dedicated subsection with quantitative gaze results (AUC, mean angular error, and success rate at 10° threshold) computed on the new annotations, allowing readers to directly assess the quality of the heatmaps and features fed into the role, phase, and communication models. revision: yes
-
Referee: [Dataset extension and annotation sections] Dataset extension and annotation sections: The newly added gaze and communication labels on 4D-OR and Team-OR are used as ground truth for all reported results, but no inter-annotator agreement statistics, annotation guidelines, or validation splits are described; if annotator consistency is low, the performance numbers and the claimed improvements become unreliable.
Authors: We recognize that explicit documentation of the annotation protocol and reliability measures is required for reproducibility and to support the claimed performance. The gaze and communication labels were collected by multiple trained annotators using a standardized protocol that defines gaze targets relative to surgical instruments, anatomy, and team members, as well as communication event boundaries. We will expand the dataset sections to include the full annotation guidelines, describe the train/validation/test splits used for all experiments, and report inter-annotator agreement (e.g., Cohen’s kappa or percentage agreement) computed on a held-out subset of frames. These additions will be placed in the revised manuscript and supplementary material. revision: yes
Circularity Check
No circularity: empirical results on extended annotated datasets
full rationale
The paper's core claims rest on dataset extensions (adding gaze and communication annotations to 4D-OR and Team-OR) followed by standard ML pipelines that feed gaze heatmaps or gaze-derived features into downstream classifiers and temporal models. Reported F1 scores (0.92 role, 0.95 phase) and >30% gains are measured against ground-truth labels on these datasets; no equations, self-citations, or fitted parameters are shown to reduce the outputs to the inputs by construction. The derivation chain is therefore self-contained and externally falsifiable via the new annotations.
Axiom & Free-Parameter Ledger
free parameters (2)
- gaze-following model parameters
- heatmap generation thresholds
axioms (2)
- domain assumption Gaze location alone is a sufficient signal for clinical role and surgical phase inference
- domain assumption Self-supervised gaze features capture team communication activity
Reference graph
Works this paper leans on
-
[1]
What do surgeons see: capturing and synchronizing eye gaze for surgery applications
Atkins, M.S., Tien, G., Khan, R.S., Meneghetti, A., Zheng, B., 2013. What do surgeons see: capturing and synchronizing eye gaze for surgery applications. Surgical innovation 20, 241–248. doi:10.1177/ 1553350612449075
2013
-
[2]
Bhavsar, P., Srinivasan, B., Srinivasan, R., 2017. Quantifying situ- ation awareness of control room operators using eye-gaze behavior. 8 Computers & chemical engineering 106, 191–201. doi:10.1016/j. compchemeng.2017.06.004
work page doi:10.1016/j 2017
-
[3]
Auditory display as feedback for a novel eye-tracking system for sterile operating room interaction
Black, D., Unger, M., Fischer, N., Kikinis, R., Hahn, H., Neumuth, T., Glaser, B., 2018. Auditory display as feedback for a novel eye-tracking system for sterile operating room interaction. International journal of computer assisted radiology and surgery 13, 37–45. doi:10.1007/ s11548-017-1677-3
2018
-
[4]
Synchronizing eye tracking and optical motion capture: How to bring them together
