Recognition: unknown
Who Defines Fairness? Target-Based Prompting for Demographic Representation in Generative Models
Pith reviewed 2026-05-09 23:43 UTC · model grok-4.3
The pith
Prompt engineering lets users set their own demographic targets for fair representation in AI image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
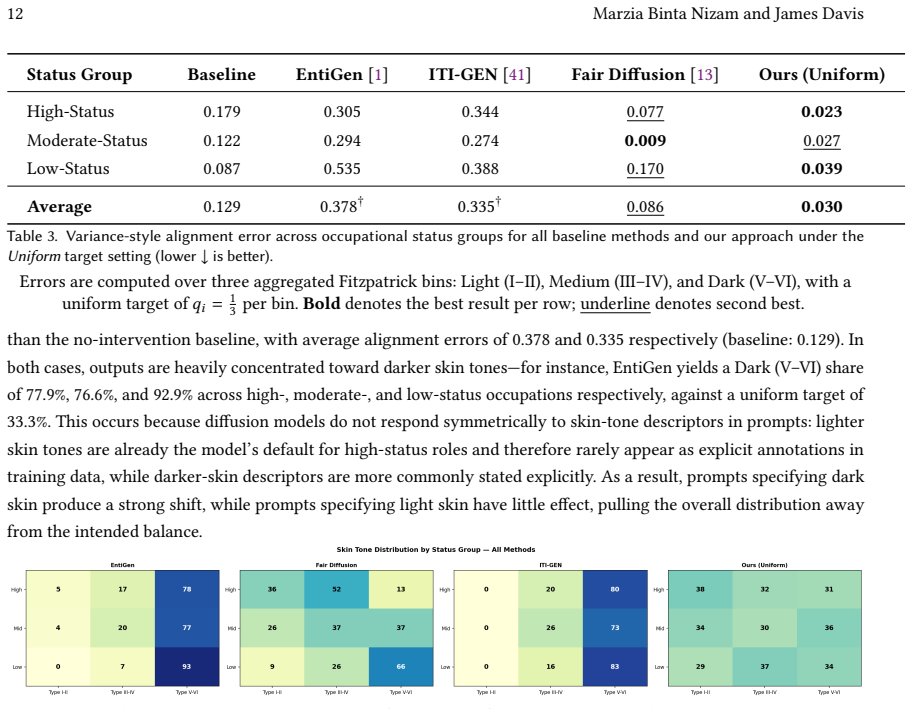
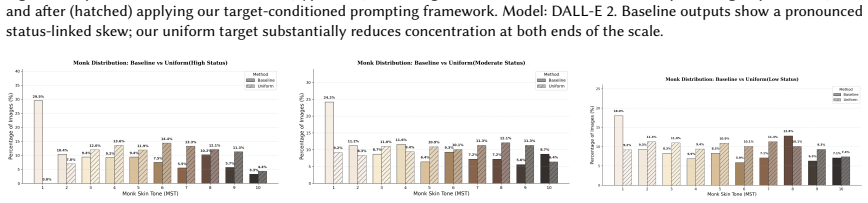
Instead of assuming one universal definition of fairness, the method lets users choose among multiple specifications, from uniform distributions to LLM-generated ones that cite sources and give confidence levels; these specifications determine the proportions in which demographic-specific prompt variants are generated, producing skin-tone distributions in the model outputs that shift consistently with the declared target and show lower deviation when the target is stated directly in skin-tone space.
What carries the argument
Target-based prompting: the construction of demographic-specific prompt variants in user-specified proportions that guide the generative model's output distribution toward the chosen fairness target.
If this is right
- Fairness specifications become explicit and choosable by the user instead of being fixed by the model developer.
- Bias mitigation works at inference time with no changes to model weights or training data.
- Evaluation measures how well outputs match the specific target chosen rather than assuming any single distribution is fair.
- The same prompting structure applies across both occupational prompts and non-occupational contexts.
