Recognition: unknown
LEXIS: LatEnt ProXimal Interaction Signatures for 3D HOI from an Image
Pith reviewed 2026-05-10 00:42 UTC · model grok-4.3
The pith
A learned discrete manifold of proximal interaction signatures enables single-image inference of 3D human-object meshes together with their dense continuous proximity fields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
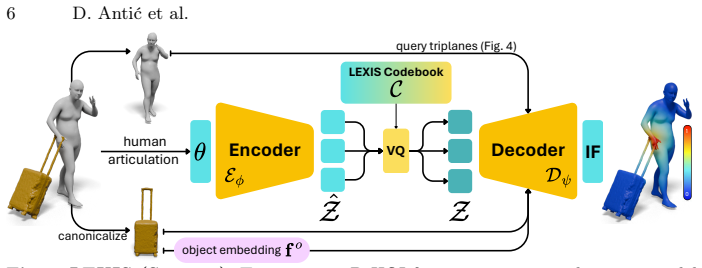
The paper claims that interaction patterns are structured by action type and object geometry, allowing a vector-quantized variational autoencoder to learn a useful discrete manifold called LEXIS of proximal interaction signatures. Conditioned on LEXIS, the LEXIS-Flow diffusion framework reconstructs human and object meshes along with dense InterFields from one image; the inferred fields then steer a guided refinement step that enforces realistic proximity without post-hoc optimization.
What carries the argument
LEXIS, the discrete manifold of proximal interaction signatures obtained via VQ-VAE; it supplies structured conditioning that lets the diffusion model infer dense InterFields from image input.
If this is right
- Mesh accuracy, contact precision, and proximity estimation all improve over existing single-image baselines on the Open3DHOI and BEHAVE datasets.
- Generalization to unseen actions and objects increases while the generated scenes are rated more realistic by human observers.
- Physically plausible results emerge directly from the generation process because InterFields guide refinement without any separate optimization stage.
- The approach moves 3D scene understanding closer to capturing continuous physical relationships between people and objects.
Where Pith is reading between the lines
- The signatures may implicitly encode action semantics from geometry alone, opening the possibility of action recognition as a byproduct of reconstruction.
- The same manifold-learning strategy could be applied to related ill-posed tasks such as hand-object interaction or multi-person contact.
- In robotics or AR settings the continuous proximity fields could supply richer distance information for planning grasps or avoiding collisions than binary contacts allow.
Load-bearing premise
Interaction patterns are characteristically structured by the action and object geometry in a manner that permits a VQ-VAE to extract a useful discrete manifold of signatures.
What would settle it
Training an ablated version of LEXIS-Flow that directly regresses InterFields from images without the VQ-VAE manifold and showing equal or superior reconstruction, contact, and proximity metrics on Open3DHOI and BEHAVE would undermine the claimed necessity of the learned signatures.
Figures






read the original abstract
Reconstructing 3D Human-Object Interaction from an RGB image is essential for perceptive systems. Yet, this remains challenging as it requires capturing the subtle physical coupling between the body and objects. While current methods rely on sparse, binary contact cues, these fail to model the continuous proximity and dense spatial relationships that characterize natural interactions. We address this limitation via InterFields, a representation that encodes dense, continuous proximity across the entire body and object surfaces. However, inferring these fields from single images is inherently ill-posed. To tackle this, our intuition is that interaction patterns are characteristically structured by the action and object geometry. We capture this structure in LEXIS, a novel discrete manifold of interaction signatures learned via a VQ-VAE. We then develop LEXIS-Flow, a diffusion framework that leverages LEXIS signatures to estimate human and object meshes alongside their InterFields. Notably, these InterFields help in a guided refinement that ensures physically-plausible, proximity-aware reconstructions without requiring post-hoc optimization. Evaluation on Open3DHOI and BEHAVE shows that LEXIS-Flow significantly outperforms existing SotA baselines in reconstruction, contact, and proximity quality. Our approach not only improves generalization but also yields reconstructions perceived as more realistic, moving us closer to holistic 3D scene understanding. Code & models will be public at https://anticdimi.github.io/lexis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InterFields as a dense, continuous proximity representation for 3D human-object interactions (HOI) from a single RGB image, contrasting with prior sparse binary contact cues. It proposes LEXIS, a discrete manifold of interaction signatures learned via VQ-VAE that captures structure from actions and object geometry, and LEXIS-Flow, a diffusion framework that infers human/object meshes together with InterFields; these fields then guide refinement for physically plausible outputs without post-hoc optimization. The central empirical claim is that LEXIS-Flow significantly outperforms existing SOTA baselines on Open3DHOI and BEHAVE in reconstruction, contact, and proximity quality while improving generalization and perceived realism.
