Recognition: unknown
Radiomics-Guided Vision Transformers for Survival Analysis
Pith reviewed 2026-05-09 22:09 UTC · model grok-4.3
The pith
Shallow vision transformers recover survival-relevant regions in chest X-rays through attention dynamics and enable token pruning for improved interpretability and performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under shallow ViTs, token-level attention dynamics recover outcome-relevant regions and attention-based thresholding enables effective token pruning, improving both interpretability and predictive performance. The proposed radiomics-guided hybrid model integrates pixel-based embeddings with interpretable radiomic features through a multimodal Cox framework and contrastive alignment, achieving competitive discrimination on a COVID-19 chest X-ray cohort while providing clinically meaningful attention maps and feature-group importance.
What carries the argument
token-level attention dynamics in shallow vision transformers paired with a radiomics-guided multimodal Cox framework that uses contrastive alignment to combine image embeddings and radiomic features
If this is right
- Attention-based thresholding can prune tokens while preserving or boosting predictive accuracy in survival tasks.
- The hybrid model produces both image-derived embeddings and ranked radiomic feature groups for clinical review.
- Clinically meaningful attention maps become available as a byproduct of the survival modeling process.
- Multimodal integration via contrastive alignment allows radiomics to complement deep image features without loss of discrimination.
Where Pith is reading between the lines
- The pruning mechanism could lower inference costs when deploying these models in resource-limited clinical settings.
- Attention maps might be validated against expert radiologist annotations in future studies to confirm alignment with pathology.
- The same radiomics-guided alignment strategy could transfer to other imaging modalities or disease endpoints beyond COVID-19.
- Feature-group importance scores could guide the selection of which radiomic descriptors to retain in simplified clinical tools.
Load-bearing premise