Where Pith is reading between the lines
- Similar prompt-proportion techniques could be tested on other visual attributes such as age or gender presentation.
- The method might be combined with retrieval of real-world demographic statistics to make targets more evidence-based.
- Different base models could be compared to see how strongly their internal biases resist or amplify the prompt interventions.
- User interfaces could expose the LLM source and confidence estimates so people can judge the reliability of a chosen target.
Load-bearing premise
The generative model will respond to the demographic proportions in the prompt variants by producing matching skin-tone distributions in its outputs rather than overriding them with its own biases.
What would settle it
Generating thousands of images with a prompt set that specifies 100 percent of one skin tone and finding that the actual skin-tone distribution remains close to the model's default bias instead of shifting toward the target.
Figures





















read the original abstract
Text-to-image(T2I) models like Stable Diffusion and DALL-E have made generative AI widely accessible, yet recent studies reveal that these systems often replicate societal biases, particularly in how they depict demographic groups across professions. Prompts such as 'doctor' or 'CEO' frequently yield lighter-skinned outputs, while lower-status roles like 'janitor' show more diversity, reinforcing stereotypes. Existing mitigation methods typically require retraining or curated datasets, making them inaccessible to most users. We propose a lightweight, inference-time framework that mitigates representational bias through prompt-level intervention without modifying the underlying model. Instead of assuming a single definition of fairness, our approach allows users to select among multiple fairness specifications-ranging from simple choices such as a uniform distribution to more complex definitions informed by a large language model(LLM) that cites sources and provides confidence estimates. These distributions guide the construction of demographic specific prompt variants in the corresponding proportions, and we evaluate alignment by auditing adherence to the declared target and measuring the resulting skin tone distribution rather than assuming uniformity as 'fairness'. Across 36 prompts spanning 30 occupations and 6 non-occupational contexts, our method shifts observed skin-tone outcomes in directions consistent with the declared target, and reduces deviation from targets when the target is defined directly in skin-tone space(fallback). This work demonstrates how fairness interventions can be made transparent, controllable, and usable at inference time, directly empowering users of generative AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an inference-time, prompt-based framework for controlling demographic (skin-tone) representation in text-to-image models. Users select among multiple fairness targets (uniform distribution or LLM-generated distributions citing sources), which dictate the proportions of demographic-specific prompt variants (e.g., 'a [skin-tone descriptor] [occupation]'). These variants are sampled to generate outputs, which are then audited for alignment with the declared target. Across 36 prompts (30 occupations + 6 non-occupational contexts), the authors claim that observed skin-tone distributions shift directionally consistent with the target and show reduced deviation from the target when the target is specified directly in skin-tone space.
Significance. If the empirical results are substantiated, the work offers a practical, transparent alternative to retraining-based debiasing methods by making fairness definitions user-controllable and auditable rather than assuming uniformity. It highlights prompt engineering as a lightweight intervention and provides external grounding via target alignment rather than self-referential metrics. The multi-specification approach (including LLM-informed targets with citations) is a notable strength for usability.
major comments (2)
- [Abstract] Abstract: the central empirical claim of directional shifts and reduced deviation from targets is presented without any details on skin-tone measurement/auditing methods, per-prompt sample sizes, variance across runs, statistical tests against targets, or baselines, making it impossible to assess whether the data support the alignment results.
- [Evaluation] The evaluation section (implied by the 36-prompt results): the assumption that constructing prompt variants in exact target proportions will produce matching output distributions is load-bearing, yet the manuscript provides no controls for prompt sensitivity, no cases of model override, and no quantitative comparison to the skeptic concern of non-linear diffusion-model responses to demographic descriptors.
minor comments (1)
- [Abstract] The parenthetical '(fallback)' in the abstract is undefined and should be clarified or removed.
