Recognition: unknown
Occupancy Reward Shaping: Improving Credit Assignment for Offline Goal-Conditioned Reinforcement Learning
Pith reviewed 2026-05-10 00:15 UTC · model grok-4.3
The pith
Occupancy Reward Shaping uses optimal transport on learned occupancy measures to derive rewards that improve credit assignment in offline goal-conditioned RL while preserving the optimal policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
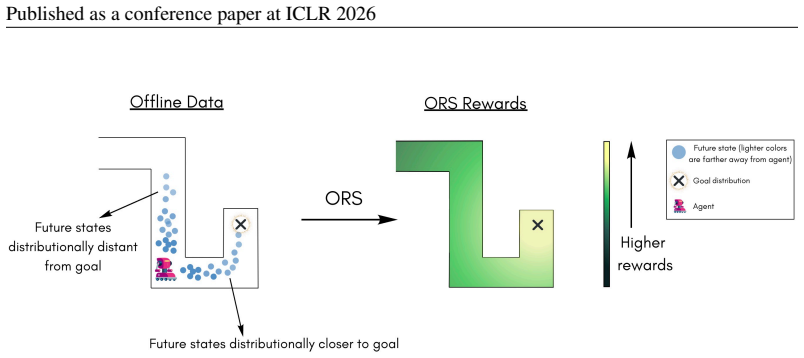
Temporal information stored in generative world models encodes the geometry of the world. This geometry can be extracted from a learned model of the occupancy measure via optimal transport and turned into a reward function that captures goal-reaching information. The resulting Occupancy Reward Shaping method largely mitigates credit assignment in sparse-reward goal-conditioned settings, provably does not alter the optimal policy, and yields large empirical gains on locomotion, manipulation, and real-world control tasks.
What carries the argument
Occupancy Reward Shaping, which computes optimal-transport distances between current-state and goal occupancies to produce shaped rewards that encode goal-reaching geometry.
If this is right
- Performance improves by a factor of 2.2 across 13 diverse long-horizon locomotion and manipulation tasks.
- The approach succeeds on three real-world Tokamak control tasks.
- Credit assignment improves in sparse-reward offline goal-conditioned settings without policy change.
- The shaped reward supplies dense goal-reaching information derived directly from the learned occupancy geometry.
Where Pith is reading between the lines
- ORS could be paired with existing offline RL algorithms to further reduce the data needed for long-horizon goal tasks.
- The same occupancy-to-reward extraction might extend to online settings where a world model is learned alongside the policy.
- Applying the geometry extraction to multi-goal or hierarchical settings could address credit assignment in even more complex environments.
Load-bearing premise
The generative world model must accurately capture the true occupancy measure and its geometry so that the optimal-transport distances supply a useful credit signal.
What would settle it
A demonstration that the shaped reward changes the optimal policy in any Markov decision process, or the absence of performance gains on the 13 long-horizon tasks.
Figures







read the original abstract
The temporal lag between actions and their long-term consequences makes credit assignment a challenge when learning goal-directed behaviors from data. Generative world models capture the distribution of future states an agent may visit, indicating that they have captured temporal information. How can that temporal information be extracted to perform credit assignment? In this paper, we formalize how the temporal information stored in world models encodes the underlying geometry of the world. Leveraging optimal transport, we extract this geometry from a learned model of the occupancy measure into a reward function that captures goal-reaching information. Our resulting method, Occupancy Reward Shaping, largely mitigates the problem of credit assignment in sparse reward settings. ORS provably does not alter the optimal policy, yet empirically improves performance by 2.2x across 13 diverse long-horizon locomotion and manipulation tasks. Moreover, we demonstrate the effectiveness of ORS in the real world for controlling nuclear fusion on 3 Tokamak control tasks. Code: https://github.com/aravindvenu7/occupancy_reward_shaping; Website: https://aravindvenu7.github.io/website/ors/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Occupancy Reward Shaping (ORS) for offline goal-conditioned RL. It extracts a dense reward signal by applying optimal transport to the occupancy measure learned by a generative world model, aiming to improve credit assignment in sparse-reward, long-horizon settings. The central claims are that ORS is provably policy-invariant and yields a 2.2x average performance gain across 13 locomotion and manipulation tasks, with additional validation on three real-world Tokamak control problems.