Significance. If the performance claims hold, the work advances 3D HOI reconstruction by replacing sparse cues with continuous proximity fields and by using a learned discrete manifold to regularize an otherwise ill-posed inverse problem. The diffusion-based inference with guided refinement is a practical contribution, and the explicit commitment to release code and models supports reproducibility. The approach could influence downstream tasks in scene understanding that require physically grounded 3D interactions.
minor comments (2)
- The abstract states that InterFields 'help in a guided refinement' but does not indicate whether this step is part of the diffusion sampling loop or a separate post-processing stage; a brief clarification would aid readers.
- Evaluation is reported on Open3DHOI and BEHAVE, yet the abstract does not name the quantitative metrics (e.g., Chamfer distance, contact IoU, proximity error) used to support the 'significantly outperforms' claim; adding these would strengthen the summary.
Simulated Author's Rebuttal
We thank the referee for the careful review and for recognizing the potential significance of InterFields as a continuous proximity representation and LEXIS as a learned discrete manifold for regularizing 3D HOI reconstruction. We appreciate the positive assessment of the diffusion framework with guided refinement and the commitment to code release. The 'uncertain' recommendation appears to stem from the need for further validation of the performance claims; below we provide point-by-point clarification on the major aspects raised in the summary, while noting that no specific technical criticisms were detailed in the major comments section.
Circularity Check
No significant circularity; empirical ML pipeline on public data
full rationale
The paper introduces InterFields as a dense proximity representation and LEXIS as a VQ-VAE-learned discrete manifold of signatures, then applies a diffusion model (LEXIS-Flow) to infer meshes and fields from images. All components are trained end-to-end on external datasets (Open3DHOI, BEHAVE) with quantitative evaluation against baselines. No equations or steps reduce by construction to fitted inputs, self-definitions, or self-citation chains; the manifold is data-driven rather than presupposed, and performance claims rest on held-out empirical metrics rather than analytic closure. The framework is self-contained against external benchmarks and falsifiable via standard ML protocols.
Axiom & Free-Parameter Ledger
free parameters (2)
- VQ-VAE codebook size and training hyperparameters
- Diffusion model architecture parameters
axioms (1)
- domain assumption Interaction patterns are characteristically structured by the action and object geometry.
