Recognition: unknown
FingerEye: Continuous and Unified Vision-Tactile Sensing for Dexterous Manipulation
Pith reviewed 2026-05-09 23:40 UTC · model grok-4.3
The pith
FingerEye combines binocular cameras and a marker-tracked compliant ring to create one continuous perception stream from vision to tactile wrench estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FingerEye integrates binocular RGB cameras for close-range visual perception with implicit stereo depth and marker-based pose estimation on a compliant ring to serve as a proxy for contact wrench sensing, enabling a perception stream that smoothly transitions from pre-contact visual cues to post-contact tactile feedback and supporting vision-tactile imitation learning for dexterous manipulation from limited real-world data augmented by simulated observations.
What carries the argument
Binocular camera pair plus marker-based pose estimation on a deformable ring that acts as wrench proxy.
If this is right
- Multiple FingerEye units can be fused to train policies for tasks such as coin standing, chip picking, letter retrieval, and syringe manipulation.
- Real demonstrations combined with visually augmented simulated observations improve policy robustness to object appearance changes.
- The sensor supplies both pre-contact depth cues and post-contact force estimates in one hardware package.
- A digital twin of the sensor and robot platform supports sim-to-real transfer without additional real-world data collection.
Where Pith is reading between the lines
- The approach could eliminate the need for separate vision systems and force sensors in future gripper designs.
- If the ring proxy holds under high-speed or high-force regimes, similar hybrid sensing could be retrofitted to existing compliant fingers.
- The digital-twin augmentation technique might transfer to other camera-based tactile sensors to reduce real-data requirements.
Load-bearing premise
Marker-tracked deformations of the compliant ring supply an accurate enough proxy for the full contact wrench across varied objects, forces, and contact angles.
What would settle it
Systematic mismatch between the ring-derived wrench estimates and simultaneous readings from a calibrated external force-torque sensor during repeated trials with different contact directions and object stiffnesses.
Figures













read the original abstract
Dexterous robotic manipulation requires comprehensive perception across all phases of interaction: pre-contact, contact initiation, and post-contact. Such continuous feedback allows a robot to adapt its actions throughout interaction. However, many existing tactile sensors, such as GelSight and its variants, only provide feedback after contact is established, limiting a robot's ability to precisely initiate contact. We introduce FingerEye, a compact and cost-effective sensor that provides continuous vision-tactile feedback throughout the interaction process. FingerEye integrates binocular RGB cameras to provide close-range visual perception with implicit stereo depth. Upon contact, external forces and torques deform a compliant ring structure; these deformations are captured via marker-based pose estimation and serve as a proxy for contact wrench sensing. This design enables a perception stream that smoothly transitions from pre-contact visual cues to post-contact tactile feedback. Building on this sensing capability, we develop a vision-tactile imitation learning policy that fuses signals from multiple FingerEye sensors to learn dexterous manipulation behaviors from limited real-world data. We further develop a digital twin of our sensor and robot platform to improve policy generalization. By combining real demonstrations with visually augmented simulated observations for representation learning, the learned policies become more robust to object appearance variations. Together, these design aspects enable dexterous manipulation across diverse object properties and interaction regimes, including coin standing, chip picking, letter retrieving, and syringe manipulation. The hardware design, code, appendix, and videos are available on our project website: https://nus-lins-lab.github.io/FingerEyeWeb/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FingerEye, a compact sensor that fuses binocular RGB cameras for pre-contact visual perception (with implicit stereo depth) and a compliant ring whose marker-tracked deformations serve as a proxy for post-contact 6D wrench sensing. This unified stream supports a multi-sensor vision-tactile imitation learning policy trained on limited real demonstrations, augmented via a digital twin for sim-to-real generalization, and is demonstrated on dexterous tasks including coin standing, chip picking, letter retrieving, and syringe manipulation.