Significance. If the invariance result holds under the approximate occupancy measures that arise from finite offline data, the method offers a principled route to reward shaping that leverages world-model geometry without changing the optimal policy. The work is strengthened by the release of code, evaluation on a diverse set of long-horizon tasks, and real-world demonstration on nuclear-fusion control.
major comments (2)
- [§3] §3 (Theoretical Analysis), invariance theorem: the proof that the shaping term is potential-based (and therefore policy-preserving) is stated with respect to the true occupancy measure. The manuscript does not supply an error bound or limiting argument showing that the same invariance continues to hold when the occupancy is replaced by its estimate from a generative model trained on finite data; this gap directly affects the central claim for practical long-horizon regimes.
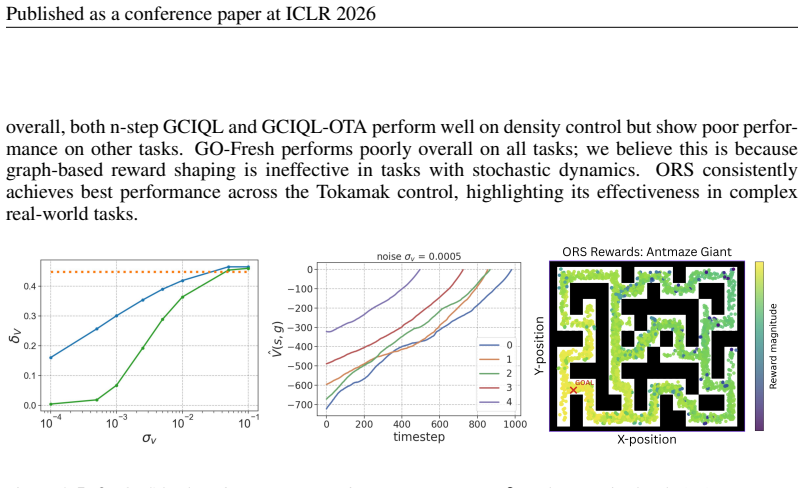
- [§4.2] §4.2 (Experimental Setup) and Table 2: the reported 2.2× aggregate improvement is presented without per-task standard deviations, number of seeds, or statistical tests. In addition, no ablation isolates the contribution of the learned occupancy accuracy versus the OT distance itself, leaving open whether the gains are robust when the world model deviates from the true measure.
minor comments (2)
- [Abstract] The abstract asserts invariance without qualifying that it holds for the exact occupancy; a brief parenthetical noting the modeling assumption would improve clarity.
- [§2] Notation for the learned versus true occupancy measure (e.g., μ̂ vs. μ) should be introduced once and used consistently in the derivation and experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying our position and committing to specific revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: §3 (Theoretical Analysis), invariance theorem: the proof that the shaping term is potential-based (and therefore policy-preserving) is stated with respect to the true occupancy measure. The manuscript does not supply an error bound or limiting argument showing that the same invariance continues to hold when the occupancy is replaced by its estimate from a generative model trained on finite data; this gap directly affects the central claim for practical long-horizon regimes.
