Stabilizing In-Context Multi-Source Domain Adaptation for Biomedical Images Through Controls
Pith reviewed 2026-07-05 01:55 UTC · model glm-5.2
The pith
Negative controls stabilize deep learning for biomedical imaging
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper's central claim is that meta-learning Batch Normalization adaptation, when stabilized by negative control samples included in the adaptation context set, can close the domain gap between training and new experimental batches in biomedical imaging — achieving near in-domain accuracy (0.930 vs. 0.939 in-domain) under mild shift and maintaining robust accuracy (0.894) under severe label shift where all competing methods collapse. The theoretical justification rests on an additive decomposition of Batch Normalization activation means into a domain-specific offset, a class-specific offset, and noise, under which combining controls and perturbed samples provably achieves lower mean-squar
What carries the argument
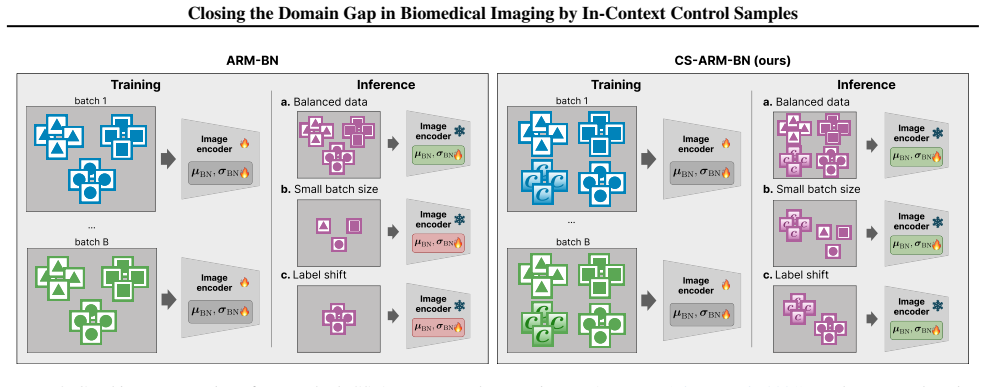
CS-ARM-BN (Control-Stabilized Adaptive Risk Minimization via Batch Normalization): a meta-learning method that computes adapted BN statistics from the union of negative control images and perturbed images from each target batch, rather than from perturbed samples alone. The adaptation function operates within the Adaptive Risk Minimization (ARM) framework, replacing running BN statistics with target-batch estimates during a single forward pass, with the model meta-trained episodically to expect control-conditioned normalization.
If this is right
- If batch effects in biomedical imaging are largely additive in BN activation space, then lightweight normalization-statistic adaptation suffices to neutralize them, making retraining or generative style transfer unnecessary for deployment across new batches.
- The control-stabilized context principle could extend to any domain where class-agnostic reference samples are structurally available — for instance, baseline measurements in clinical trials or sham conditions in neuroscience.
- The bias-variance decomposition suggests a concrete design guideline: the ratio of controls to perturbed samples in the context set should scale with the expected degree of label shift at deployment time.
Where Pith is reading between the lines
- The additive separability assumption (µ_obs = µ_domain + µ_class + ε) is most plausible when batch effects manifest as shifts in illumination, staining intensity, or microscope optics — conditions that may hold for cell painting but could break for modalities where technical variation interacts with biological signal.
- If the method generalizes beyond JUMP-CP, it could reduce the barrier to deploying pre-trained biomedical image classifiers across institutions, since adaptation requires only a single forward pass over controls plus target images rather than any labeled data or retraining.
- The principle of using structurally guaranteed reference samples as stabilization anchors may apply more broadly to test-time adaptation in non-biological domains where calibration samples are available (e.g., standardized test inputs for NLP models deployed in new domains).
Load-bearing premise
The theoretical justification depends on batch-specific technical variation and class-specific biological signal being additively separable in Batch Normalization activation space. If domain and class effects interact multiplicatively or non-linearly — for instance, if different mechanisms of action produce different feature shifts depending on the batch — the mean-squared-error analysis that motivates combining controls and perturbed samples no longer holds.
