Recognition: unknown
Hidden Secrets in the arXiv: Discovering, Analyzing, and Preventing Unintentional Information Disclosure in Source Files of Scientific Preprints
Pith reviewed 2026-05-10 00:39 UTC · model grok-4.3
The pith
Nearly every arXiv preprint source file unintentionally discloses sensitive information such as API keys, Git histories, and internal links.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
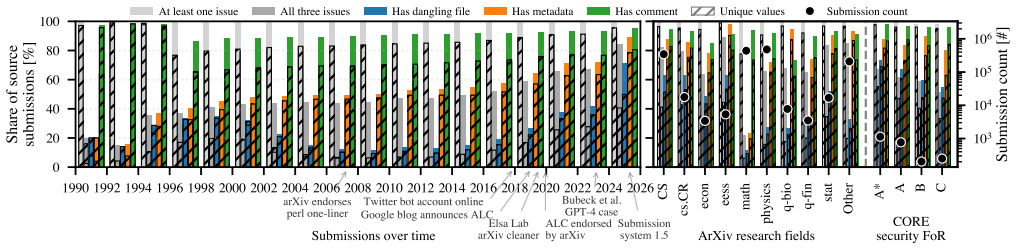
A systematic scan across three dimensions of source-file content shows that unintentional information disclosure is ubiquitous in arXiv preprints, and that current sanitization utilities fail to eliminate it.
What carries the argument
A three-dimensional scan of unnecessary files, embedded metadata, and irrelevant content such as comments, applied to the full set of 2.7 million arXiv source submissions.
If this is right
- Researchers must inspect their source bundles before arXiv upload if they wish to avoid exposing internal coordination links, keys, or repository histories.
- Existing cleaning utilities cannot be trusted to produce safe source archives.
- ALC-NG provides a practical method for removing files, metadata, and comments that are not required to compile the paper.
- The public availability of LaTeX sources on arXiv creates a persistent leakage channel that authors and platforms must actively manage.
Where Pith is reading between the lines
- Preprint platforms that publish sources could integrate automated cleaning at upload time to reduce the risk without limiting openness.
- The same leakage pattern likely appears on other servers that distribute author-provided source archives.
- Authors who maintain clean, dedicated submission repositories rather than full development histories would avoid many of the detected disclosures.
Load-bearing premise
The items flagged as sensitive are genuine unintentional disclosures rather than items the authors deliberately chose to share, and the automated detection rules produce few false positives.
What would settle it
A manual review of a random sample of flagged items that finds most of them are either false positives or were intentionally left in the source.
Figures









read the original abstract
Preprints are essential for the timely and open dissemination of research. arXiv, the most widely used preprint service, takes the idea of open science one step further by not only publishing the actual preprints but also LaTeX sources and other files used to create them. As known from other contexts, such as GitHub repositories, and anecdotally exemplified for arXiv, making source code publicly available risks disclosing otherwise "hidden" information. Consequently, the public availability of paper sources raises the question of how much sensitive content is (unintentionally) disclosed through them. In this paper, we systematically answer this question for all 2.7M arXiv submissions with available source files across three dimensions of source file-induced information disclosure: (1) inclusion of unnecessary files, (2) metadata embedded in files, and (3) irrelevant content in files such as source code comments. Our analysis reveals that nearly every arXiv submission contains some form of "hidden" information. Notable findings range from links to editable web documents for internal coordination over API and private keys to complete Git histories. While different tools promise to remove such information from source files, we show that they fail to reliably achieve the intended cleaning functionality. To mitigate this situation, we provide ALC-NG to comprehensively remove files, metadata, and comments that are not needed to compile a LaTeX paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale empirical analysis of source files from 2.7M arXiv submissions, examining unintentional information disclosure along three dimensions: inclusion of unnecessary files, embedded metadata, and irrelevant content such as comments. It concludes that nearly every submission contains some form of hidden information, with examples including links to editable documents, API/private keys, and full Git histories. The authors further show that existing cleaning tools are unreliable and introduce ALC-NG as a comprehensive solution for removing non-essential elements from LaTeX sources.