Burger, B., Puupponen, A., Jantunen, T., 2018. Synchronizing eye tracking and optical motion capture: How to bring them together. Jour- nal of eye movement research 11, 10–16910. doi:10.16910/jemr.11. 2.5
-
[5]
End-to-End Object Detection with Transformers , volume =
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S., 2020. End-to-end object detection with transformers, in: European conference on computer vision, Springer. pp. 213–229. doi:10.1007/978-3-030-58452-8_13
-
[6]
Chen, K., Schewski, L., Srivastav, V ., Lavanchy, J., Mutter, D., Beldi, G., Keller, S., Padoy, N., 2025. When do they stop?: A first step toward automatically identifying team communication in the operating room. International journal of computer assisted radiology and surgery , 1– 9doi:10.1007/s11548-025-03393-2
-
[7]
Chong, E., Ruiz, N., Wang, Y ., Zhang, Y ., Rozga, A., Rehg, J.M., 2018. Connecting gaze, scene, and attention: Generalized attention estimation via joint modeling of gaze and scene saliency, in: Proceedings of the European conference on computer vision, pp. 383–398. doi:10.1007/ 978-3-030-01228-1_24
2018
-
[8]
Chong, E., Wang, Y ., Ruiz, N., Rehg, J.M., 2020. Detecting attended visual targets in video, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5396–5406. doi:10.1109/ CVPR42600.2020.00544
-
[9]
Duan, H., Wang, J., Chen, K., Lin, D., 2022. Pyskl: Towards good practices for skeleton action recognition, in: Proceedings of the 30th ACM International Conference on Multimedia, pp. 7351–7354. doi:10. 1145/3503161.3548546
-
[10]
The eyes have it: the neuroethology, function and evolution of social gaze
Emery, N.J., 2000. The eyes have it: the neuroethology, function and evolution of social gaze. Neuroscience & biobehavioral reviews 24, 581–604. doi:10.1016/S0149-7634(00)00025-7
-
[11]
Theoretical underpinnings of situation awareness: A critical review, in: Endsley, M.R., Garland, D.J
Endsley, M.R., 2000. Theoretical underpinnings of situation awareness: A critical review, in: Endsley, M.R., Garland, D.J. (Eds.), Situation Awareness Analysis and Measurement. CRC Press, Boca Raton, FL. chapter 1, pp. 3–32. doi:10.1201/b12461
-
[12]
Comparison of gaze behaviour of trainee and experienced surgeons dur- ing laparoscopic gastric bypass
Erridge, S., Ashraf, H., Purkayastha, S., Darzi, A., Sodergren, M., 2018. Comparison of gaze behaviour of trainee and experienced surgeons dur- ing laparoscopic gastric bypass. Journal of British Surgery 105, 287–
2018
-
[13]
doi:10.1002/bjs.10672
-
[14]
Fan, L., Chen, Y ., Wei, P., Wang, W., Zhu, S.C., 2018. Inferring shared attention in social scene videos, in: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pp. 6460–6468. doi:10.1109/CVPR.2018.00676
-
[15]
Fan, L., Wang, W., Huang, S., Tang, X., Zhu, S.C., 2019. Understand- ing human gaze communication by spatio-temporal graph reasoning, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5724–5733. doi:10.1109/ICCV.2019.00582
-
[16]
Farha, Y .A., Gall, J., 2019. Ms-tcn: Multi-stage temporal convolutional network for action segmentation, in: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pp. 3575–3584. doi:10.1109/CVPR.2019.00369
-
[17]
Situation aware- ness in anesthesiology
Gaba, D.M., Howard, S.K., Small, S.D., 1995. Situation aware- ness in anesthesiology. Human factors 37, 20–31. doi:10.1518/ 001872095779049435
1995
-
[18]
Eye-gaze driven surgical workflow segmentation, in: MICCAI, Springer
James, A., Vieira, D., Lo, B., Darzi, A., Yang, G.Z., 2007. Eye-gaze driven surgical workflow segmentation, in: MICCAI, Springer. pp. 110–
2007
-
[19]
doi:10.1007/978-3-540-75759-7_14
-
[20]
Depth-aware gaze-following via auxiliary networks for robotics