What would settle it
Test whether CS-ARM-BN's advantage over ARM-BN persists when the additive decomposition is violated — for example, by constructing synthetic batches where domain shift multiplicatively modulates class-specific feature directions, or by measuring interaction effects between batch identity and MoA label in BN activation space.
Figures


read the original abstract
Biomedical imaging data presents enormous potential for deep learning models to predict invaluable properties, such as diseases and drug effects. However, unavoidable alterations of the technical conditions cause batch effects: variations between groups of samples that are not due to any biological signal of interest. Batch effects greatly hinder the generalization abilities of deep learning models, preventing their practical use in the real world. Unsupervised Domain Adaptation (UDA) methods have been proposed to mitigate batch effects, but they usually assume that the data is comprised of only one source domain and one target domain, whereas biological datasets are comprised of multiple domains, both at training and at inference time. While Batch Normalization-based test-time and meta-learning adaptation methods offer a promising mechanism for domain alignment, we show that existing approaches exhibit degraded performance under the usual inference scenarios of small target batch sizes and label shift. We address these limitations by leveraging negative control samples, which are consistently present in every experimental batch in biological datasets, as stable context for adaptation. We propose CS-ARM-BN, a meta-learning BN adaptation method that uses controls both during training and inference to stabilize domain statistics. We perform a suite of experiments of Mechanism-Of-Action (MoA) classification, a crucial task for drug discovery, on the large JUMP-CP imaging dataset. Our experiments show that CS-ARM-BN substantially improves robustness to batch size and class distribution shifts, enabling practical use of deep learning models for biomedical images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CS-ARM-BN, a meta-learning BatchNorm adaptation method that incorporates negative control samples (unperturbed reference images) into the adaptation context to stabilize domain adaptation for biomedical imaging. The method extends Adaptive Risk Minimization (ARM-BN) by computing BN statistics from the union of control and perturbed samples at both training and inference time. The authors provide a bias-variance analysis (Eqs. 12-14, Appendix F) showing that combining controls and perturbed samples achieves a favorable bias-variance tradeoff compared to using either alone. Experiments on the JUMP-CP dataset across four scenarios (mild shift, strong cross-source shift, label shift, combined) demonstrate that CS-ARM-BN substantially outperforms existing BN-adaptation methods under label shift and small batch sizes, while remaining competitive under mild shift.
Significance. The paper addresses a practically important problem: batch effects in biomedical imaging are a well-known barrier to deploying deep learning models. The use of negative controls as a stabilizing context is a natural and domain-appropriate idea. The experimental design is thorough, including four scenarios, multiple baselines (DANN, CORAL, TENT, AdaBN, ARM-BN, ARM-CML, StyleID, foundation models), ablations controlling for batch size (Tables A8, A9), and a ViT architecture (Table A10). The bias-variance analysis in Appendix F is a clean, parameter-free derivation under stated assumptions. The claim that meta-learning approaches nearly close the domain gap (0.935 vs. 0.939 in-domain) is notable. Code and data are stated to be available. The work is relevant to the journal's scope at the intersection of machine learning and biomedical imaging.
major comments (3)
- The bias-variance analysis (Eqs. 12-14, Appendix F) predicts that the controls-only estimator has zero bias and variance σ²/C, while CS-ARM-BN has bias (L/M)²·μ̄²_class and variance σ²/M. In the label-shift experiments (Section 5.3, Appendix D.2.1), C=288 controls and L=36 perturbed samples are used. Under the additive model, the controls-only estimator should therefore have very low variance (σ²/288) and zero bias, making it the clear MSE winner over CS-ARM-BN (which includes 36 biased perturbed samples). Yet Table 4 shows ARM-BEN (the meta-learned controls-only variant) achieves only 0.663 on S3→S8 at α=0.01, while CS-ARM-BN achieves 0.825. This 0.16 gap is too large to be explained by the MSE framework as presented. The paper's own theory predicts controls-only should win in this regime, but empirically it loses badly. This suggests the bias-variance analysis is not the primary driver
- The additive decomposition μ_obs,x = μ_domain + μ_class(x) + ε_x (Eq. 15, Appendix F.1) is the load-bearing assumption for the entire MSE analysis. If domain and class effects interact non-linearly (e.g., different MoAs produce different feature shifts depending on the batch), the MSE analysis breaks down and the theoretical justification for CS-ARM-BN's advantage over controls-only or perturbed-only estimators no longer holds. The paper does not test this assumption empirically. Given the concern above (that the theory's prediction contradicts the experimental results), the authors should either (a) empirically validate the additive decomposition in BN activation space, or (b) reframe the MSE analysis as a motivating intuition rather than a justification, and identify the actual mechanism (likely the meta-learning training procedure) that drives the observed advantage.