Significance. If the deformation-to-wrench proxy can be shown to be accurate and reliable across regimes, the design would address a genuine gap in continuous perception for dexterous manipulation, enabling smoother contact initiation and policy learning with modest real-world data plus visual augmentation. The open release of hardware, code, and digital twin is a clear strength that supports reproducibility.
major comments (3)
- [Sensor Design] Sensor design and characterization: the central claim that marker-based pose estimation on the compliant ring provides a usable proxy for full contact wrench (3D force + 3D torque) is not supported by any explicit mapping (stiffness matrix, FEM model, or learned regressor), calibration procedure, or direct comparison to a reference force/torque sensor. Without this, the asserted smooth vision-to-tactile transition and reliable imitation learning rest on an unverified assumption.
- [Experiments] Experimental evaluation: task success is reported for the four manipulation scenarios, yet no quantitative metrics appear for wrench estimation accuracy (e.g., RMSE vs. ground truth, drift, saturation limits, or sensitivity to contact location/shear), nor any ablation isolating the contribution of the tactile proxy versus vision alone.
- [Imitation Learning] Imitation learning pipeline: the fusion of signals from multiple FingerEye units and the role of the digital twin in representation learning lack ablation studies or baseline comparisons that would demonstrate the necessity of the continuous vision-tactile stream for the claimed generalization gains.
minor comments (2)
- [Abstract / Sensor Design] The phrase 'implicit stereo depth' is used without a concrete description of the stereo algorithm, baseline, or expected depth accuracy at the close-range operating distances.
- [Figures] Figure captions and text could more clearly distinguish pre-contact visual cues from post-contact deformation signals to help readers follow the continuous perception claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has identified important areas for clarification and strengthening in our manuscript. We address each major comment point by point below, outlining the revisions we will make.
read point-by-point responses
-
Referee: [Sensor Design] Sensor design and characterization: the central claim that marker-based pose estimation on the compliant ring provides a usable proxy for full contact wrench (3D force + 3D torque) is not supported by any explicit mapping (stiffness matrix, FEM model, or learned regressor), calibration procedure, or direct comparison to a reference force/torque sensor. Without this, the asserted smooth vision-to-tactile transition and reliable imitation learning rest on an unverified assumption.
Authors: We clarify that the policy directly ingests the 6D marker poses estimated from the binocular images as the tactile observation; these poses encode contact-induced deformations without an intermediate explicit wrench computation. The 'proxy' phrasing in the manuscript is conceptual, indicating that the deformation signal captures equivalent information to a wrench for the purposes of the imitation learning pipeline. The continuous perception stream arises because the same RGB cameras provide both pre-contact stereo vision and post-contact marker tracking. In the revision we will expand the sensor design section with the precise marker tracking algorithm, representation of the 6D pose in the observation vector, and a discussion of why an explicit stiffness mapping is unnecessary for our end-to-end approach. We will also add qualitative examples of marker deformation under varied contact conditions. revision: partial
-
Referee: [Experiments] Experimental evaluation: task success is reported for the four manipulation scenarios, yet no quantitative metrics appear for wrench estimation accuracy (e.g., RMSE vs. ground truth, drift, saturation limits, or sensitivity to contact location/shear), nor any ablation isolating the contribution of the tactile proxy versus vision alone.
Authors: The manuscript's primary evaluation is end-to-end task success on dexterous behaviors, which serves as the practical validation of the sensing approach. We agree that an ablation isolating the tactile component would be informative and will add a vision-only baseline comparison in the revised experiments section. For quantitative wrench metrics, we will include qualitative deformation visualizations and a limitations discussion noting the absence of reference-sensor calibration data; however, we cannot add RMSE or saturation figures without new experiments. revision: partial
-
Referee: [Imitation Learning] Imitation learning pipeline: the fusion of signals from multiple FingerEye units and the role of the digital twin in representation learning lack ablation studies or baseline comparisons that would demonstrate the necessity of the continuous vision-tactile stream for the claimed generalization gains.
