Recognition: unknown
Visual-Tactile Peg-in-Hole Assembly Learning from Peg-out-of-Hole Disassembly
Pith reviewed 2026-05-09 23:31 UTC · model grok-4.3
The pith
Reversing trajectories from the easier peg-out-of-hole task supplies expert data that trains higher-success visual-tactile policies for peg-in-hole assembly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Formulating both disassembly and assembly in a shared visual-tactile POMDP, training a disassembly policy first, and then temporally reversing plus action-randomizing its trajectories to serve as expert demonstrations produces an assembly policy that reaches 87.5 percent average success on seen peg-hole pairs and 77.1 percent on unseen pairs, 18.1 percentage points above direct reinforcement learning from scratch, while reducing contact forces by 6.4 percent relative to single-modality baselines.
What carries the argument
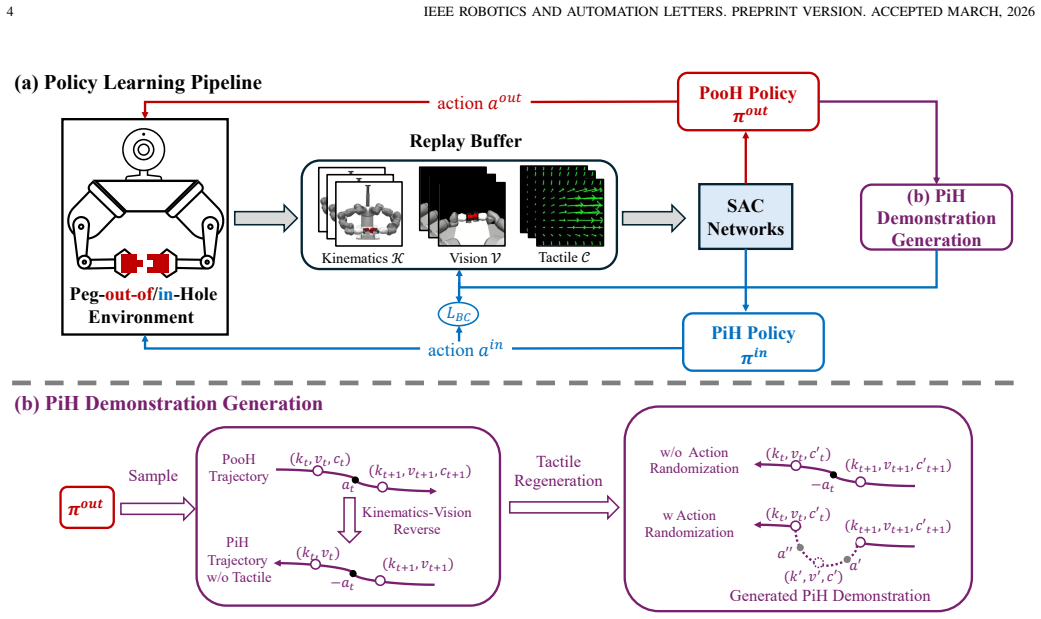
Temporal reversal and action randomization of trajectories collected from a trained peg-out-of-hole policy, used as expert demonstrations inside a unified visual-tactile POMDP for learning the peg-in-hole policy.
If this is right
- Visual sensing drives the coarse approach while tactile sensing supplies fine corrective actions during insertion.
- The same visual-tactile policy generalizes across a range of peg and hole geometries without retraining.
- Contact forces during insertion remain lower than those produced by policies that rely on vision or touch alone.
- Data collection for policy learning becomes cheaper because disassembly trajectories are easier to obtain than assembly ones.
Where Pith is reading between the lines
- The reversal trick may shorten learning for any insertion task whose inverse extraction is mechanically simpler.
- Combining the approach with other inverse demonstrations could further shrink the random-exploration budget required by reinforcement learning in contact-rich settings.
- The shared POMDP structure implies that visual-tactile policies trained on disassembly could be fine-tuned for related tasks such as screw insertion or connector mating.