Simulated Author's Rebuttal
We appreciate the referee's feedback highlighting areas where the manuscript can be strengthened for clarity and rigor. We have made revisions to address both major comments as detailed below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of directional shifts and reduced deviation from targets is presented without any details on skin-tone measurement/auditing methods, per-prompt sample sizes, variance across runs, statistical tests against targets, or baselines, making it impossible to assess whether the data support the alignment results.
Authors: We agree with the referee that the abstract lacks sufficient detail on the empirical methods to allow full assessment of the claims. We have revised the abstract to include information on the skin-tone measurement and auditing approach (using automated classification of generated images), per-prompt sample sizes, variance across runs, statistical tests employed, and comparison to baselines. These details are now summarized in the abstract while referring readers to the full Evaluation section for complete methodology. revision: yes
-
Referee: [Evaluation] The evaluation section (implied by the 36-prompt results): the assumption that constructing prompt variants in exact target proportions will produce matching output distributions is load-bearing, yet the manuscript provides no controls for prompt sensitivity, no cases of model override, and no quantitative comparison to the skeptic concern of non-linear diffusion-model responses to demographic descriptors.
Authors: We agree that the evaluation relies on the assumption that prompt proportions translate to output distributions, and that additional controls would strengthen the work. The current manuscript does not include explicit sensitivity analyses, override cases, or direct comparisons to non-linear models. We have therefore revised the Evaluation section to add: controls for prompt sensitivity through testing of alternative demographic descriptors; documented cases where the model partially overrides the target proportions; and a quantitative discussion comparing observed deviations to what would be expected under linear vs. non-linear response assumptions, using the data from the 36 prompts. This addresses the skeptic concern while maintaining the paper's focus on practical usability. revision: yes
Circularity Check
No significant circularity; evaluation is externally grounded
full rationale
The paper proposes constructing prompt variants from user- or LLM-specified target distributions and then audits generated outputs by directly measuring skin-tone distributions against those declared targets. This evaluation step is independent of the input targets and does not reduce to a self-referential fit, redefinition, or self-citation chain. No equations, parameter fitting, or load-bearing self-citations appear in the abstract or described method. The central result (directional shifts and reduced deviation) is presented as an empirical observation rather than a derivation that collapses to its own premises by construction. The approach remains self-contained against external image auditing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompt modifications specifying demographics can control skin-tone distributions in generated images
Reference graph
Works this paper leans on
-
[1]
Hritik Bansal, Da Yin, Masoud Monajatipoor, and Kai-Wei Chang. 2022. How well can text-to-image generative models understand ethical natural language interventions?. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 1358–1370
2022
-
[2]
2017.Fairness and machine learning
Solon Barocas, Moritz Hardt, and Arvind Narayanan. 2017.Fairness and machine learning. fairmlbook. org
2017
-
[3]
Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. 2023. Easily accessible text-to-image generation amplifies demographic stereotypes at large scale.arXiv preprint arXiv:2211.03759 (2023)
-
[4]
Alain Chardon, Isabelle Cretois, and Colette Hourseau. 1991. Skin colour typology and suntanning pathways.International journal of cosmetic science13, 4 (1991), 191–208. 16 Marzia Binta Nizam and James Davis
1991
-
[5]
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. 2023. Pixart Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426(2023)
work page internal anchor Pith review arXiv 2023
- [6]
- [7]
- [8]
-
[9]
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. 2020. Retinaface: Single-shot multi-level face localisation in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5203–5212
