Recognition: unknown
DiP-SD: Distributed Pipelined Speculative Decoding for Efficient LLM Inference at the Edge
Pith reviewed 2026-05-09 23:37 UTC · model grok-4.3
The pith
DiP-SD maximizes expected accepted tokens per unit time by distributing draft generation to devices and pipelining verification batches on the edge server.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
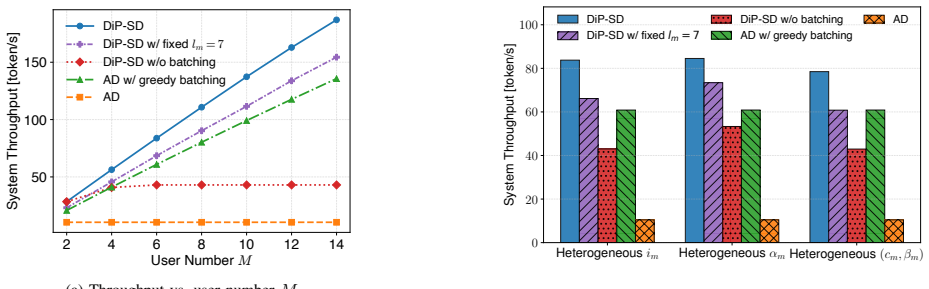
The paper claims that a throughput objective defined as the expected number of accepted tokens per unit time can be maximized by scanning possible batch numbers and iteratively solving an association subproblem for user-to-batch assignment together with a draft-length subproblem; when applied to a device-edge setup this yields up to 17.89 times the throughput of plain autoregressive decoding and 1.93 times the throughput of autoregressive decoding with greedy batching.
What carries the argument
The throughput-maximization objective that treats the expected number of accepted tokens per unit time as the quantity to optimize, solved by scanning batch counts and alternating between a user-batch association subproblem and an integer draft-length subproblem.
If this is right
- Batching and pipelining together sustain higher token acceptance rates under simultaneous multi-user load than either technique alone.
- Draft lengths become tunable per user to balance local generation speed against server verification time.
- The edge server can process more concurrent requests without increasing its own compute capacity.
- Overall system latency drops because drafting happens in parallel on devices while verification runs in overlapped phases.
Where Pith is reading between the lines
- The same alternating-subproblem structure might apply to other hierarchical setups where light work is pushed to clients and heavy verification stays centralized.
- If acceptance rates prove sensitive to specific model pairs, an online estimator for the objective could replace the static scan.
- Network jitter between devices and server could shrink the pipelining benefit, suggesting a follow-up model that includes transmission time explicitly.
Load-bearing premise
The optimization assumes that acceptance rates and generation times can be modeled accurately enough to choose batches and draft lengths without incurring large unaccounted overhead from network delays or model-specific effects.
What would settle it
A real-device measurement in which the observed tokens accepted per second under the proposed batch-and-draft schedule falls below twice the rate of simple batched autoregressive decoding would falsify the throughput gain.
Figures



read the original abstract
Speculative decoding has emerged as a promising technique for large language model (LLM) inference by accelerating autoregressive decoding via draft-then-verify. This paper studies a new edge scenario with multi-user inference, where draft tokens are generated locally on devices and subsequently offloaded to a centralized edge server for batch verification. The key challenge is to sustain high throughput under coupled decisions of (i) batching and pipeline scheduling and (ii) per user draft token length. We propose DiP-SD, which exploits two complementary parallelism dimensions: device-level distributed drafting and phase-level draft-verify pipelining. We formulate a throughput-maximization objective, defined as the expected number of accepted tokens per unit time, and jointly optimize the number of batches, user-to-batch assignment, and integer draft lengths. To solve the resulting fractional mixed-integer program, DiP-SD scans the batch number and iteratively alternates between an association subproblem and a draft-length subproblem. Numerical results under a Qwen3-1.7B/Qwen3-32B device-edge deployment show that DiP-SD achieves up to 17.89x throughput over autoregressive decoding (AD) and 1.93x over AD with greedy batching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiP-SD for multi-user speculative decoding at the edge, where devices generate draft tokens locally and an edge server performs batched verification. It defines throughput as the expected number of accepted tokens per unit time and jointly optimizes batch count, user-to-batch assignments, and integer draft lengths via a fractional mixed-integer program solved by scanning batch numbers and alternating between association and draft-length subproblems. Experiments with a Qwen3-1.7B/Qwen3-32B device-edge pair report up to 17.89x throughput over autoregressive decoding and 1.93x over greedy batching.