Significance. If the detection accuracy holds, the work is significant for highlighting privacy risks in open-science practices at unprecedented scale. The direct analysis of public arXiv data and the release of ALC-NG represent practical contributions that could inform submission guidelines and tool development in the field.
major comments (2)
- [Section 3 (Detection Methodology)] The central prevalence claim ('nearly every' submission contains hidden information) rests on automated detection across 2.7M files, yet no precision evaluation, false-positive rates, or manual validation on a labeled sample is reported for the heuristics identifying API keys, private keys, Git histories, or internal coordination links. This directly undermines the measurement and the subsequent claim that cleaning tools fail.
- [Section 5 (Tool Evaluation)] The evaluation that existing tools 'fail to reliably achieve the intended cleaning functionality' lacks quantitative metrics (e.g., before/after precision-recall on a held-out set of files containing the identified sensitive patterns) or details on how ALC-NG was benchmarked against them.
minor comments (2)
- [Abstract] The abstract states high-level findings without quantifying the exact fraction of submissions affected or providing confidence intervals for the 'nearly every' statistic.
- [Section 3] Detection patterns and file-type classifications would benefit from an explicit table or appendix listing the regular expressions or rules used, to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional validation and quantitative evaluation as outlined.
read point-by-point responses
-
Referee: [Section 3 (Detection Methodology)] The central prevalence claim ('nearly every' submission contains hidden information) rests on automated detection across 2.7M files, yet no precision evaluation, false-positive rates, or manual validation on a labeled sample is reported for the heuristics identifying API keys, private keys, Git histories, or internal coordination links. This directly undermines the measurement and the subsequent claim that cleaning tools fail.
Authors: We acknowledge that the original manuscript does not report precision, false-positive rates, or manual validation for the detection heuristics. The heuristics were implemented conservatively using established patterns (e.g., regex for keys and directory checks for Git histories) to reduce false positives, and the large-scale results are supported by numerous concrete examples of disclosures. However, we agree that explicit validation metrics would strengthen the prevalence claim and the argument about cleaning tools. In the revision we will add a dedicated validation subsection to Section 3, including manual review of a random sample of 500 detections per category with reported precision and false-positive rates. revision: yes
-
Referee: [Section 5 (Tool Evaluation)] The evaluation that existing tools 'fail to reliably achieve the intended cleaning functionality' lacks quantitative metrics (e.g., before/after precision-recall on a held-out set of files containing the identified sensitive patterns) or details on how ALC-NG was benchmarked against them.
Authors: The current Section 5 evaluation demonstrates tool failures through systematic analysis and case studies on real arXiv submissions. We agree that the absence of quantitative before/after metrics limits the strength of the comparison. In the revised manuscript we will add a quantitative benchmark subsection that uses a held-out test set of files containing the identified sensitive patterns, reporting precision, recall, and F1 scores for existing tools versus ALC-NG, along with full details of the benchmarking procedure. revision: yes
Circularity Check
Empirical measurement study with no derivations or self-referential claims
full rationale
This paper performs a direct empirical scan of 2.7M public arXiv source files across three dimensions of disclosure (unnecessary files, metadata, irrelevant content). No equations, fitted parameters, predictions, or uniqueness theorems appear; claims rest on observable counts from public data rather than any construction that reduces to the paper's own inputs or prior self-citations. The measurement pipeline is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Certain content such as source comments, metadata, and non-compilation files constitutes unintentional disclosure when made public.
Reference graph
Works this paper leans on
-
[1]
arXiv.org: the Los Alamos National Laboratory e-print server Available to Purchase,
G. McKiernan, “arXiv.org: the Los Alamos National Laboratory e-print server Available to Purchase,”IJGL, vol. 1, no. 3, 2000
2000
-
[2]
Let’s discuss: is arXiv always good?