2020
- [10]
-
[11]
Thomas B Fitzpatrick. 1988. The validity and practicality of sun-reactive skin types I through VI.Archives of dermatology124, 6 (1988), 869–871
1988
-
[12]
Fraser, Svetlana Kiritchenko, and Isar Nejadgholi
Kathleen C. Fraser, Svetlana Kiritchenko, and Isar Nejadgholi. 2023. Diversity is Not a One-Way Street: Pilot Study on Ethical Interventions for Racial Bias in Text-to-Image Systems. InProceedings of the 14th International Conference on Computational Creativity (ICCC). 288–292
2023
- [13]
- [14]
-
[15]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets.Advances in neural information processing systems27 (2014)
2014
-
[16]
Google. [n. d.]. Skin Tone by Google. https://skintone.google/. Accessed: 2026-03-23
2026
-
[17]
Ruifei He, Chuhui Xue, Haoru Tan, Wenqing Zhang, Yingchen Yu, Song Bai, and Xiaojuan Qi. 2024. Debiasing text-to-image diffusion models. In Proceedings of the 1st ACM Multimedia Workshop on Multi-modal Misinformation Governance in the Era of Foundation Models. 29–36
2024
-
[18]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems33 (2020), 6840–6851
2020
- [19]
-
[20]
Kimmo Kärkkäinen and Jungseock Joo. 2021. FairFace: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. Proceedings of the IEEE/CVF winter conference on applications of computer vision(2021), 1548–1558
2021
-
[21]
Tahsin Alamgir Kheya, Mohamed Reda Bouadjenek, and Sunil Aryal. 2024. The Pursuit of Fairness in Artificial Intelligence Models: A Survey.arXiv preprint arXiv:2403.17333(2024). doi:10.48550/arXiv.2403.17333
-
[22]
Eunji Kim, Siwon Kim, Minjun Park, Rahim Entezari, and Sungroh Yoon. 2025. Rethinking Training for De-biasing Text-to-Image Generation: Unlocking the Potential of Stable Diffusion. InProceedings of the Computer Vision and Pattern Recognition Conference. 13361–13370
2025
- [23]
-
[24]
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. 2021. A survey on bias and fairness in machine learning. ACM computing surveys54, 6 (2021), 1–35
2021
- [25]
- [26]
-
[27]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transformers.arXiv preprint arXiv:2212.09748(2023)
work page internal anchor Pith review arXiv 2023
-
[28]
Shah Prerak. 2024. Addressing Bias in Text-to-Image Generation: A Review of Mitigation Methods. In2024 Third International Conference on Smart Technologies and Systems for Next Generation Computing (ICSTSN). doi:10.1109/ICSTSN61422.2024.10671230
-
[29]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125(2022)
work page internal anchor Pith review arXiv 2022
-
[30]
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation.arXiv preprint arXiv:2102.12092(2021)
work page internal anchor Pith review arXiv 2021
- [31]
-
[32]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
-
[33]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. 2022. Photorealistic text-to-image diffusion models with deep language understanding.Advances in Neural Information Processing Systems35 (2022), 36479–36494
2022
-
[34]
Peter Saunders. 2004. What is Fair About a ’Fair Go’?Policy20, 1 (2004), 3–10. Who Defines Fairness? Target-Based Prompting for Demographic Representation in Generative Models 17
2004
-
[35]
Nripsuta Ani Saxena, Karen Huang, Evan DeFilippis, Goran Radanovic, David C. Parkes, and Yang Liu. 2019. How Do Fairness Definitions Fare? Examining Public Attitudes Towards Algorithmic Definitions of Fairness. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES ’19). doi:10.1145/3306618.3314248
-
[36]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[37]
Donald J Treiman. 2019. Occupational prestige in comparative perspective. InSocial Stratification, Class, Race, and Gender in Sociological Perspective, Second Edition. Routledge, 260–263
2019
-
[38]
Sahil Verma and Julia Rubin. 2018. Fairness Definitions Explained. InProceedings of the International Workshop on Software Fairness (FairWare ’18). doi:10.1145/3194770.3194776
- [39]
- [40]
-
[41]
A full-color headshot of a [OCCUPATION]
Cheng Zhang, Xuanbai Chen, Siqi Chai, Chen Henry Wu, Dmitry Lagun, Thabo Beeler, and Fernando De la Torre. 2023. ITI-GEN: Inclusive text-to-image generation.arXiv preprint arXiv:2309.05569(2023). A Appendix: Prompt List A.1 Occupational Prompts We used 30 occupational prompts grouped into three status categories: High, Moderate, and Low. Each prompt follo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.