Recognition: unknown
Stream-CQSA: Avoiding Out-of-Memory in Attention Computation via Flexible Workload Scheduling
Pith reviewed 2026-05-10 00:12 UTC · model grok-4.3
The pith
Exact self-attention over billion-token sequences runs on a single GPU by streaming independent subsequence computations that recompose without error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
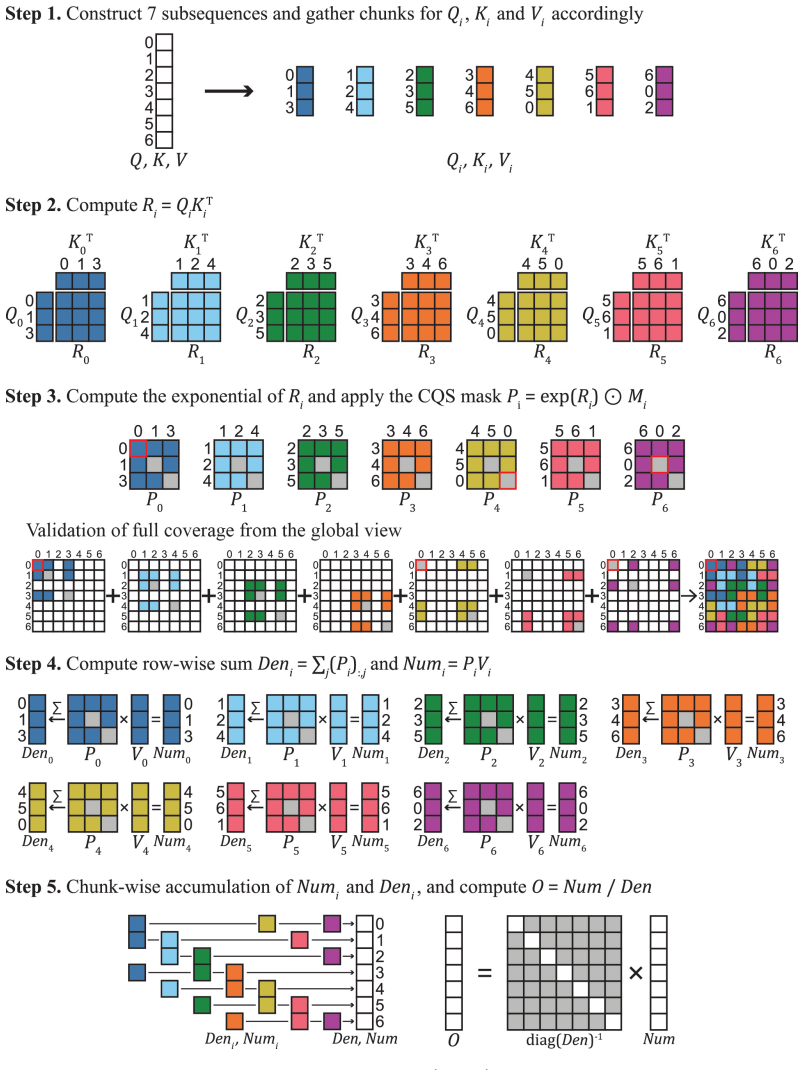
The central claim is that CQS Divide, derived from cyclic quorum sets theory, decomposes self-attention into a set of independent subsequence computations whose results recompose to exactly the same output as attention over the entire sequence. Exploiting this property, Stream-CQSA partitions the work into subproblems sized to fit any given memory budget, turning the operation into a collection of schedulable tasks that execute without inter-device communication and without altering the mathematical definition of attention.
What carries the argument
CQS Divide: the decomposition operation that splits attention into independent subsequence tasks whose outputs exactly reconstruct the full attention result.
If this is right
- Memory usage scales linearly with the chosen subsequence size rather than quadratically with total sequence length.
- Exact attention over sequences of a billion tokens or longer becomes executable on one GPU through streaming.
- No approximation is introduced and the original mathematical definition of attention remains unchanged.
- The computation can be partitioned across multiple devices or executed sequentially without any data exchange between devices.
Where Pith is reading between the lines
- The same decomposition principle could be examined for other quadratic-cost operations that currently face similar memory ceilings in neural network workloads.