Significance. If the modeling assumptions hold and the reported gains are reproducible, DiP-SD would provide a practical framework for scaling speculative decoding to multi-user edge deployments by combining distributed drafting with pipelined verification. The external objective (expected accepted tokens per unit time) and the explicit handling of batching plus draft-length coupling are strengths; the approach could influence distributed LLM serving if validated beyond the specific model pair.
major comments (3)
- [Formulation and objective] Formulation of the throughput objective (abstract and §3): acceptance probabilities are treated as fixed or pre-computable inputs independent of batch count, user-to-batch mapping, and draft lengths. No analysis or sensitivity experiments address how batching alters KV-cache behavior, scheduling, or stochastic acceptance rates, which directly undermines whether the optimized parameters deliver the claimed throughput in deployment.
- [Optimization algorithm] Solution method (§4): the alternating optimization between association and draft-length subproblems after batch-number scanning has no convergence proof, no comparison to exact MIP solvers or other heuristics, and no reported overhead relative to inference time. This leaves open whether the procedure reaches a high-quality solution or simply fits the reported numbers.
- [Experiments] Numerical results (abstract and experimental section): the headline 17.89x and 1.93x figures are given without error bars, without description of how acceptance probabilities were measured or estimated across prompts, and without accounting for communication/synchronization latency in the distributed draft-verify pipeline. These omissions make the central performance claim difficult to verify or generalize.
minor comments (2)
- [Abstract] Clarify in the abstract and introduction whether the acceptance-rate model is prompt-dependent or averaged; the current wording leaves the measurement procedure ambiguous.
- [Introduction] Add a short discussion of related work on pipelined speculative decoding and edge offloading to better situate the contribution.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We address each of the major concerns point by point below, indicating the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: Formulation of the throughput objective (abstract and §3): acceptance probabilities are treated as fixed or pre-computable inputs independent of batch count, user-to-batch mapping, and draft lengths. No analysis or sensitivity experiments address how batching alters KV-cache behavior, scheduling, or stochastic acceptance rates, which directly undermines whether the optimized parameters deliver the claimed throughput in deployment.
Authors: We thank the referee for highlighting this modeling assumption. In DiP-SD, acceptance probabilities are indeed pre-computed from offline measurements on representative prompts for the Qwen3 device-edge pair, treating them as constants to enable tractable optimization. This is a common simplification in speculative decoding literature to focus on the optimization of scheduling parameters. However, we acknowledge that batching can influence KV-cache usage and potentially acceptance rates due to scheduling variations. The reported throughput gains are measured end-to-end in our deployment, incorporating actual acceptance behavior. To address the concern, we will revise §3 to explicitly state the assumption and add a sensitivity analysis subsection in the experiments, evaluating acceptance rates across different batch configurations. revision: partial
-
Referee: Solution method (§4): the alternating optimization between association and draft-length subproblems after batch-number scanning has no convergence proof, no comparison to exact MIP solvers or other heuristics, and no reported overhead relative to inference time. This leaves open whether the procedure reaches a high-quality solution or simply fits the reported numbers.
Authors: The alternating optimization is proposed as an efficient heuristic for the fractional mixed-integer program, which is NP-hard in general. We do not claim global optimality or provide a convergence proof, as the subproblems are solved iteratively until stabilization, which occurs rapidly in our experiments. Exact MIP solvers were not compared due to scalability issues with the fractional nature and integer constraints for larger user counts. We will add a discussion on the heuristic nature and report the computational overhead of the optimization, which is negligible (on the order of seconds) compared to inference times. Additionally, we will include a comparison to a greedy baseline to demonstrate the quality of the solutions obtained. revision: yes
-
Referee: Numerical results (abstract and experimental section): the headline 17.89x and 1.93x figures are given without error bars, without description of how acceptance probabilities were measured or estimated across prompts, and without accounting for communication/synchronization latency in the distributed draft-verify pipeline. These omissions make the central performance claim difficult to verify or generalize.
