Recognition: unknown
Masked-Token Prediction for Anomaly Detection at the Large Hadron Collider
Pith reviewed 2026-05-09 23:21 UTC · model grok-4.3
The pith
Masked-token prediction trained solely on background events detects anomalous collider signatures by scoring deviations from learned Standard Model patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
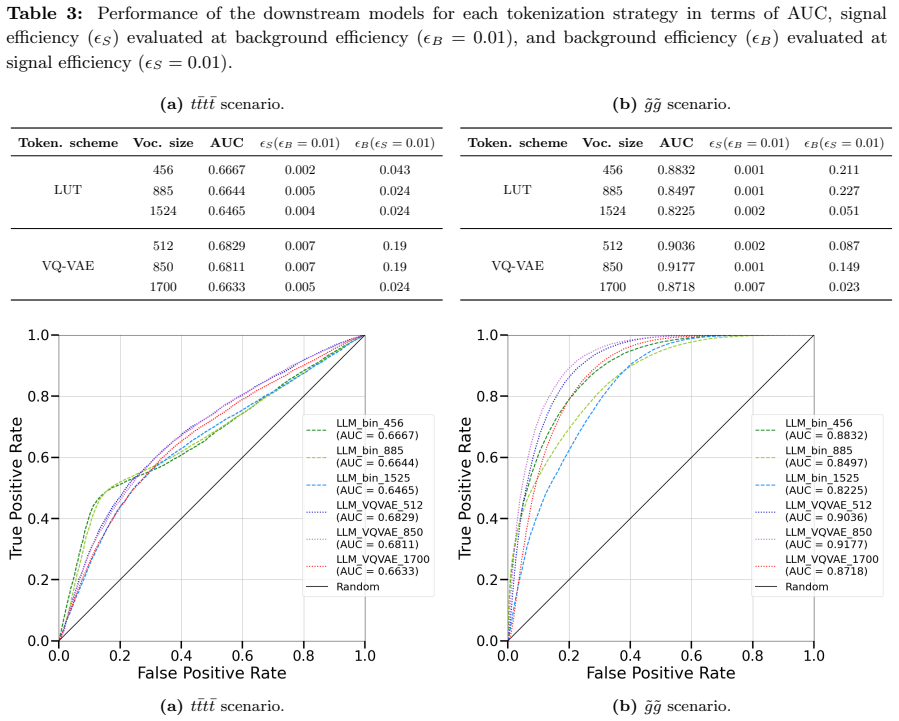
By representing collider events as sequences of tokens and training an encoder to predict masked tokens from background data alone, the method learns the patterns of Standard Model physics. Deviations in these predictions then serve as anomaly scores for potential new physics signals, without any signal-specific training. Evaluation on four-top quark production and supersymmetric gluino pair production shows effective detection, particularly with deep-learned tokenization.
What carries the argument
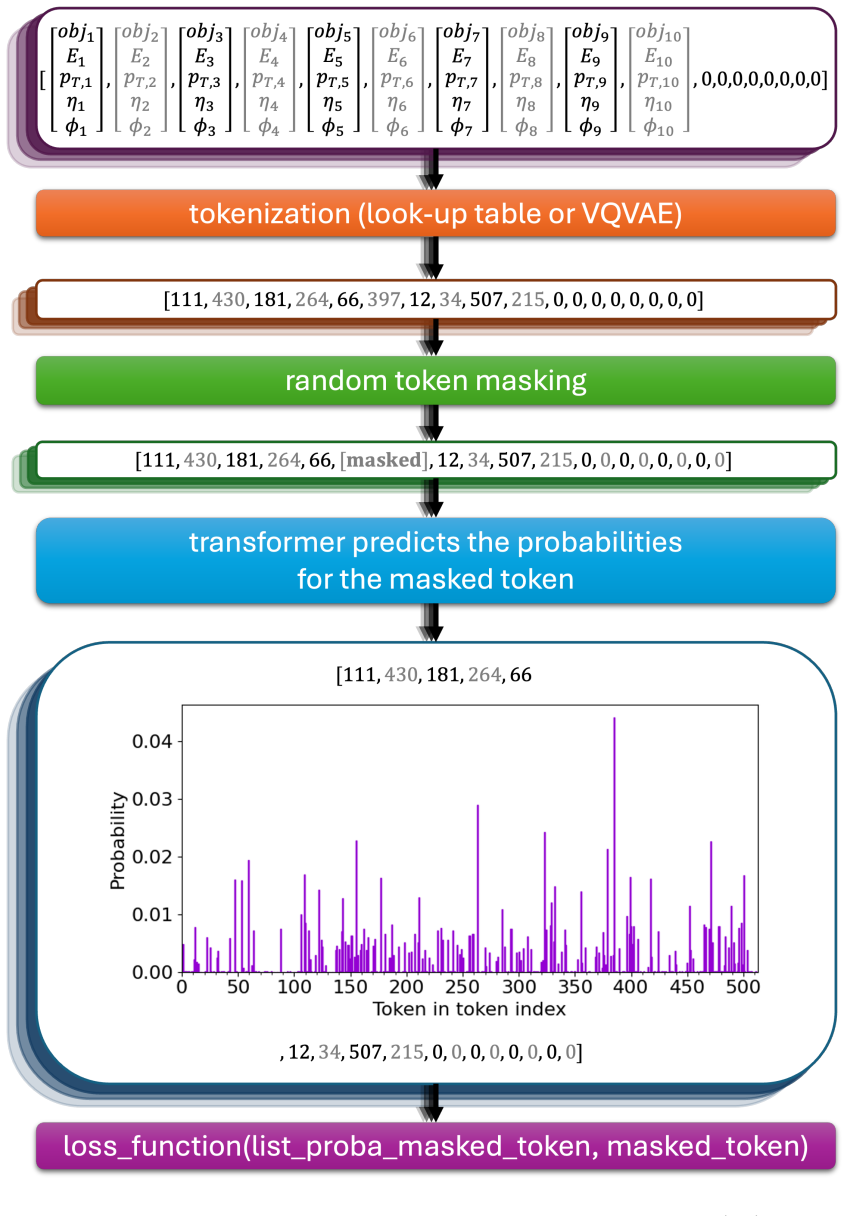
Masked-token prediction on tokenized event sequences, where the model learns to reconstruct masked tokens from background context and uses prediction error as the anomaly score.
If this is right
- The model transfers across different beyond-Standard-Model searches after a single background-only training run.
- Vector-quantized variational autoencoder tokenization improves detection performance over lookup table tokenization.
- Strong results on the four-top signature demonstrate sensitivity to subtle deviations that resemble background.
- The approach supports scalable, model-independent anomaly detection at reduced computational cost.
Where Pith is reading between the lines
- The importance of tokenization choice indicates that data representation learning is a key factor when adapting sequence models to physics events.
- This method could extend to other sequential or high-dimensional datasets in particle physics where explicit feature engineering is costly.
- The transferability across searches suggests potential for unified anomaly pipelines that scan large datasets for unexpected signals.
Load-bearing premise
That sequences of tokenized background events capture enough of the Standard Model physics structure for beyond-Standard-Model deviations to produce reliably higher anomaly scores without signal-specific training.
What would settle it
A controlled test in which known beyond-Standard-Model events receive anomaly scores statistically indistinguishable from those of Standard Model background events.