- Table 1 reports CS-ARM-BN at 0.930±0.019 for the mild-shift scenario, which is slightly lower than ARM-BN at 0.935±0.018. The abstract and main text (e.g., line 'CS-ARM-BN substantially improves robustness') emphasize CS-ARM-BN's advantages, but the paper should more clearly acknowledge that in the mild-shift setting, CS-ARM-BN does not improve over ARM-BN. The value of CS-ARM-BN is specifically in the label-shift and small-batch regimes, and the framing should reflect this more precisely.
minor comments (9)
- Table 2: CS-ARM-BN achieves 0.776 on S8→S3, which is lower than ARM-BN's 0.795. This is mentioned in the text ('less stable') but the discussion could be more precise about when CS-ARM-BN underperforms ARM-BN.
- Section 3, Eqs. (10)-(11): The notation uses u to denote BN-layer activations, but u is introduced as an element of C_β (the combined context set of images). It would be clearer to write u as the activation f(x;w) rather than the image itself.
- Table A9: The 'Ada-BN (perturbed + controls)' row shows 0.785 at α=0.01, which is substantially better than ARM-BN with controls (0.752). This suggests that for AdaBN, simply adding controls helps a lot, but for ARM-BN, adding controls helps less. This interaction is not discussed.
- The abstract states 'enabling practical use of deep learning models for biomedical images' — this is a strong claim that could be tempered to 'improving robustness of deep learning models for biomedical images under label shift and small batch sizes.'
- Figure 1: The y-axis label 'MoA Classification Accuracy' could include the range for clarity. The green/orange color coding is mentioned in the caption but not consistently used in other figures.
- Table 4: BEN (w/o meta-learning) achieves 0.125 across all conditions, which is chance-level for 8-class classification. This is mentioned as 'performs poorly' but it would help to explicitly state this is chance-level.
- Appendix D.4, Table A11: The claim that plate-level alignment yields better results than source-level is interesting but the sample sizes differ dramatically (288 vs. 56,160). The paper should discuss whether the improvement is due to finer alignment or simply due to having more adaptation domains.
- The paper cites Dong et al. (2026) in the related work; this appears to be a future-dated reference. Please verify.
- Algorithm 1 and Algorithm 2 are identical; the second is labeled as the 'in-context view' but contains the same pseudocode. Consider merging or differentiating them.
Simulated Author's Rebuttal
We thank the referee for a careful and constructive review. The comments on the tension between the MSE analysis and the experimental results, on the untested additive assumption, and on the framing of the mild-shift results are all well-taken. Below we respond point by point.
read point-by-point responses
-
Referee: The bias-variance analysis predicts controls-only should win in the label-shift regime (C=288, L=36), but ARM-BEN achieves only 0.663 while CS-ARM-BN achieves 0.825 on S3→S8 at α=0.01. The theory's prediction contradicts the experimental results.
Authors: The referee is correct that the MSE analysis, taken in isolation, does not explain the full gap between ARM-BEN and CS-ARM-BN. We acknowledge this tension and will revise the manuscript to address it explicitly. The key issue is that the MSE analysis in Appendix F concerns the estimation quality of a single BN-layer mean μ_domain, not end-to-end classification accuracy. It captures one component of the story—statistical estimation quality of BN statistics—but not the full picture. The critical missing element is the meta-learning training procedure. In CS-ARM-BN, the model is trained episodically with both controls and perturbed samples in the context set, so the network learns to leverage the combined context effectively at test time. In ARM-BEN, the model is trained with only controls in the context, meaning the network never encounters perturbed samples during adaptation in training. This creates a train-test mismatch: at test time, ARM-BEN must adapt BN statistics using only controls, but the downstream classifier was never trained to operate on features normalized by control-only statistics. The MSE analysis does not account for this learned coupling between the adaptation mechanism and the prediction head. We will add a paragraph in Section 3 and a remark in Appendix F clarifying that the MSE analysis provides a statistical intuition for why combining controls and perturbed samples is beneficial for BN statistic estimation, but that the empirical advantage of CS-ARM-BN over ARM-BEN is additionally driven by the meta-learning training procedure, which trains the model to expect and exploit the combined context. We will also add a note that the MSE framework considers a single BN layer in isolation and does not model how estimation errors propagate through a deep网络. revision: partial
-
Referee: The additive decomposition μ_obs,x = μ_domain + μ_class(x) + ε_x is the load-bearing assumption for the MSE analysis. If domain and class effects interact non-linearly, the analysis breaks down. The authors should either empirically validate the additive decomposition or reframe the MSE analysis as motivating intuition.