Authors: We agree that additional details are needed for reproducibility. The acceptance probabilities were estimated by running the draft model on a set of 100 diverse prompts and measuring the average acceptance rate per draft length. We will include error bars by reporting mean and standard deviation over multiple runs with different prompt sets. Regarding communication and synchronization latency, in our edge deployment setup, these are included in the measured end-to-end throughput as the pipeline accounts for data transfer times between devices and server. We will clarify this in the experimental section and provide more details on the measurement methodology. revision: yes
Circularity Check
No significant circularity; objective and solver are externally defined
full rationale
The paper defines its core objective as the expected number of accepted tokens per unit time, an external performance metric independent of the decision variables (batch count, assignments, draft lengths). The solution procedure—scanning batch numbers and alternating between association and draft-length subproblems—is presented as a standard heuristic for the resulting fractional mixed-integer program, without any reduction of the claimed throughput gains to a fitted parameter or self-referential definition. No self-citations appear load-bearing in the derivation, no uniqueness theorems are invoked from prior author work, and no ansatz or renaming of known results is used to justify the central formulation. Numerical results are reported as simulation outcomes under a concrete device-edge setup rather than predictions forced by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Draft tokens generated locally can be verified in batches on the edge server with acceptance rates that depend on draft length and batching decisions.
- ad hoc to paper The fractional mixed-integer program can be solved to sufficient quality by scanning the number of batches and iteratively alternating between an association subproblem and a draft-length subproblem.
Reference graph
Works this paper leans on
-
[1]
Fast inference from transform- ers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transform- ers via speculative decoding,” inProceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decoding with speculative sampling,” arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Speculative decoding: Exploiting speculative execution for accelerating seq2seq gen- eration,
H. Xia, T. Ge, P. Wang, S.-Q. Chen, F. Wei, and Z. Sui, “Speculative decoding: Exploiting speculative execution for accelerating seq2seq gen- eration,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023
2023
-
[4]
Distillspec: Improving speculative decoding via knowledge distillation,
Y . Zhou, K. Lyu, A. S. Rawat, A. K. Menon, A. Rostamizadeh, S. Kumar, J.-F. Kagy, and R. Agarwal, “Distillspec: Improving speculative decoding via knowledge distillation,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[5]
Online speculative decoding,
X. Liu, L. Hu, P. Bailis, A. Cheung, Z. Deng, I. Stoica, and H. Zhang, “Online speculative decoding,” inProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[6]
EAGLE: Speculative sampling requires rethinking feature uncertainty,
Y . Li, F. Wei, C. Zhang, and H. Zhang, “EAGLE: Speculative sampling requires rethinking feature uncertainty,” inProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[7]
EAGLE-2: Faster inference of language models with dynamic draft trees,
Y . Li, F. Wei, C. Zhang, and H. Zhang, “EAGLE-2: Faster inference of language models with dynamic draft trees,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[8]
Medusa: Simple LLM inference acceleration framework with multiple decoding heads,
T. Cai, Y . Li, Z. Geng, H. Peng, J. D. Lee, D. Chen, and T. Dao, “Medusa: Simple LLM inference acceleration framework with multiple decoding heads,” inProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[9]
Draft & verify: Lossless large language model acceleration via self- speculative decoding,
J. Zhang, J. Wang, H. Li, L. Shou, K. Chen, G. Chen, and S. Mehrotra, “Draft & verify: Lossless large language model acceleration via self- speculative decoding,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[10]
Dsd: A distributed speculative decoding solution for edge-cloud agile large model serving,
F. Yu, L. Li, B. McDanel, and S. Q. Zhang, “Dsd: A distributed speculative decoding solution for edge-cloud agile large model serving,” arXiv preprint arXiv:2511.21669, 2025
