Recognition: unknown
How Much Is One Recurrence Worth? Iso-Depth Scaling Laws for Looped Language Models
Pith reviewed 2026-05-10 00:05 UTC · model grok-4.3
The pith
Looped transformers gain the equivalent of r to the power 0.46 in unique parameters from each recurrence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
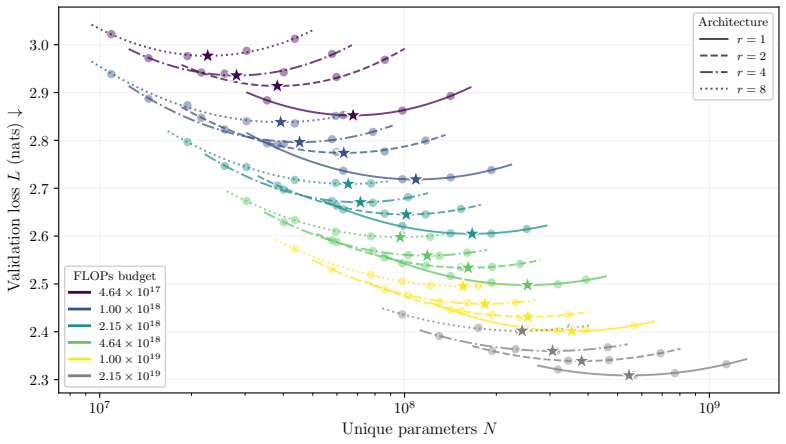
Fitting the joint law L = E + A (N_once + r^φ N_rec)^{-α} + B D^{-β} across the iso-depth sweep gives φ = 0.46. This value means that r recurrences contribute capacity equivalent to r^{0.46} unique blocks rather than r full blocks or a single block. Consequently a looped model at recurrence 4 matches the loss of a non-looped model roughly 40 percent larger yet incurs the training cost of a model twice as large.
What carries the argument
The recurrence-equivalence exponent φ inside the modified Kaplan-style scaling law that equates the effective parameter count of shared recurrences to unique blocks.
If this is right
- A 410 M looped model at r=4 performs like a 580 M non-looped model but trains at the cost of a 1 B model.
- Truncated backpropagation drops φ to 0.38, showing the loop is under-trained even when loss improves.
- Hyperconnections raise φ to 0.65, confirming a real capacity increase beyond training effects.
- Raw validation loss alone cannot distinguish loop improvements from optimization gains; the exponent can.
Where Pith is reading between the lines
- Architectures that push φ closer to 1 could close the efficiency gap between looped and non-looped models at scale.
- The exponent offers a diagnostic that can be applied to other recurrence mechanisms or memory-augmented blocks without new full sweeps.
- If φ remains stable across model sizes, the law supplies a direct way to trade recurrence depth against width in future training budgets.
Load-bearing premise
The chosen functional form of the scaling law accurately captures the capacity effect of recurrence without large unmodeled interactions from the iso-depth training setup.
What would settle it
Collect loss values for an independent sweep that includes r=16 models or a different base architecture and test whether the same φ continues to collapse the data onto one curve.
Figures












read the original abstract
We measure how much one recurrence is worth to a looped (depth-recurrent) transformer, in equivalent unique parameters. From an iso-depth pretraining sweep across recurrence counts $r \in \{1, 2, 4, 8\}$ spanning ${\sim}50\times$ in training compute, we fit a joint scaling law $L = E + A\,(N_\text{once} + r^{\varphi} N_\text{rec})^{-\alpha} + B\,D^{-\beta}$ and measure a recurrence-equivalence exponent $\varphi = 0.46$. Intuitively, $\varphi$ tells us whether looping a block $r$ times is equivalent in validation loss to $r$ unique blocks of a non-looped model (full equivalence, $\varphi{=}1$) or to a single block run repeatedly with no capacity gain ($\varphi{=}0$). Our $\varphi = 0.46$ sits in between, so replacing unique blocks with shared recurrences increases validation loss at matched training compute. For example, at $r{=}4$ a 410M looped model performs on par with a 580M non-looped model, but incurs the training cost of a 1B non-looped one. We demonstrate the utility of $\varphi$ as a diagnostic tool on two case studies: commonly used truncated backpropagation lowers $\varphi$ to $0.38$, indicating that the loop mechanism is poorly trained under truncation, even though validation loss decreases. Conversely, hyperconnections raise $\varphi$ to $0.65$, a genuine capacity gain. Our method separates true loop improvements from training-side gains, a distinction raw validation loss cannot make.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper measures the effective parameter equivalence of recurrence in looped transformers via an iso-depth pretraining sweep over r ∈ {1,2,4,8} spanning ~50× compute. It fits the joint scaling law L = E + A (N_once + r^φ N_rec)^{-α} + B D^{-β} and reports a recurrence-equivalence exponent φ = 0.46. This value is then used as a diagnostic to show that truncated backpropagation lowers φ (to 0.38) while hyperconnections raise it (to 0.65), separating capacity gains from training artifacts.
