Recognition: unknown
WFM: 3D Wavelet Flow Matching for Ultrafast Multi-Modal MRI Synthesis
Pith reviewed 2026-05-09 23:48 UTC · model grok-4.3
The pith
Wavelet flow matching synthesizes all BraTS MRI modalities from one model in 1-2 steps at near-diffusion quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
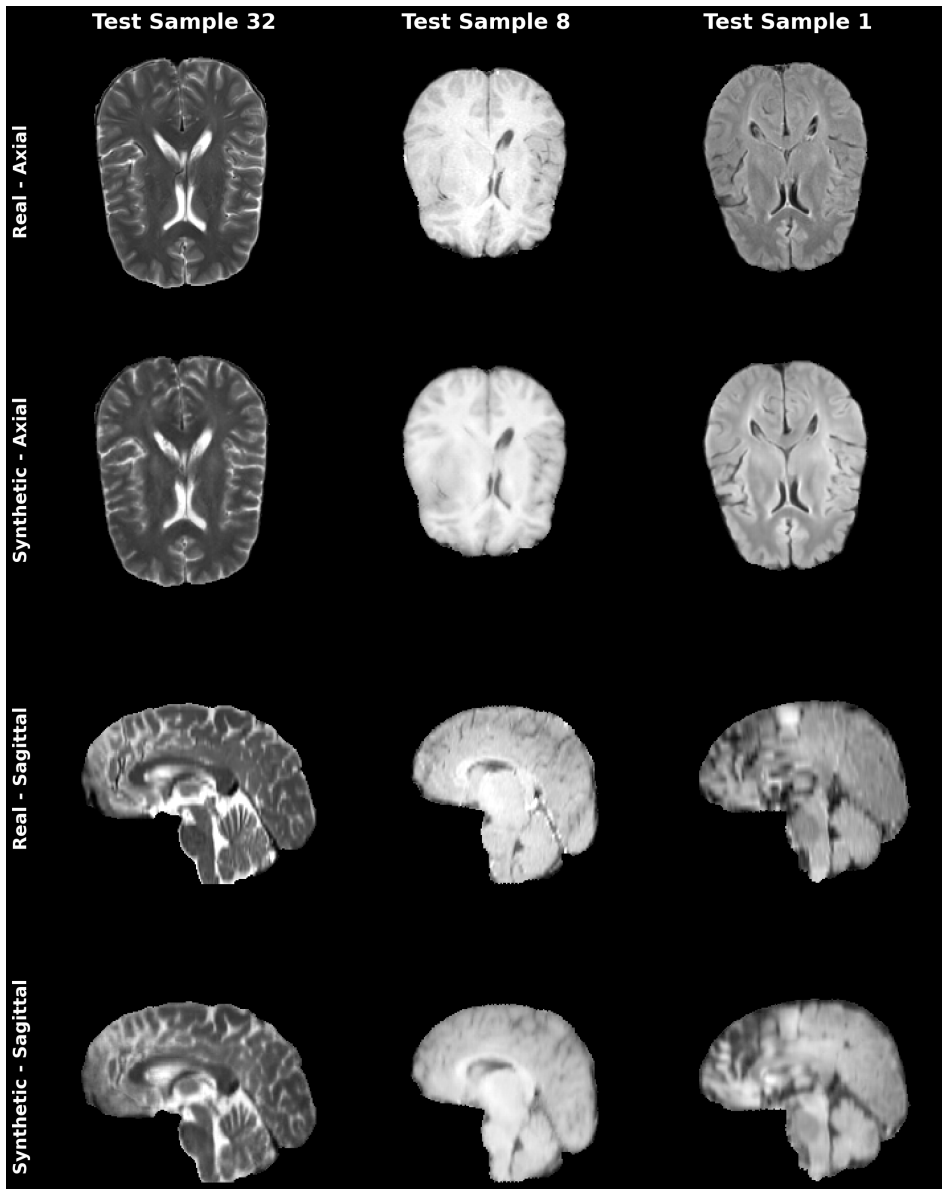
WFM learns a direct flow in 3D wavelet space from the mean of conditioning modalities to the target modality distribution; a single class-conditioned network therefore synthesizes any of the four BraTS sequences (T1, T1c, T2, FLAIR) in 1-2 steps, reaching 26.8 dB PSNR and 0.94 SSIM on BraTS 2024.
What carries the argument
3D wavelet flow matching that transports from the mean of conditioning modalities (the informed prior) to the target distribution, with class conditioning inside one network.
Load-bearing premise
The mean of the conditioning modalities in wavelet space supplies a sufficiently informed prior for accurate synthesis in only one or two integration steps.