invented entities (2)
-
InterFields
no independent evidence
-
LEXIS
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Computer Vision (ICCV)
Antić, D., Paschalidis, G., Tripathi, S., Gevers, T., Dwivedi, S.K., Tzionas, D.: SDFit: 3D object pose and shape by fitting a morphable SDF to a single image. In: International Conference on Computer Vision (ICCV). pp. 9616–9626 (2025) 4
2025
-
[2]
In: International Conference on Machine Learning (ICML)
Bao, F., Nie, S., Xue, K., Li, C., Pu, S., Wang, Y., Yue, G., Cao, Y., Su, H., Zhu, J.: One transformer fits all distributions in multi-modal diffusion at scale. In: International Conference on Machine Learning (ICML). pp. 1692–1717 (2023) 8
2023
-
[3]
Transactions on Robotics (T-RO)21(1), 47–57 (2005) 4
Bernardin, K., Ogawara, K., Ikeuchi, K., Dillmann, R.: A sensor fusion approach for recognizing continuous human grasping sequences using hidden markov models. Transactions on Robotics (T-RO)21(1), 47–57 (2005) 4
2005
-
[4]
In: Computer Vision and Pattern Recognition (CVPR)
Bhatnagar, B.L., Xie, X., Petrov, I.A., Sminchisescu, C., Theobalt, C., Pons-Moll, G.: BEHAVE: Dataset and method for tracking human object interactions. In: Computer Vision and Pattern Recognition (CVPR). pp. 15914–15925 (2022) 3, 4, 11, 13
2022
-
[5]
In: European Conference on Computer Vision (ECCV)
Bogo, F., Kanazawa, A., Lassner, C., Gehler, P., Romero, J., Black, M.J.: Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. In: European Conference on Computer Vision (ECCV). vol. 9909, pp. 561–578 (2016) 4
2016
-
[6]
In: European Conference on Computer Vision (ECCV)
Brahmbhatt, S., Tang, C., Twigg, C.D., Kemp, C.C., Hays, J.: ContactPose: A dataset of grasps with object contact and hand pose. In: European Conference on Computer Vision (ECCV). vol. 12358, pp. 361–378 (2020) 2
2020
-
[7]
In: Computer Vision and Pat- tern Recognition (CVPR)
Chan, E.R., Lin, C.Z., Chan, M.A., Nagano, K., Pan, B., Mello, S.D., Gallo, O., Guibas, L.J., Tremblay, J., Khamis, S., Karras, T., Wetzstein, G.: Efficient geometry-aware 3D generative adversarial networks. In: Computer Vision and Pat- tern Recognition (CVPR). pp. 16102–16112 (2022) 7
2022
-
[8]
Chen, Y., Dwivedi, S.K., Black, M.J., Tzionas, D.: Detecting human-object contact inimages.In:ComputerVisionandPatternRecognition(CVPR).pp.17100–17110 (2023) 4
2023
-
[9]
In: Computer Vision and Pattern Recognition (CVPR)
Chen, Z., Zhang, H.: Learning implicit fields for generative shape modeling. In: Computer Vision and Pattern Recognition (CVPR). pp. 5939–5948 (2019) 4
2019
-
[10]
In: Computer Vision and Pattern Recognition (CVPR)
Cheng, Y.C., Lee, H.Y., Tuyakov, S., Schwing, A., Gui, L.: SDFusion: Multimodal 3D shape completion, reconstruction, and generation. In: Computer Vision and Pattern Recognition (CVPR). pp. 4456–4465 (2023) 4
2023
-
[11]
In: European Conference on Computer Vision (ECCV)
Choy, C.B., Xu, D., Gwak, J., Chen, K., Savarese, S.: 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction. In: European Conference on Computer Vision (ECCV). vol. 9912, pp. 628–644 (2016) 4
2016
-
[12]
Corona, E., Pons-Moll, G., Alenyà, G., Moreno-Noguer, F.: Learned vertex descent: Anewdirectionfor3Dhumanmodelfitting.In:EuropeanConferenceonComputer Vision (ECCV). pp. 146–165 (2022) 4
2022
-
[13]
In: Computer Vision and Pattern Recognition (CVPR)
Cseke, A., Tripathi, S., Dwivedi, S.K., Lakshmipathy, A., Chatterjee, A., Black, M.J., Tzionas, D.: PICO: Reconstructing 3D people in contact with objects. In: Computer Vision and Pattern Recognition (CVPR). pp. 1783–1794 (2025) 4, 5