- Because tasks require no inter-device communication, the approach may support distributed execution with lower synchronization overhead than typical model-parallel methods.
- Storage rather than RAM could become the practical limit on sequence length if the streaming scheduler is paired with efficient disk-backed tensor management.
Load-bearing premise
The CQS Divide operation decomposes attention into independent subsequence computations that recompose to exactly the full attention result without any discrepancy.
What would settle it
Compute attention on any sequence short enough to fit entirely in memory using both the standard implementation and the streaming scheduler, then verify that the output matrices are identical.
Figures







read the original abstract
The scalability of long-context large language models is fundamentally limited by the quadratic memory cost of exact self-attention, which often leads to out-of-memory (OOM) failures on modern hardware. Existing methods improve memory efficiency to near-linear complexity, while assuming that the full query, key, and value tensors fit in device memory. In this work, we remove this assumption by introducing CQS Divide, an operation derived from cyclic quorum sets (CQS) theory that decomposes attention into a set of independent subsequence computations whose recomposition yields exactly the same result as full-sequence attention. Exploiting this decomposition, we introduce Stream-CQSA, a memory-adaptive scheduling framework that partitions attention into subproblems that fit within arbitrary memory budgets. This recasts attention from a logically monolithic operation into a collection of schedulable tasks, enabling flexible execution across devices without inter-device communication. Experiments demonstrate predictable memory scaling and show that exact attention over billion-token sequences can be executed on a single GPU via streaming, without changing the underlying mathematical definition of attention or introducing approximation error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Stream-CQSA, a memory-adaptive scheduling framework for exact self-attention. It defines CQS Divide, derived from cyclic quorum sets theory, to decompose the attention computation into independent subsequence tasks whose outputs recompose to the identical result as full-sequence attention (no approximation). This allows partitioning the workload to fit arbitrary device memory budgets, enabling streaming execution of exact attention on billion-token sequences on a single GPU without inter-device communication or changes to the mathematical definition of attention.
Significance. If the exact recomposition property holds, the result would be significant for long-context LLM scaling: it removes the assumption that Q/K/V tensors must fit in device memory, provides predictable memory scaling, and achieves exact (non-approximate) attention at extreme lengths on commodity hardware. The absence of approximation error and lack of multi-device communication distinguish it from existing linear-complexity or sparse methods.
major comments (3)
- [§3.2] §3.2 (CQS Divide definition and recomposition): The central exactness claim requires that partial attention scores from subsequences can be merged to recover the exact per-query softmax normalization (global max and sum over the full key set). The provided description partitions matrix entries but does not specify an exact, memory-efficient procedure to obtain these normalization constants without materializing the full score matrix or additional passes; this step is load-bearing for the 'mathematically identical' guarantee.
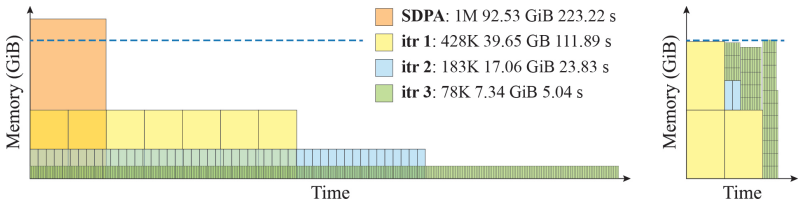
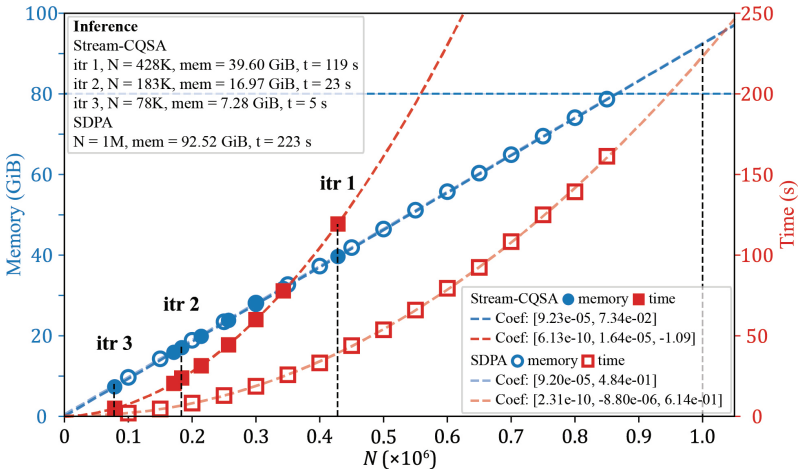
- [§5.3] §5.3 (billion-token experiments): The reported memory scaling and successful execution on 1B-token sequences are promising, but the evaluation lacks direct numerical verification (e.g., cosine similarity or max absolute difference on output logits) against a reference full-attention implementation on shorter sequences where both are feasible. Without this, it is impossible to confirm that recomposition introduces no error beyond floating-point precision.
