Recognition: unknown
Self-Predictive Representation for Autonomous UAV Object-Goal Navigation
Pith reviewed 2026-05-09 23:28 UTC · model grok-4.3
The pith
A novel self-predictive model for state representations substantially improves sample efficiency when combined with reinforcement learning for UAV object-goal navigation in 3D space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
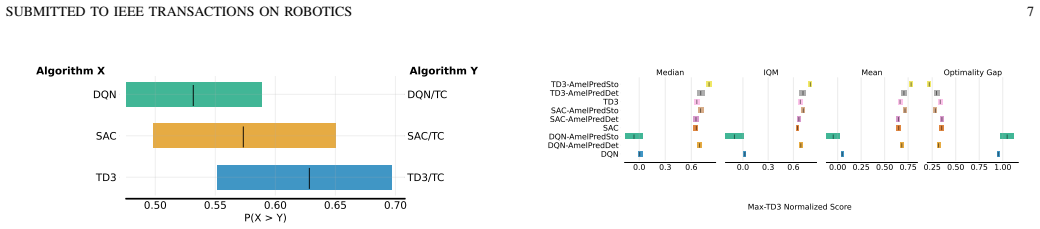
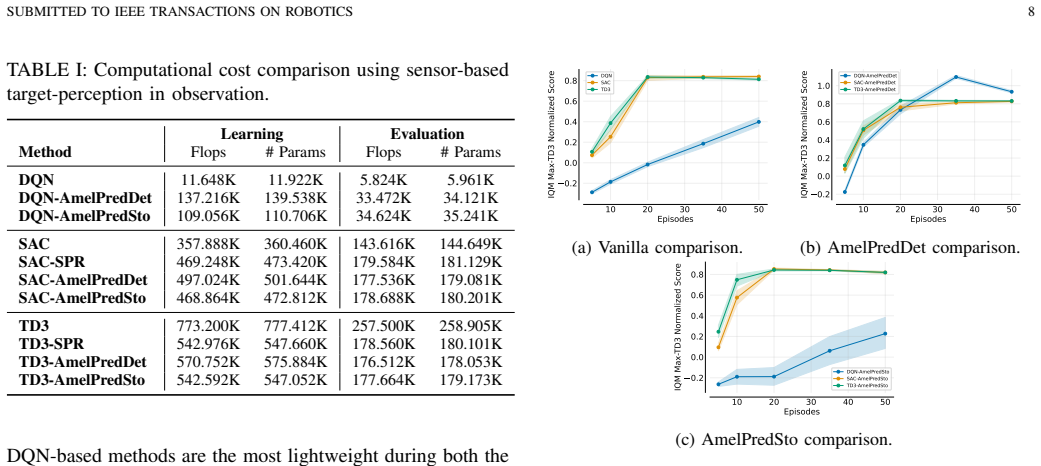
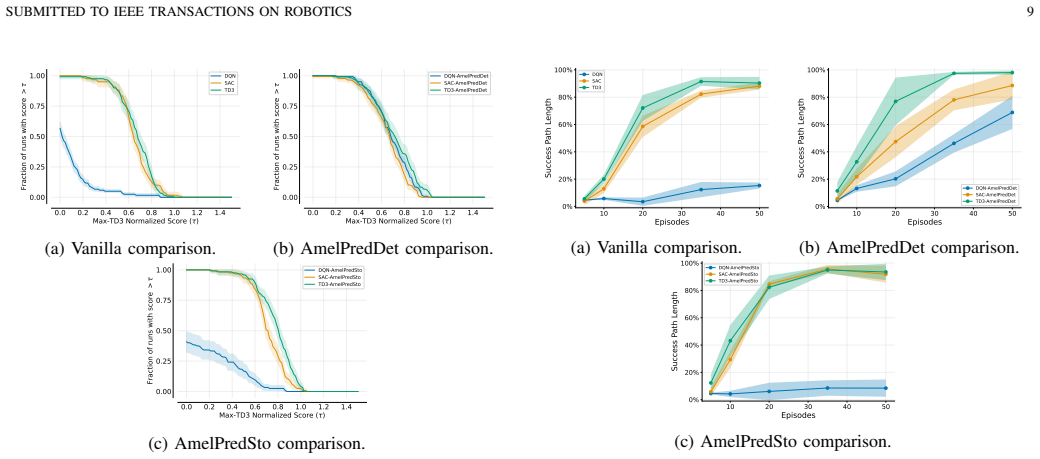