Load-bearing premise
Temporally reversed and action-randomized trajectories from a peg-out-of-hole policy transfer as useful expert demonstrations for the peg-in-hole policy inside the shared visual-tactile POMDP.
What would settle it
Train an otherwise identical peg-in-hole policy using non-reversed or non-randomized disassembly trajectories and measure whether success rates on both seen and unseen objects drop to levels no higher than direct RL from scratch.
Figures






read the original abstract
Peg-in-hole (PiH) assembly is a fundamental yet challenging robotic manipulation task. While reinforcement learning (RL) has shown promise in tackling such tasks, it requires extensive exploration. In this paper, we propose a novel visual-tactile skill learning framework for the PiH task that leverages its inverse task, i.e., peg-out-of-hole (PooH) disassembly, to facilitate PiH learning. Compared to PiH, PooH is inherently easier as it only needs to overcome existing friction without precise alignment, making data collection more efficient. To this end, we formulate both PooH and PiH as Partially Observable Markov Decision Processes (POMDPs) in a unified environment with shared visual-tactile observation space. A visual-tactile PooH policy is first trained; its trajectories, containing kinematic, visual and tactile information, are temporally reversed and action-randomized to provide expert data for PiH. In the policy learning, visual sensing facilitates the peg-hole approach, while tactile measurements compensate for peg-hole misalignment. Experiments across diverse peg-hole geometries show that the visual-tactile policy attains 6.4% lower contact forces than its single-modality counterparts, and that our framework achieves average success rates of 87.5% on seen objects and 77.1% on unseen objects, outperforming direct RL methods that train PiH policies from scratch by 18.1% in success rate. Demos, code, and datasets are available at https://sites.google.com/view/pooh2pih.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a visual-tactile skill learning framework for peg-in-hole (PiH) assembly that exploits the inverse peg-out-of-hole (PooH) disassembly task. Both tasks are formulated as POMDPs with shared visual-tactile observations. A PooH policy is trained, its trajectories are reversed in time and actions randomized to generate expert demonstrations for training the PiH policy. The approach is evaluated on diverse peg-hole geometries, reporting 87.5% success on seen objects, 77.1% on unseen, 18.1% better than direct RL, and 6.4% lower contact forces with multimodal sensing.
Significance. If the core transfer assumption holds, the work offers a practical way to bootstrap RL for contact-rich tasks by using easier inverse tasks, potentially lowering exploration costs. Strengths include public code, datasets, and demos, as well as concrete empirical comparisons across modalities and object sets. The results suggest benefits from combining vision for approach and touch for alignment.
major comments (2)
- [Framework description] The temporal reversal and action randomization of PooH trajectories to obtain PiH expert data (described in the framework section) is introduced without analysis showing that the reversed state-action pairs remain feasible or near-optimal under non-reversible frictional forces and unilateral contacts. This assumption is load-bearing for the reported 18.1% success-rate gain and 77.1% unseen-object performance.
- [Experiments] The experimental results (Section 5) report average success rates of 87.5% (seen) and 77.1% (unseen) plus force reductions without specifying the number of evaluation trials per condition, statistical significance tests, or precise criteria for seen/unseen object splits, which prevents full verification of the central empirical claims.
minor comments (2)
- [Problem formulation] The shared POMDP formulation would benefit from explicit equations defining the observation space (visual + tactile) and action space to clarify how modalities are fused.
- [Abstract] The link to demos/code/datasets in the abstract should be accompanied by a permanent archive reference (e.g., Zenodo) for long-term reproducibility.
Simulated Author's Rebuttal
We appreciate the referee's feedback, which helps improve the clarity and rigor of our work. Below we respond to each major comment and indicate the planned revisions.
read point-by-point responses
-
Referee: The temporal reversal and action randomization of PooH trajectories to obtain PiH expert data (described in the framework section) is introduced without analysis showing that the reversed state-action pairs remain feasible or near-optimal under non-reversible frictional forces and unilateral contacts. This assumption is load-bearing for the reported 18.1% success-rate gain and 77.1% unseen-object performance.