Attention patterns in shallow vision transformers will consistently highlight regions that are truly relevant to survival outcomes rather than reflecting dataset-specific artifacts or noise.
What would settle it
Attention maps that fail to highlight known clinical markers such as lung consolidations on COVID-19 X-rays, or survival models whose accuracy drops after attention-based token pruning on an independent test set.
Figures
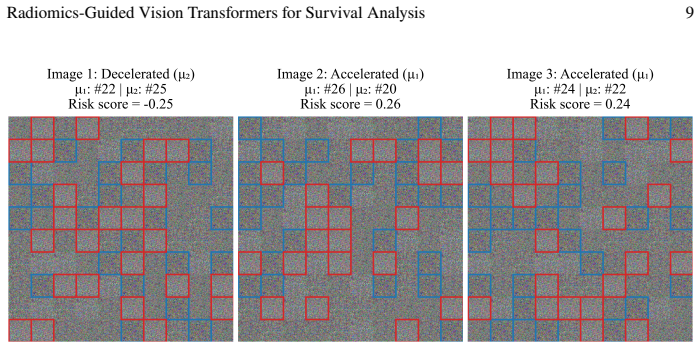


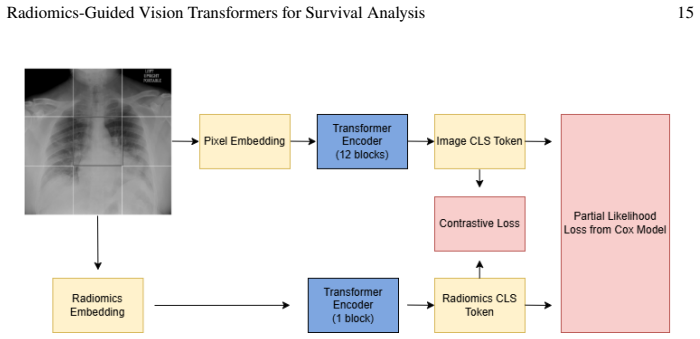
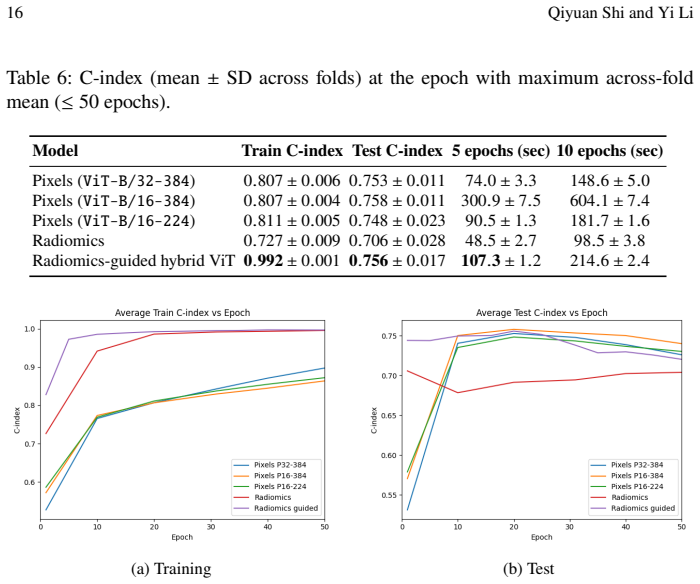


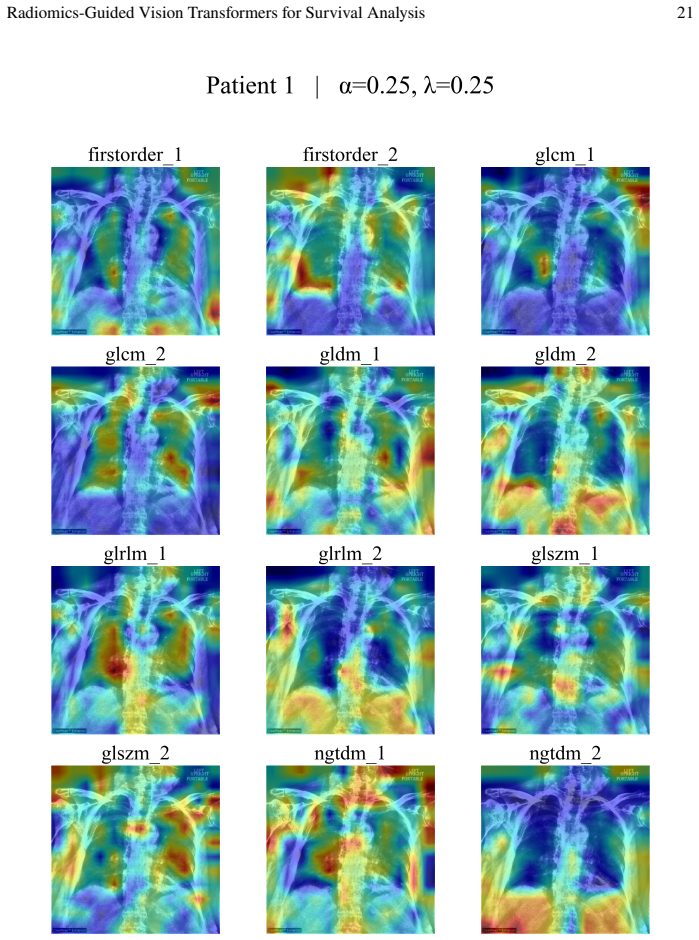


read the original abstract
Vision Transformers (ViTs) have shown strong empirical performance on high-dimensional medical imaging data, yet their behavior under survival objectives and the interpretability of their attention mechanisms remain poorly understood. Under shallow ViTs, we design controlled experiments showing that token-level attention dynamics can recover outcome-relevant regions and that attention-based thresholding enables effective token pruning, improving both interpretability and predictive performance. We also study pretrained deep ViTs for survival analysis and propose a radiomics-guided hybrid model that integrates pixel-based embeddings with interpretable radiomic features through a multimodal Cox framework and contrastive alignment. Applied to a COVID-19 chest X-ray cohort with a composite ICU admission or mortality endpoint, the proposed approach achieves competitive discrimination while providing clinically meaningful attention maps and feature-group importance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates Vision Transformers for survival analysis on medical imaging, focusing on a COVID-19 chest X-ray cohort with a composite ICU admission/mortality endpoint. It reports controlled experiments on shallow ViTs showing that token-level attention dynamics recover outcome-relevant regions and that attention-based thresholding enables effective token pruning to improve interpretability and predictive performance. It further proposes a radiomics-guided hybrid model that fuses pixel-based ViT embeddings with interpretable radiomic features via a multimodal Cox framework and contrastive alignment, claiming competitive discrimination alongside clinically meaningful attention maps and feature-group importance.