Jin, T., Yu, Q., Zhu, S., Lin, Z., Ren, J., Zhou, Y ., Song, W., 2022. Depth-aware gaze-following via auxiliary networks for robotics. En- gineering Applications of Artificial Intelligence 113, 104924. doi:10. 1016/j.engappai.2022.104924
-
[21]
Analysis of eye gaze: do novice surgeons look at the same location as expert surgeons during a laparoscopic operation? Surgical endoscopy 26, 3536–3540
Khan, R.S., Tien, G., Atkins, M.S., Zheng, B., Panton, O.N., Meneghetti, A.T., 2012. Analysis of eye gaze: do novice surgeons look at the same location as expert surgeons during a laparoscopic operation? Surgical endoscopy 26, 3536–3540. doi:10.1007/ s00464-012-2400-7
2012
-
[22]
Mosaic: a web-based plat- form for collaborative medical video assessment and annotation
Mazellier, J.P., Boujon, A., Bour-Lang, M., Erharhd, M., Waechter, J., Wernert, E., Mascagni, P., Padoy, N., 2023. Mosaic: a web-based plat- form for collaborative medical video assessment and annotation. arXiv doi:10.48550/arXiv.2312.08593
-
[23]
Niehorster, D.C., Hessels, R.S., Nyström, M., Benjamins, J.S., Hooge, I.T., 2025. gazemapper: A tool for automated world-based analysis of gaze data from one or multiple wearable eye trackers. Behavior Re- search Methods 57, 188. doi:10.3758/s13428-025-02704-4
-
[24]
Representation Learning with Contrastive Predictive Coding
Oord, A.v.d., Li, Y ., Vinyals, O., 2018. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 doi:10. 48550/arXiv.1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Labrad-or: lightweight memory scene graphs for accurate bimodal rea- soning in dynamic operating rooms, in: MICCAI, Springer
Özsoy, E., Czempiel, T., Holm, F., Pellegrini, C., Navab, N., 2023. Labrad-or: lightweight memory scene graphs for accurate bimodal rea- soning in dynamic operating rooms, in: MICCAI, Springer. pp. 302–
2023
-
[26]
doi:10.1007/978-3-031-43996-4_29
-
[27]
Holistic or domain modeling: a semantic scene graph approach
Özsoy, E., Czempiel, T., Örnek, E.P., Eck, U., Tombari, F., Navab, N., 2024a. Holistic or domain modeling: a semantic scene graph approach. International journal of computer assisted radiology and surgery 19, 791–799. doi:10.1007/s11548-023-03022-w
-
[28]
arXiv preprint arXiv:2505.24287 (2025)
Özsoy, E., Mamur, A., Tristram, F., Pellegrini, C., Wysocki, M., Busam, B., Navab, N., 2025. Egoexor: An ego-exo-centric operat- ing room dataset for surgical activity understanding. arXiv preprint arXiv:2505.24287 doi:10.48550/arXiv.2505.24287
-
[29]
Özsoy, E., Örnek, E.P., Eck, U., Czempiel, T., Tombari, F., Navab, N.,
-
[30]
4d-or: Semantic scene graphs for or domain modeling, in: MIC- CAI, Springer. pp. 475–485. doi:10.1007/978-3-031-16449-1_45
-
[31]
Özsoy, E., Pellegrini, C., Keicher, M., Navab, N., 2024b. Oracle: Large vision-language models for knowledge-guided holistic or do- main modeling, in: International Conference on Medical Image Com- puting and Computer-Assisted Intervention, Springer. pp. 455–465. doi:10.1007/978-3-031-72089-5_43
-
[32]
Where are they looking? Advances in neural information processing systems 28
Recasens, A., Khosla, A., V ondrick, C., Torralba, A., 2015. Where are they looking? Advances in neural information processing systems 28. doi:10.5555/2969239.2969262
-
[33]
Following gaze in video, in: Proceedings of the IEEE International Conference on Computer Vision, pp
Recasens, A., V ondrick, C., Khosla, A., Torralba, A., 2017. Following gaze in video, in: Proceedings of the IEEE International Conference on Computer Vision, pp. 1435–1443. doi:10.1109/ICCV.2017.160
-
[34]
Evaluation of optical tracking to distinguish surgeon expe- rience during endoscopic stone surgery