Authors: We will add the requested ablation studies to the imitation learning section. These will compare the full multi-FingerEye vision-tactile policy against (i) a single-sensor variant, (ii) a vision-only variant, and (iii) a version without digital-twin augmentation, reporting success rates and generalization performance across the four tasks. This will directly quantify the contribution of the continuous sensing stream and the digital twin. revision: yes
- Quantitative wrench estimation accuracy (RMSE, drift, saturation limits, sensitivity to contact location/shear) versus a reference force/torque sensor, as no such calibration experiments were performed in the original work.
Circularity Check
No significant circularity: hardware design and imitation learning with no mathematical derivations or self-referential predictions
full rationale
The paper describes a sensor hardware design (binocular RGB cameras + compliant ring with marker-based pose estimation as proxy for contact wrench) and applies it to vision-tactile imitation learning for dexterous tasks. No equations, derivations, fitted parameters presented as predictions, or uniqueness theorems appear in the provided text. Claims rest on empirical demonstration and design choices rather than any chain that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for any core result. This matches the default expectation of non-circularity for applied robotics hardware papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
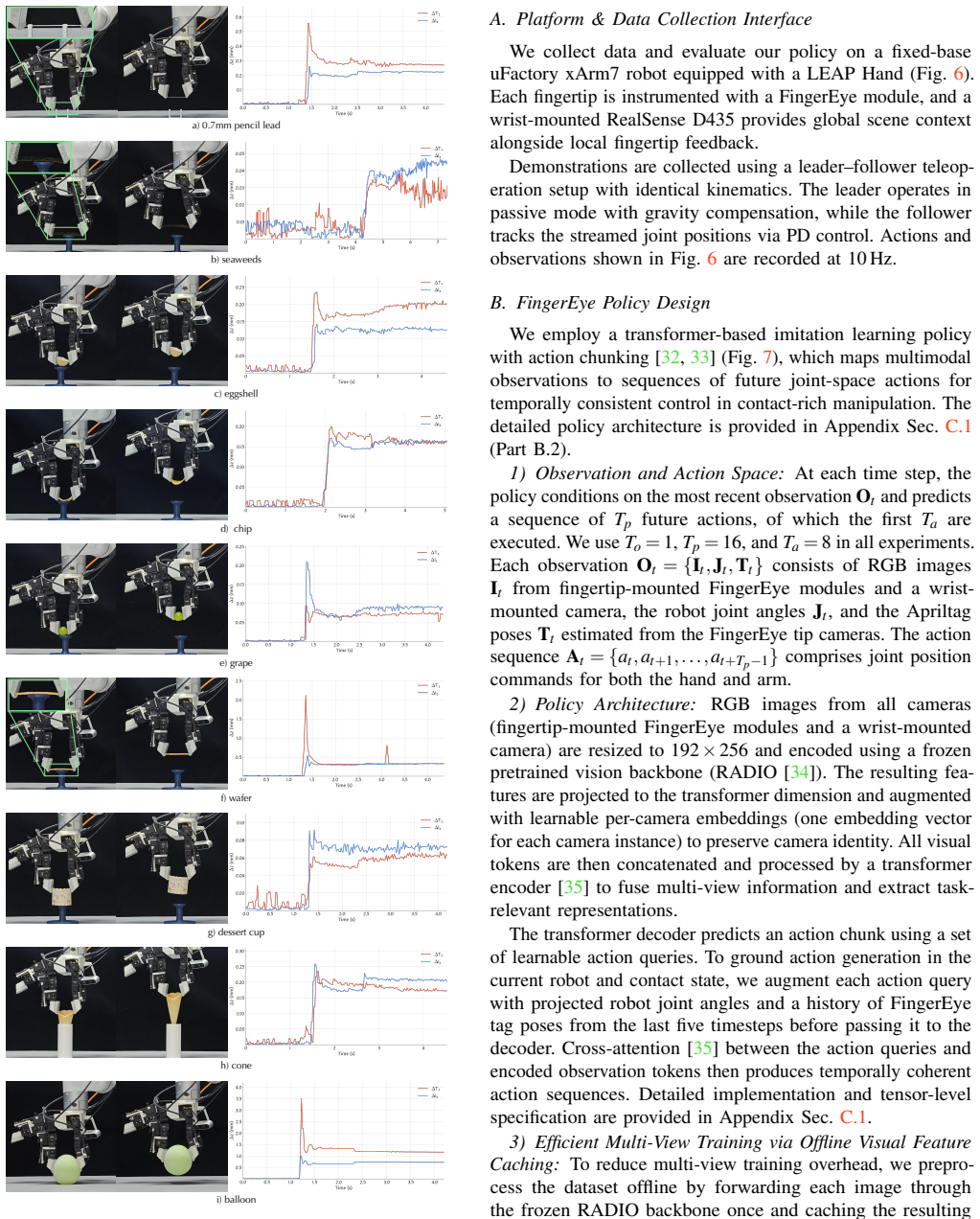
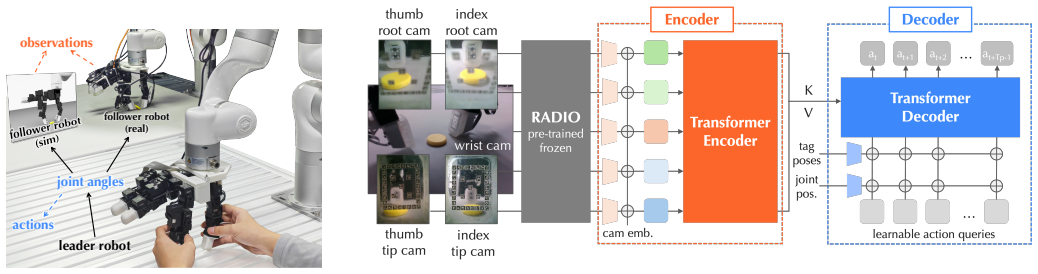
-
[1]
Toward robotic manipulation.Annual Review of Control, Robotics, and Autonomous Systems, 1(1):1–28, 2018
Matthew T Mason. Toward robotic manipulation.Annual Review of Control, Robotics, and Autonomous Systems, 1(1):1–28, 2018
2018
-
[2]
Tailai Cheng, Kejia Chen, Lingyun Chen, Liding Zhang, Yue Zhang, Yao Ling, Mahdi Hamad, Zhenshan Bing, Fan Wu, Karan Sharma, et al. Tacumi: A multi-modal universal manipulation interface for contact-rich tasks.arXiv preprint arXiv:2601.14550, 2026
-
[3]
SeeThruFinger: See and Grasp Anything with a Multi-Modal Soft Touch, 2025
Fang Wan and Chaoyang Song. Seethrufinger: See and grasp anything with a soft touch.arXiv preprint arXiv:2312.09822, 2023
-
[4]
Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017
Wenzhen Yuan, Siyuan Dong, and Edward H Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017
2017
-
[5]
9dtact: A compact vision-based tactile sensor for accurate 3d shape reconstruction and generalizable 6d force estimation.IEEE Robotics and Automation Letters, 2023
Changyi Lin, Han Zhang, Jikai Xu, Lei Wu, and Huazhe Xu. 9dtact: A compact vision-based tactile sensor for accurate 3d shape reconstruction and generalizable 6d force estimation.IEEE Robotics and Automation Letters, 2023
2023
-
[6]