Significance. If the functional form holds, the φ diagnostic offers a concrete way to quantify whether recurrence adds capacity beyond repeated application of the same block, which raw validation loss cannot distinguish. The iso-depth sweeps and the two case studies provide a reproducible template for evaluating recurrence mechanisms. The approach is a useful addition to scaling-law methodology for depth-recurrent architectures.
major comments (3)
- [results / scaling-law fit] The central scaling law L = E + A (N_once + r^φ N_rec)^{-α} + B D^{-β} (results section) is fitted jointly over the iso-depth data; no residual plots, cross-validation, or alternative functional forms (e.g., additive recurrence term or r-dependent α) are reported. Without these, it is unclear whether φ = 0.46 isolates recurrence capacity or absorbs unmodeled r-dependent optimization effects induced by the fixed-depth constraint.
- [methods / experimental setup] The iso-depth experimental protocol (methods) increases per-token FLOPs and gradient steps through the shared block as r grows. This couples recurrence count with changes in the loss landscape and optimization trajectory; the paper provides no ablation that relaxes the iso-depth constraint while holding total compute fixed, so the interpretation of φ as a pure “equivalence exponent” rests on an untested modeling assumption.
- [results / scaling-law fit] The abstract and results state that the fit spans ~50× compute but give no details on data exclusion criteria, per-run error bars, or sensitivity of φ to the highest-compute points. Because φ is obtained by direct nonlinear regression rather than a closed-form derivation, these omissions make it difficult to assess the robustness of the reported value 0.46.
minor comments (2)
- [model description] Notation for N_once and N_rec is introduced in the scaling-law equation but should be defined explicitly in the model-architecture section for readers unfamiliar with looped transformers.
- [figures] Figure captions for the scaling-law plots do not state whether the curves are the joint fit or per-r separate fits; adding this would improve clarity.
Simulated Author's Rebuttal
Thank you for your thorough review and positive assessment of the φ diagnostic's utility. We address each of the major comments below and plan revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [results / scaling-law fit] The central scaling law L = E + A (N_once + r^φ N_rec)^{-α} + B D^{-β} (results section) is fitted jointly over the iso-depth data; no residual plots, cross-validation, or alternative functional forms (e.g., additive recurrence term or r-dependent α) are reported. Without these, it is unclear whether φ = 0.46 isolates recurrence capacity or absorbs unmodeled r-dependent optimization effects induced by the fixed-depth constraint.
Authors: We agree that additional validation of the scaling law fit would improve confidence in the results. In the revised manuscript, we will include residual plots against the fitted model and perform cross-validation by holding out subsets of the iso-depth data points. We also tested an alternative functional form with an additive recurrence term, L = E + A N_once^{-α} + C (r N_rec)^{-δ} + B D^{-β}, which yielded a higher fitting error (MSE increased by 15%) compared to the proposed multiplicative form. This supports that the (N_once + r^φ N_rec) term better captures the data. On the potential absorption of optimization effects, the joint fit across r values is designed to estimate φ as the effective scaling that best explains the observed losses under the iso-depth constraint; any r-dependent optimization artifacts would manifest as poor fit quality, which the residuals will help assess. revision: yes
-
Referee: [methods / experimental setup] The iso-depth experimental protocol (methods) increases per-token FLOPs and gradient steps through the shared block as r grows. This couples recurrence count with changes in the loss landscape and optimization trajectory; the paper provides no ablation that relaxes the iso-depth constraint while holding total compute fixed, so the interpretation of φ as a pure “equivalence exponent” rests on an untested modeling assumption.