2025
-
[14]
In: Computer Vision and Pattern Recognition (CVPR)
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3D objects. In: Computer Vision and Pattern Recognition (CVPR). pp. 13142–13153 (2023) 5
2023
-
[15]
In: Computer Vision and Pattern Recognition (CVPR)
Diller, C., Dai, A.: CG-HOI: Contact-guided 3D human-object interaction gener- ation. In: Computer Vision and Pattern Recognition (CVPR). pp. 19888–19901 (2024) 4 LEXIS 17
2024
-
[16]
In: Com- puter Vision and Pattern Recognition (CVPR)
Dwivedi, S.K., Antić, D., Tripathi, S., Taheri, O., Schmid, C., Black, M.J., Tzionas, D.: InteractVLM: 3D interaction reasoning from 2D foundational models. In: Com- puter Vision and Pattern Recognition (CVPR). pp. 22605–22615 (2025) 2, 3, 4, 5, 11, 12, 13
2025
-
[17]
In: International Conference on 3D Vision (3DV)
Dwivedi, S.K., Schmid, C., Yi, H., Black, M.J., Tzionas, D.: POCO: 3D pose and shape estimation using confidence. In: International Conference on 3D Vision (3DV). pp. 85–95 (2024) 4
2024
-
[18]
In: Computer Vision and Pattern Recognition (CVPR)
Dwivedi, S.K., Sun, Y., Patel, P., Feng, Y., Black, M.J.: TokenHMR: Advancing human mesh recovery with a tokenized pose representation. In: Computer Vision and Pattern Recognition (CVPR). pp. 1323–1333 (2024) 3, 6, 7, 10
2024
-
[19]
In: Computer Vision and Pattern Recognition (CVPR)
Fan, H., Su, H., Guibas, L.: A point set generation network for 3D object re- construction from a single image. In: Computer Vision and Pattern Recognition (CVPR). pp. 2463–2471 (2017) 4
2017
-
[20]
In: Computer Vision and Pattern Recognition (CVPR)
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M.J., Hilliges, O.: ARCTIC: A dataset for dexterous bimanual hand-object manipulation. In: Computer Vision and Pattern Recognition (CVPR). pp. 12943–12954 (2023) 2, 4
2023
-
[21]
Transactions on Human-Machine Systems (THMS)46(1), 66–77 (2016) 4
Feix, T., Romero, J., Schmiedmayer, H.B., Dollar, A.M., Kragic, D.: The GRASP taxonomy of human grasp types. Transactions on Human-Machine Systems (THMS)46(1), 66–77 (2016) 4
2016
-
[22]
In: European Conference on Computer Vision (ECCV)
Fiche, G., Leglaive, S., Alameda-Pineda, X., Agudo, A., Moreno-Noguer, F.: VQ- HPS: Human pose and shape estimation in a vector-quantized latent space. In: European Conference on Computer Vision (ECCV). vol. 15110, pp. 471–490 (2024) 3
2024
-
[23]
In: International Conference on Computer Vision (ICCV)
Gkioxari, G., Malik, J., Johnson, J.: Mesh R-CNN. In: International Conference on Computer Vision (ICCV). pp. 9784–9794 (2019) 4
2019
-
[24]
In: European Conference on Computer Vision (ECCV)
Goodwin,W.,Vaze,S.,Havoutis,I.,Posner,I.:Zero-shotcategory-levelobjectpose estimation. In: European Conference on Computer Vision (ECCV). vol. 13699, pp. 516–532 (2022) 4
2022
-
[25]
In: European Conference on Computer Vision (ECCV)
Grady, P., Tang, C., Brahmbhatt, S., Twigg, C.D., Wan, C., Hays, J., Kemp, C.C.: PressureVision: Estimating hand pressure from a single RGB image. In: European Conference on Computer Vision (ECCV). vol. 13666, pp. 328–345 (2022) 4
2022
-
[26]
In: Computer Vision and Pattern Recognition (CVPR)
Grady, P., Tang, C., Twigg, C.D., Vo, M., Brahmbhatt, S., Kemp, C.C.: Contac- tOpt: Optimizing contact to improve grasps. In: Computer Vision and Pattern Recognition (CVPR). pp. 1471–1481 (2021) 4
2021
-