Atsushi Yamaguchi and Christopher G. Atkeson. Implementing tactile behaviors using fingervision. In2017 IEEE-RAS 17th International Conference on Humanoid Robotics (Humanoids), pages 241–248. IEEE, 2017. doi: 10.1109/HUMANOIDS.2017. 8246891
-
[7]
Sheeraz Athar, Gaurav Patel, Zhengtong Xu, Qiang Qiu, and Yu She. Vistac toward a unified multimodal sensing finger for robotic manipulation.IEEE Sensors Journal, 23(20):25440– 25450, 2023. doi: 10.1109/JSEN.2023.3310918
-
[8]
Yuyang Li, Yinghan Chen, Zihang Zhao, Puhao Li, Tengyu Liu, Siyuan Huang, and Yixin Zhu. Simultaneous tactile-visual perception for learning multimodal robot manipulation.arXiv preprint arXiv:2512.09851, 2025
-
[9]
Optical proximity sensing for pose estimation during in-hand manipulation
Patrick Lancaster, Pratik Gyawali, Christoforos Mavrogiannis, Siddhartha S Srinivasa, and Joshua R Smith. Optical proximity sensing for pose estimation during in-hand manipulation. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11818–11825. IEEE, 2022
2022
-
[10]
Vision-based proximity and tactile sensing for robot arms: Design, perception, and control
Quan Khanh Luu, Dinh Quang Nguyen, Nhan Huu Nguyen, Nam Phuong Dam, and Van Anh Ho. Vision-based proximity and tactile sensing for robot arms: Design, perception, and control. IEEE Transactions on Robotics, 2025
2025
-
[11]
Finger-sts: Combined proximity and tactile sensing for robotic manipulation
Francois R Hogan, Jean-Fran c ¸ois Tremblay, Bobak H Baghi, Michael Jenkin, Kaleem Siddiqi, and Gregory Dudek. Finger-sts: Combined proximity and tactile sensing for robotic manipulation. IEEE Robotics and Automation Letters, 7(4):10865–10872, 2022
2022
-
[12]
Stereotac: A novel visuotactile sensor that combines tactile sensing with 3d vision.IEEE Robotics and Automation Letters, 8(10):6291–6298, 2023
Etienne Roberge, Guillaume Fornes, and Jean-Philippe Roberge. Stereotac: A novel visuotactile sensor that combines tactile sensing with 3d vision.IEEE Robotics and Automation Letters, 8(10):6291–6298, 2023
2023
-
[13]
Trevor Ablett, Oliver Limoyo, Adam Sigal, Affan Jilani, Jonathan Kelly, Kaleem Siddiqi, Francois Hogan, and Gregory Dudek. Multimodal and force-matched imitation learning with a see- through visuotactile sensor.IEEE Transactions on Robotics, 41: 946–959, 2025. doi: 10.1109/TRO.2024.3521864
-
[14]
Dtactive: A vision-based tactile sensor with active surface
Jikai Xu, Lei Wu, Changyi Lin, Ding Zhao, and Huazhe Xu. Dtactive: A vision-based tactile sensor with active surface. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 21664–21670. IEEE, 2025
2025
-
[15]
Look-to-touch: A vision- enhanced proximity and tactile sensor for distance and geometry perception in robotic manipulation.IEEE/ASME Transactions on Mechatronics, 2026