Figures
read the original abstract
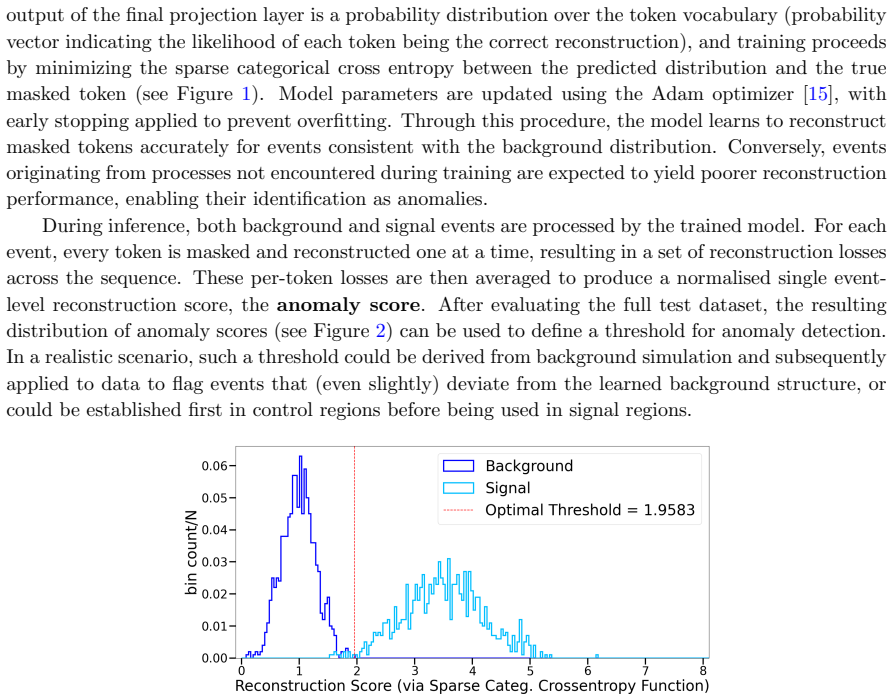
Anomaly detection in High Energy Physics requires identifying rare signals against overwhelming backgrounds, without prior knowledge of the signal. We present the first application of masked-token prediction, a technique from Large Language Models, to this problem. A lightweight encoder architecture trained solely on background events captures the structure of Standard Model (SM) physics; at inference, sequences deviating from this learned structure are flagged as anomalous. We evaluate the approach on searches for four-top-quark production and supersymmetric gluino pair production, both featuring top-rich final states with substantial missing transverse energy, covering SM and beyond the Standard Model (BSM) scenarios. Strong performance on the four-top signature, which closely resembles background, demonstrates the method's sensitivity to subtle deviations. We further show that the tokenization strategy significantly impacts performance: deep-learned tokenization via vector-quantized variational autoencoders (VQ-VAE) outperforms look-up table tokenization. Comparison with established anomaly detection baselines confirms robustness. These results highlight the potential of token-based collider data representations combined with transformer architectures for new-physics discovery. Once trained on SM background, the model transfers across different BSM searches, enabling scalable, model-independent anomaly detection at reduced computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
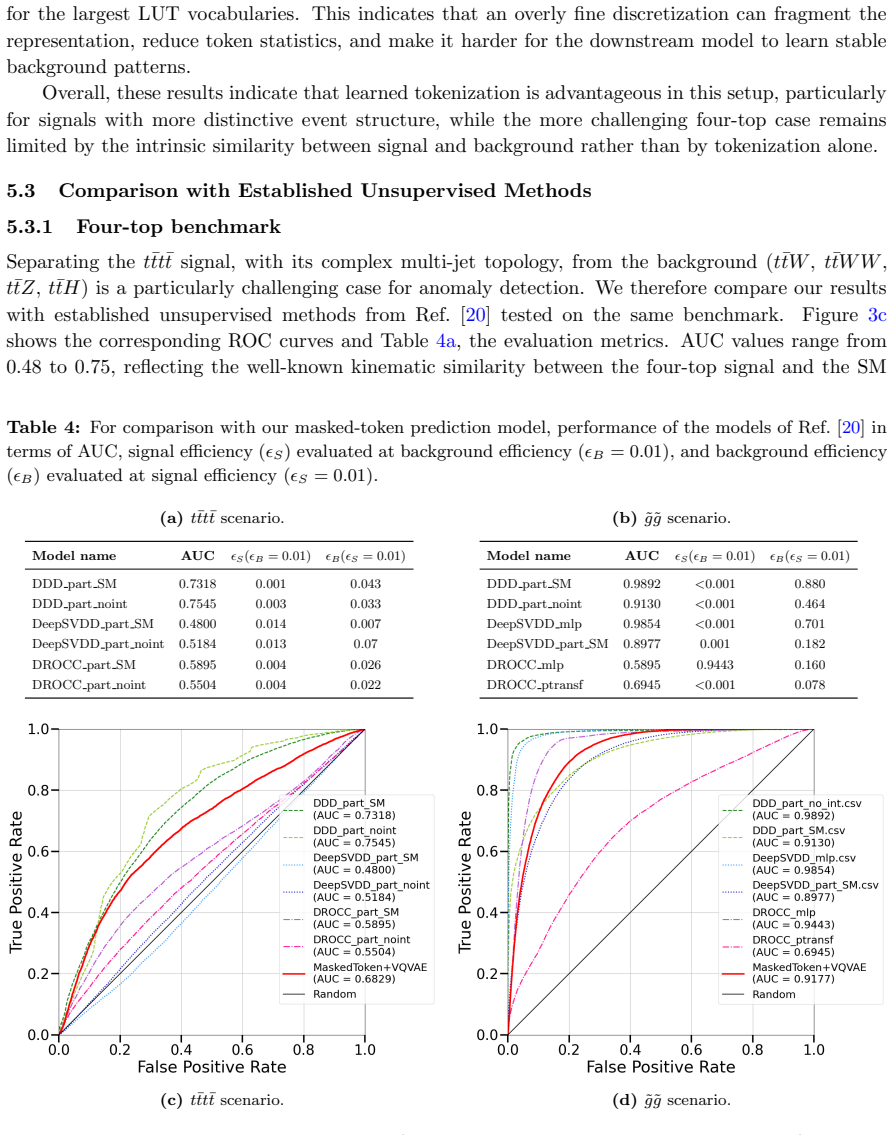
Summary. The manuscript presents the first application of masked-token prediction from large language models to anomaly detection in LHC collider data. A lightweight encoder is trained exclusively on Standard Model background events using tokenized event sequences; at inference, deviations from the learned structure yield anomaly scores. The approach is tested on four-top-quark production and supersymmetric gluino-pair production (both top-rich final states with substantial MET), with claims of strong performance on the four-top channel despite its background-like kinematics, superior results when using VQ-VAE tokenization versus lookup-table tokenization, transferability across BSM searches, and robustness relative to established anomaly-detection baselines.
Significance. If the quantitative results and validation tests support the claims, the work could introduce a scalable, model-independent anomaly-detection paradigm that repurposes transformer masked-prediction techniques for tokenized collider data. This would offer a route to efficient, signal-agnostic new-physics searches that avoid per-signal retraining and could lower computational overhead once the background model is learned.