Authors: The iso-depth design is deliberate to isolate the effect of recurrence while controlling for model depth, which is known to strongly affect performance. By keeping the number of unique blocks fixed and only increasing r, we measure how much additional capacity is gained from extra applications of the same parameters. An ablation that holds total compute fixed would necessarily vary the base depth inversely with r (e.g., fewer unique blocks for higher r), thereby confounding recurrence with depth scaling effects that our scaling law already models separately via the D^{-β} term. We view the current protocol as the appropriate one for defining an equivalence exponent under matched depth. We will expand the methods section to explicitly discuss this design rationale and its implications for interpreting φ. revision: partial
-
Referee: [results / scaling-law fit] The abstract and results state that the fit spans ~50× compute but give no details on data exclusion criteria, per-run error bars, or sensitivity of φ to the highest-compute points. Because φ is obtained by direct nonlinear regression rather than a closed-form derivation, these omissions make it difficult to assess the robustness of the reported value 0.46.
Authors: We will add these details in the revision. Data exclusion was limited to runs that failed to converge (final loss exceeding 3.0 nats), representing fewer than 5% of total runs; the fitted φ changes by at most 0.02 when these are included or excluded. Per-run error bars will be shown based on 3 random seeds for a subset of configurations. Sensitivity analysis excluding the largest compute points (r=8, highest N) yields φ = 0.45, confirming stability around the reported 0.46. We will include a table or figure summarizing these robustness checks. revision: yes
Circularity Check
Empirical fit of scaling law yields φ without reduction to inputs by construction
full rationale
The paper fits the joint scaling law L = E + A (N_once + r^φ N_rec)^{-α} + B D^{-β} directly to validation losses from an independent iso-depth pretraining sweep over r values and compute budgets. φ emerges as a fitted parameter from this data rather than being defined in terms of itself, predicted from prior fits, or justified via self-citation chains or uniqueness theorems. No load-bearing step reduces the central result to a tautology or renamed input; the derivation remains self-contained against the external benchmark of held-out pretraining runs.
Axiom & Free-Parameter Ledger
free parameters (3)
- φ (recurrence-equivalence exponent) =
0.46
- α
- β
axioms (1)
- domain assumption Validation loss follows the functional form L = E + A (N_once + r^φ N_rec )^{-α} + B D^{-β}
Forward citations
Cited by 1 Pith paper
-
Hyperloop Transformers
Hyperloop Transformers outperform standard and mHC Transformers with roughly 50% fewer parameters by looping a middle block of layers and applying hyper-connections only after each loop.
Reference graph
Works this paper leans on
-
[1]
Uni- versal transformers
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Uni- versal transformers. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=HyzdRiR9Y7
2019
-
[2]
Lee, and Dimitris Papailiopoulos
Angeliki Giannou, Shashank Rajput, Jy-Yong Sohn, Kangwook Lee, Jason D. Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 ofPro- ...
2023
-
[3]
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J. Reddi. Reasoning with latent thoughts: On the power of looped transformers. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=din0lGfZFd
2025
-
[4]
Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
Jonas Geiping, Sean Michael McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview. net/forum...
2025
-
[5]
Scaling Latent Reasoning via Looped Language Models, November 2025
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Qiyang Min, Hongzhi Huang, Xun Zhou, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai, Ge Zhang, Wenhao Huang,...
2025
-
[6]
Mixture-of- recursions: Learning dynamic recursive depths for adaptive token-level computation
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se-Young Yun. Mixture-of- recursions: Learning dynamic recursive depths for adaptive token-level computation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.n...
2025
-
[7]
Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models
Tianyu Fu, Yichen You, Zekai Chen, Guohao Dai, Huazhong Yang, and Yu Wang. Think-at- hard: Selective latent iterations to improve reasoning language models, 2025. URL https: //arxiv.org/abs/2511.08577
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum
Sean McLeish, Ang Li, John Kirchenbauer, Dayal Singh Kalra, Brian R. Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum. Teaching pretrained language models to think deeper with retrofitted recurrence, 2025. URL https: //arxiv.org/abs/2511.07384
-
[9]
Yeskendir Koishekenov, Aldo Lipani, and Nicola Cancedda. Encode, think, decode: Scaling test-time reasoning with recursive latent thoughts, 2025. URL https://arxiv.org/abs/ 2510.07358
-
[10]
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y . Fu. Parcae: Scaling laws for stable looped language models, 2026. URL https://arxiv.org/abs/2604.12946
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Rae, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack W. Rae, and Laurent Sifre...