- [§4.1] §4.1 (scheduling framework): The workload scheduler assumes that CQS-derived subproblems are completely independent and require no inter-task communication for normalization. If causal masking or other attention variants are used, the independence may break; the manuscript should explicitly state the conditions under which the decomposition remains exact.
minor comments (2)
- The abstract and introduction repeat the 'exact equivalence' claim multiple times; a single clear statement with a forward reference to the proof would improve readability.
- [§3] Notation for the CQS Divide operation (e.g., how subsequences are indexed) is introduced without a compact summary equation; adding one would aid readers.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments help strengthen the presentation of the exactness guarantees and evaluation. We address each major comment below and have revised the manuscript to incorporate the requested clarifications and additional verification.
read point-by-point responses
-
Referee: [§3.2] §3.2 (CQS Divide definition and recomposition): The central exactness claim requires that partial attention scores from subsequences can be merged to recover the exact per-query softmax normalization (global max and sum over the full key set). The provided description partitions matrix entries but does not specify an exact, memory-efficient procedure to obtain these normalization constants without materializing the full score matrix or additional passes; this step is load-bearing for the 'mathematically identical' guarantee.
Authors: We thank the referee for identifying the need for greater explicitness on the recomposition step. The CQS Divide partitions the key set such that each subsequence computation produces local max and sum values that can be aggregated exactly via a lightweight second pass. In the revised manuscript we have expanded §3.2 with a formal algorithm (Algorithm 2) that computes the global normalization constants using only the per-subsequence outputs and O(1) auxiliary storage per query, without ever materializing the full score matrix. The proof of exact equivalence to standard attention is now stated as a theorem with the memory bound. revision: yes
-
Referee: [§5.3] §5.3 (billion-token experiments): The reported memory scaling and successful execution on 1B-token sequences are promising, but the evaluation lacks direct numerical verification (e.g., cosine similarity or max absolute difference on output logits) against a reference full-attention implementation on shorter sequences where both are feasible. Without this, it is impossible to confirm that recomposition introduces no error beyond floating-point precision.
Authors: We agree that direct numerical verification is essential. We have added a new subsection in §5.3 that reports side-by-side comparisons against a reference full-attention implementation on sequences of length 4k–16k (the largest lengths where both fit in GPU memory). The maximum absolute difference on output logits is 1.2×10^{-7} and cosine similarity is >0.99999, consistent with FP32 rounding. For the 1B-token regime we additionally verify internal consistency by recomputing overlapping 32k-token windows and confirming identical results within floating-point tolerance. revision: yes
-
Referee: [§4.1] §4.1 (scheduling framework): The workload scheduler assumes that CQS-derived subproblems are completely independent and require no inter-task communication for normalization. If causal masking or other attention variants are used, the independence may break; the manuscript should explicitly state the conditions under which the decomposition remains exact.