Authors: We acknowledge that the manuscript lacks a dedicated analysis of how temporal reversal preserves feasibility under non-reversible dynamics such as friction and unilateral contacts. Our justification in the paper rests on the observation that PooH is easier due to not requiring precise alignment, and the reversal provides a starting point for PiH policies, with randomization to introduce robustness. The strong empirical performance, particularly the 77.1% success on unseen objects, suggests the generated demonstrations are effective in practice. In the revision, we will expand the framework section with a discussion of this assumption, including potential limitations and why it holds for the tested scenarios, supported by additional trajectory visualizations. revision: partial
-
Referee: The experimental results (Section 5) report average success rates of 87.5% (seen) and 77.1% (unseen) plus force reductions without specifying the number of evaluation trials per condition, statistical significance tests, or precise criteria for seen/unseen object splits, which prevents full verification of the central empirical claims.
Authors: We agree that these details are necessary for reproducibility and verification. The experiments consisted of 20 trials per object and condition. Statistical significance was evaluated using Student's t-test, with p-values below 0.05 for the reported improvements. Seen objects correspond to the four peg-hole pairs used during training, while unseen objects are three additional pairs with varying diameters and shapes, as detailed in the experimental setup. We will revise Section 5 to explicitly state the number of trials, include error bars or standard deviations, report the p-values, and clarify the object split criteria. revision: yes
Circularity Check
No circularity: empirical RL method with external benchmarks
full rationale
The paper describes an empirical RL pipeline: train a PooH policy, temporally reverse and randomize its trajectories to seed a PiH policy inside a shared visual-tactile POMDP, then evaluate success rate and contact force on seen/unseen objects. No equations, first-principles derivations, or fitted parameters are presented that reduce to their own inputs by construction. Reported gains (18.1 % success, 6.4 % lower force) are measured against direct RL baselines and real hardware, not generated from self-referential definitions or self-citations. The transfer assumption is an unproven modeling choice, but it is not smuggled in via prior self-work or renamed as a derived result; it remains an external hypothesis tested by experiment. Hence the derivation chain is self-contained and non-circular.
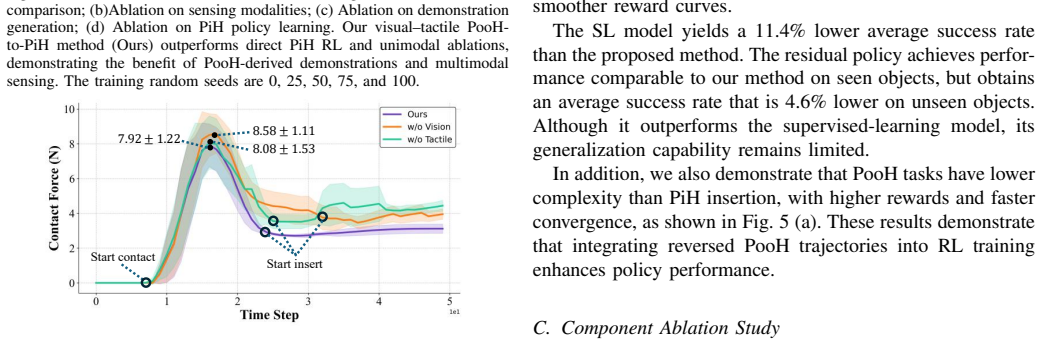
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodality driven impedance-based sim2real transfer learning for robotic multiple peg-in-hole assembly,
W. Chen, C. Zeng, H. Liang, F. Sun, and J. Zhang, “Multimodality driven impedance-based sim2real transfer learning for robotic multiple peg-in-hole assembly,”IEEE Transactions on Cybernetics, 2023
2023
-
[2]
Tactile-rl for insertion: Generalization to objects of unknown geome- try,
S. Dong, D. K. Jha, D. Romeres, S. Kim, D. Nikovski, and A. Rodriguez, “Tactile-rl for insertion: Generalization to objects of unknown geome- try,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 6437–6443
2021
-
[3]
Skill general- ization of tubular object manipulation with tactile sensing and sim2real learning,