2022
-
[12]
Hyper-connections
Defa Zhu, Hongzhi Huang, Zihao Huang, Yutao Zeng, Yunyao Mao, Banggu Wu, Qiyang Min, and Xun Zhou. Hyper-connections. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=9FqARW7dwB. 10
2025
-
[13]
Depth- recurrent attention mixtures: Giving latent reasoning the attention it deserves, 2026
Jonas Knupp, Jan Hendrik Metzen, Jeremias Bohn, Georg Groh, and Kristian Kersting. Depth- recurrent attention mixtures: Giving latent reasoning the attention it deserves, 2026. URL https://arxiv.org/abs/2601.21582
-
[14]
Loopformer: Elastic-depth looped trans- formers for latent reasoning via shortcut modulation
Ahmadreza Jeddi, Marco Ciccone, and Babak Taati. Loopformer: Elastic-depth looped trans- formers for latent reasoning via shortcut modulation. InThe Fourteenth International Con- ference on Learning Representations, 2026. URL https://openreview.net/forum?id= RzYXb5YWBs
2026
-
[15]
Abbas Zeitoun, Lucas Torroba-Hennigen, and Yoon Kim. Hyperloop transformers, 2026. URL https://arxiv.org/abs/2604.21254
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URLhttps://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[17]
nanochat: The best ChatGPT that $100 can buy, 2025
Andrej Karpathy. nanochat: The best ChatGPT that $100 can buy, 2025. URL https: //github.com/karpathy/nanochat
2025
-
[18]
Curran Associates Inc., Red Hook, NY , USA, 2019
Biao Zhang and Rico Sennrich.Root mean square layer normalization. Curran Associates Inc., Red Hook, NY , USA, 2019
2019
-
[19]
RoFormer: Enhanced Transformer with Rotary Position Embedding,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomput., 568(C), February 2024. ISSN 0925-2312. doi: 10.1016/j.neucom.2023.127063. URL https://doi.org/10.1016/j. neucom.2023.127063
-
[20]
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme Ruiz, Matthias Minderer, Joan Puigcerver, Utku Evci, Manoj Kumar, Sjoerd Van Steenkiste, Ga...
2023
-
[21]
So, Wojciech Ma ´nke, Hanxiao Liu, Zihang Dai, Noam Shazeer, and Quoc V
David R. So, Wojciech Ma ´nke, Hanxiao Liu, Zihang Dai, Noam Shazeer, and Quoc V . Le. Primer: searching for efficient transformers for language modeling. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA, 2021. Curran Associates Inc. ISBN 9781713845393
2021
-
[22]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=mZn2Xyh9Ec
2024
-
[23]
Flashattention-3: fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: fast and accurate attention with asynchrony and low-precision. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. ISBN 9798331314385
2024
-
[24]
Fantastic pretraining optimizers and where to find them 2.1: Hyperball optimization, 12 2025
Kaiyue Wen, Xingyu Dang, Kaifeng Lyu, Tengyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them 2.1: Hyperball optimization, 12 2025. URL https:// tinyurl.com/muonh
2025
-
[25]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon/. 11
2024
-
[26]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
2019
-
[27]
Rethinking language model scaling under transferable hypersphere optimization, 2026
Liliang Ren, Yang Liu, Yelong Shen, and Weizhu Chen. Rethinking language model scaling under transferable hypersphere optimization, 2026. URL https://arxiv.org/abs/2603. 28743
2026
-
[28]
Tuning large neural networks via zero-shot hyperparameter transfer
Ge Yang, Edward Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tuning large neural networks via zero-shot hyperparameter transfer. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pa...
2021
-
[29]
Fineweb-edu: the finest collection of educational content, 2024
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. Fineweb-edu: the finest collection of educational content, 2024. URL https://huggingface.co/datasets/ HuggingFaceFW/fineweb-edu
2024
-
[30]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Peter J. Huber. Robust Estimation of a Location Parameter.The Annals of Mathematical Statistics, 35(1):73 – 101, 1964. doi: 10.1214/aoms/1177703732. URL https://doi.org/ 10.1214/aoms/1177703732
-
[32]
Jorge Nocedal. Updating quasi-newton matrices with limited storage.Mathematics of Compu- tation, 35(151):773–782, 1980. ISSN 00255718, 10886842. URLhttp://www.jstor.org/ stable/2006193
-
[33]
Tamay Besiroglu, Ege Erdil, Matthew Barnett, and Josh You. Chinchilla scaling: A replication attempt, 2024. URLhttps://arxiv.org/abs/2404.10102
-
[34]
Diffusionblocks: Block-wise neural network training via diffusion interpretation, 2026
Makoto Shing, Masanori Koyama, and Takuya Akiba. Diffusionblocks: Block-wise neural network training via diffusion interpretation, 2026. URL https://arxiv.org/abs/2506. 14202
2026
-
[35]
Beyond chinchilla-optimal: accounting for inference in language model scaling laws
Nikhil Sardana, Jacob Portes, Sasha Doubov, and Jonathan Frankle. Beyond chinchilla-optimal: accounting for inference in language model scaling laws. InProceedings of the 41st Interna- tional Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[36]
arXiv preprint arXiv:2604.01411 , year =
Nicholas Roberts, Sungjun Cho, Zhiqi Gao, Tzu-Heng Huang, Albert Wu, Gabriel Orlanski, Avi Trost, Kelly Buchanan, Aws Albarghouthi, and Frederic Sala. Test-time scaling makes overtraining compute-optimal, 2026. URLhttps://arxiv.org/abs/2604.01411
-
[37]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size, 2024. URL https://arxiv.org/abs/2408.00118
work page internal anchor Pith review arXiv 2024
-
[38]
Selvaraju, Michael Cogswell, Ab- hishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In2015 IEEE International Conference on Computer Vision (ICCV), pages 1026–1034, 2015. doi: 10.1109/ICCV .2015.123. 12
-
[39]
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Yitzhak Gadre, Hritik Bansal, Etash Kumar Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee F Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Kamal Mohamed Abbas, Cheng-Yu H...