Reed, A.M., Li, Y ., Atoum, J., Acar, A., Henry, C., Wu, J.Y ., Kavoussi, N., 2024. Evaluation of optical tracking to distinguish surgeon expe- rience during endoscopic stone surgery. Journal of Endourology 38, 1421–1426. doi:10.1089/end.2024.0246
-
[35]
What’s in the image? a deep-dive into the vision of vision language models
Ryan, F., Bati, A., Lee, S., Bolya, D., Hoffman, J., Rehg, J.M., 2025. Gaze-lle: Gaze target estimation via large-scale learned encoders, in: Proceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pp. 28874–28884. doi:10.1109/CVPR52734.2025. 02689
-
[36]
Saran, A., Majumdar, S., Short, E.S., Thomaz, A., Niekum, S., 2018. Human gaze following for human-robot interaction, in: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE. pp. 8615–8621. doi:10.1109/IROS.2018.8593580
-
[37]
Seagull, F.J., Xiao, Y ., MacKenzie, C.F., Jaberi, M., Dutton, R.P., 1999. Monitoring behavior: A pilot study using an ambulatory eye-tracker in surgical operating rooms, in: Proceedings of the Human Factors and Ergonomics Society Annual Meeting, SAGE Publications Sage CA: Los Angeles, CA. pp. 850–854. doi:10.1177/154193129904301503
-
[38]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Shi, D., Zhong, Y ., Cao, Q., Ma, L., Li, J., Tao, D., 2023. Tridet: Temporal action detection with relative boundary modeling, in: Pro- ceedings of the CVPR, pp. 18857–18866. doi:10.1109/CVPR52729. 2023.01808
-
[39]
Temporalmaxer: Maximize temporal context with only max pooling for temporal action localization,
Tang, T.N., Kim, K., Sohn, K., 2023. Temporalmaxer: Maximize tem- poral context with only max pooling for temporal action localization. arXiv preprint arXiv:2303.09055 doi:10.48550/arXiv.2303.09055
-
[40]
Tonini, F., Dall’Asen, N., Beyan, C., Ricci, E., 2023. Object-aware gaze target detection, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 21860–21869. doi:10.1109/ ICCV51070.2023.01998
-
[41]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
Tu, D., Min, X., Duan, H., Guo, G., Zhai, G., Shen, W., 2022. End-to- end human-gaze-target detection with transformers, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, IEEE. pp. 2192–2200. doi:10.1109/CVPR52688.2022.00224
-
[42]
Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y ., Wang, Y ., Wang, Y ., Qiao, Y ., 2023. Videomae v2: Scaling video masked autoen- coders with dual masking, in: Proceedings of the IEEE/CVF confer- 9 ence on computer vision and pattern recognition, pp. 14549–14560. doi:10.1109/CVPR52729.2023.01398
-
[43]
Wei, P., Liu, Y ., Shu, T., Zheng, N., Zhu, S.C., 2018. Where and why are they looking? jointly inferring human attention and intentions in com- plex tasks, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6801–6809. doi:10.1109/CVPR. 2018.00711
-
[44]
Interact as you intend: Intention-driven human-object interaction detection
Xu, B., Li, J., Wong, Y ., Zhao, Q., Kankanhalli, M.S., 2019. Interact as you intend: Intention-driven human-object interaction detection. IEEE Transactions on Multimedia 22, 1423–1432. doi:10.1109/TMM.2019. 2943753
-
[45]
Zhang, C.L., Wu, J., Li, Y ., 2022. Actionformer: Localizing moments of actions with transformers, in: European Conference on Computer Vision, Springer. pp. 492–510. doi:10.1007/978-3-031-19772-7_ 29
-
[46]
Surgeon’s vigilance in the operating room
Zheng, B., Tien, G., Atkins, S.M., Swindells, C., Tanin, H., Meneghetti, A., Qayumi, K.A., Panton, O.N.M., 2011. Surgeon’s vigilance in the operating room. The American journal of surgery 201, 673–677. doi:10.1016/j.amjsurg.2011.01.016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.