Recognition: unknown
Learning to Emulate Chaos: Adversarial Optimal Transport Regularization
Pith reviewed 2026-05-09 22:45 UTC · model grok-4.3
The pith
Adversarial optimal transport regularization trains neural emulators to match chaotic attractor statistics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A family of adversarial optimal transport objectives, including Sinkhorn divergence for 2-Wasserstein matching and a WGAN-style dual for 1-Wasserstein matching, jointly learns summary statistics and a physically consistent emulator that reproduces the statistical properties of chaotic attractors.
What carries the argument
Adversarial optimal transport objectives that enforce distributional matching between emulator trajectories and the true chaotic attractor while learning summary statistics.
If this is right
- Emulators exhibit significantly improved long-term statistical fidelity across a variety of chaotic systems.
- The method succeeds even for systems with high-dimensional chaotic attractors.
- Joint learning of summary statistics and the emulator removes the need for handcrafted local features.
- Both the Sinkhorn divergence and WGAN-style formulations are theoretically analyzed and experimentally validated for this task.
Where Pith is reading between the lines
- The regularization may allow neural operator architectures to handle a wider range of complex dynamical systems where only statistical behavior is observable.
- Applications such as weather or power-grid modeling could use these emulators for ensemble forecasting without pointwise accuracy.
- The approach could be combined with other regularization terms that encode known physical invariants.
Load-bearing premise
The adversarial optimal transport regularization produces physically consistent emulators without introducing artifacts, instabilities, or distribution mismatches that affect downstream use.
What would settle it
Train an emulator on a chaotic system using the proposed regularization, then generate long trajectories and measure whether their statistical properties (for example, state distributions or attractor dimensions) match those of the true system or whether unphysical artifacts appear.