[27]
In: Computer Vision and Pattern Recognition (CVPR)
Hampali, S., Rad, M., Oberweger, M., Lepetit, V.: HOnnotate: A method for 3D annotation of hand and object poses. In: Computer Vision and Pattern Recognition (CVPR). pp. 3196–3206 (2020) 4
2020
-
[28]
In: International Conference on Com- puter Vision (ICCV)
Han, S., Joo, H.: CHORUS: Learning canonicalized 3D human-object spatial rela- tions from unbounded synthesized images. In: International Conference on Com- puter Vision (ICCV). pp. 15789–15800 (2023) 4
2023
-
[29]
In: International Conference on Computer Vision (ICCV)
Hassan, M., Choutas, V., Tzionas, D., Black, M.J.: Resolving 3D human pose ambiguities with 3D scene constraints. In: International Conference on Computer Vision (ICCV). pp. 2282–2292 (2019) 4
2019
-
[30]
In: Computer Vision and Pattern Recognition (CVPR)
Hassan, M., Ghosh, P., Tesch, J., Tzionas, D., Black, M.J.: Populating 3D scenes by learning human-scene interaction. In: Computer Vision and Pattern Recognition (CVPR). pp. 14708–14718 (2021) 4
2021
-
[31]
In: Computer Vision and Pattern Recognition (CVPR)
Huang, C.H.P., Yi, H., Höschle, M., Safroshkin, M., Alexiadis, T., Polikovsky, S., Scharstein, D., Black, M.J.: Capturing and inferring dense full-body human-scene contact. In: Computer Vision and Pattern Recognition (CVPR). pp. 13274–13285 (2022) 4 18 D. Antić et al
2022
-
[32]
International Journal of Computer Vision (IJCV)132(7), 2551–2566 (2024) 4
Huang, Y., Taheri, O., Black, M.J., Tzionas, D.: InterCap: Joint markerless 3D tracking of humans and objects in interaction from multi-view RGB-D images. International Journal of Computer Vision (IJCV)132(7), 2551–2566 (2024) 4
2024
-
[33]
In: Computer Vision and Pattern Recognition (CVPR)
Huang, Z., Jampani, V., Thai, A., Li, Y., Stojanov, S., Rehg, J.M.: ShapeClipper: Scalable 3D shape learning from single-view images via geometric and CLIP-based consistency. In: Computer Vision and Pattern Recognition (CVPR). pp. 12912– 12922 (2023) 4
2023
-
[34]
In: International Conference on Computer Vision (ICCV)
Jiang, H., Liu, S., Wang, J., Wang, X.: Hand-object contact consistency reasoning for human grasps generation. In: International Conference on Computer Vision (ICCV). pp. 11087–11096 (2021) 4
2021
-
[35]
In: Computer Vision and Pattern Recognition (CVPR)
Joo, H., Simon, T., Sheikh, Y.: Total capture: A 3D deformation model for tracking faces, hands, and bodies. In: Computer Vision and Pattern Recognition (CVPR). pp. 8320–8329 (2018) 4
2018
-
[36]
American Journal of Occupational Therapy34(7), 437–445 (1980) 4
Kamakura, N., Matsuo, M., Ishii, H., Mitsuboshi, F., Miura, Y.: Patterns of static prehension in normal hands. American Journal of Occupational Therapy34(7), 437–445 (1980) 4
1980
-
[37]
In: Computer Vision and Pattern Recognition (CVPR)
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of human shape and pose. In: Computer Vision and Pattern Recognition (CVPR). pp. 7122– 7131 (2018) 4
2018
-
[38]
In: European Conference on Computer Vision (ECCV)
Kim, H., Han, S., Kwon, P., Joo, H.: Beyond the contact: Discovering comprehen- sive affordance for 3D objects from pre-trained 2D diffusion models. In: European Conference on Computer Vision (ECCV). pp. 400–419 (2024) 4
2024
-
[39]
In: International Conference on Computer Vision (ICCV)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollar, P., Girshick, R.: Segment anything. In: International Conference on Computer Vision (ICCV). pp. 4015–4026 (2023) 9, 10