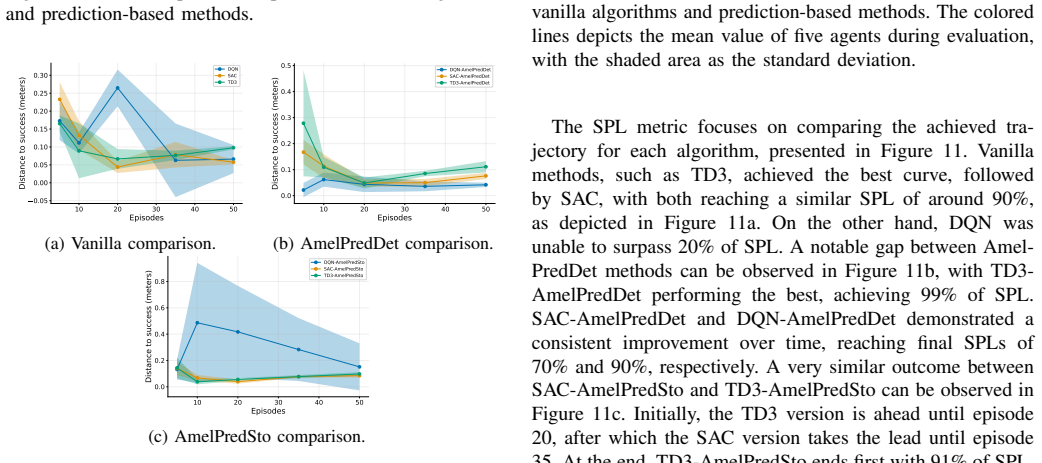
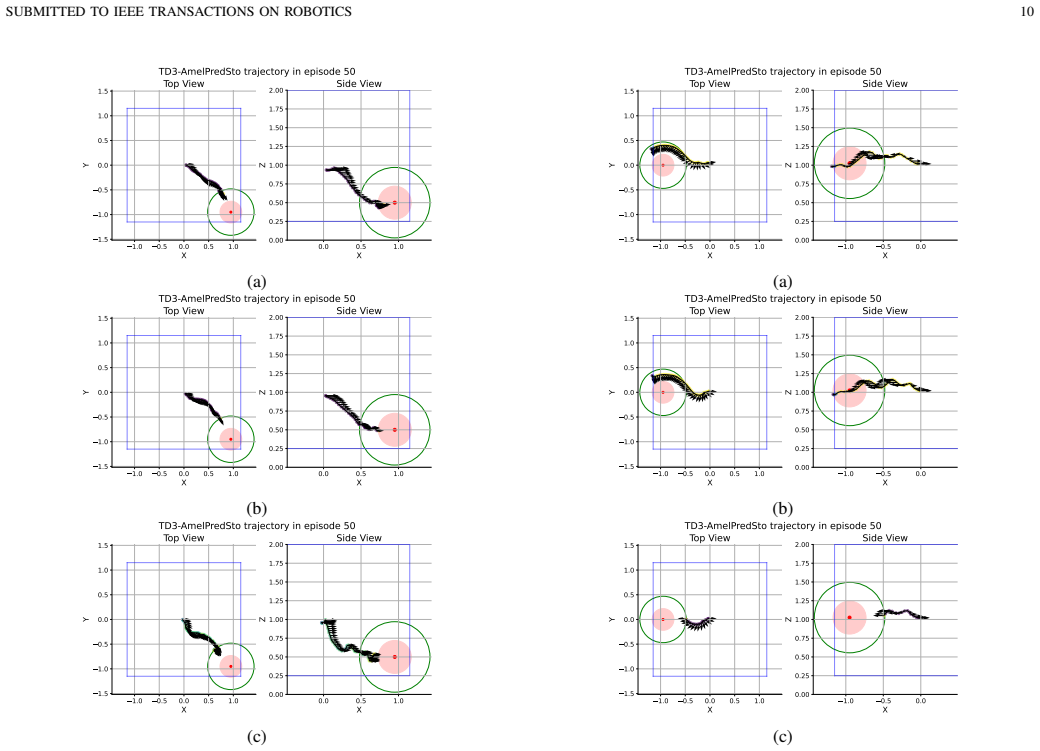
The main contribution is the development of the perception module featuring a novel self-predictive model named AmelPred. Empirical results demonstrate that its stochastic version, AmelPredSto, is the best-performing SRL model when combined with actor-critic RL algorithms. The obtained results show substantial improvement in RL algorithms' efficiency by using AmelPredSto in solving the OGN problem.