What would settle it
Run the model on BraTS cases that omit one or more conditioning modalities or contain large contrast mismatches and measure whether PSNR and SSIM drop more than 2 dB below the diffusion baselines.
Figures



read the original abstract
Diffusion models have achieved remarkable quality in multi-modal MRI synthesis, but their computational cost (hundreds of sampling steps and separate models per modality) limits clinical deployment. We observe that this inefficiency stems from an unnecessary starting point: diffusion begins from pure noise, discarding the structural information already present in available MRI sequences. We propose WFM (Wavelet Flow Matching), which instead learns a direct flow from an informed prior, the mean of conditioning modalities in wavelet space, to the target distribution. Because the source and target share underlying anatomy and differ primarily in contrast, this formulation enables accurate synthesis in just 1-2 integration steps. A single 82M-parameter model with class conditioning synthesizes all four BraTS modalities (T1, T1c, T2, FLAIR), replacing four separate diffusion models totaling 326M parameters. On BraTS 2024, WFM achieves 26.8 dB PSNR and 0.94 SSIM, within 1-2 dB of diffusion baselines, while running 250-1000x faster (0.16-0.64s vs. 160s per volume). This speed-quality trade-off makes real-time MRI synthesis practical for clinical workflows. Code is available at https://github.com/yalcintur/WFM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WFM, a single 82M-parameter 3D wavelet flow matching model with class conditioning that synthesizes all four BraTS modalities (T1, T1c, T2, FLAIR) by flowing from the mean of available modalities in wavelet space rather than pure noise. This enables accurate synthesis in 1-2 integration steps, yielding 26.8 dB PSNR and 0.94 SSIM on BraTS 2024 (within 1-2 dB of diffusion baselines) while running 250-1000x faster (0.16-0.64 s vs. 160 s per volume). Code is released.
Significance. If the performance and speed claims are robust, the work offers a practical path to real-time multi-modal MRI synthesis by leveraging an informed wavelet prior to bypass the inefficiency of noise-based diffusion. The parameter reduction (one model vs. four) and open code are notable strengths that could influence clinical deployment and follow-on research in efficient generative models for medical imaging.
major comments (2)
- [Experiments] Experiments section: the central claim that WFM is 'within 1-2 dB of diffusion baselines' cannot be fully assessed because the manuscript provides neither error bars, the exact diffusion baseline architectures and sampling schedules, nor the precise implementation details of the 326M-parameter comparison models.
- [Methods] Methods section: the key assumption that the wavelet-space mean of conditioning modalities supplies a sufficiently informative prior for 1-2 step synthesis is stated but lacks supporting analysis (e.g., quantitative contrast difference metrics between mean prior and target or ablation on wavelet decomposition levels), which is load-bearing for the efficiency argument.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from an explicit statement of which modalities are used as conditioning versus target in each experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential practical impact of WFM. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Experiments section: the central claim that WFM is 'within 1-2 dB of diffusion baselines' cannot be fully assessed because the manuscript provides neither error bars, the exact diffusion baseline architectures and sampling schedules, nor the precise implementation details of the 326M-parameter comparison models.
Authors: We agree that error bars and explicit baseline specifications would strengthen the presentation. In the revised manuscript we will add standard deviations (computed over multiple random seeds) to the reported PSNR and SSIM values. We will also insert a concise table summarizing the diffusion baseline architectures, parameter counts, and sampling schedules (e.g., 1000-step DDPM). Because the full code and configuration files are already released, we will add explicit references to the relevant repository paths so that every implementation detail is directly traceable without requiring readers to inspect the code themselves. revision: yes
-
Referee: Methods section: the key assumption that the wavelet-space mean of conditioning modalities supplies a sufficiently informative prior for 1-2 step synthesis is stated but lacks supporting analysis (e.g., quantitative contrast difference metrics between mean prior and target or ablation on wavelet decomposition levels), which is load-bearing for the efficiency argument.