2023
-
[40]
In: Computer Vision and Pattern Recognition (CVPR)
Kocabas, M., Athanasiou, N., Black, M.: VIBE: Video inference for human body pose and shape estimation. In: Computer Vision and Pattern Recognition (CVPR). pp. 5252–5262 (2020) 4
2020
-
[41]
Transac- tions on Graphics (TOG)42(6), 197:1–197:11 (2023) 11
Li, J., Wu, J., Liu, C.K.: Object motion guided human motion synthesis. Transac- tions on Graphics (TOG)42(6), 197:1–197:11 (2023) 11
2023
-
[42]
In: International Conference on Computer Vision (ICCV)
Lin, K., Wang, L., Liu, Z.: Mesh graphormer. In: International Conference on Computer Vision (ICCV). pp. 12919–12928 (2021) 4
2021
-
[43]
In: International Conference on Learning Representations (ICLR) (2023) 8
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: International Conference on Learning Representations (ICLR) (2023) 8
2023
-
[44]
In: Conference on Neural Information Processing Systems (NeurIPS) (2023) 4, 5
Liu, M., Shi, R., Kuang, K., Zhu, Y., Li, X., Han, S., Cai, H., Porikli, F., Su, H.: OpenShape: Scaling up 3D shape representation towards open-world understand- ing. In: Conference on Neural Information Processing Systems (NeurIPS) (2023) 4, 5
2023
-
[45]
In: Conference on Neural Information Processing Systems (NeurIPS) (2024) 4
Liu, M., Xu, C., Jin, H., Chen, L., Varma T, M., Xu, Z., Su, H.: One-2-3-45: Any single image to 3D mesh in 45 seconds without per-shape optimization. In: Conference on Neural Information Processing Systems (NeurIPS) (2024) 4
2024
-
[46]
In: International Conference on Computer Vision (ICCV)
Liu, R., Wu, R., Hoorick, B.V., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero-1- to-3: Zero-shot one image to 3D object. In: International Conference on Computer Vision (ICCV). pp. 9264–9275 (2023) 4
2023
-
[47]
In: International Conference on Computer Vision (ICCV)
Liu, S., Zhou, Y., Yang, J., Gupta, S., Wang, S.: ContactGen: Generative contact modeling for grasp generation. In: International Conference on Computer Vision (ICCV). pp. 20552–20563 (2023) 2, 4 LEXIS 19
2023
-
[48]
In: International Conference on Computer Vision (ICCV)
Liu, Z., Zhou, D., Lu, F., Fang, J., Zhang, L.: AutoShape: Real-time shape-aware monocular 3D object detection. In: International Conference on Computer Vision (ICCV). pp. 15621–15630 (2021) 4
2021
-
[49]
Transactions on Graphics (TOG)34(6), 248:1– 248:16 (2015) 4, 5
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. Transactions on Graphics (TOG)34(6), 248:1– 248:16 (2015) 4, 5
2015
-
[50]
In: International Conference on Learning Representations (ICLR) (2019) 10
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (ICLR) (2019) 10
2019
-
[51]
In: International Conference on Learning Representations (ICLR) (2022) 10, 11
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J., Ermon, S.: SDEdit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations (ICLR) (2022) 10, 11
2022
-
[52]
In: Computer Vision and Pattern Recognition (CVPR)
Nam, H., Jung, D.S., Moon, G., Lee, K.M.: Joint reconstruction of 3D human and object via contact-based refinement transformer. In: Computer Vision and Pattern Recognition (CVPR). pp. 10218–10227 (2024) 4, 5, 11, 13
2024
-
[53]
Transactions on Ma- chine Learning Research (TMLR) (2024) 10
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fer- nandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Syn- naeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual fe...