Authors: We agree that the additive decomposition is an untested assumption and that the referee's concern is well-founded, especially given the tension noted in the previous comment. We will take option (b): we will reframe the MSE analysis as a motivating intuition rather than a rigorous justification, and we will explicitly identify the meta-learning training procedure as an additional mechanism driving the observed advantage. Specifically, we will revise the text in Section 3 (around Eqs. 12–14) and Appendix F to state clearly that: (1) the additive model is a simplifying assumption that provides intuition for the bias-variance tradeoff in BN statistic estimation; (2) the actual mechanism behind CS-ARM-BN's advantage is likely a combination of favorable BN statistic estimation (as captured by the MSE analysis) and the meta-learning training procedure (which trains the model to exploit the combined control-perturbed context); and (3) we do not claim the additive decomposition fully explains the experimental results. We believe this reframing is the honest and accurate characterization of what the theory does and does not show. We considered empirically validating the additive decomposition in BN activation space, but given that the theory already does not fully explain the experimental results (as the referee correctly identifies in the previous comment), we think reframing is the more appropriate response. revision: yes
-
Referee: Table 1 shows CS-ARM-BN at 0.930±0.019, slightly lower than ARM-BN at 0.935±0.018 in the mild-shift scenario. The paper should more clearly acknowledge that CS-ARM-BN does not improve over ARM-BN in this setting, and the framing should reflect that CS-ARM-BN's value is specifically in label-shift and small-batch regimes.
Authors: The referee is correct. In the mild-shift setting, CS-ARM-BN does not improve over ARM-BN, and the difference (0.930 vs. 0.935) is within the standard deviations. We will revise the abstract, introduction, and Section 5.1 to state this explicitly. Specifically, we will: (1) modify the abstract to say that CS-ARM-BN substantially improves robustness specifically under label shift and small batch sizes, while remaining competitive under mild shift; (2) add a sentence in Section 5.1 noting that CS-ARM-BN does not improve over ARM-BN in the mild-shift regime, which is expected since the bias-variance advantage of including controls is negligible when the perturbed-only estimator already has low bias (balanced classes) and sufficient samples; and (3) adjust the contribution bullet points to clarify that the value of CS-ARM-BN is in the label-shift and small-batch regimes. This more precise framing accurately reflects the experimental results. revision: yes
Circularity Check
No significant circularity: the MSE analysis is a parameter-free derivation from stated assumptions, and the central empirical claims are validated against the external JUMP-CP dataset with no self-citation chain.