citeordie, “Let’s discuss: is arXiv always good?” https://archive.is/ ZQ5u2, 2015
2015
-
[3]
arXiv.org e-Print archive,
Cornell Tech, “arXiv.org e-Print archive,” https://arxiv.org/, 1991
1991
-
[4]
Is preprint the future of science? A thirty year journey of online preprint services,
B. Xieet al., “Is preprint the future of science? A thirty year journey of online preprint services,” arXiv:2102.09066, 2021
-
[5]
Monthly Submissions,
arXiv, “Monthly Submissions,” https://arxiv.org/stats/monthly_ submissions, 2014
2014
-
[6]
Requiring TeX when possible,
arXiv, “Requiring TeX when possible,” https://arxiv.org/help/faq/ whytex.html, 2005
2005
-
[7]
Overview of the 2003 KDD Cup,
J. Gehrkeet al., “Overview of the 2003 KDD Cup,”SIGKDD Explor., vol. 5, no. 2, 2003
2003
-
[8]
Inconsistencies in TeX-Produced Documents,
J. Tan and M. Rigger, “Inconsistencies in TeX-Produced Documents,” inISSTA, 2024
2024
-
[9]
Challenges in End-to-End Neural Scientific Table Recognition,
Y . Denget al., “Challenges in End-to-End Neural Scientific Table Recognition,” inICDAR, 2019
2019
-
[10]
LATTE: Improving Latex Recognition for Tables and Formulae with Iterative Refinement,
N. Jianget al., “LATTE: Improving Latex Recognition for Tables and Formulae with Iterative Refinement,”AAAI, vol. 39, no. 4, 2025
2025
-
[11]
A framework for improving the accessibility of research papers on arXiv.org,
S. Brinnet al., “A framework for improving the accessibility of research papers on arXiv.org,” arXiv:2212.07286, 2022
-
[12]
Information Leakage Caused by Hidden Data in Published Documents,
S. Byers, “Information Leakage Caused by Hidden Data in Published Documents,”SP, vol. 2, no. 2, 2004
2004
-
[13]
Scanning electronic documents for personally identifiable information,
T. Auraet al., “Scanning electronic documents for personally identifiable information,” inWPES, 2006
2006
-
[14]
Taking advantages of a disadvantage: Digital forensics and steganography using document metadata,
A. Castiglioneet al., “Taking advantages of a disadvantage: Digital forensics and steganography using document metadata,”JSS, vol. 80, no. 5, 2007
2007
-
[15]
Disclosing Private Information from Metadata, hidden info and lost data,
C. Alonsoet al., “Disclosing Private Information from Metadata, hidden info and lost data,” Black Hat Europe 2009, 2009
2009
-
[16]
Leaking Sensitive Information in Complex Docu- ment Files–and How to Prevent It,
S. L. Garfinkel, “Leaking Sensitive Information in Complex Docu- ment Files–and How to Prevent It,”SP, vol. 12, no. 1, 2013
2013
-
[17]
A Systematic Method on PDF Privacy Leakage Issues,
Y . Fenget al., “A Systematic Method on PDF Privacy Leakage Issues,” inTrustCom, 2018
2018
-
[18]
Exploitation and Sanitization of Hidden Data in PDF Files: Do Security Agencies Sanitize Their PDF Files?
S. Adhatarao and C. Lauradoux, “Exploitation and Sanitization of Hidden Data in PDF Files: Do Security Agencies Sanitize Their PDF Files?” inIH&MMSec, 2021
2021
-
[19]
Overheard on Quant-Ph,
QuantPhComments, “Overheard on Quant-Ph,” https://archive.is/ RyI9q, 2018
2018
-
[20]
Sparks of Artificial General Intelligence: Early experiments with GPT-4 (Uncommented Version),