Yueshi Dong, Jieji Ren, Zhenle Liu, Zhanxuan Peng, Zihao Yuan, Ningbin Zhang, and Guoying Gu. Look-to-touch: A vision- enhanced proximity and tactile sensor for distance and geometry perception in robotic manipulation.IEEE/ASME Transactions on Mechatronics, 2026
2026
-
[16]
The tactip family: Soft optical tactile sensors with 3d-printed biomimetic morphologies.Soft robotics, 5(2):216–227, 2018
Benjamin Ward-Cherrier, Nicholas Pestell, Luke Cramphorn, Benjamin Winstone, Maria Elena Giannaccini, Jonathan Rossiter, and Nathan F Lepora. The tactip family: Soft optical tactile sensors with 3d-printed biomimetic morphologies.Soft robotics, 5(2):216–227, 2018
2018
-
[17]
Hardware technology of vision-based tactile sensor: A review
Shixin Zhang, Zixi Chen, Yuan Gao, Weiwei Wan, Jianhua Shan, Hongxiang Xue, Fuchun Sun, Yiyong Yang, and Bin Fang. Hardware technology of vision-based tactile sensor: A review. IEEE Sensors Journal, 22(22):21410–21427, 2022
2022
-
[18]
Haoran Li, Yijiong Lin, Chenghua Lu, Max Yang, Efi Pso- mopoulou, and Nathan F. Lepora. Classification of vision-based tactile sensors: A review.IEEE Sensors Journal, 25(19):35672– 35686, 2025. doi: 10.1109/JSEN.2025.3599236
-
[19]
Vision-based tactile sensing: From performance parameters to device design
Yi-Hang Xin, Kai-Ming Hu, Rui-Jia Xiang, Yu-Ling Gao, Jun- Feng Zhou, Guang Meng, and Wen-Ming Zhang. Vision-based tactile sensing: From performance parameters to device design. Applied Physics Reviews, 12(2), 2025
2025
-
[20]
Gelslim: A high-resolution, compact, robust, and calibrated tactile-sensing finger
Elliott Donlon, Siyuan Dong, Melody Liu, Jianhua Li, Edward Adelson, and Alberto Rodriguez. Gelslim: A high-resolution, compact, robust, and calibrated tactile-sensing finger. In2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1927–1934. IEEE, 2018
1927
-
[21]
Densetact: Optical tactile sensor for dense shape reconstruction
Won Kyung Do and Monroe Kennedy. Densetact: Optical tactile sensor for dense shape reconstruction. In2022 International Conference on Robotics and Automation (ICRA), pages 6188–
-
[22]
Kuppuswamy, A
N. Kuppuswamy, A. Alspach, A. Uttamchandani, S. Creasy, T. Ikeda, and R. Tedrake. Soft-bubble grippers for robust and perceptive manipulation.International Conference on Intelligent Robots and Systems (IROS), 2020
2020
-
[23]
Eyesight hand: Design of a fully-actuated dexterous robot hand with integrated vision-based tactile sensors and compliant actuation
Branden Romero, Hao-Shu Fang, Pulkit Agrawal, and Edward Adelson. Eyesight hand: Design of a fully-actuated dexterous robot hand with integrated vision-based tactile sensors and compliant actuation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1853–1860. IEEE, 2024
2024
-
[24]
Jialiang Zhao, Naveen Kuppuswamy, Siyuan Feng, Benjamin Burchfiel, and Edward Adelson. Polytouch: A robust multi-modal tactile sensor for contact-rich manipulation using tactile-diffusion policies.arXiv preprint arXiv:2504.19341, 2025