Y . Zhao, X. Jing, K. Qian, D. F. Gomes, and S. Luo, “Skill general- ization of tubular object manipulation with tactile sensing and sim2real learning,”Robotics and Autonomous Systems, vol. 160, p. 104321, 2023
2023
-
[4]
Alore: Au- tonomous large-object rearrangement with a legged manipulator,
Z. Bi, Y . Zhang, K. Chen, G. Zhao, Y . Li, and J. Ma, “Alore: Au- tonomous large-object rearrangement with a legged manipulator,”arXiv preprint arXiv:2602.04214, 2026
-
[5]
Vitac-tracing: Visual-tactile imitation learning of deformable object tracing,
Y . Zhao, H. Luo, Y . Wang, E. S. Papastavridis, Y . Demiris, and S. Luo, “Vitac-tracing: Visual-tactile imitation learning of deformable object tracing,”arXiv preprint arXiv:2603.18784, 2026
-
[6]
Automate: Specialist and generalist assembly policies over diverse geometries,
B. Tang, I. Akinola, J. Xu, B. Wen, A. Handa, K. Van Wyk, D. Fox, G. S. Sukhatme, F. Ramos, and Y . S. Narang, “Automate: Specialist and generalist assembly policies over diverse geometries,”CoRR, 2024
2024
-
[7]
Theory of event coding (tec) v2. 0: Representing and con- trolling perception and action,
B. Hommel, “Theory of event coding (tec) v2. 0: Representing and con- trolling perception and action,”Attention, Perception, & Psychophysics, vol. 81, no. 7, pp. 2139–2154, 2019
2019
-
[8]
Break and make: Interactive structural understanding using lego bricks,
A. Walsman, M. Zhang, K. Kotar, K. Desingh, A. Farhadi, and D. Fox, “Break and make: Interactive structural understanding using lego bricks,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 90– 107
2022
-
[9]
Jamming problems and the effects of compliance in dual peg-hole disassembly,
F. Goli, Y . Zhang, M. Qu, Y . Zang, M. Saadat, D. T. Pham, and Y . Wang, “Jamming problems and the effects of compliance in dual peg-hole disassembly,”Proceedings of the Royal Society A, vol. 480, no. 2286, p. 20230364, 2024
2024
-
[10]
Vision-based robotic peg-in-hole research: integrating object recognition, positioning, and reinforcement learning,
C. Chen, H. Wang, Y . Pan, and D. Li, “Vision-based robotic peg-in-hole research: integrating object recognition, positioning, and reinforcement learning,”The International Journal of Advanced Manufacturing Tech- nology, vol. 135, no. 3, pp. 1119–1129, 2024
2024
-
[11]
Hybrid-vins: Underwater tightly coupled hybrid visual inertial dense slam for auv,
Y . Ou, J. Fan, C. Zhou, P. Zhanget al., “Hybrid-vins: Underwater tightly coupled hybrid visual inertial dense slam for auv,”IEEE Transactions on Industrial Electronics, vol. 72, no. 3, pp. 2821–2831, 2024
2024
-
[12]
Vision-guided peg-in-hole assembly by baxter robot,
Y . Huang, X. Zhang, X. Chen, and J. Ota, “Vision-guided peg-in-hole assembly by baxter robot,”Advances in Mechanical Engineering, vol. 9, no. 12, p. 1687814017748078, 2017
2017
-
[13]
Fots: A fast optical tactile simulator for sim2real learning of tactile-motor robot manipulation skills,
Y . Zhao, K. Qian, B. Duan, and S. Luo, “Fots: A fast optical tactile simulator for sim2real learning of tactile-motor robot manipulation skills,”IEEE Robotics and Automation Letters, 2024
2024
-
[14]
Visual–tactile fusion and sac-based learning for robot peg-in-hole assembly in uncertain environments,
J. Tang, X. Yuan, and S. Li, “Visual–tactile fusion and sac-based learning for robot peg-in-hole assembly in uncertain environments,”Machines, vol. 13, no. 7, p. 605, 2025
2025
-
[15]
Geltip: A finger-shaped optical tactile sensor for robotic manipulation,