DV2559106965076, “Sparks of Artificial General Intelligence: Early experiments with GPT-4 (Uncommented Version),” https://archive.is/ 1icMv, 2023
2023
-
[21]
arxiv_latex_cleaner,
Google Research, “arxiv_latex_cleaner,” https://github.com/google- research/arxiv-latex-cleaner, 2019
2019
-
[22]
arXiv LaTeX cleaner: safer and easier open source research papers,
J. Pont-Tuset, “arXiv LaTeX cleaner: safer and easier open source research papers,” https://archive.is/0Fmqz, 2019
2019
-
[23]
Scienceography: The Study of How Science Is Written,
G. Cormodeet al., “Scienceography: The Study of How Science Is Written,” inLNCS, 2012
2012
-
[24]
Studying the source code of scientific research,
G. Cormodeet al., “Studying the source code of scientific research,” SIGKDD Explor., vol. 14, no. 2, 2013
2013
-
[25]
Artifact: Hidden Secrets in the arXiv,
J. Pennekampet al., “Artifact: Hidden Secrets in the arXiv,” https://zenodo.org/record/19366799, 2026, see also: https://arxiv.comsys.rwth-aachen.de
-
[26]
Pennekampet al., “ALC-NG,” https://github.com/COMSYS/ALC- NG, 2026, see also: http://alc-ng.de
J. Pennekampet al., “ALC-NG,” https://github.com/COMSYS/ALC- NG, 2026, see also: http://alc-ng.de
2026
-
[27]
A Guide to Posting and Managing Preprints,
H. Moshontzet al., “A Guide to Posting and Managing Preprints,” AMPPS, vol. 4, no. 2, 2021
2021
-
[28]
Directory of Open Access Preprint Repositories,
COAR and CCSD, “Directory of Open Access Preprint Repositories,” https://doapr.coar-repositories.org/repositories/, 2022
2022
-
[29]
arXiv Annual Report 2023,
arXiv, “arXiv Annual Report 2023,” Cornell Tech, Tech. Rep., 2024
2023
-
[30]
Information seeking behavior of scientists in the electronic information age: Astronomers, chemists, mathematicians, and physicists,
C. M. Brown, “Information seeking behavior of scientists in the electronic information age: Astronomers, chemists, mathematicians, and physicists,”JASIST, vol. 50, no. 10, 1999
1999
-
[31]
The Place of E-Prints in the Publication Patterns of Physical Scientists,
K. Manuel, “The Place of E-Prints in the Publication Patterns of Physical Scientists,”Sci. Technol. Libr., vol. 20, no. 1, 2001
2001
-
[32]
How many preprints have actually been printed and why: a case study of computer science preprints on arXiv,
J. Linet al., “How many preprints have actually been printed and why: a case study of computer science preprints on arXiv,”Scientometrics, vol. 124, no. 1, 2020
2020
-
[33]
Monthly Download Rates,
arXiv, “Monthly Download Rates,” https://arxiv.org/stats/monthly_ downloads, 2014
2014
-
[34]
ArXiv screens spot fake papers,
P. Ginsparg, “ArXiv screens spot fake papers,”Nature, vol. 508, no. 7494, 2014
2014
-
[35]
WithdrarXiv: A Large-Scale Dataset for Retraction Study,
D. Raoet al., “WithdrarXiv: A Large-Scale Dataset for Retraction Study,” arXiv:2412.03775, 2024
-
[36]
arXiv E-prints and the journal of record: An analysis of roles and relationships,
V . Larivièreet al., “arXiv E-prints and the journal of record: An analysis of roles and relationships,”JASIST, vol. 65, no. 6, 2014
2014
-
[37]
The effect of use and access on citations,
M. J. Kurtzet al., “The effect of use and access on citations,”IP&M, vol. 41, no. 6, 2005
2005
-
[38]
Does the arXiv lead to higher citations and reduced publisher downloads for mathematics articles?