Authors: We agree that Theorem 1 is stated for the exact occupancy measure, where the shaping term is rigorously shown to be potential-based and thus policy-invariant. For the approximate occupancy obtained from a generative world model on finite data, the manuscript does not derive an explicit error bound. However, because the world-model training objective minimizes a divergence to the true occupancy and the optimal transport cost is continuous in the weak topology, the induced reward perturbation remains small when the model is sufficiently accurate. This is consistent with the strong empirical results on long-horizon tasks. In the revision we will add a short discussion subsection after Theorem 1 that (i) states the approximation assumption explicitly and (ii) sketches a Lipschitz-based bound on the difference between the shaped value functions under bounded occupancy error, thereby clarifying the practical scope of the invariance result. revision: partial
-
Referee: §4.2 (Experimental Setup) and Table 2: the reported 2.2× aggregate improvement is presented without per-task standard deviations, number of seeds, or statistical tests. In addition, no ablation isolates the contribution of the learned occupancy accuracy versus the OT distance itself, leaving open whether the gains are robust when the world model deviates from the true measure.
Authors: We accept that the current experimental reporting lacks statistical detail. The 2.2× figure was obtained by averaging over 5 independent random seeds per task; we will update Table 2 to report per-task means and standard deviations, add a footnote specifying the seed count, and include paired t-test p-values against the strongest baseline. To isolate the effect of occupancy accuracy, we will insert a new ablation subsection (4.3) that retrains the world model on progressively smaller fractions of the offline dataset (10 %, 25 %, 50 %, 100 %) while keeping the OT shaping fixed, and reports the resulting performance degradation. This directly quantifies robustness to model error and addresses the concern about confounding the occupancy estimate with the OT mechanism. revision: yes
Circularity Check
No significant circularity in derivation of policy invariance or reward construction
full rationale
The paper constructs a dense reward via optimal transport on the occupancy measure of a learned generative world model and claims policy invariance. This follows from applying the standard potential-based reward shaping theorem (independent of the paper) to the resulting term; the derivation does not reduce by the paper's own equations to a fitted parameter renamed as prediction, a self-definition, or a load-bearing self-citation. The empirical 2.2x gains are presented as separate validation rather than part of the proof chain. The method remains self-contained against external benchmarks of reward shaping theory.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The generative world model accurately approximates the true occupancy measure.
- ad hoc to paper Optimal transport distance on occupancy measures corresponds to useful goal-reaching credit.
Reference graph
Works this paper leans on
-
[1]
Option-aware temporally abstracted value for offline goal-conditioned reinforcement learning
Hongjoon Ahn, Heewoong Choi, Jisu Han, and Taesup Moon. Option-aware temporally abstracted value for offline goal-conditioned reinforcement learning.arXiv preprint arXiv:2505.12737,
-
[2]
Ian Char, Youngseog Chung, Joseph Abbate, Egemen Kolemen, and Jeff Schneider. Full shot pre- dictions for the diii-d tokamak via deep recurrent networks.arXiv preprint arXiv:2404.12416,
-
[3]
arXiv preprint arXiv:2503.09817 , year=
11 Published as a conference paper at ICLR 2026 Jesse Farebrother, Matteo Pirotta, Andrea Tirinzoni, R´emi Munos, Alessandro Lazaric, and Ahmed Touati. Temporal difference flows.arXiv preprint arXiv:2503.09817,
-
[4]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review arXiv 2004
-
[6]
arXiv preprint arXiv:1907.08225 , year=
URLhttps://arxiv. org/abs/1907.08225. Anna Harutyunyan, Sam Devlin, Peter Vrancx, and Ann Now ´e. Expressing arbitrary reward func- tions as potential-based advice. InProceedings of the AAAI conference on artificial intelligence, volume 29,
-
[7]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415,
-
[8]
Michael Janner, Igor Mordatch, and Sergey Levine. Gamma-models: Generative temporal difference learning for infinite-horizon prediction.Advances in neural information processing systems, 33: 1724–1735, 2020a. Michael Janner, Igor Mordatch, and Sergey Levine. Generative temporal difference learning for infinite-horizon prediction.arXiv preprint arXiv:2010....