major comments (2)
- Abstract: the abstract asserts 'strong performance on the four-top signature' and that 'comparison with established anomaly detection baselines confirms robustness,' yet supplies no quantitative metrics (AUC, significance, error bars), baseline values, or details on data selection, training procedure, or evaluation protocol. These omissions are load-bearing for the central claims of sensitivity to subtle deviations and cross-BSM transferability.
- Tokenization strategy: the paper states that VQ-VAE tokenization 'significantly impacts performance' and outperforms lookup tables, but provides no explicit test or analysis showing that the learned discrete codes preserve the continuous kinematic correlations (jet pT, MET, angular separations) required for the model to capture SM structure. Without such checks, the assumption that reconstruction errors on masked background sequences reliably flag subtle BSM deviations remains unverified and central to the method's validity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of our results and validation.
read point-by-point responses
-
Referee: Abstract: the abstract asserts 'strong performance on the four-top signature' and that 'comparison with established anomaly detection baselines confirms robustness,' yet supplies no quantitative metrics (AUC, significance, error bars), baseline values, or details on data selection, training procedure, or evaluation protocol. These omissions are load-bearing for the central claims of sensitivity to subtle deviations and cross-BSM transferability.
Authors: We agree that the abstract would be strengthened by including quantitative metrics. In the revised manuscript we will update the abstract to report key AUC values for the four-top and gluino-pair channels, the improvement over baselines, and concise details on the data selection, training, and evaluation protocol while keeping the abstract concise. revision: yes
-
Referee: Tokenization strategy: the paper states that VQ-VAE tokenization 'significantly impacts performance' and outperforms lookup tables, but provides no explicit test or analysis showing that the learned discrete codes preserve the continuous kinematic correlations (jet pT, MET, angular separations) required for the model to capture SM structure. Without such checks, the assumption that reconstruction errors on masked background sequences reliably flag subtle BSM deviations remains unverified and central to the method's validity.