Figures








read the original abstract
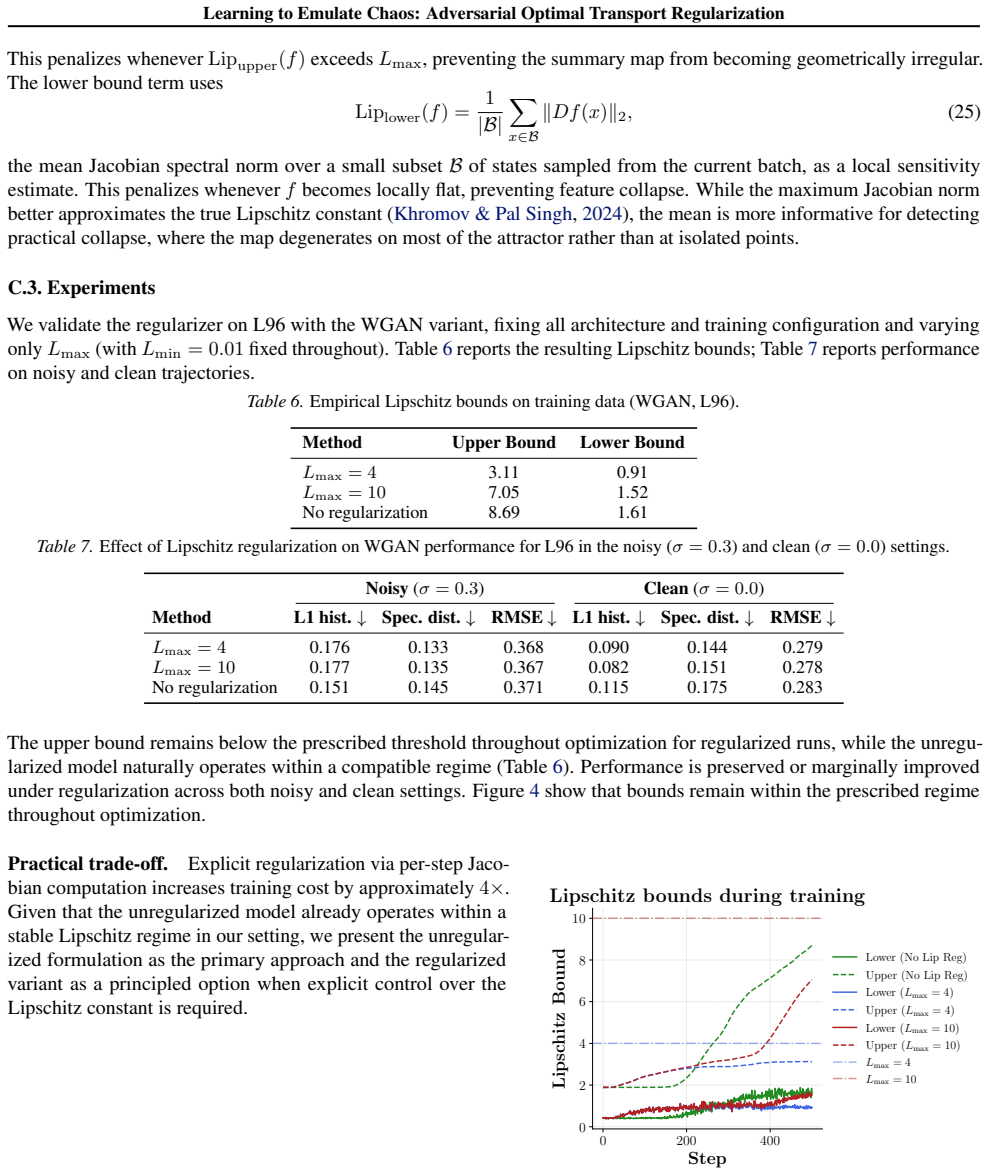
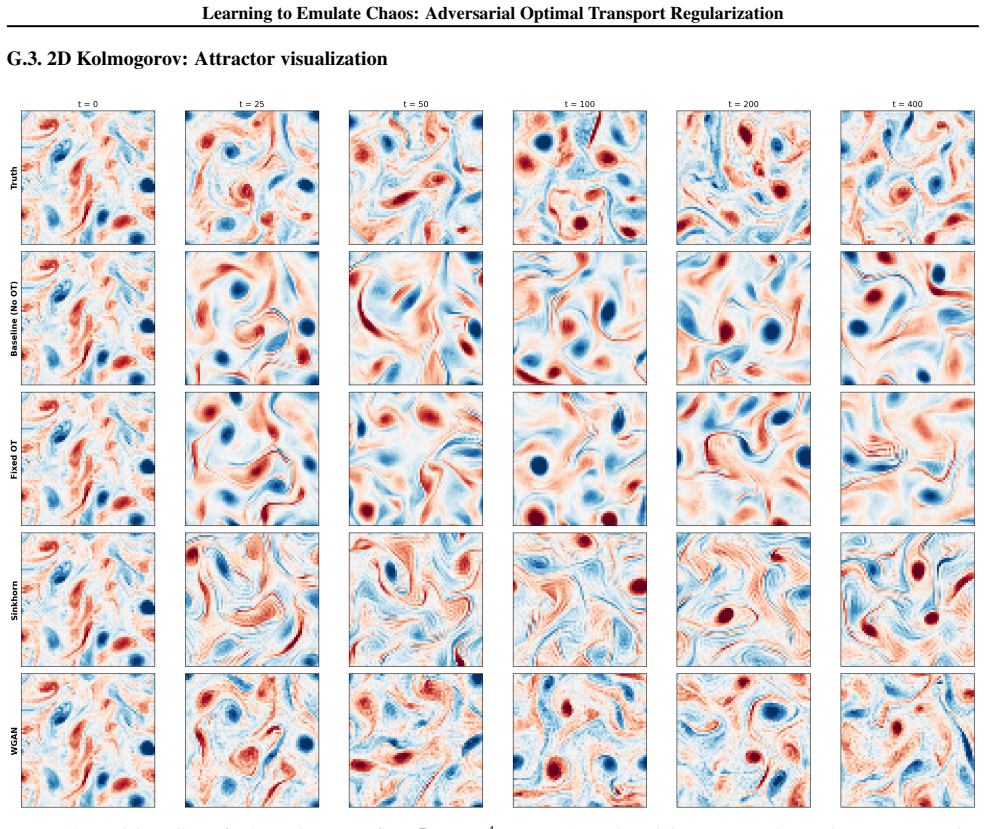
Chaos arises in many complex dynamical systems, from weather to power grids, but is difficult to accurately model using data-driven emulators, including neural operator architectures. For chaotic systems, the inherent sensitivity to initial conditions makes exact long-term forecasts theoretically infeasible, meaning that traditional squared-error losses often fail when trained on noisy data. Recent work has focused on training emulators to match the statistical properties of chaotic attractors by introducing regularization based on handcrafted local features and summary statistics, as well as learned statistics extracted from a diverse dataset of trajectories. In this work, we propose a family of adversarial optimal transport objectives that jointly learn high-quality summary statistics and a physically consistent emulator. We theoretically analyze and experimentally validate a Sinkhorn divergence formulation (2-Wasserstein) and a WGAN-style dual formulation (1-Wasserstein). Our experiments across a variety of chaotic systems, including systems with high-dimensional chaotic attractors, show that emulators trained with our approach exhibit significantly improved long-term statistical fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a family of adversarial optimal transport objectives—specifically a Sinkhorn divergence formulation based on the 2-Wasserstein distance and a WGAN-style dual formulation for the 1-Wasserstein distance—to jointly learn summary statistics and train neural emulators for chaotic dynamical systems. The central claim is that this regularization yields emulators with significantly improved long-term statistical fidelity to the attractors of chaotic systems, outperforming baselines that rely on handcrafted local features or learned statistics from trajectory datasets, as supported by theoretical analysis and experiments on a variety of chaotic systems including high-dimensional attractors.