What carries the argument
AmelPred, a self-predictive model that learns state representations to supply improved inputs to a model-free reinforcement learning planner for object-goal navigation.
If this is right
- Actor-critic reinforcement learning reaches effective navigation policies with fewer environment interactions in three-dimensional object-goal tasks.
- UAV systems gain a practical path to autonomous operation in open spaces by reducing the data volume needed for training.
- State representation learning that incorporates self-prediction becomes a preferred perception component when planning relies on model-free methods.
- The Markov decision process formalization enables systematic comparison of perception and planning modules in similar navigation problems.
Where Pith is reading between the lines
- Similar self-predictive representations could reduce sample needs in other robotic control settings that combine vision with continuous action spaces.
- Integrating explicit visual object detectors with the learned representations might further lower the data cost of recognizing targets during flight.
- The approach offers a route to analyze how perception quality directly affects planning sample efficiency in partially observable environments.
Load-bearing premise
That the representations learned by the self-predictive model will reliably support target recognition and yield efficiency gains when paired with model-free RL without further mechanisms for handling unknown locations.
What would settle it
An experiment repeating the reported comparisons and finding no measurable reduction in samples required to reach target success rates when using the stochastic self-predictive model versus standard state representation baselines.
Figures





read the original abstract
Autonomous Unmanned Aerial Vehicles (UAVs) have revolutionized industries through their versatility with applications including aerial surveillance, search and rescue, agriculture, and delivery. Their autonomous capabilities offer unique advantages, such as operating in large open space environments. Reinforcement Learning (RL) empowers UAVs to learn intricate navigation policies, enabling them to optimize flight behavior autonomously. However, one of its main challenge is the inefficiency in using data sample to achieve a good policy. In object-goal navigation (OGN) settings, target recognition arises as an extra challenge. Most UAV-related approaches use relative or absolute coordinates to move from an initial position to a predefined location, rather than to find the target directly. This study addresses the data sample efficiency issue in solving a 3D OGN problem, in addition to, the formalization of the unknown target location setting as a Markov decision process. Experiments are conducted to analyze the interplay of different state representation learning (SRL) methods for perception with a model-free RL algorithm for planning in an autonomous navigation system. The main contribution of this study is the development of the perception module, featuring a novel self-predictive model named AmelPred. Empirical results demonstrate that its stochastic version, AmelPredSto, is the best-performing SRL model when combined with actor-critic RL algorithms. The obtained results show substantial improvement in RL algorithms' efficiency by using AmelPredSto in solving the OGN problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a novel self-predictive representation learning model (AmelPred and its stochastic variant AmelPredSto) for the perception module in UAV-based 3D object-goal navigation. It formalizes the unknown-target setting as an MDP and claims that AmelPredSto, when paired with actor-critic RL, is the best-performing SRL method and yields substantial gains in sample efficiency over other approaches.