full rationale
The paper's theoretical justification (Eqs. 12-14, Appendix F) is a self-contained, parameter-free derivation from the additive decomposition assumption (Eq. 15). No parameter is fitted to data and then 'predicted.' The ARM framework is cited from Zhang et al. (2021) with no author overlap. The method builds on ARM-BN, but this is standard incremental work, not circular self-citation. The central empirical claims are tested on the external JUMP-CP dataset with ablations controlling for batch-size effects (Tables A8, A9). The skeptic's concern that the MSE analysis does not fully explain the empirical advantage of CS-ARM-BN over controls-only (ARM-BEN) is a correctness/explanatory-power concern, not a circularity issue: the paper does not claim the MSE analysis quantitatively predicts the exact performance gap, but rather motivates the bias-variance tradeoff qualitatively. The derivation chain has no step that reduces to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (5)
- Learning rate =
0.001
- Batch size (ARM-BN/CS-ARM-BN) =
64-128
- Negative controls batch size =
64-128
- DANN λ =
not specified which selected
- CORAL γ =
not specified which selected
axioms (4)
- domain assumption BN activation mean decomposes additively as µ_obs,x = µ_domain + µ_class(x) + ε_x
- domain assumption Batches are independent and drawn from a meta-distribution µ
- domain assumption Negative controls carry no class-specific signal (µ_class = 0 for controls)
- standard math Noise ε_x is zero-mean with variance σ²
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Ando, D. M., McLean, C. Y., and Berndl, M. (2017). Improving phenotypic measurements in high-content imaging screens. bioRxiv , page 161422
work page 2017
-
[3]
D., van Dijk, R., Carpenter, A
Arevalo, J., Su, E., Ewald, J. D., van Dijk, R., Carpenter, A. E., and Singh, S. (2024). Evaluating batch correction methods for image-based cell profiling. Nature Communications 2024 15:1 , 15:1--12
work page 2024
-
[4]
Baxter, J. (1998). Theoretical models of learning to learn. In Learning to learn , pages 71--94. Springer
work page 1998
-
[5]
Ben-David, S., Blitzer, J., Crammer, K., and Pereira, F. (2006). Analysis of representations for domain adaptation. Advances in neural information processing systems , 19
work page 2006
-
[6]
Blanchard, G., Lee, G., and Scott, C. (2011). Generalizing from several related classification tasks to a new unlabeled sample. In Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., and Weinberger, K., editors, Advances in Neural Information Processing Systems , volume 24. Curran Associates, Inc
work page 2011
-
[7]
Boudiaf, M., Mueller, R., Ayed, I. B., and Bertinetto, L. (2022). Parameter-free online test-time adaptation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition , 2022-June:8334--8343
work page 2022
-
[8]
Bousmalis, K., Silberman, N., Dohan, D., Erhan, D., and Krishnan, D. (2017). Unsupervised pixel-level domain adaptation with generative adversarial networks. Proceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017 , 2017-January:95--104
work page 2017
-
[9]
Bray, M.-A., Carpenter, A., of MIT, B. I., and Platform, H. I. (2017). Advanced assay development guidelines for image-based high content screening and analysis. Assay Guidance Manual
work page 2017
-
[10]
N., Ackerman, J., Alix, E., Ando, D
Chandrasekaran, S. N., Ackerman, J., Alix, E., Ando, D. M., Arevalo, J., Bennion, M., Boisseau, N., Borowa, A., Boyd, J. D., Brino, L., Byrne, P. J., Ceulemans, H., Ch’ng, C., Cimini, B. A., Clevert, D.-A., Deflaux, N., Doench, J. G., Dorval, T., Doyonnas, R., Dragone, V., Engkvist, O., Faloon, P. W., Fritchman, B., Fuchs, F., Garg, S., Gilbert, T. J., Gl...
work page 2023
-
[11]
Chen, W., Zhao, Y., Chen, X., Yang, Z., Xu, X., Bi, Y., Chen, V., Li, J., Choi, H., Ernest, B., Tran, B., Mehta, M., Kumar, P., Farmer, A., Mir, A., Mehra, U. A., Li, J. L., Moos, M., Xiao, W., and Wang, C. (2020). A multicenter study benchmarking single-cell rna sequencing technologies using reference samples. Nature Biotechnology 2020 39:9 , 39:1103--1114
work page 2020
-
[12]
Chung, J., Hyun, S., and Heo, J. P. (2024). Style injection in diffusion: A training-free approach for adapting large-scale diffusion models for style transfer. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition , pages 8795--8805
work page 2024
-
[13]