Significance. If the central claims hold, the work provides a principled, automatic alternative to handcrafted or pre-learned statistics for regularizing data-driven emulators of chaotic dynamics. This could improve the reliability of long-term statistical predictions in applications such as weather modeling and power-grid simulation, where exact trajectory matching is infeasible due to sensitivity to initial conditions. The joint learning of statistics and emulator via optimal transport is a notable strength relative to prior regularization approaches.
minor comments (3)
- The abstract and introduction would benefit from a brief, explicit statement of the precise baseline methods (handcrafted features and learned-statistic approaches) and the quantitative metrics used to assess long-term statistical fidelity, to allow readers to immediately gauge the scope of the claimed improvements.
- In the experimental section, additional detail on the number of independent runs, standard deviations or confidence intervals for the reported fidelity metrics, and the precise definition of 'long-term' (e.g., integration horizon relative to Lyapunov time) would strengthen reproducibility and interpretation of the results.
- Notation for the adversarial objectives (Sinkhorn and dual formulations) should be introduced with a short table or inline reminder of the key variables (e.g., the role of the critic network and the regularization parameter) to improve readability for readers less familiar with optimal transport.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work and for recommending minor revision. The referee's description accurately reflects the manuscript's contributions regarding adversarial optimal transport regularization for emulators of chaotic systems. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines its core adversarial optimal transport objectives (Sinkhorn 2-Wasserstein divergence and WGAN-style 1-Wasserstein dual) directly from standard optimal transport theory and applies them to jointly optimize summary statistics and the emulator. No load-bearing step in the abstract or described approach reduces the claimed predictions or statistical fidelity improvements to quantities fitted from the target data by construction, nor relies on self-citations for uniqueness theorems, ansatzes, or renaming of known results. The central claim rests on experimental comparison to handcrafted and learned-statistic baselines, which supplies independent validation rather than tautological equivalence to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Training neural operators to preserve invariant measures of chaotic attractors , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
Hierarchical Implicit Neural Emulators , author =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[3]
2010 , eprint=
Physical Measure and Absolute Continuity for One-Dimensional Center Direction , author=. 2010 , eprint=
2010
-
[4]
International Conference on Artificial Intelligence and Statistics , pages=
Learning generative models with sinkhorn divergences , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2018 , organization=
2018
-
[5]
Neural Computation 9(8), 1735–1780 (1997)
Hochreiter, Sepp and Schmidhuber, J\". Long Short-Term Memory , year =. Neural Comput. , month = nov, pages =. doi:10.1162/neco.1997.9.8.1735 , abstract =
-
[6]
2025 , eprint=
Optimal Transport for Machine Learners , author=. 2025 , eprint=
2025
-
[7]
Annals of Mathematical Statistics , volume =
Richard Sinkhorn , title =. Annals of Mathematical Statistics , volume =
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , pages =
Marco Cuturi , title =. Advances in Neural Information Processing Systems (NeurIPS) , pages =
-
[9]
Proceedings of the 31st International Conference on Machine Learning (ICML) , volume =
Marco Cuturi and Arnaud Doucet , title =. Proceedings of the 31st International Conference on Machine Learning (ICML) , volume =. 2014 , publisher =
2014
-
[10]
2018 , eprint=
Interpolating between Optimal Transport and MMD using Sinkhorn Divergences , author=. 2018 , eprint=
2018
-
[11]
2022 , eprint=
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning , author=. 2022 , eprint=
2022