P. M. Davis and M. J. Fromerth, “Does the arXiv lead to higher citations and reduced publisher downloads for mathematics articles?” Scientometrics, vol. 71, no. 2, 2007
2007
-
[39]
The effect of “open access
H. F. Moed, “The effect of “open access” on citation impact: An analysis of ArXiv’s condensed matter section,”JASIST, vol. 58, no. 13, 2007
2007
-
[40]
Positional effects on citation and readership in arXiv,
A.-u. Haque and P. Ginsparg, “Positional effects on citation and readership in arXiv,”JASIST, vol. 60, no. 11, 2009
2009
-
[41]
Last but not least: Additional positional effects on citation and readership in arXiv,
A.-u. Haque and P. Ginsparg, “Last but not least: Additional positional effects on citation and readership in arXiv,”JASIST, vol. 61, no. 12, 2010
2010
-
[42]
On the Use of ArXiv as a Dataset
C. B. Clementet al., “On the Use of ArXiv as a Dataset,” arXiv:1905.00075, 2019, representation Learning on Graphs and Manifolds (RLGM) Workshop 2019
work page Pith review arXiv 1905
-
[43]
unarXive: a large scholarly data set with publications’ full-text, annotated in-text citations, and links to metadata,
T. Saier and M. Färber, “unarXive: a large scholarly data set with publications’ full-text, annotated in-text citations, and links to metadata,”Scientometrics, vol. 125, no. 3, 2020
2020
-
[44]
Text Mining arXiv: A Look Through Quantitative Finance Papers,
M. L. Bianchi, “Text Mining arXiv: A Look Through Quantitative Finance Papers,”Mathematics, vol. 13, no. 9, 2025
2025
-
[45]
Modular versus Hierarchical: A Structural Signature of Topic Popularity in Mathematical Research,
B. Hepler, “Modular versus Hierarchical: A Structural Signature of Topic Popularity in Mathematical Research,” arXiv:2506.22946, 2025
-
[46]
Hidden Division of Labor in Scientific Teams Revealed Through 1.6 Million LaTeX Files,
J. Peiet al., “Hidden Division of Labor in Scientific Teams Revealed Through 1.6 Million LaTeX Files,” arXiv:2502.07263, 2025
-
[47]
Writing Patterns Reveal a Hidden Division of Labor in Scientific Teams,
L. Yanget al., “Writing Patterns Reveal a Hidden Division of Labor in Scientific Teams,” arXiv:2504.14093, 2025
-
[48]
Plagiarism Detection in arXiv,
D. Sorokinaet al., “Plagiarism Detection in arXiv,” inICDM, 2006
2006
-
[49]
Patterns of text reuse in a scientific corpus,
D. T. Citron and P. Ginsparg, “Patterns of text reuse in a scientific corpus,”PNAS, vol. 112, no. 1, 2015
2015
-
[50]
A. Akram, “Quantitative Analysis of AI-Generated Texts in Academic Research: A Study of AI Presence in Arxiv Submissions using AI Detection Tool,” arXiv:2403.13812, 2024
-
[51]
A Literature Review on Text Classification and Sentiment Analysis Approaches,
W. Daweiet al., “A Literature Review on Text Classification and Sentiment Analysis Approaches,” inLNEE, 2020
2020
-
[52]
Scientific Statement Classification over arXiv.org,
D. Ginev and B. R. Miller, “Scientific Statement Classification over arXiv.org,” inLREC, 2020
2020
-
[53]
Classification and Clustering of arXiv Documents, Sections, and Abstracts, Comparing Encodings of Natural and Mathematical Language,
P. Scharpfet al., “Classification and Clustering of arXiv Documents, Sections, and Abstracts, Comparing Encodings of Natural and Mathematical Language,” inACM/IEEE JCDL, 2020
2020
-
[54]
Reconstructing LaTeX Source Files from Generated PDFs — a Neural Network Approach,
B. Safnuk and G. Hu, “Reconstructing LaTeX Source Files from Generated PDFs — a Neural Network Approach,” inINDIN, 2018
2018
-
[55]
DocBank: A Benchmark Dataset for Document Layout Analysis,
M. Liet al., “DocBank: A Benchmark Dataset for Document Layout Analysis,” inCOLING, 2020
2020
-
[56]
A Benchmark of PDF Information Extraction Tools Using a Multi-task and Multi-domain Evaluation Framework for Academic Documents,
N. Meuschkeet al., “A Benchmark of PDF Information Extraction Tools Using a Multi-task and Multi-domain Evaluation Framework for Academic Documents,” inLNCS, 2023
2023
-
[57]
Detecting and Mitigating Secret-Key Leaks in Source Code Repositories,