D. F. Gomes, Z. Lin, and S. Luo, “Geltip: A finger-shaped optical tactile sensor for robotic manipulation,” in2020 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2020, pp. 9903–9909
2020
-
[16]
Insertionnet-a scalable solution for insertion,
O. Spector and D. Di Castro, “Insertionnet-a scalable solution for insertion,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 5509–5516, 2021
2021
-
[17]
Symmetry-aware reinforcement learning for robotic assembly under partial observability with a soft wrist,
H. Nguyen, T. Kozuno, C. C. Beltran-Hernandez, and M. Hamaya, “Symmetry-aware reinforcement learning for robotic assembly under partial observability with a soft wrist,” in2024 IEEE international conference on robotics and automation (ICRA). IEEE, 2024, pp. 9369– 9375
2024
-
[18]
J. Xu, Z. Hou, Z. Liu, and H. Qiao, “Compare contact model-based control and contact model-free learning: A survey of robotic peg-in- hole assembly strategies,”arXiv preprint arXiv:1904.05240, 2019
-
[19]
Dual-arm peg-in-hole assembly using dnn with double force/torque sensor,
D. Ortega-Aranda, J. F. Jimenez-Vielma, B. N. Saha, and I. Lopez- Juarez, “Dual-arm peg-in-hole assembly using dnn with double force/torque sensor,”Applied Sciences, vol. 11, no. 15, p. 6970, 2021
2021
-
[20]
Vision-enhanced peg-in-hole for automotive body parts using semantic image segmentation and object detection,
M. Sileo, N. Capece, M. Gruosso, M. Nigro, D. D. Bloisi, F. Pierri, and U. Erra, “Vision-enhanced peg-in-hole for automotive body parts using semantic image segmentation and object detection,”Engineering Applications of Artificial Intelligence, vol. 128, p. 107486, 2024
2024
-
[21]
End-to-end deep reinforcement learning and control with multimodal perception for planetary robotic dual peg-in- hole assembly,
B. Li and Z. Wang, “End-to-end deep reinforcement learning and control with multimodal perception for planetary robotic dual peg-in- hole assembly,”Advances in Space Research, vol. 74, no. 11, pp. 5860– 5873, 2024
2024
-
[22]
Peg-in-hole assembly with dual-arm robot and dexterous robot hands,
D.-H. Lee, M.-S. Choi, H. Park, G.-R. Jang, J.-H. Park, and J.-H. Bae, “Peg-in-hole assembly with dual-arm robot and dexterous robot hands,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 8566–8573, 2022
2022
-
[23]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
2018
-
[24]
Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation,
H. Xue, J. Ren, W. Chen, G. Zhang, Y . Fang, G. Gu, H. Xu, and C. Lu, “Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation,” inProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[25]
Stable-baselines3: Reliable reinforcement learning implementa- tions,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dor- mann, “Stable-baselines3: Reliable reinforcement learning implementa- tions,”Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021
2021
-
[26]
Mujoco: A physics engine for model- based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model- based control,” in2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2012, pp. 5026–5033
2012
-
[27]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, S. Nasiriany, and Y . Zhu, “robosuite: A modular simulation framework and benchmark for robot learning,”arXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review arXiv 2009
-
[28]
Generation of gelsight tactile images for sim2real learning,
D. F. Gomes, P. Paoletti, and S. Luo, “Generation of gelsight tactile images for sim2real learning,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 4177–4184, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.