-
[9]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q- learning.arXiv preprint arXiv:2110.06169,
work page internal anchor Pith review arXiv
-
[11]
Automatic reward shaping from confounded offline data.arXiv preprint arXiv:2505.11478, 2025
Mingxuan Li, Junzhe Zhang, and Elias Bareinboim. Automatic reward shaping from confounded offline data.arXiv preprint arXiv:2505.11478,
-
[12]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky TQ Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code.arXiv preprint arXiv:2412.06264,
work page internal anchor Pith review arXiv
-
[14]
Goal-conditioned re- inforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299,
12 Published as a conference paper at ICLR 2026 Minghuan Liu, Menghui Zhu, and Weinan Zhang. Goal-conditioned reinforcement learning: Prob- lems and solutions.arXiv preprint arXiv:2201.08299, 2022a. Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003...
-
[15]
Haozhe Ma, Zhengding Luo, Thanh Vinh V o, Kuankuan Sima, and Tze-Yun Leong. Highly efficient self-adaptive reward shaping for reinforcement learning.arXiv preprint arXiv:2408.03029,
-
[16]
Learning to shape rewards using a game of switching controls.arXiv preprint arXiv:2103.09159,
David Mguni, Jianhong Wang, Taher Jafferjee, Nicolas Perez-Nieves, Wenbin Song, Yaodong Yang, Feifei Tong, Hui Chen, Jiangcheng Zhu, Yali Du, et al. Learning to shape rewards using a game of switching controls.arXiv preprint arXiv:2103.09159,
-
[17]
Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092,
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092, 2024a. Seohong Park, Kevin Frans, Sergey Levine, and Aviral Kumar. Is value learning really the main bottleneck in offline rl?Advances in Neural Information Processing Systems, 37:79029–79056, 2024b. Seohong ...
-
[18]
13 Published as a conference paper at ICLR 2026 Alfredo Reichlin, Miguel Vasco, Hang Yin, and Danica Kragic. Learning goal-conditioned policies from sub-optimal offline data via metric learning.arXiv preprint arXiv:2402.10820,
-
[19]
arXiv preprint arXiv:1803.00653 , year=
Nikolay Savinov, Alexey Dosovitskiy, and Vladlen Koltun. Semi-parametric topological memory for navigation.arXiv preprint arXiv:1803.00653,
-
[20]
Bellman diffusion models.arXiv preprint arXiv:2407.12163,
Liam Schramm and Abdeslam Boularias. Bellman diffusion models.arXiv preprint arXiv:2407.12163,
-
[21]
arXiv preprint arXiv:2302.08560 , year=
Harshit Sikchi, Rohan Chitnis, Ahmed Touati, Alborz Geramifard, Amy Zhang, and Scott Niekum. Score models for offline goal-conditioned reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2023a. Harshit Sikchi, Qinqing Zheng, Amy Zhang, and Scott Niekum. Dual rl: Unification and new methods for reinforcement and imit...
-
[22]
arXiv preprint arXiv:2202.04478 , year=
Tongzhou Wang, Antonio Torralba, Phillip Isola, and Amy Zhang. Optimal goal-reaching reinforce- ment learning via quasimetric learning. InInternational Conference on Machine Learning, pp. 36411–36430. PMLR, 2023a. Yiming Wang, Ming Yang, Renzhi Dong, Binbin Sun, Furui Liu, et al. Efficient potential-based exploration in reinforcement learning using invers...
-
[23]
Reward models in deep reinforcement learning: A survey.arXiv preprint arXiv:2506.15421, 2025
Rui Yu, Shenghua Wan, Yucen Wang, Chen-Xiao Gao, Le Gan, Zongzhang Zhang, and De- Chuan Zhan. Reward models in deep reinforcement learning: A survey.arXiv preprint arXiv:2506.15421,
-
[24]
Contrastive difference predictive coding, 2025
Chongyi Zheng, Ruslan Salakhutdinov, and Benjamin Eysenbach. Contrastive difference predictive coding.arXiv preprint arXiv:2310.20141,
-
[25]
Can a MISL fly? analysis and ingredients for mutual information skill learning,
Chongyi Zheng, Jens Tuyls, Joanne Peng, and Benjamin Eysenbach. Can a misl fly? analysis and ingredients for mutual information skill learning.arXiv preprint arXiv:2412.08021,
-
[26]
Flattening hierarchies with policy bootstrapping.arXiv preprint arXiv:2505.14975,
John L Zhou and Jonathan C Kao. Flattening hierarchies with policy bootstrapping.arXiv preprint arXiv:2505.14975,
-
[27]
14 Published as a conference paper at ICLR 2026 Appendices A PROOFS We introduce notation in Sec. A.1. We then provide common setup used for all proofs in Sec. A.2. We introduce the assumptions used in Sec. A.3. Sec. A.4, A.5 and A.6 provide the proofs for Proposition1, Proposition2 and Theorem1, respectively. A.1 NOTATION •Shortest-path distance: We use ...