Significance. If the empirical claims hold under rigorous validation, the work would advance interpretable survival modeling by clarifying attention behavior in ViTs and demonstrating a practical integration of deep embeddings with radiomics. The controlled experiments on attention dynamics and token pruning, if reproducible, could provide a template for enhancing both performance and clinical trust in medical AI systems.
major comments (1)
- [Experimental results] Experimental results section: The claims of competitive discrimination and performance gains from token pruning and the hybrid model are not supported by reported baselines, C-index values with confidence intervals, cross-validation details, or statistical tests. Without these, it is impossible to evaluate whether the attention-based improvements and multimodal framework deliver meaningful gains over standard approaches.
minor comments (2)
- [Abstract and Methods] The abstract and methods would benefit from explicit notation for the contrastive alignment loss and the multimodal Cox partial likelihood to clarify how radiomic features are fused with ViT embeddings.
- [Figures] Figure captions for attention maps should include quantitative metrics (e.g., overlap with radiologist annotations or region importance scores) to substantiate the claim of 'clinically meaningful' maps.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major comment regarding the experimental results below and will incorporate the requested details in the revised version.
read point-by-point responses
-
Referee: [Experimental results] Experimental results section: The claims of competitive discrimination and performance gains from token pruning and the hybrid model are not supported by reported baselines, C-index values with confidence intervals, cross-validation details, or statistical tests. Without these, it is impossible to evaluate whether the attention-based improvements and multimodal framework deliver meaningful gains over standard approaches.
Authors: We agree that the current presentation of results would benefit from additional rigor to allow proper evaluation of the claims. In the revised manuscript, we will expand the Experimental Results section to include: (1) explicit baseline comparisons, such as a standard Cox proportional hazards model using only radiomic features and a non-hybrid ViT-based survival model; (2) C-index values reported with 95% confidence intervals estimated via bootstrap resampling (e.g., 1000 iterations) or repeated cross-validation; (3) full details on the cross-validation procedure, including the use of 5-fold patient-level stratified cross-validation to prevent data leakage, along with the exact splitting strategy; and (4) statistical tests (e.g., paired Wilcoxon signed-rank tests across folds or DeLong tests for C-index differences) to assess the significance of performance gains from attention-based token pruning and the radiomics-guided hybrid model. These additions will substantiate the reported competitive discrimination and improvements without altering the core methodology or conclusions. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents empirical controlled experiments on shallow ViTs demonstrating attention dynamics for region recovery and token pruning, plus a proposed radiomics-guided hybrid model using standard multimodal Cox regression and contrastive alignment on a COVID-19 cohort. No equations, derivations, or self-citations are described that reduce any prediction or result to fitted inputs by construction. The central claims rest on experimental outcomes and integration of established components (ViT embeddings, radiomic features, Cox framework) without load-bearing self-referential steps or uniqueness theorems imported from prior author work. This is the most common honest finding for papers whose contributions are experimental rather than axiomatic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Decoding tumour phenotype by noninvasive imaging using a quantitative radiomics approach.Nature communications, 5(1):4006, 2014
Hugo JWL Aerts, Emmanuel Rios Velazquez, Ralph TH Leijenaar, Chintan Parmar, Patrick Grossmann, Sara Carvalho, Johan Bussink, Ren ´e Monshouwer, Benjamin Haibe-Kains, Derek Radiomics-Guided Vision Transformers for Survival Analysis 25 Rietveld, et al. Decoding tumour phenotype by noninvasive imaging using a quantitative radiomics approach.Nature communica...