Dong, M., Adduri, A., Gautam, D., Carpenter, C., Shah, R., Ricci-Tam, C., Kluger, Y., Burke, D. P., and Roohani, Y. H. (2026). Stack: In-context learning of single-cell biology. bioRxiv
work page 2026
-
[14]
Farahani, A., Voghoei, S., Rasheed, K., and Arabnia, H. R. (2020). A brief review of domain adaptation. ArXiv , pages 877--894
work page 2020
-
[15]
Finn, C., Abbeel, P., and Levine, S. (2017). Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning , pages 1126--1135. PMLR
work page 2017
-
[16]
Ganin, Y. and Lempitsky, V. (2014). Unsupervised domain adaptation by backpropagation. 32nd International Conference on Machine Learning, ICML 2015 , 2:1180--1189
work page 2014
-
[17]
Gong, T., Jeong, J., Kim, T., Kim, Y., Shin, J., and Lee, S. J. (2022). Note: Robust continual test-time adaptation against temporal correlation. Advances in Neural Information Processing Systems , 35
work page 2022
-
[18]
Graham, B., El-Nouby, A., Touvron, H., Stock, P., Joulin, A., Jégou, H., and Douze, M. (2021). Levit: a vision transformer in convnet's clothing for faster inference. Proceedings of the IEEE International Conference on Computer Vision , pages 12239--12249
work page 2021
-
[19]
Multi-Source Domain Adaptation with Mixture of Experts
Guo, J., Shah, D. J., and Barzilay, R. (2018). Multi-source domain adaptation with mixture of experts. arXiv preprint arXiv:1809.02256
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Haghverdi, L., Lun, A. T., Morgan, M. D., and Marioni, J. C. (2018). Batch effects in single-cell rna-sequencing data are corrected by matching mutual nearest neighbors. Nature Biotechnology 2018 36:5 , 36:421--427
work page 2018
-
[21]
F., Matsoukas, C., Leuchowius, K
Haslum, J. F., Matsoukas, C., Leuchowius, K. J., and Smith, K. (2023). Bridging generalization gaps in high content imaging through online self-supervised domain adaptation. IEEE Workshop/Winter Conference on Applications of Computer Vision , pages 7723--7732
work page 2023
-
[22]
He, K., Zhang, X., Ren, S., and Sun, J. (2015). Deep residual learning for image recognition. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition , 2016-December:770--778
work page 2015
-
[23]
Hie, B., Bryson, B., and Berger, B. (2019). Efficient integration of heterogeneous single-cell transcriptomes using scanorama. Nature biotechnology , 37:685--691
work page 2019
-
[24]
Hochreiter, S., Younger, A. S., and Conwell, P. R. (2001). Learning to learn using gradient descent. In International conference on artificial neural networks , pages 87--94. Springer
work page 2001
-
[25]
Hughes, J. P., Rees, S. S., Kalindjian, S. B., and Philpott, K. L. (2011). Principles of early drug discovery. British Journal of Pharmacology , 162:1239
work page 2011
-
[26]
Ioffe, S. and Szegedy, C. (2015). Batch normalization: accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37 , ICML'15, page 448–456. JMLR.org
work page 2015
-
[27]
Johnson, W. E., Li, C., and Rabinovic, A. (2007). Adjusting batch effects in microarray expression data using empirical bayes methods. Biostatistics (Oxford, England) , 8:118--127
work page 2007
-
[28]
M., Halawa, M., König, T., Gnutt, D., and Zapata, P
Kim, V., Adaloglou, N., Osterland, M., Morelli, F. M., Halawa, M., König, T., Gnutt, D., and Zapata, P. A. M. (2025). Self-supervision advances morphological profiling by unlocking powerful image representations. Scientific Reports 2025 15:1 , 15:1--15
work page 2025
-
[29]
Kimura, M. and Hino, H. (2024). A short survey on importance weighting for machine learning. arXiv preprint arXiv:2403.10175
-
[30]
Knowles, J. and Gromo, G. (2003). A guide to drug discovery: Target selection in drug discovery. Nature reviews. Drug discovery , 2:63--69
work page 2003
-
[31]
Korsunsky, I., Millard, N., Fan, J., Slowikowski, K., Zhang, F., Wei, K., Baglaenko, Y., Brenner, M., ru Loh, P., and Raychaudhuri, S. (2019). Fast, sensitive and accurate integration of single-cell data with harmony. Nature Methods 2019 16:12 , 16:1289--1296
work page 2019
-
[32]
V., Morse, K., Makes, M., Mabey, B., and Earnshaw, B
Kraus, O., Kenyon-Dean, K., Saberian, S., Fallah, M., McLean, P., Leung, J., Sharma, V., Khan, A., Balakrishnan, J., Celik, S., Beaini, D., Sypetkowski, M., Cheng, C. V., Morse, K., Makes, M., Mabey, B., and Earnshaw, B. (2024). Masked autoencoders for microscopy are scalable learners of cellular biology. Proceedings of the IEEE Computer Society Conferenc...