2026
-
[28]
Moreover, for any state–goal pair(s, g), the squared Wasserstein-2 distance is minimized by the optimal action: W 2 2 δg, dπD(s+ |s, a ∗) ≤W 2 2 δg, dπD(s+ |s, a) ,∀a∈ A, a ∗ ∼π ∗(· |s, g). We prove the proposition in two parts: We first prove that the averageW 2 2 distance is monotoni- cally decreasing in shortest-path distance to goal and then show that...
2026
-
[29]
2 2,(6) 18 Published as a conference paper at ICLR 2026 wherex t =tx 1 + (1−t)x
2026
-
[30]
We start from the definition of squared Wasserstein-2 distance in Sec
We note thatx 1 −x 0 gives us the velocity at(x 0, x1), wherex 1 =g. We start from the definition of squared Wasserstein-2 distance in Sec. A.2. In our case,µcorresponds toδ g andνcorresponds tod πD θ (s+ |s, a). Asµ=δ g, a point mass centered atg, the transport plan is uniquely determined to be the product measureλ(x, s +) =δ g(x)dπD θ (s+ |s, a)(Sec. A....
2025
-
[31]
2 2 i (7) A.6 OPTIMALITY OFORSPOLICY(PROOF OF THEOREM1) Theorem.Under suitable assumptions on goal reachability, dynamics, and dataset coverage, the greedy goal-conditioned policy: πgreedy(a|s, g) = arg max a∈A Q∗(s, a, g), whereQ ∗(s, a, g)denotes the optimal action-value function induced by the rewardr W (s, a, g), coincides with the optimal shortest-pa...
2026
-
[32]
So we can lower bound the entire difference: V π∗ W (s1, g)−V π∗ W (s2, g)≥γ k−1 ·0 + k−2X t=0 γt(1−γ)∆ Φ = (1−γ)∆ Φ k−2X t=0 γt = (1−γ)∆ Φ 1−γ k−1 1−γ = (1−γ k−1)∆Φ
We knowM πD ≥0. So we can lower bound the entire difference: V π∗ W (s1, g)−V π∗ W (s2, g)≥γ k−1 ·0 + k−2X t=0 γt(1−γ)∆ Φ = (1−γ)∆ Φ k−2X t=0 γt = (1−γ)∆ Φ 1−γ k−1 1−γ = (1−γ k−1)∆Φ. Sincek≥1andγ∈(0,1), the term(1−γ k−1)is strictly positive. As∆ Φ >0, the entire lower bound is strictly positive. This completes the proof. Theorem A.1(Equivalence of the Q-l...
2026
-
[33]
Both antmaze-large-navigateandantmaze-giant-navigateare collected with noisy expert SAC policies that repeatedly move towards randomly sampled goals (Park et al., 2024a)
designed to substantially challenge long-horizon planning capabilities. Both antmaze-large-navigateandantmaze-giant-navigateare collected with noisy expert SAC policies that repeatedly move towards randomly sampled goals (Park et al., 2024a). antmaze-large-explorefeatures extremely low quality yet high coverage data consisting of random exploratory trajec...