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Deep Sets , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[13]
IEEE transactions on neural networks , volume=
Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems , author=. IEEE transactions on neural networks , volume=. 1995 , publisher=
1995
-
[14]
Nature machine intelligence , volume=
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators , author=. Nature machine intelligence , volume=. 2021 , publisher=
2021
-
[15]
2016 , eprint=
Exploiting Cyclic Symmetry in Convolutional Neural Networks , author=. 2016 , eprint=
2016
-
[16]
2016 , eprint=
Group Equivariant Convolutional Networks , author=. 2016 , eprint=
2016
-
[17]
2017 , eprint=
Wasserstein GAN , author=. 2017 , eprint=
2017
-
[18]
arXiv preprint arXiv:1910.03875 , year=
How well do wgans estimate the wasserstein metric? , author=. arXiv preprint arXiv:1910.03875 , year=
-
[19]
Wasserstein GANs work because they fail (to approximate the Wasserstein distance)
Wasserstein GANs work because they fail (to approximate the Wasserstein distance) , author=. arXiv preprint arXiv:2103.01678 , year=
-
[20]
Advances in neural information processing systems , volume=
Improved training of wasserstein gans , author=. Advances in neural information processing systems , volume=
-
[21]
Communications of the ACM , volume=
Generative adversarial networks , author=. Communications of the ACM , volume=. 2020 , publisher=
2020
-
[22]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Recent advances in optimal transport for machine learning , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[23]
On convergence and stability of GANs
On convergence and stability of gans , author=. arXiv preprint arXiv:1705.07215 , year=
-
[24]
Advances in neural information processing systems , volume=
Generative adversarial nets , author=. Advances in neural information processing systems , volume=
-
[25]
Demystifying mmd gans , author=. arXiv preprint arXiv:1801.01401 , year=
work page internal anchor Pith review arXiv
-
[26]
The journal of machine learning research , volume=
A kernel two-sample test , author=. The journal of machine learning research , volume=. 2012 , publisher=
2012
-
[27]
Spectral Normalization for Generative Adversarial Networks
Spectral normalization for generative adversarial networks , author=. arXiv preprint arXiv:1802.05957 , year=
-
[28]
Advances in Neural Information Processing Systems , volume=
Learning Chaotic Dynamics in Dissipative Systems , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
SIAM Journal on Applied Dynamical Systems , volume=
Optimal Transport for Parameter Identification of Chaotic Dynamics via Invariant Measures , author=. SIAM Journal on Applied Dynamical Systems , volume=. 2023 , doi=
2023
-
[30]
Learning Dynamics on Invariant Measures Using
Botvinick-Greenhouse, Jonah and Martin, Robert and Yang, Yunan , journal=. Learning Dynamics on Invariant Measures Using. 2023 , publisher=
2023
-
[31]
Chaos: An Interdisciplinary Journal of Nonlinear Science , volume=
Constraining Chaos: Enforcing Dynamical Invariants in the Training of Reservoir Computers , author=. Chaos: An Interdisciplinary Journal of Nonlinear Science , volume=. 2023 , publisher=
2023
-
[32]
Proceedings of the 41st International Conference on Machine Learning , series=
Schiff, Yair and Wan, Zhong Yi and Parker, Jeffrey B and Hoyer, Stephan and Kuleshov, Volodymyr and Sha, Fei and Zepeda-N. Proceedings of the 41st International Conference on Machine Learning , series=
-
[33]
Advances in Neural Information Processing Systems , volume=
Beyond Closure Models: Learning Chaotic-Systems via Physics-Informed Neural Operators , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Proceedings of the 13th International Conference on Learning Representations , year=
Learning Chaos In A Linear Way , author=. Proceedings of the 13th International Conference on Learning Representations , year=
-
[35]
On the Difficulty of Learning Chaotic Dynamics with
Mikhaeil, Jonas M and Monfared, Zahra and Durstewitz, Daniel , booktitle=. On the Difficulty of Learning Chaotic Dynamics with
-
[36]
Proceedings of the 40th International Conference on Machine Learning , series=
Generalized Teacher Forcing for Learning Chaotic Dynamics , author=. Proceedings of the 40th International Conference on Machine Learning , series=