-
[25]
Son Bui, Duy Le, Tu Nguyen, Son Nguyen, Son Tran, Luc Tran, and Thong Pham. Digiteye: A transparent soft tactile sensor for robust multi-modal perception.Journal of Machine Engineering, 25:91–105, December 2025. doi: 10.36897/jme/213851
-
[26]
Hogan, Michael Jenkin, Sahand Rezaei-Shoshtari, Yogesh Girdhar, David Meger, and Gregory Dudek
Francois R. Hogan, Michael Jenkin, Sahand Rezaei-Shoshtari, Yogesh Girdhar, David Meger, and Gregory Dudek. Seeing through your skin: Recognizing objects with a novel visuotactile sensor. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1218–1227, January 2021
2021
-
[27]
Look-to-touch: A vision-enhanced proximity and tactile sensor for distance and geometry perception in robotic manipulation.arXiv preprint,
Yueshi Dong, Jieji Ren, Zhenle Liu, Zhanxuan Peng, Zihao Yuan, Ningbin Zhang, and Guoying Gu. Look-to-touch: A vision-enhanced proximity and tactile sensor for distance and geometry perception in robotic manipulation.arXiv preprint,
- [28]
-
[29]
Apriltag: A robust and flexible visual fiducial system
Edwin Olson. Apriltag: A robust and flexible visual fiducial system. In2011 IEEE International Conference on Robotics and Automation (ICRA), pages 3400–3407, 2011. doi: 10.1109/ ICRA.2011.5979561
-
[30]
Low-cost fiducial-based 6-axis force-torque sensor
Rui Ouyang and Robert Howe. Low-cost fiducial-based 6-axis force-torque sensor. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 1653–1659. IEEE, 2020
2020
-
[31]
Jinxuan Zhu, Zihao Yan, Yangyu Xiao, Jingxiang Guo, Chenrui Tie, Xinyi Cao, Yuhang Zheng, and Lin Shao. Shapeforce: Low-cost soft robotic wrist for contact-rich manipulation.arXiv preprint arXiv:2511.19955, 2025
-
[32]
Leap hand: Low-cost, effi- cient, and anthropomorphic hand for robot learning,
Kenneth Shaw, Ananye Agarwal, and Deepak Pathak. Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning.arXiv preprint arXiv:2309.06440, 2023
-
[33]
Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, page 02783649241273668, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[34]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review arXiv 2023
-
[35]
Am-radio: Agglomerative vision foundation model reduce all domains into one
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. Am-radio: Agglomerative vision foundation model reduce all domains into one. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12490–12500, 2024
2024
-
[36]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017
2017
-
[37]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Mu ˜noz, Xinjie Yao, Ren ´e Zurbr¨ugg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Heiden, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Animesh Garg, Renato Gasoto, Lionel Gulich, Yijie Guo,...