2026
-
[34]
We use a dataset of raw sensor and actuator data collected from the DIII-D tokamak located in San Diego, CA, USA
is a scientific device that uses electro-magnetic fields to confine extremely hot ionized gas called plasma in a toroidal chamber, with the aim of achieving controlled nuclear fusion It is considered the most promising experimental design for achieving commercial nuclear fusion at scale, opening up avenues for nearly unlimited clean energy. We use a datas...
2023
-
[35]
Each RL algorithm was evaluated based on how closely it tracks a given goal state of the plasma
as a proxy. Each RL algorithm was evaluated based on how closely it tracks a given goal state of the plasma. The reward at each time- step during evaluation corresponds to the L2 distance between the goal variables to track and the actual quantities achieved through control. Figure 8: Tokamak fusion reactor from (Walker et al., 2020). 22 Published as a co...
2020
-
[36]
that fits the optimalQ ∗ using expectile regression (Newey & Powell, 1987). GCIQL learnsQandVas follows: LV GCIQL(V) =E (s,a)∼pD(s,a), g∼p D mixed(g|s) ℓ2 κ ¯Q(s, a, g)−V(s, g) , LQ GCIQL(Q) =E (s,a,s′)∼pD(s,a,s′), g∼p D mixed(g|s) h rW (s, a, g) +γV(s ′, g)−Q(s, a, g) 2i Here, ¯Qis the target Q function (Mnih et al., 2015),κis the expectile andr W (s, a,...
1987
-
[37]
We increased the R-Net size to an MLP of 64 units (we did not see an improvement in classification accuracy for large sizes) and used a local distance thresholdτ= 10 on all tasks
Furthermore, noticing that Go-Fresh is tested on relatively simpler tasks compared to ours in their paper (Mezghani et al., 2023), we modify the following hyperparameters to account for the increased task difficulty, in addition to using best values for other hyperparameters: We used a memory capacity of 5000 on all tasks which we found to be sufficient (...
2023
-
[38]
We provide the specific hyperparameters used for each task in Table
•n-step returns:We implement two ways of doing n-step returns in the critic with sparse rewards (wherer(s, g) =−1(s̸=g)andtis the MDP timestep): 1.n-step GCIQL:Q(s t, at, g) =Pt+n−1 i=t r(st+i, g) +γ nQ(st+n, π(at+n|st+n, g), g) 2.GCIQL-OTA(based on the core idea in (Ahn et al., 2025)): Q(st, at, g) =−1(s t+n ̸=g) +γQ(s t+n, π(at+n|st+n, g), g) As evident...
2025
-
[39]
3.2 and Sec
24 Published as a conference paper at ICLR 2026 B.4 TRAJECTORYVISUALIZATIONS: ANALYSED TRAJECTORIES 0 1 2 3 4 Figure 9: Expert trajectories of varying lengths onantmaze-giant-navigateused for analysis in Sec. 3.2 and Sec. 5.1. The green dot represents the starting position and the star represents the goal. B.5 TRAININGITERATIONS Table 7: Training iteratio...
2026
-
[40]
4.1 for next next 1M epochs, however we did not see any consistent improvements from doing this
Layer normalization True Target net update rate (occupancy model) 0.005 Discount factorγ(occupancy model) 0.99 Flow steps 22 (antmaze-giant-navigate), 55 (antmaze-large-navigate), 45 (other tasks) Reward (pD cur, pD traj , pD rand) ratio for goal sampling (0.2, 0.5, 0.3) We added a warm-start stage without bootstrapping to the occupancy model by training ...
2026
-
[41]
For default GCIQL, policy training takes 7.2 ms per iteration
0.25 antmaze-large-explore 0.015 0.9 0.99 (0, 0.5, 0.5) 3.0 B.8 WALL-CLOCK TIME The average wall-clock time per iteration is as follows: Method Component Time per iteration (ms) ORS Occupancy model 14 Reward function 8 Policy training 6.5 GO-FRESH R-NET training 9.5 Policy training 7.2 GO-FRESH also has a graph computation time that ranges between 1.5-10 ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.