-
[37]
Nonlinear Dynamics: A Primer , DOI=
Medio, Alfredo and Lines, Marji , year=. Nonlinear Dynamics: A Primer , DOI=
-
[38]
Dorfman, J. R. , year=. An Introduction to Chaos in Nonequilibrium Statistical Mechanics , DOI=
-
[39]
2015 , month =
Davidson, Peter , title = ". 2015 , month =
2015
-
[40]
2022 , eprint=
FourCastNet: A Global Data-driven High-resolution Weather Model using Adaptive Fourier Neural Operators , author=. 2022 , eprint=
2022
-
[41]
Uncovering turbulent plasma dynamics via deep learning from partial observations , author =. Phys. Rev. E , volume =. 2021 , month =. doi:10.1103/PhysRevE.104.025205 , url =
-
[42]
and Chmiela, Stefan and Sauceda, Huziel E
Unke, Oliver T. and Chmiela, Stefan and Sauceda, Huziel E. and Gastegger, Michael and Poltavsky, Igor and Sch. Machine Learning Force Fields , journal=. 2021 , month=
2021
-
[43]
and Kornbluth, Mordechai and Kozinsky, Boris , title=
Musaelian, Albert and Batzner, Simon and Johansson, Anders and Sun, Lixin and Owen, Cameron J. and Kornbluth, Mordechai and Kozinsky, Boris , title=. Nature Communications , year=
-
[44]
International Conference on Learning Representations , year=
Fourier Neural Operator for Parametric Partial Differential Equations , author=. International Conference on Learning Representations , year=
-
[45]
Nature Machine Intelligence , year=
Lu, Lu and Jin, Pengzhan and Pang, Guofei and Zhang, Zhongqiang and Karniadakis, George Em , title=. Nature Machine Intelligence , year=
-
[46]
On the difficulty of learning chaotic dynamics with RNNs
Mikhaeil, Jonas M and Monfared, Zahra and Durstewitz, Daniel. On the difficulty of learning chaotic dynamics with RNNs. Advances in Neural Information Processing Systems
-
[47]
2015 , publisher=
Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering , author=. 2015 , publisher=
2015
-
[48]
Annual Review of Condensed Matter Physics , volume=
Machine learning for climate physics and simulations , author=. Annual Review of Condensed Matter Physics , volume=. 2024 , publisher=
2024
-
[49]
Science , volume=
Learning skillful medium-range global weather forecasting , author=. Science , volume=. 2023 , publisher=
2023
-
[50]
Nature , volume=
Neural general circulation models for weather and climate , author=. Nature , volume=. 2024 , publisher=
2024
-
[51]
ACE: A fast, skillful learned global atmospheric model for climate prediction
ACE: A fast, skillful learned global atmospheric model for climate prediction , author=. arXiv preprint arXiv:2310.02074 , year=
-
[52]
2024 , eprint=
Challenges of learning multi-scale dynamics with AI weather models: Implications for stability and one solution , author=. 2024 , eprint=
2024
-
[53]
Geophysical Research Letters , volume=
On some limitations of current machine learning weather prediction models , author=. Geophysical Research Letters , volume=. 2024 , publisher=
2024
-
[54]
Subspace Robust
Paty, Fran. Subspace Robust. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[55]
Chandler, Gary J. and Kerswell, Rich R. , year=. Invariant recurrent solutions embedded in a turbulent two-dimensional Kolmogorov flow , volume=. doi:10.1017/jfm.2013.122 , journal=
-
[56]
The Kuramoto-Sivashinsky equation: A bridge between PDE'S and dynamical systems , journal =. 1986 , issn =. doi:https://doi.org/10.1016/0167-2789(86)90166-1 , author =
-
[57]
and Brunton, Bingni W
Brunton, Steven L. and Brunton, Bingni W. and Proctor, Joshua L. and Kaiser, Eurika and Kutz, J. Nathan , title =. Nature Communications , volume =. 2017 , doi =
2017
-
[58]
International Conference on Learning Representations , year =
Khromov, Grigory and Pal Singh, Sidak , title =. International Conference on Learning Representations , year =
-
[59]
Journal of Advances in Modeling Earth Systems , volume=
Learning closed-form equations for subgrid-scale closures from high-fidelity data: Promises and challenges , author=. Journal of Advances in Modeling Earth Systems , volume=. 2024 , publisher=
2024
-
[60]
Part 1: Theory , author=
Lyapunov characteristic exponents for smooth dynamical systems and for Hamiltonian systems; a method for computing all of them. Part 1: Theory , author=. Meccanica , volume=. 1980 , publisher=
1980
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.