Authors: We acknowledge that an explicit verification of correlation preservation would strengthen the validation of the tokenization step. Although comparative performance results are already presented, we will add a new subsection and accompanying figure in the revision that directly compares kinematic distributions and correlation matrices (jet pT, MET, angular separations) between the original continuous variables and the VQ-VAE tokenized representations to confirm that the essential SM structure is retained. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper applies masked-token prediction (an established LLM technique) to HEP anomaly detection by training a lightweight encoder solely on background events to learn SM structure, then scoring anomalies via deviation from predicted tokens at inference. This is a direct, non-circular transfer of the method: the anomaly score is the reconstruction error under masking, not a quantity defined in terms of itself or a fitted parameter renamed as a prediction. Tokenization (VQ-VAE vs. lookup table) is compared as an independent design choice with external baselines, and transfer across BSM searches follows from the background-only training without self-referential loops or load-bearing self-citations. No self-definitional steps, ansatz smuggling, or renaming of known results appear; the chain remains self-contained against standard anomaly detection benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- model architecture hyperparameters
- VQ-VAE codebook size and training parameters
axioms (2)
- domain assumption Background events can be represented as sequences whose statistical structure is learnable by a masked-token objective without explicit physics modeling.
- domain assumption Anomalous BSM events will produce measurable increases in prediction error under the learned background model.
Reference graph
Works this paper leans on
-
[1]
Radford, K
A. Radford, K. Narasimhan, T. Salimans and I. Sutskever, Improving language understanding by generative pre-training, 2018
2018
-
[2]
Large Language Models: A Survey
S. Minaee, T. Mikolov, N. Nikzad, M. Chenaghlu, R. Socher, X. Amatriain et al., Large Language Models: A Survey,2402.06196
work page internal anchor Pith review arXiv
-
[3]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez et al., Attention Is All You Need, CoRRabs/1706.03762(2023) [1706.03762]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Bender, T
E.M. Bender, T. Gebru, A. McMillan-Major and S. Shmitchell, On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?, in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Association for Computer Machinery – ACM, Mar., 2021, DOI
2021
- [5]
-
[6]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee and K. Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,1810.04805
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
T. Golling, L. Heinrich, M. Kagan, S. Klein, M. Leigh, M. Osadchy et al., Masked particle modeling on sets: towards self-supervised high energy physics foundation models, Mach. Learn. Sci. Tech.5(2024) 035074 [2401.13537]
-
[8]
Ramprasad et al., Large Language Models in Science, arXiv:2501.05382 (2025)
K.G. Barman et al., Large physics models: towards a collaborative approach with large language models and foundation models, Eur. Phys. J. C85(2025) 1066 [2501.05382]
-
[9]
Builtjes, S
L. Builtjes, S. Caron, P. Moskvitina, C. Nellist, R.R. de Austri, R. Verheyen et al., Attention to the strengths of physical interactions: Transformer and graph-based event classification for particle physics experiments, SciPost Phys.19(2025) 028
2025
-
[10]
Aarrestad, M
T. Aarrestad, M. van Beekveld, M. Bona, A. Boveia, S. Caron, J. Davies et al., The Dark Machines Anomaly Score Challenge: Benchmark Data and Model Independent Event Classification for the Large Hadron Collider, SciPost Physics12(2022)
2022
-
[11]
S. Caron, R.R. de Austri and Z. Zhang, Mixture-of-Theories training: can we find new physics and anomalies better by mixing physical theories?, JHEP03(2023) 004 [2207.07631]
- [12]
-
[13]
J. Su, Y. Lu, S. Pan, A. Murtadha, B. Wen and Y. Liu, RoFormer: Enhanced Transformer with Rotary Position Embedding,2104.09864
work page internal anchor Pith review arXiv
- [14]
-
[15]
Adam: A Method for Stochastic Optimization
D.P. Kingma and J. Ba, Adam: A Method for Stochastic Optimization,1412.6980
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
A. van den Oord, O. Vinyals and K. Kavukcuoglu, Neural Discrete Representation Learning, 1711.00937
-
[17]
J. Birk, A. Hallin and G. Kasieczka, OmniJet-α: the first cross-task foundation model for particle physics, Machine Learning: Science and Technology5(2024) 035031. – 24 –
2024
-
[18]
Normformer: Improved transformer pretraining with extra normalization
S. Shleifer, J. Weston and M. Ott, NormFormer: Improved Transformer Pretraining with Extra Normalization,2110.09456
- [19]
- [20]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.