2024
-
[54]
In: Com- puter Vision and Pattern Recognition (CVPR)
Park, J.J., Florence, P.R., Straub, J., Newcombe, R.A., Lovegrove, S.: DeepSDF: Learning continuous signed distance functions for shape representation. In: Com- puter Vision and Pattern Recognition (CVPR). pp. 165–174 (2019) 4
2019
-
[55]
In: Computer Vision and Pattern Recognition (CVPR)
Paschalidou, D., Ulusoy, A.O., Geiger, A.: Superquadrics revisited: Learning 3D shape parsing beyond cuboids. In: Computer Vision and Pattern Recognition (CVPR). pp. 10344–10353 (2019) 4
2019
-
[56]
In: Interna- tional Conference on 3D Vision (3DV)
Patel, P., Black, M.: CameraHMR: Aligning people with perspective. In: Interna- tional Conference on 3D Vision (3DV). pp. 1562–1571 (2025) 4, 11, 12
2025
-
[57]
In: Computer Vision and Pattern Recognition (CVPR)
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3D hands, face, and body from a single image. In: Computer Vision and Pattern Recognition (CVPR). pp. 10975–10985 (2019) 11
2019
-
[58]
In: International Conference on Computer Vision (ICCV)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: International Conference on Computer Vision (ICCV). pp. 4172–4182 (2023) 8
2023
-
[59]
In: International Conference on Computer Vision (ICCV)
Petrov, I.A., Marin, R., Chibane, J., Pons-Moll, G.: TriDi: Trilateral diffusion of 3D humans, objects, and interactions. In: International Conference on Computer Vision (ICCV). pp. 5523–5535 (2025) 4, 8
2025
-
[60]
In: Computer Vision and Pattern Recognition (CVPR)
Qi, H., Zhao, C., Salzmann, M., Mathis, A.: HOISDF: Constraining 3D hand- object pose estimation with global signed distance fields. In: Computer Vision and Pattern Recognition (CVPR). pp. 10392–10402 (2024) 4
2024
-
[61]
In: Conference on Neural Information Processing Systems (NeurIPS) (2022) 7, 10
Qian, G., Li, Y., Peng, H., Mai, J., Hammoud, H., Elhoseiny, M., Ghanem, B.: PointNeXt: Revisiting pointnet++ with improved training and scaling strategies. In: Conference on Neural Information Processing Systems (NeurIPS) (2022) 7, 10
2022
-
[62]
In: International Conference on Learning Representations (ICLR) (2024) 4
Qian, G., Mai, J., Hamdi, A., Ren, J., Siarohin, A., Li, B., Lee, H.Y., Skorokhodov, I., Wonka, P., Tulyakov, S., Ghanem, B.: Magic123: One image to high-quality 3D object generation using both 2D and 3D diffusion priors. In: International Conference on Learning Representations (ICLR) (2024) 4
2024
-
[63]
Accelerating 3D Deep Learning with PyTorch3D
Ravi,N.,Reizenstein,J.,Novotny,D.,Gordon,T.,Lo,W.Y.,Johnson,J.,Gkioxari, G.: Accelerating 3D deep learning with PyTorch3D. arXiv:2007.08501 (2020) 10 20 D. Antić et al
work page internal anchor Pith review arXiv 2007
-
[64]
Transactions on Graphics (TOG)36(6), 245:1–245:17 (2017) 5, 7, 11
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. Transactions on Graphics (TOG)36(6), 245:1–245:17 (2017) 5, 7, 11
2017
-
[65]
In: Conference on Neural Information Processing Systems (NeurIPS) (2024) 4
Sárándi, I., Pons-Moll, G.: Neural localizer fields for continuous 3D human pose and shape estimation. In: Conference on Neural Information Processing Systems (NeurIPS) (2024) 4
2024
-
[66]
Transactions on Graphics (TOG) 35(4), 139 (2016) 4
Savva, M., Chang, A.X., Hanrahan, P., Fisher, M., Nießner, M.: PiGraphs: Learn- ing interaction snapshots from observations. Transactions on Graphics (TOG) 35(4), 139 (2016) 4
2016
-
[67]
In: European Conference on Computer Vision (ECCV)
Shimada, S., Golyanik, V., Li, Z., Pérez, P., Xu, W., Theobalt, C.: HULC: 3D human motion capture with pose manifold sampling and dense contact guidance. In: European Conference on Computer Vision (ECCV). vol. 13682, pp. 516–533 (2022) 2
2022
-
[68]