-
[11]
DSSD: Efficient edge-device de- ployment and collaborative inference via distributed split speculative decoding,
J. Ning, C. Zheng, and T. Yang, “DSSD: Efficient edge-device de- ployment and collaborative inference via distributed split speculative decoding,” inICML 2025 Workshop on Machine Learning for Wireless Communication and Networks, 2025
2025
-
[12]
Communication-efficient collaborative llm inference via distributed speculative decoding,
C. Zheng and T. Yang, “Communication-efficient collaborative llm inference via distributed speculative decoding,”arXiv preprint arXiv:2509.04576, 2025
-
[13]
Conformal sparsification for bandwidth-efficient edge-cloud speculative decoding,
P. Bhattacharjee, F. Tian, M. Zhong, G. Zhang, O. Simeone, and R. Tandon, “Conformal sparsification for bandwidth-efficient edge-cloud speculative decoding,”arXiv preprint arXiv:2510.09942, 2025
-
[14]
Sled: A speculative llm decoding frame- work for efficient edge serving,
X. Li, D. Spatharakis, S. Ghafouri, J. Fan, H. Vandierendonck, D. John, B. Ji, and D. S. Nikolopoulos, “Sled: A speculative llm decoding frame- work for efficient edge serving,” inProceedings of the Tenth ACM/IEEE Symposium on Edge Computing (SEC), 2025
2025
-
[15]
Spin: Accelerating large language model inference with heterogeneous speculative models,
F. Chen, P. Li, T. H. Luan, Z. Su, and J. Deng, “Spin: Accelerating large language model inference with heterogeneous speculative models,” inProceedings of the 44th IEEE International Conference on Computer Communications (INFOCOM), 2025
2025
-
[16]
Fast and cost-effective speculative edge-cloud decoding with early exits,
Y . Venkatesha, S. Kundu, and P. Panda, “Fast and cost-effective speculative edge-cloud decoding with early exits,”arXiv preprint arXiv:2505.21594, 2025
-
[17]
Flowspec: Continuous pipelined speculative decoding for efficient distributed llm inference,
X. Liu, L. Luo, M. Tang, C. Huang, and X. Chen, “Flowspec: Continuous pipelined speculative decoding for efficient distributed llm inference,” arXiv preprint arXiv:2507.02620, 2026
-
[18]
Flexspec: Frozen drafts meet evolving targets in edge-cloud collaborative llm speculative decoding,
Y . Li, R. Kong, Z. Lyu, Q. Li, X. Chen, H. Cai, L. Yan, S. Wang, J. Zhao, G. Zhu, L. Kong, G. Chen, H. Xiong, and D. Yin, “Flexspec: Frozen drafts meet evolving targets in edge-cloud collaborative llm speculative decoding,”arXiv preprint arXiv:2601.00644, 2026
-
[19]
X. Liu, C. Daniel, L. Hu, W. Kwon, Z. Li, X. Mo, A. Cheung, Z. Deng, I. Stoica, and H. Zhang, “Optimizing speculative decoding for serving large language models using goodput,”arXiv preprint arXiv:2406.14066, 2024
-
[20]
Efficient llm inference over heterogeneous edge networks with speculative decoding,
B. Zhu, Z. Chen, L. Zhao, H. Shin, and A. Nallanathan, “Efficient llm inference over heterogeneous edge networks with speculative decoding,” arXiv preprint arXiv:2510.11331, 2025
-
[21]
Pearl: Parallel speculative decoding with adaptive draft length,
T. Liu, Y . Li, Q. Lv, K. Liu, J. Zhu, W. Hu, and X. Sun, “Pearl: Parallel speculative decoding with adaptive draft length,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[22]
Smdp-based dynamic batching for im- proving responsiveness and energy efficiency of batch services,
Y . Xu, S. Zhou, and Z. Niu, “Smdp-based dynamic batching for im- proving responsiveness and energy efficiency of batch services,”IEEE Transactions on Parallel and Distributed Systems, pp. 1–16, 2025
2025
-
[23]
Smdp-based dynamic batching for efficient inference on gpu-based platforms,
Y . Xu, J. Sun, S. Zhou, and Z. Niu, “Smdp-based dynamic batching for efficient inference on gpu-based platforms,” inProceedings of the IEEE International Conference on Communications (ICC), 2023
2023
-
[24]
SCIP: Solving constraint integer programs,
T. Achterberg, “SCIP: Solving constraint integer programs,”Mathemati- cal Programming Computation, vol. 1, no. 1, pp. 1–41, 2009
2009
-
[25]
Pyscipopt: Mathematical programming in Python with the SCIP optimization suite,
S. Maher, M. Miltenberger, J. P. Pedroso, D. Rehfeldt, R. Schwarz, and F. Serrano, “Pyscipopt: Mathematical programming in Python with the SCIP optimization suite,” inMathematical Software – ICMS 2016, 2016
2016
-
[26]
On nonlinear fractional programming,
W. Dinkelbach, “On nonlinear fractional programming,”Management Science, vol. 13, no. 7, pp. 492–498, 1967
1967
-
[27]
A. Yang, A. Li, B. Yang,et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.