work page internal anchor Pith review arXiv 2025
-
[38]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[39]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision, pages 213–229. Springer, 2020
2020
-
[40]
Robopanoptes: The all- seeing robot with whole-body dexterity,
Xiaomeng Xu, Dominik Bauer, and Shuran Song. Robopanoptes: The all-seeing robot with whole-body dexterity.arXiv preprint arXiv:2501.05420, 2025
-
[41]
Much ado about noising: Dispelling the myths of generative robotic control,
Chaoyi Pan, Giri Anantharaman, Nai-Chieh Huang, Claire Jin, Daniel Pfrommer, Chenyang Yuan, Frank Permenter, Guannan Qu, Nicholas Boffi, Guanya Shi, et al. Much ado about noising: Dispelling the myths of generative robotic control.arXiv preprint arXiv:2512.01809, 2025
-
[42]
Chang, Peter Ballentine, Zhanpeng He, Do-Gon Kim, Kai Jiang, Hua-Hsuan Liang, Joaquin Palacios, William Wang, Pedro Piacenza, Ioannis Kymissis, and Matei Ciocarlie
Eric T. Chang, Peter Ballentine, Zhanpeng He, Do-Gon Kim, Kai Jiang, Hua-Hsuan Liang, Joaquin Palacios, William Wang, Pedro Piacenza, Ioannis Kymissis, and Matei Ciocarlie. Spikeatac: A multimodal tactile finger with taxelized dynamic sensing for dexterous manipulation, 2025. URL https://arxiv.org/abs/2510. 27048
2025
-
[43]
On the continuity of rotation representations in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5753, 2019
2019
-
[44]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018. APPENDIX Appendix Contents A Additional Hardware Details ................................... 13 A.1 Comparison with Keyline Markers ......
2018
-
[45]
The keyline approach detects circular markers with blob detection, then relies on nearest-neighbor association and temporal filtering
Comparison with Keyline Markers:We compare our AprilTag-based pipeline with a keyline-marker pipeline inspired by TacThru [8]. The keyline approach detects circular markers with blob detection, then relies on nearest-neighbor association and temporal filtering. In our setup, this pipeline is less stable when deformation between frames is large and when am...
-
[46]
For instance, Gelsight was unable to detect the contact between the sensor and the table surface due to the lack of the deformation at its sides
Comparison with Gelsight:We attempted to use Gelsight for the task ofcoin standing, but encountered several issues during the data collection stage of teleoperation. For instance, Gelsight was unable to detect the contact between the sensor and the table surface due to the lack of the deformation at its sides. Additionally, the square shape of Gelsight hi...
-
[47]
Peripheral Deformation Enabled by a Compliant Ring: The soft ring of FingerEye is mechanically bonded to and surrounds the acrylic cover, forming a compliant boundary at the fingertip periphery. In contrast to designs that enclose a deformable medium within a rigid structural ring, this compliant interface allows contact and deformation to occur not only ...