In: Computer Vision and Pattern Recogni- tion (CVPR)
Taheri, O., Choutas, V., Black, M.J., Tzionas, D.: GOAL: Generating 4D whole- body motion for hand-object grasping. In: Computer Vision and Pattern Recogni- tion (CVPR). pp. 13263–13273 (2022) 2, 4
2022
-
[69]
In: European Conference on Computer Vision (ECCV)
Taheri, O., Ghorbani, N., Black, M.J., Tzionas, D.: GRAB: A dataset of whole- body human grasping of objects. In: European Conference on Computer Vision (ECCV). vol. 12349, pp. 581–600 (2020) 2, 4
2020
-
[70]
In: International Conference on 3D Vision (3DV)
Taheri, O., Zhou, Y., Tzionas, D., Zhou, Y., Ceylan, D., Pirk, S., Black, M.J.: GRIP: Generating interaction poses using spatial cues and latent consistency. In: International Conference on 3D Vision (3DV). pp. 933–943 (2024) 4
2024
-
[71]
SAM 3D: 3Dfy Anything in Images
Team, S.D., Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., Lin, A., Liu, J., Ma, Z., Sagar, A., Song, B., Wang, X., Yang, J., Zhang, B., Dollár, P., Gkioxari, G., Feiszli, M., Malik, J.: SAM 3D: 3Dfy anything in images. arXiv:2511.16624 (2025) 4, 5, 8, 10, 11, 12
work page internal anchor Pith review arXiv 2025
-
[72]
In: International Confer- ence on Computer Vision (ICCV)
Tripathi, S., Chatterjee, A., Passy, J., Yi, H., Tzionas, D., Black, M.J.: DECO: Dense estimation of 3D human-scene contact in the wild. In: International Confer- ence on Computer Vision (ICCV). pp. 7967–7979 (2023) 4, 5
2023
-
[73]
In: Computer Vision and Pattern Recognition (CVPR)
Tripathi, S., Müller, L., Huang, C.H.P., Omid, T., Black, M.J., Tzionas, D.: 3D human pose estimation via intuitive physics. In: Computer Vision and Pattern Recognition (CVPR). pp. 4713–4725 (2023) 4
2023
-
[74]
In: Computer Vision and Pattern Recognition (CVPR)
Wang, H., Sridhar, S., Huang, J., Valentin, J.P.C., Song, S., Guibas, L.: Normalized object coordinate space for category-level 6D object pose and size estimation. In: Computer Vision and Pattern Recognition (CVPR). pp. 2642–2651 (2019) 4
2019
-
[75]
In: European Conference on Computer Vision (ECCV)
Wang, N., Zhang, Y., Li, Z., Fu, Y., Liu, W., Jiang, Y.G.: Pixel2Mesh: Generating 3D mesh models from single RGB images. In: European Conference on Computer Vision (ECCV). vol. 11215, pp. 55–71 (2018) 4
2018
-
[76]
In: Computer Vision and Pattern Recognition (CVPR)
Wang,R.,Xu,S.,Dai,C.,Xiang,J.,Deng,Y.,Tong,X.,Yang,J.:MoGe:Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. In: Computer Vision and Pattern Recognition (CVPR). pp. 5261–5271 (June 2025) 11, 12
2025
-
[77]
In: Computer Vision and Pattern Recognition (CVPR)
Wang, Z., Zheng, Q., Ma, S., Ye, M., Zhan, Y., Li, D.: End-to-end HOI reconstruc- tion transformer with graph-based encoding. In: Computer Vision and Pattern Recognition (CVPR). pp. 27706–27715 (2025) 5, 11, 13
2025
-
[78]
In: Computer Vision and Pattern Recognition (CVPR)
Wen, B., Huang, D., Zhang, Z., Zhou, J., Deng, J., Gong, J., Chen, Y., Ma, L., Li, Y.: Reconstructing in-the-wild open-vocabulary human-object interactions. In: Computer Vision and Pattern Recognition (CVPR). pp. 17426–17436 (2025) 3, 4, 5, 11, 12, 13, 14 LEXIS 21
2025
-
[79]
In: Computer Vision and Pattern Recognition (CVPR)
Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., Xiao, J.: 3D shapenets: A deep representation for volumetric shapes. In: Computer Vision and Pattern Recognition (CVPR). pp. 1912–1920 (2015) 10
1912
-
[80]
In: Proceedings of Robotics: Science and Systems
Xiang, Y., Schmidt, T., Narayanan, V., Fox, D.: PoseCNN: A convolutional neu- ral network for 6D object pose estimation in cluttered scenes. In: Proceedings of Robotics: Science and Systems. Pittsburgh, Pennsylvania (June 2018) 4
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.