work page 2024
-
[33]
Lee, J., Jung, D., Lee, S., Park, J., Shin, J., Hwang, U., and Yoon, S. (2024). Entropy is not enough for test-time adaptation: From the perspective of disentangled factors. 12th International Conference on Learning Representations, ICLR 2024
work page 2024
-
[34]
Leek, J. T., Scharpf, R. B., Bravo, H. C., Simcha, D., Langmead, B., Johnson, W. E., Geman, D., Baggerly, K., and Irizarry, R. A. (2010). Tackling the widespread and critical impact of batch effects in high-throughput data. Nature reviews. Genetics , 11:10.1038/nrg2825
-
[35]
Li, Y., Wang, N., Shi, J., Liu, J., and Hou, X. (2016). Revisiting batch normalization for practical domain adaptation. International Conference on Learning Representations
work page 2016
-
[36]
Lin, A. and Lu, A. (2022). Incorporating knowledge of plates in batch normalization improves generalization of deep learning for microscopy images. In Knowles, D. A., Mostafavi, S., and Lee, S.-I., editors, Proceedings of the 17th Machine Learning in Computational Biology meeting , volume 200 of Proceedings of Machine Learning Research , pages 74--93. PMLR
work page 2022
-
[37]
Liu, M.-Y. and Tuzel, O. (2016). Coupled generative adversarial networks. In Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., and Garnett, R., editors, Advances in Neural Information Processing Systems , volume 29. Curran Associates, Inc
work page 2016
-
[38]
Lopez, R., Regier, J., Cole, M. B., Jordan, M. I., and Yosef, N. (2018). Deep generative modeling for single-cell transcriptomics. Nature methods , 15:1053--1058
work page 2018
-
[39]
D., Büttner, M., Chaichoompu, K., Danese, A., Interlandi, M., Mueller, M
Luecken, M. D., Büttner, M., Chaichoompu, K., Danese, A., Interlandi, M., Mueller, M. F., Strobl, D. C., Zappia, L., Dugas, M., Colomé-Tatché, M., and Theis, F. J. (2021). Benchmarking atlas-level data integration in single-cell genomics. Nature Methods 2021 19:1 , 19:41--50
work page 2021
-
[40]
Marsden, R. A., Döbler, M., and Yang, B. (2023). Universal test-time adaptation through weight ensembling, diversity weighting, and prior correction. Proceedings - 2024 IEEE Winter Conference on Applications of Computer Vision, WACV 2024 , pages 2543--2553
work page 2023
-
[41]
Palma, A., Theis, F. J., and Lotfollahi, M. (2025). Predicting cell morphological responses to perturbations using generative modeling. Nature Communications , 16:1--19
work page 2025
-
[42]
Park, S., Yang, S., Choo, J., and Yun, S. (2023). Label shift adapter for test-time adaptation under covariate and label shifts. Proceedings of the IEEE International Conference on Computer Vision , pages 16375--16385
work page 2023
-
[43]
D., Shen, C., Gross, T., Min, J., Garda, S., Yuan, B., Schumacher, L
Peidli, S., Green, T. D., Shen, C., Gross, T., Min, J., Garda, S., Yuan, B., Schumacher, L. J., Taylor-King, J. P., Marks, D. S., Luna, A., Blüthgen, N., and Sander, C. (2023). sc P erturb: Harmonized single-cell perturbation data. bioRxiv , page 2022.08.20.504663
work page 2023
-
[44]
Peng, X., Bai, Q., Xia, X., Huang, Z., Saenko, K., and Wang, B. (2019). Moment matching for multi-source domain adaptation. In Proceedings of the IEEE/CVF international conference on computer vision , pages 1406--1415
work page 2019
-
[45]
Shimodaira, H. (2000). Improving predictive inference under covariate shift by weighting the log-likelihood function. Journal of statistical planning and inference , 90(2):227--244
work page 2000
-
[46]
Stirling, D. R., Swain-Bowden, M. J., Lucas, A. M., Carpenter, A. E., Cimini, B. A., and Goodman, A. (2021). Cellprofiler 4: improvements in speed, utility and usability. BMC Bioinformatics , 22:433