-
[48]
Fabrication Details:Our fabrication process consists of the following steps
-
[49]
3D Printing.3D-print the sensor base, camera wrappers, and mold components, including the lower mold, upper mold, and core insert
-
[50]
Pour the mixture into the lower mold until the cavity is filled
Silicone Preparation and Casting.Prepare the silicone elastomer by mixing the silicone base with the silicone curing agent at a mass ratio of base : curing agent=100 : (1∼3) . Pour the mixture into the lower mold until the cavity is filled. Assemble the upper mold and core insert into a single unit, then invert and press the assembly onto the lower mold. ...
-
[51]
Bond the soft silicone ring to the AprilTag sticker using silicone adhesive (JL-401), ensuring uniform contact
Acrylic Plate and Tag Preparation.Apply the AprilTag sticker to the inner surface of the acrylic plate. Bond the soft silicone ring to the AprilTag sticker using silicone adhesive (JL-401), ensuring uniform contact. Allow the adhesive to fully cure
-
[52]
Camera Assembly.Secure the camera wrappers to the sensor base using M2 ×4 screws, and install the camera modules into the wrappers
-
[53]
Wiring and Connection.Connect the assembled sensor to a host PC using a USB-C cable
-
[54]
Bill of Materials:The detailed cost is listed in Table I. TABLE I: Bill of Materials for One FingerEye Module Item Cost (USD) Acrylic plate 0.28 AprilTag sticker 0.42 Silicone elastomer & curing agent (20 g) 0.10 Silicone adhesive (JL-401,∼0.5 ml) 0.17 Soft silicone ring 0.02 Sensor base (3D-printed) 0.44 Camera wrappers (3D-printed) 0.45 Soft-ring mold (...
-
[55]
Wrench–Deformation Correlation Experiment Setup:To identify the mapping between the deformation of FingerEye and the applied wrench, we use the controlled hardware setup shown in Fig. 19. A digital scale is used to measure the applied forces, while a set of 3D-printed fixtures enables force application from different directions and at different contact lo...
-
[56]
Sensitivity Analysis (Details):This section provides the detailed derivation of the sensitivity analysis summarized in the main paper. Following fiducial-based sensitivity analysis in prior work [ 29, 30], we estimate the minimum detectable pose change of FingerEye from pixel-level localization accuracy and propagate it to force–torque sensitivity using t...
-
[57]
These experiments aim to validate whether vision-based tactile feedback from FingerEye can reliably indicate contact onset and enable responsive stopping and lifting behaviors
Detailed Delicate Grasping Setup and Hyper-parameters: Inspired by prior work on contact-sensitive grasping, such as SpikeAtac [ 41], we design a set of delicate grasping experiments to evaluate FingerEye in scenarios requiring early contact detection and gentle interaction. These experiments aim to validate whether vision-based tactile feedback from Fing...
-
[58]
The same architecture is used across all experiments unless otherwise stated
Detailed Policy Architecture:We describe the FingerEye policy architecture in detail, explicitly specifying all inputs, learnable components, and tensor dimensions. The same architecture is used across all experiments unless otherwise stated. Temporal structure.At each control step t, the policy conditions on the most recent To observations and predicts a...
2048
-
[59]
Shared visual encoder.Real observations and simulation- augmented observations are processed by a shared visual encoder with identical weights
Details on Simulation Augmented Representation Learn- ing:We describe the simulation-augmented representation learning framework, focusing on the auxiliary object decoder and its supervision. Shared visual encoder.Real observations and simulation- augmented observations are processed by a shared visual encoder with identical weights. Given an observation ...
-
[60]
Details on Simulation Augmentation:Our sim augmen- tation pipeline can be divided into three main categories: image, lighting, and material. Given that real-world cameras often exhibit various imperfections, we applied multiple post- processing augmentation methods—such as mean blur and Gaussian noise—to emulate these effects. In addition, we randomized l...
-
[61]
Rollouts with Full FingerEye Visualization:The entire process of the policy rollout for our four experiments can be visualized in Fig. 20. Initial poseApproach the chipContact the chipLift the chip Pick the chip RootIndex | Thumb TipIndex | Thumb Wrist Wrist Initial poseApproach the coinWedge the coinStand the coinRelease the coin Stand the coin RootIndex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.