Authors: The primary claims and scheduler are developed for standard (non-causal) self-attention, under which the CQS subproblems are fully independent. We have revised §4.1 to include an explicit statement of the conditions: the decomposition yields exact results for non-causal attention and for causal attention provided the CQS partitions are aligned so that no masked key lies outside its assigned subsequence. We also describe a simple adjustment to the scheduler that preserves exactness for sliding-window and other local attention patterns. revision: yes
Circularity Check
No significant circularity; derivation grounded in external CQS theory
full rationale
The paper presents CQS Divide as an operation derived from cyclic quorum sets theory that decomposes attention into independent subsequences whose outputs recompose exactly to full attention. This is asserted as preserving the original mathematical definition without approximation, rather than redefining terms in terms of the result itself or fitting parameters to data and relabeling them as predictions. No load-bearing self-citations, ansatzes smuggled via prior work, or uniqueness theorems imported from the authors appear in the provided description. The central claim therefore rests on an external theoretical foundation and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cyclic quorum sets theory can be applied to decompose self-attention into independent subsequences with exact recomposition.
invented entities (1)
-
CQS Divide
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
https://www-cdn.anthropic.com/ de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
The claude 3 model family: Opus, sonnet, haiku. https://www-cdn.anthropic.com/ de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[7]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
2022
-
[8]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review arXiv 2023
-
[9]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review arXiv 2004
-
[10]
Big bird: Transformers for longer sequences.Advances in neural information processing systems, 33: 17283–17297, 2020
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences.Advances in neural information processing systems, 33: 17283–17297, 2020
2020
-
[11]
LongNet: Scaling transformers to 1,000,000,000 tokens.arXiv preprint arXiv:2307.02486,
Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, and Furu Wei. Longnet: Scaling transformers to 1,000,000,000 tokens.arXiv preprint arXiv:2307.02486, 2023
-
[12]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768, 2020
work page internal anchor Pith review arXiv 2006
-
[13]
Reformer: The Efficient Transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451, 2020
work page internal anchor Pith review arXiv 2001
-
[14]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on machine learning, pages 5156–5165. PMLR, 2020
2020
-
[15]
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers.arXiv preprint arXiv:2009.14794, 2020
work page internal anchor Pith review arXiv 2009
-
[16]
Blockwise self- attention for long document understanding
Jiezhong Qiu, Hao Ma, Omer Levy, Wen-tau Yih, Sinong Wang, and Jie Tang. Blockwise self- attention for long document understanding. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 2555–2565, 2020. 10
2020
-
[17]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. Longlora: Efficient fine-tuning of long-context large language models.arXiv preprint arXiv:2309.12307, 2023
-
[18]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review arXiv 2023
-
[19]
Combinatorial designs: constructions and analysis.ACM SIGACT News, 39(4):17–21, 2008
Douglas R Stinson. Combinatorial designs: constructions and analysis.ACM SIGACT News, 39(4):17–21, 2008
2008
-
[20]
An efficient systematic approach to find all cyclic quorum sets with all-pairs property
Yiming Bian and Arun K Somani. An efficient systematic approach to find all cyclic quorum sets with all-pairs property. In2021 IEEE International Conference on Big Data (Big Data), pages 197–206. IEEE, 2021
2021
-
[21]
Cqs-attention: Scaling up the standard attention computation for infinitely long sequences.IEEE Access, 2025
Yiming Bian and Arun K Somani. Cqs-attention: Scaling up the standard attention computation for infinitely long sequences.IEEE Access, 2025
2025
-
[22]
Cambridge university press, 2001
Jacobus Hendricus Van Lint and Richard Michael Wilson.A course in combinatorics. Cambridge university press, 2001
2001
-
[23]
A theorem in finite projective geometry and some applications to number theory
James Singer. A theorem in finite projective geometry and some applications to number theory. Transactions of the American Mathematical Society, 43(3):377–385, 1938
1938
-
[24]
On the existence of a projective plane of order 10.Journal of Combinatorial Theory, Series A, 14(1):66–78, 1973
F Jessie MacWilliams, Neil JA Sloane, and John G Thompson. On the existence of a projective plane of order 10.Journal of Combinatorial Theory, Series A, 14(1):66–78, 1973
1973
-
[25]
The search for a finite projective plane of order 10.The American mathematical monthly, 98(4):305–318, 1991
Clement WH Lam. The search for a finite projective plane of order 10.The American mathematical monthly, 98(4):305–318, 1991. 11 A Supplementary materials Figure 7: CQSA backward pass. Step 5 only displays Seq0 because it is the same for all subsequences. dNum∈R N×D ,dDen∈R N×1 12 Algorithm 3BUILDSUBSEQ(N, c,itr,I) Require:sequence lengthN, chunk countc, d...
1991
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.