2014
-
[2]
Covid-19 outbreak in italy: experimental chest x-ray scor- ing system for quantifying and monitoring disease progression.La radiologia medica, 125(5):509– 513, 2020
Andrea Borghesi and Roberto Maroldi. Covid-19 outbreak in italy: experimental chest x-ray scor- ing system for quantifying and monitoring disease progression.La radiologia medica, 125(5):509– 513, 2020
2020
-
[3]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In Hal Daum´e III and Aarti Singh, editors,Pro- ceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 1597–1607. PMLR, 13–18 Jul 2020
2020
-
[4]
Explainable vision transformers and radiomics for covid-19 detection in chest x-rays.Journal of clinical medicine, 11(11):3013, 2022
Mohamed Chetoui and Moulay A Akhloufi. Explainable vision transformers and radiomics for covid-19 detection in chest x-rays.Journal of clinical medicine, 11(11):3013, 2022
2022
-
[5]
Cox-nnet: an artificial neural network method for prognosis prediction of high-throughput omics data.PLoS computational biology, 14(4):e1006076, 2018
Travers Ching, Xun Zhu, and Lana X Garmire. Cox-nnet: an artificial neural network method for prognosis prediction of high-throughput omics data.PLoS computational biology, 14(4):e1006076, 2018
2018
-
[6]
Explainable transformer-based deep survival analysis in childhood acute lymphoblastic leukemia
Yuning Cui, Weixuan Dong, Yifu Li, Amanda E Janitz, Hanumantha R Pokala, and Rui Zhu. Explainable transformer-based deep survival analysis in childhood acute lymphoblastic leukemia. Computers in Biology and Medicine, 191:110118, 2025
2025
-
[7]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021
2021
-
[8]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[9]
Radiomics-guided global-local transformer for weakly supervised pathology localization in chest x-rays.IEEE transactions on medical imaging, 42(3):750–761, 2022
Yan Han, Gregory Holste, Ying Ding, Ahmed Tewfik, Yifan Peng, and Zhangyang Wang. Radiomics-guided global-local transformer for weakly supervised pathology localization in chest x-rays.IEEE transactions on medical imaging, 42(3):750–761, 2022
2022
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[11]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[12]
Transformer-based deep survival analysis
Shi Hu, Egill Fridgeirsson, Guido van Wingen, and Max Welling. Transformer-based deep survival analysis. InSurvival Prediction-Algorithms, Challenges and Applications, pages 132–148. PMLR, 2021
2021
-
[13]
In-context convergence of transformers.arXiv preprint arXiv:2310.05249,
Yu Huang, Yuan Cheng, and Yingbin Liang. In-context convergence of transformers.arXiv preprint arXiv:2310.05249, 2023
-
[14]
Automatic pruning rate adjustment for dynamic token reduction in vision transformer.Applied Intelligence, 55(5):342, 2025
Ryuto Ishibashi and Lin Meng. Automatic pruning rate adjustment for dynamic token reduction in vision transformer.Applied Intelligence, 55(5):342, 2025
2025
-
[15]
Efficient transformer inference through hybrid dynamic pruning.IEEE Transactions on Artificial Intelligence, 2025
Ghadeer A Jaradat, Mohammed F Tolba, Ghada Alsuhli, Hani Saleh, Mahmoud Al-Qutayri, and Thanos Stouraitis. Efficient transformer inference through hybrid dynamic pruning.IEEE Transactions on Artificial Intelligence, 2025
2025
-
[16]
Advancing transformer efficiency with token pruning
Xiulan Jie, Yahui Yang, and Yong Jianhong. Advancing transformer efficiency with token pruning. Preprints, March 2025
2025
-
[17]
Deepsurv: personalized treatment recommender system using a cox proportional hazards deep neural network.BMC medical research methodology, 18(1):24, 2018
Jared L Katzman, Uri Shaham, Alexander Cloninger, Jonathan Bates, Tingting Jiang, and Yuval Kluger. Deepsurv: personalized treatment recommender system using a cox proportional hazards deep neural network.BMC medical research methodology, 18(1):24, 2018