work page 2021
-
[47]
M., Hao, Y., Stoeckius, M., Smibert, P., and Satija, R
Stuart, T., Butler, A., Hoffman, P., Hafemeister, C., Papalexi, E., Mauck, W. M., Hao, Y., Stoeckius, M., Smibert, P., and Satija, R. (2019). Comprehensive integration of single-cell data. Cell , 177:1888--1902.e21
work page 2019
-
[48]
Sun, B., Feng, J., and Saenko, K. (2015). Return of frustratingly easy domain adaptation. 30th AAAI Conference on Artificial Intelligence, AAAI 2016 , pages 2058--2065
work page 2015
-
[49]
R., Haque, I., and Earnshaw, B
Sypetkowski, M., Rezanejad, M., Saberian, S., Kraus, O., Urbanik, J., Taylor, J., Mabey, B., Victors, M., Yosinski, J., Sereshkeh, A. R., Haque, I., and Earnshaw, B. (2023). R x R x1: A dataset for evaluating experimental batch correction methods. IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops , 2023-June:4285--4294
work page 2023
-
[50]
Taigman, Y., Polyak, A., and Wolf, L. (2016). Unsupervised cross-domain image generation. ArXiv , abs/1611.02200
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[51]
N., Singh, D., Revanur, A., et al
Venkat, N., Kundu, J. N., Singh, D., Revanur, A., et al. (2020). Your classifier can secretly suffice multi-source domain adaptation. Advances in Neural Information Processing Systems , 33:4647--4659
work page 2020
-
[52]
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., and Darrell, T. (2021). TENT : Fully test-time adaptation by entropy minimization. In International Conference on Learning Representations
work page 2021
-
[53]
Wang, Q., Fink, O., Gool, L. V., and Dai, D. (2022). Continual test-time domain adaptation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition , 2022-June:7191--7201
work page 2022
-
[54]
Wen, J., Greiner, R., and Schuurmans, D. (2020). Domain aggregation networks for multi-source domain adaptation. In International conference on machine learning , pages 10214--10224. PMLR
work page 2020
-
[55]
Yang, L., Balaji, Y., Lim, S.-N., and Shrivastava, A. (2020). Curriculum manager for source selection in multi-source domain adaptation. In European conference on computer vision , pages 608--624. Springer
work page 2020
-
[56]
Zellinger, W., Grubinger, T., Lughofer, E., Natschl \"a ger, T., and Saminger-Platz, S. (2017). Central moment discrepancy (cmd) for domain-invariant representation learning. In International Conference on Learning Representations (ICLR)
work page 2017
-
[57]
A., de Borja, R., Svensson, V., Thomas, N., Thakar, N., Lai, I., Winters, A., Khan, U., Jones, M
Zhang, J., Ubas, A. A., de Borja, R., Svensson, V., Thomas, N., Thakar, N., Lai, I., Winters, A., Khan, U., Jones, M. G., Tran, V., Pangallo, J., Papalexi, E., Sapre, A., Nguyen, H., Sanderson, O., Nigos, M., Kaplan, O., Schroeder, S., Hariadi, B., Marrujo, S., Salvino, C. C. A., Gallareta Olivares, G., Koehler, R., Geiss, G., Rosenberg, A., Roco, C., Mer...
work page 2025
-
[58]
Zhang, M., Marklund, H., Dhawan, N., Gupta, A., Levine, S., and Finn, C. (2021). Adaptive R isk M inimization: learning to adapt to domain shift. In Proceedings of the 35th International Conference on Neural Information Processing Systems , NeurIPS '21, Red Hook, NY, USA. Curran Associates Inc
work page 2021
-
[59]
Zhao, H., Liu, Y., Alahi, A., and Lin, T. (2023). On pitfalls of test-time adaptation. Proceedings of Machine Learning Research , 202:42058--42080
work page 2023
-
[60]
Zhao, H., Zhang, S., Wu, G., Moura, J. M., Costeira, J. P., and Gordon, G. J. (2018). Adversarial M ultiple S ource D omain A daptation. Advances in neural information processing systems , 31
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.