V . S. Sinhaet al., “Detecting and Mitigating Secret-Key Leaks in Source Code Repositories,” inMSR, 2015
2015
-
[58]
How Bad Can It Git? Characterizing Secret Leakage in Public GitHub Repositories,
M. Meliet al., “How Bad Can It Git? Characterizing Secret Leakage in Public GitHub Repositories,” inNDSS, 2019
2019
-
[59]
Automated Detection of Password Leakage from Public GitHub Repositories,
R. Fenget al., “Automated Detection of Password Leakage from Public GitHub Repositories,” inICSE, 2022
2022
-
[60]
SecretBench: A Dataset of Software Secrets,
S. K. Basaket al., “SecretBench: A Dataset of Software Secrets,” in MSR, 2023
2023
-
[61]
A Comparative Study of Software Secrets Reporting by Secret Detection Tools,
S. K. Basaket al., “A Comparative Study of Software Secrets Reporting by Secret Detection Tools,” inESEM, 2023
2023
-
[62]
Secrets Revealed in Container Images: An Internet-wide Study on Occurrence and Impact,
M. Dahlmannset al., “Secrets Revealed in Container Images: An Internet-wide Study on Occurrence and Impact,” inASIACCS, 2023
2023
-
[63]
Leaky Apps: Large-scale Analysis of Secrets Distributed in Android and iOS Apps,
D. Schmidtet al., “Leaky Apps: Large-scale Analysis of Secrets Distributed in Android and iOS Apps,” inCCS, 2025
2025
-
[64]
latexindent.pl,
C. Hughes, “latexindent.pl,” https://github.com/cmhughes/latexindent. pl, 2012
2012
-
[65]
arXiv Cleaner,
Elsa Lab, “arXiv Cleaner,” https://github.com/elsa-lab/arxiv-cleaner, 2019
2019
-
[66]
Submission Sanitizer & Flattener,
D. Stutz, “Submission Sanitizer & Flattener,” https://github.com/ davidstutz/arxiv-submission-sanitizer-flattener, 2022
2022
-
[67]
Dirty Metadata: Understanding A Threat to Online Privacy,
C. Gouert and N. G. Tsoutsos, “Dirty Metadata: Understanding A Threat to Online Privacy,”IEEE Secur. Priv., vol. 20, no. 6, 2022
2022
-
[68]
MetaLeak: Assessing Image Metadata Leakage in Android Apps,
T. T. L. Nguyenet al., “MetaLeak: Assessing Image Metadata Leakage in Android Apps,” inAICCSA, 2024
2024
-
[69]
ExifTool,
P. Harvey, “ExifTool,” https://exiftool.org/, 2003
2003
-
[70]
Berkenbilt, “qpdf,” https://github.com/qpdf/qpdf, 2005
J. Berkenbilt, “qpdf,” https://github.com/qpdf/qpdf, 2005
2005
-
[71]
mat2 – Metadata and privacy,
J. V oisin, “mat2 – Metadata and privacy,” https://github.com/jvoisin/ mat2, 2018
2018
-
[72]
Security and privacy issues in the Portable Document Format,
A. Castiglioneet al., “Security and privacy issues in the Portable Document Format,”JSS, vol. 83, no. 10, 2010
2010
-
[73]
Malicious PDF Documents Explained,
D. Stevens, “Malicious PDF Documents Explained,”SP, vol. 9, no. 1, 2011
2011
-
[74]
Malicious PDF Detection using Metadata and Structural Features,
C. Smutz and A. Stavrou, “Malicious PDF Detection using Metadata and Structural Features,” inACSAC, 2012
2012
-
[75]
How are PDF files published in the Scientific Community?
S. Adhatarao and C. Lauradoux, “How are PDF files published in the Scientific Community?” inWIFS, 2021
2021
-
[76]
R. A. Dubniczkyet al., “You Have Been LaTeXpOsEd: A Systematic Analysis of Information Leakage in Preprint Archives Using Large Language Models,” arXiv:2510.03761, 2025
work page internal anchor Pith review arXiv 2025
-
[77]
X-raying the arXiv: A Large-Scale Analysis of arXiv Submissions’ Source Files,
G. Apruzzese and A. Fass, “X-raying the arXiv: A Large-Scale Analysis of arXiv Submissions’ Source Files,” arXiv:2601.11385, 2026
-
[78]
The 00README File Format,
arXiv, “The 00README File Format,” https://info.arxiv.org/help/ 00README.html, 2010
2010
-
[79]
Are Your Documents Leaking Sensitive Information? Scrub Your Metadata!
M. Spiegel, “Are Your Documents Leaking Sensitive Information? Scrub Your Metadata!” https://er.educause.edu/blogs/2017/1/are-your- documents-leaking-sensitive-information-scrub-your-metadata, 2017
2017
-
[80]
Tree-sitter,
tree-sitter, “Tree-sitter,” https://tree-sitter.github.io/tree-sitter/, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.