Significance. If the empirical superiority holds under rigorous controls, the work would offer a concrete advance in integrating self-supervised perception with model-free RL for UAV navigation in large 3D spaces, with potential relevance to sample-efficient policies in search-and-rescue or surveillance tasks.
major comments (2)
- [Abstract] Abstract: the central claim of empirical superiority for AmelPredSto (best SRL model, substantial RL efficiency gains) is asserted without any information on baselines, metrics, environment details, statistical significance, or ablation studies, making it impossible to assess whether the data support the claim.
- [Abstract] Abstract: formalization of the unknown-target OGN setting as an MDP is load-bearing for attributing efficiency gains to the self-predictive model. If target recognition is not encoded in the state passed to the policy, the transition kernel is not Markovian, and any reported gains may instead reflect an implicit POMDP reduction whose validity is untested.
minor comments (1)
- [Abstract] Abstract contains a grammatical error ('one of its main challenge' should be 'one of its main challenges').
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a novel self-predictive representation learning model (AmelPred and its stochastic variant AmelPredSto) as a perception module, then evaluates its empirical performance when paired with standard actor-critic RL algorithms on a 3D object-goal navigation task. The central claims rest on experimental comparisons of sample efficiency rather than any closed-form derivation, parameter fitting that is later relabeled as prediction, or self-citation chains that bear the load of the main result. The MDP formalization of the unknown-target setting is presented as a modeling choice to enable RL application; no equations or steps reduce the claimed efficiency gains to the inputs by construction. The approach is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The unknown target location setting can be formalized as a Markov decision process.
invented entities (1)
-
AmelPred
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Unmanned aerial vehicle for internet of everything: Opportunities and challenges,
Y . Liu, H.-N. Dai, Q. Wang, M. K. Shukla, and M. Imran, “Unmanned aerial vehicle for internet of everything: Opportunities and challenges,” Computer communications, vol. 155, pp. 66–83, 2020
2020
-
[2]
Towards the unmanned aerial vehicles (UA Vs): A comprehensive review,
S. A. H. Mohsan, M. A. Khan, F. Noor, I. Ullah, and M. H. Alsharif, “Towards the unmanned aerial vehicles (UA Vs): A comprehensive review,”Drones, vol. 6, no. 6, p. 147, 2022
2022
-
[3]
Unmanned aerial vehicles in agriculture: A survey,
J. del Cerro, C. Cruz Ulloa, A. Barrientos, and J. de Le ´on Rivas, “Unmanned aerial vehicles in agriculture: A survey,”Agronomy, vol. 11, no. 2, p. 203, 2021
2021
-
[4]
A review of quadrotor UA V: Control and SLAM method- ologies ranging from conventional to innovative approaches,
G. Sonug ¨ur, “A review of quadrotor UA V: Control and SLAM method- ologies ranging from conventional to innovative approaches,”Robotics and Autonomous Systems, vol. 161, p. 104342, 2023
2023
-
[5]
Intro- ducing autonomous aerial robots in industrial manufacturing,
F. J. Perez-Grau, J. R. Martinez-de Dios, J. L. Paneque, J. J. Acevedo, A. Torres-Gonz ´alez, A. Viguria, J. R. Astorga, and A. Ollero, “Intro- ducing autonomous aerial robots in industrial manufacturing,”Journal of Manufacturing Systems, vol. 60, pp. 312–324, 2021
2021
-
[6]
Introduction to feedback control of underactuated VTOL vehicles: A review of basic control design ideas and principles,
M.-D. Hua, T. Hamel, P. Morin, and C. Samson, “Introduction to feedback control of underactuated VTOL vehicles: A review of basic control design ideas and principles,”IEEE Control systems magazine, vol. 33, no. 1, pp. 61–75, 2013. SUBMITTED TO IEEE TRANSACTIONS ON ROBOTICS 12