2018
-
[18]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
Radiomics: extracting more information from medical images using advanced feature analysis.European Journal of Cancer, 48(4):441–446, 2012
Philippe Lambin, Eva Rios-Velazquez, Ralph Leijenaar, Sara Carvalho, Roel GPM van Stiphout, Patrick Granton, Corine M L Zegers, Robert Gillies, Ronald Boellard, Andre Dekker, and Hugo JWL Aerts. Radiomics: extracting more information from medical images using advanced feature analysis.European Journal of Cancer, 48(4):441–446, 2012
2012
-
[20]
Deephit: A deep learning approach to survival analysis with competing risks
Changhee Lee, William Zame, Jinsung Yoon, and Mihaela Van Der Schaar. Deephit: A deep learning approach to survival analysis with competing risks. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018. 26 Qiyuan Shi and Yi Li
2018
-
[21]
arXiv preprint arXiv:2302.06015 , year=
Hongkang Li, Meng Wang, Sijia Liu, and Pin-Yu Chen. A theoretical understanding of shal- low vision transformers: Learning, generalization, and sample complexity.arXiv preprint arXiv:2302.06015, 2023
-
[22]
Survformer: A transformer based framework for survival analysis in insurance underwriting
Yingxue Li, Xiaolu Zhang, Jun Hu, Wenwen Xia, Ziyi Liu, Xiaobo Qin, Binjie Fei, and Jun Zhou. Survformer: A transformer based framework for survival analysis in insurance underwriting. In Companion Proceedings of the ACM on Web Conference 2025, pages 325–333, 2025
2025
-
[23]
Adaptive computation pruning for the forgetting transformer.arXiv preprint arXiv:2504.06949, 2025
Zhixuan Lin, Johan Obando-Ceron, Xu Owen He, and Aaron Courville. Adaptive computation pruning for the forgetting transformer.arXiv preprint arXiv:2504.06949, 2025
-
[24]
Evolutionvit: Multi-objective evolutionary vision transformer pruning under resource constraints.Information Sciences, 689:121406, 2025
Lei Liu, Gary G Yen, and Zhenan He. Evolutionvit: Multi-objective evolutionary vision transformer pruning under resource constraints.Information Sciences, 689:121406, 2025
2025
-
[25]
Prune and merge: Efficient token compression for vision transformer with spatial information preserved
Junzhu Mao, Yang Shen, Jinyang Guo, Yazhou Yao, Xiansheng Hua, and Hengtao Shen. Prune and merge: Efficient token compression for vision transformer with spatial information preserved. IEEE Transactions on Multimedia, 2025
2025
-
[26]
Explainable machine-learning models for covid-19 prognosis prediction using clinical, laboratory and radiomic features.IEEE Access, 11:121492–121510, 2023
Francesco Prinzi, Carmelo Militello, Nicola Scichilone, Salvatore Gaglio, and Salvatore Vitabile. Explainable machine-learning models for covid-19 prognosis prediction using clinical, laboratory and radiomic features.IEEE Access, 11:121492–121510, 2023
2023
-
[27]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021
2021
-
[28]
Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society Series B: Statistical Methodology, 58(1):267–288, 1996
Robert Tibshirani. Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society Series B: Statistical Methodology, 58(1):267–288, 1996
1996
-
[29]
Computational radiomics system to decode the radiographic phenotype.Cancer research, 77(21):e104–e107, 2017
Joost JM Van Griethuysen et al. Computational radiomics system to decode the radiographic phenotype.Cancer research, 77(21):e104–e107, 2017
2017
-
[30]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[31]
Efficient adverse event forecasting in clinical trials via transformer-augmented survival analysis