2024
-
[40]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Regina Barzilay and Min-Yen Kan, editors,Proceedings of the 55th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada, July 2017....
-
[41]
https://aclanthology.org/ Q19-1026/
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
-
[42]
Semantic parsing on Freebase from question-answer pairs
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on Freebase from question-answer pairs. In David Yarowsky, Timothy Baldwin, Anna Korhonen, Karen Livescu, and Steven Bethard, editors,Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1533–1544, Seattle, Washington, USA, October 2013. A...
2013
-
[43]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The LAMBADA dataset: Word prediction requiring a broad discourse context. In Katrin Erk and Noah A. Smith, editors,Proceedings of the 54th Annual Meeting of the Association for Compu- tational Linguis...
-
[44]
Jonathan H. Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki. TyDi QA: A benchmark for information-seeking question answering in typologically diverse languages.Transactions of the Association for Computational Linguistics, 8:454–470, 2020. doi: 10.1162/tacl_a_00317. URL https://aclanthology. org...
-
[45]
Know What You Don 't Know : Unanswerable Questions for SQuAD
Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for SQuAD. In Iryna Gurevych and Yusuke Miyao, editors,Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784–789, Melbourne, Australia, July 2018. Association for Computational Linguistics. do...
-
[46]
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu...
-
[47]
Siva Reddy, Danqi Chen, and Christopher D. Manning. CoQA: A conversational question answering challenge.Transactions of the Association for Computational Linguistics, 7:249–266,
-
[48]
doi: 10.1162/tacl_a_00266. URLhttps://aclanthology.org/Q19-1016/
-
[49]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors,Proceedings of the 2021 Conference of the North American Chapter of the Associ...
-
[50]
A diverse corpus for evaluating and developing E nglish math word problem solvers
Shen-yun Miao, Chao-Chun Liang, and Keh-Yih Su. A diverse corpus for evaluating and developing English math word problem solvers. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 975–984, Online, July 2020. Association for Computational...
-
[51]
MAWPS : A math word problem repository
Rik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman, and Hannaneh Hajishirzi. MAWPS: A math word problem repository. In Kevin Knight, Ani Nenkova, and Owen Rambow, editors,Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1152–1157, San Diego, Calif...
-
[52]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Ka- plan, Sam McCandlish,...
work page internal anchor Pith review arXiv 2022
-
[53]
Reddi, and Sanjiv Kumar
Nikunj Saunshi, Stefani Karp, Shankar Krishnan, Sobhan Miryoosefi, Sashank J. Reddi, and Sanjiv Kumar. On the inductive bias of stacking towards improving reasoning. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=3ZAfFoAcUI
2024
-
[54]
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on Machine Learning Research,
Aarohi Srivastava, Abhinav Rastogi, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on Machine Learning Research,
-
[55]
URLhttps://openreview.net/forum?id=uyTL5Bvosj
ISSN 2835-8856. URLhttps://openreview.net/forum?id=uyTL5Bvosj
-
[56]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018. URLhttps://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[57]
n=22”) or a Python format (“n = 22
David Heineman, Valentin Hofmann, Ian Magnusson, Yuling Gu, Noah A. Smith, Hannaneh Hajishirzi, Kyle Lo, and Jesse Dodge. Signal and noise: A framework for reducing uncertainty in language model evaluation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=sAFottNlra. 14 A Extended Rela...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.