2013
-
[7]
Position control of quadrotor UA V based on cascade fuzzy neural network,
J. Rao, B. Li, Z. Zhang, D. Chen, and W. Giernacki, “Position control of quadrotor UA V based on cascade fuzzy neural network,”Energies, vol. 15, no. 5, p. 1763, 2022
2022
-
[8]
Intelligent position controller for unmanned aerial vehicles (UA V) based on supervised deep learning,
J. A. Cardenas, U. E. Carrero, E. C. Camacho, and J. M. Calderon, “Intelligent position controller for unmanned aerial vehicles (UA V) based on supervised deep learning,”Machines, vol. 11, no. 6, p. 606, 2023
2023
-
[9]
Advances in intelligent and autonomous navigation systems for small UAS,
S. Bijjahalli, R. Sabatini, and A. Gardi, “Advances in intelligent and autonomous navigation systems for small UAS,”Progress in Aerospace Sciences, vol. 115, p. 100617, 2020
2020
-
[10]
R. S. Sutton and A. G. Barto,Reinforcement learning: An introduction. MIT press, 2018
2018
-
[11]
Drone deep reinforcement learning: A review,
A. T. Azar, A. Koubaa, N. Ali Mohamed, H. A. Ibrahim, Z. F. Ibrahim, M. Kazim, A. Ammar, B. Benjdira, A. M. Khamis, I. A. Hameedet al., “Drone deep reinforcement learning: A review,”Electronics, vol. 10, no. 9, p. 999, 2021
2021
-
[12]
Memory-enhanced deep reinforcement learning for UA V navigation in 3d environment,
C. Fu, X. Xu, Y . Zhang, Y . Lyu, Y . Xia, Z. Zhou, and W. Wu, “Memory-enhanced deep reinforcement learning for UA V navigation in 3d environment,”Neural Computing and Applications, vol. 34, no. 17, pp. 14 599–14 607, 2022
2022
-
[13]
A survey on vision-based UA V navigation,
Y . Lu, Z. Xue, G.-S. Xia, and L. Zhang, “A survey on vision-based UA V navigation,”Geo-spatial information science, vol. 21, no. 1, pp. 21–32, 2018
2018
-
[14]
UA V control in autonomous object-goal navigation: A systematic literature review,
A. Ayala, L. Portela, F. Buarque, B. J. Fernandes, and F. Cruz, “UA V control in autonomous object-goal navigation: A systematic literature review,”Artificial Intelligence Review, vol. 57, no. 5, pp. 1–64, 2024
2024
-
[15]
Object-goal visual navigation via effective exploration of relations among historical navigation states,
H. Du, L. Li, Z. Huang, and X. Yu, “Object-goal visual navigation via effective exploration of relations among historical navigation states,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2563–2573
2023
-
[16]
ENTL: Embodied naviga- tion trajectory learner,
K. Kotar, A. Walsman, and R. Mottaghi, “ENTL: Embodied naviga- tion trajectory learner,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 863–10 872
2023
-
[17]
Learning cognitive map representations for navigation by sensory–motor integra- tion,
D. Zhao, Z. Zhang, H. Lu, S. Cheng, B. Si, and X. Feng, “Learning cognitive map representations for navigation by sensory–motor integra- tion,”IEEE Transactions on Cybernetics, vol. 52, no. 1, pp. 508–521, 2020
2020
-
[18]
NavRep: Unsuper- vised representations for reinforcement learning of robot navigation in dynamic human environments,
D. Dugas, J. Nieto, R. Siegwart, and J. J. Chung, “NavRep: Unsuper- vised representations for reinforcement learning of robot navigation in dynamic human environments,” in2021 IEEE international conference on robotics and automation (ICRA). IEEE, 2021, pp. 7829–7835
2021
-
[19]
Goal-oriented robot navigation learning using a multi- scale space representation,
M. Llofriu, G. Tejera, M. Contreras, T. Pelc, J.-M. Fellous, and A. Weitzenfeld, “Goal-oriented robot navigation learning using a multi- scale space representation,”Neural Networks, vol. 72, pp. 62–74, 2015
2015
-
[20]
State representation learning for control: An overview,
T. Lesort, N. D ´ıaz-Rodr´ıguez, J.-F. Goudou, and D. Filliat, “State representation learning for control: An overview,”Neural Networks, vol. 108, pp. 379–392, 2018
2018
-
[21]
A survey of object goal navigation,