Yachen Wang. Efficient adverse event forecasting in clinical trials via transformer-augmented survival analysis. InProceedings of the 2025 International Symposium on Bioinformatics and Computational Biology, pages 92–97, 2025
2025
-
[32]
Survtrace: Transformers for survival analysis with competing events
Zifeng Wang and Jimeng Sun. Survtrace: Transformers for survival analysis with competing events. InProceedings of the 13th ACM international conference on bioinformatics, computational biology and health informatics, pages 1–9, 2022
2022
-
[33]
Severity scoring of lung oedema on the chest radiograph is associated with clinical outcomes in ards.Thorax, 73(9):840–846, 2018
Melissa A Warren, Zhiguou Zhao, Tatsuki Koyama, Julie A Bastarache, Ciara M Shaver, Matthew W Semler, Todd W Rice, Michael A Matthay, Carolyn S Calfee, and Lorraine B Ware. Severity scoring of lung oedema on the chest radiograph is associated with clinical outcomes in ards.Thorax, 73(9):840–846, 2018
2018
-
[34]
A deep survival interpretable radiomics model of hepatocellular carcinoma patients.Physica Medica, 82:295–305, 2021
Lise Wei, Dawn Owen, Benjamin Rosen, Xinzhou Guo, Kyle Cuneo, Theodore S Lawrence, Randall Ten Haken, and Issam El Naqa. A deep survival interpretable radiomics model of hepatocellular carcinoma patients.Physica Medica, 82:295–305, 2021
2021
-
[35]
PyTorch Image Models
Ross Wightman. PyTorch Image Models
-
[36]
Tafp-vit: A transformer accelerator via qkv computational fusion and adaptive pruning for vision transformer.ACM Transactions on Embedded Computing Systems, 24(5):1–21, 2025
Liang Xu, Hongrui Song, Lan Tian, Zhongfeng Wang, and Meiqi Wang. Tafp-vit: A transformer accelerator via qkv computational fusion and adaptive pruning for vision transformer.ACM Transactions on Embedded Computing Systems, 24(5):1–21, 2025
2025
-
[37]
Rui Yan, Xueyuan Zhang, Zihang Jiang, Baizhi Wang, Xiuwu Bian, Fei Ren, and S Kevin Zhou. Pathway-aware multimodal transformer (pamt): Integrating pathological image and gene expres- sion for interpretable cancer survival analysis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[38]
Deep learning attention-guided radiomics for covid-19 chest radiograph classification
Dongrong Yang, Ge Ren, Ruiyan Ni, Yu-Hua Huang, Ngo Fung Daniel Lam, Hongfei Sun, Shiu Bun Nelson Wan, Man Fung Esther Wong, King Kwong Chan, Hoi Ching Hailey Tsang, et al. Deep learning attention-guided radiomics for covid-19 chest radiograph classification. Quantitative imaging in medicine and surgery, 13(2):572, 2022
2022
-
[39]
Zhenyu Yang, Haiming Zhu, Rihui Zhang, Haipeng Zhang, Jianliang Wang, Chunhao Wang, Minbin Chen, and Fang-Fang Yin. Embedding radiomics into vision transformers for multimodal medical image classification.arXiv preprint arXiv:2504.10916, 2025
-
[40]
Mini-batch Estimation for Deep Cox Models: Statistical Foundations and Practical Guidance
Lang Zeng, Weijing Tang, Zhao Ren, and Ying Ding. Mini-batch estimation for deep cox models: Statistical foundations and practical guidance.arXiv preprint arXiv:2408.02839, 2024. Radiomics-Guided Vision Transformers for Survival Analysis 27
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Partitioned token fusion and pruning strategy for transformer tracking.Image and Vision Computing, 154:105431, 2025
Chi Zhang, Yun Gao, Tao Meng, and Tao Wang. Partitioned token fusion and pruning strategy for transformer tracking.Image and Vision Computing, 154:105431, 2025
2025
-
[42]
Adaptive transformer modelling of density function for nonparametric survival analysis.Machine Learning, 114(2):31, 2025
Xin Zhang, Deval Mehta, Yanan Hu, Chao Zhu, David Darby, Zhen Yu, Daniel Merlo, Melissa Gresle, Anneke Van Der Walt, Helmut Butzkueven, et al. Adaptive transformer modelling of density function for nonparametric survival analysis.Machine Learning, 114(2):31, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.