J. Sun, J. Wu, Z. Ji, and Y .-K. Lai, “A survey of object goal navigation,” IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 2292–2308, 2024
2024
-
[22]
Representation learning: A review and new perspectives,
Y . Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,”IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 8, pp. 1798–1828, 2013
2013
-
[23]
Learning Markov state abstractions for deep reinforcement learning,
C. Allen, N. Parikh, O. Gottesman, and G. Konidaris, “Learning Markov state abstractions for deep reinforcement learning,”Advances in Neural Information Processing Systems, vol. 34, pp. 8229–8241, 2021
2021
-
[24]
A generalizing spatial representation for robot navi- gation with reinforcement learning
L. Frommberger, “A generalizing spatial representation for robot navi- gation with reinforcement learning.” inFLAIRS, 2007, pp. 586–591
2007
-
[25]
Learning state representations with robotic priors,
R. Jonschkowski and O. Brock, “Learning state representations with robotic priors,”Autonomous Robots, vol. 39, pp. 407–428, 2015
2015
-
[26]
State representation learning using robotic priors in con- tinuous action spaces for mobile robot navigation,
A. Bijman, “State representation learning using robotic priors in con- tinuous action spaces for mobile robot navigation,” Master’s thesis, University of Twente, 2020
2020
-
[27]
Learning a state representation and navigation in cluttered and dynamic environ- ments,
D. Hoeller, L. Wellhausen, F. Farshidian, and M. Hutter, “Learning a state representation and navigation in cluttered and dynamic environ- ments,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 5081– 5088, 2021
2021
-
[28]
Monocular vision guided deep reinforce- ment learning UA V systems with representation learning perception,
Z. Xue and T. Gonsalves, “Monocular vision guided deep reinforce- ment learning UA V systems with representation learning perception,” Connection Science, vol. 35, no. 1, p. 2183828, 2023
2023
-
[29]
Representation enhancement- based proximal policy optimization for UA V path planning and obstacle avoidance,
X. Huang, W. Wang, Z. Ji, and B. Cheng, “Representation enhancement- based proximal policy optimization for UA V path planning and obstacle avoidance,”International Journal of Aerospace Engineering, vol. 2023, no. 1, p. 6654130, 2023
2023
-
[30]
Transferable representation learning in vision-and-language navigation,
H. Huang, V . Jain, H. Mehta, A. Ku, G. Magalhaes, J. Baldridge, and E. Ie, “Transferable representation learning in vision-and-language navigation,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 7404–7413
2019
-
[31]
Learning visuomotor policies for aerial navigation using cross-modal representa- tions,
R. Bonatti, R. Madaan, V . Vineet, S. Scherer, and A. Kapoor, “Learning visuomotor policies for aerial navigation using cross-modal representa- tions,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 1637–1644
2020
-
[32]
Representation learning for event-based visuomotor policies,
S. Vemprala, S. Mian, and A. Kapoor, “Representation learning for event-based visuomotor policies,”Advances in Neural Information Pro- cessing Systems, vol. 34, pp. 4712–4724, 2021
2021
-
[33]
Understanding self-predictive learning for reinforcement learning,
Y . Tang, Z. D. Guo, P. H. Richemond, B. A. Pires, Y . Chandak, R. Munos, M. Rowland, M. G. Azar, C. Le Lan, C. Lyleet al., “Understanding self-predictive learning for reinforcement learning,” in International Conference on Machine Learning. PMLR, 2023, pp. 33 632–33 656
2023
-
[34]
Enhancing reinforcement learning via transformer-based state predictive representations,
M. Liu, Y . Zhu, Y . Chen, and D. Zhao, “Enhancing reinforcement learning via transformer-based state predictive representations,”IEEE Transactions on Artificial Intelligence, vol. 5, no. 9, pp. 4364–4375, 2024
2024
-
[35]
Q-learning,
C. J. Watkins and P. Dayan, “Q-learning,”Machine learning, vol. 8, pp. 279–292, 1992
1992
-
[36]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[37]
Addressing function approxi- mation error in actor-critic methods,
S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approxi- mation error in actor-critic methods,” inInternational conference on machine learning. PMLR, 2018, pp. 1587–1596
2018
-
[38]
Soft Actor-Critic Algorithms and Applications
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V . Ku- mar, H. Zhu, A. Gupta, P. Abbeelet al., “Soft actor-critic algorithms and applications,”arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review arXiv 2018
-
[39]
Self-supervised representation learning: Introduction, advances, and challenges,
L. Ericsson, H. Gouk, C. C. Loy, and T. M. Hospedales, “Self-supervised representation learning: Introduction, advances, and challenges,”IEEE Signal Processing Magazine, vol. 39, no. 3, pp. 42–62, 2022
2022
-
[40]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Self-supervised representation learning with relative predictive coding,
Y .-H. H. Tsai, M. Q. Ma, M. Yang, H. Zhao, L.-P. Morency, and R. Salakhutdinov, “Self-supervised representation learning with relative predictive coding,”arXiv preprint arXiv:2103.11275, 2021
-
[42]
Bootstrap your own latent-a new approach to self-supervised learning,
J.-B. Grill, F. Strub, F. Altch ´e, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azaret al., “Bootstrap your own latent-a new approach to self-supervised learning,” Advances in neural information processing systems, vol. 33, pp. 21 271– 21 284, 2020
2020
-
[43]
Decoupling representation learning from reinforcement learning,
A. Stooke, K. Lee, P. Abbeel, and M. Laskin, “Decoupling representation learning from reinforcement learning,” inInternational conference on machine learning. PMLR, 2021, pp. 9870–9879
2021
-
[44]
Data-efficient reinforcement learning with self-predictive representations
M. Schwarzer, A. Anand, R. Goel, R. D. Hjelm, A. Courville, and P. Bachman, “Data-efficient reinforcement learning with self-predictive representations,”arXiv preprint arXiv:2007.05929, 2020
-
[45]
Bridging state and history representations: Under- standing self-predictive RL,
T. Ni, B. Eysenbach, E. Seyedsalehi, M. Ma, C. Gehring, A. Mahajan, and P.-L. Bacon, “Bridging state and history representations: Under- standing self-predictive RL,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[46]
La- tentSLAM: Unsupervised multi-sensor representation learning for lo- calization and mapping,
O. C ¸ atal, W. Jansen, T. Verbelen, B. Dhoedt, and J. Steckel, “La- tentSLAM: Unsupervised multi-sensor representation learning for lo- calization and mapping,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 6739–6745
2021
-
[47]
Learning visual representation for autonomous drone navigation via a contrastive world model,
J. Zhao, Y . Wang, Z. Cai, N. Liu, K. Wu, and Y . Wang, “Learning visual representation for autonomous drone navigation via a contrastive world model,”IEEE Transactions on Artificial Intelligence, vol. 5, no. 3, pp. 1263–1276, 2023
2023
-
[48]
Semantic-driven autonomous visual navigation for unmanned aerial vehicles,
P. Yue, J. Xin, Y . Zhang, Y . Lu, and M. Shan, “Semantic-driven autonomous visual navigation for unmanned aerial vehicles,”IEEE Transactions on Industrial Electronics, vol. 71, no. 11, pp. 14 853– 14 863, 2024
2024
-
[49]
Analytic formulation of the principle of increasing precision with decreasing intelligence for intelligent machines,
G. N. Saridis, “Analytic formulation of the principle of increasing precision with decreasing intelligence for intelligent machines,” inRobot Control 1988 (Syroco’88). Elsevier, 1989, pp. 529–534
1988
-
[50]
I-divergence geometry of probability distributions and min- imization problems,
I. Csisz ´ar, “I-divergence geometry of probability distributions and min- imization problems,”The annals of probability, pp. 146–158, 1975
1975
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.