Authors: We concur that quantitative support for the informativeness of the wavelet mean prior is valuable. We will augment the methods section with dataset-wide metrics (PSNR and SSIM) comparing the wavelet-space mean prior (inverted to image space) against the target modality. We will also report an ablation on wavelet decomposition depth (2, 3, and 4 levels) showing its effect on both synthesis quality and the minimal number of integration steps required. These additions will directly substantiate why the chosen prior enables accurate 1-2 step synthesis. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper defines WFM as an independent architectural choice: replacing diffusion's pure-noise initialization with the mean of available modalities in wavelet space, then training a single class-conditioned flow-matching model to map this informed prior to the target modality distribution. This formulation and the 1-2 step integration claim follow directly from the stated modeling decision rather than reducing to any fitted parameter or self-referential definition. Performance numbers (26.8 dB PSNR, 0.94 SSIM on BraTS 2024) are obtained via standard external-benchmark evaluation after training, with no load-bearing self-citations, uniqueness theorems, or renamings of prior results invoked to justify the core method. The central assumption that the wavelet-space mean supplies a sufficiently informative prior is presented explicitly as the source of the efficiency gain and is not smuggled in via citation or construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ujjwal Baid, Satyam Ghodasara, Suyash Mohan, Michel Bilello, Evan Calabrese, Errol Co- lak, Keyvan Farahani, Jayashree Kalpathy-Cramer, Felipe C Kitamura, Sarthak Pati, et al. The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification.arXiv preprint arXiv:2107.02314, 2021
work page internal anchor Pith review arXiv 2021
-
[2]
Lbm: Latent bridge matching for fast image-to-image translation
Clément Chadebec, Onur Tasar, Sanjeev Sreetharan, and Benjamin Aubin. Lbm: Latent bridge matching for fast image-to-image translation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 29086–29098, October 2025
2025
-
[3]
Controllable flow matching for 3d contrast-enhanced brain mri synthesis from non-contrast scans
Heng Chang, Yu Shang, Haifeng Wang, Yuxia Liang, Haoyu Wang, Fan Wang, Chen Niu, and Chunfeng Lian. Controllable flow matching for 3d contrast-enhanced brain mri synthesis from non-contrast scans. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2025: 28th International Conference, Daejeon, South Korea, September 23–27, 2025, Proceedi...
-
[4]
Agisilaos Chartsias, Thomas Joyce, Mario Valerio Giuffrida, and Sotirios A. Tsaftaris. Multi- modal mr synthesis via modality-invariant latent representation.IEEE Transactions on Medical Imaging, 37(3):803–814, 2018. doi: 10.1109/TMI.2017.2764326
-
[5]
Resvit: Residual vision transformers for multimodal medical image synthesis.IEEE Transactions on Medical Imaging, 41(10):2598– 2614, 2022
Onat Dalmaz, Mahmut Yurt, and Tolga Çukur. Resvit: Residual vision transformers for multimodal medical image synthesis.IEEE Transactions on Medical Imaging, 41(10):2598– 2614, 2022
2022
- [6]
-
[7]
Wdm: 3d wavelet diffusion models for high-resolution medical image synthesis
Paul Friedrich, Julia Wolleb, Florentin Bieder, Alicia Durrer, and Philippe C Cattin. Wdm: 3d wavelet diffusion models for high-resolution medical image synthesis. InMICCAI Workshop on Deep Generative Models, pages 11–21. Springer, 2024
2024
-
[8]
Image-to-image translation with conditional adversarial networks.CVPR, 2017
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks.CVPR, 2017
2017
-
[9]
Adaptive latent diffusion model for 3d medical image to image translation: Multi-modal magnetic resonance imaging study
Jonghun Kim and Hyunjin Park. Adaptive latent diffusion model for 3d medical image to image translation: Multi-modal magnetic resonance imaging study. InProceedings of the IEEE/CVF Winter conference on applications of computer Vision, pages 7604–7613, 2024. 10
2024
-
[10]
Bbdm: Image-to-imagetranslationwithbrownian bridge diffusion models
BoLi, KaitaoXue, BinLiu, andYu-KunLai. Bbdm: Image-to-imagetranslationwithbrownian bridge diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1952–1961, June 2023
1952
-
[11]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
I2SB: Image-to-image Schrödinger bridge.arXiv preprint arXiv:2302.05872,
Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A Theodorou, Weili Nie, and Anima Anandkumar. I 2SB: Image-to-image Schrödinger bridge.arXiv preprint arXiv:2302.05872, 2023
-
[13]
Unsupervised medical image translation with adversarial diffusion models
Muzaffer Özbey, Onat Dalmaz, Salman UH Dar, Hasan A Bedel, Şaban Özturk, Alper Güngör, and Tolga Cukur. Unsupervised medical image translation with adversarial diffusion models. IEEE Transactions on Medical Imaging, 42(12):3524–3539, 2023
2023
-
[14]
Wavelet diffusion models are fast and scalable image generators
Hao Phung, Quan Dao, and Anh Tran. Wavelet diffusion models are fast and scalable image generators. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10199–10208, June 2023
2023
-
[15]
Muhammad Muneeb Saad, Ruairi O’Reilly, and Mubashir Husain Rehmani. A survey on training challenges in generative adversarial networks for biomedical image analysis.Artificial Intelligence Review, 57(2):19, Jan 2024. ISSN 1573-7462. doi: 10.1007/s10462-023-10624-y. URLhttps://doi.org/10.1007/s10462-023-10624-y
-
[16]
Progressive distillation for fast sampling of diffusion models,
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models,
-
[17]
URLhttps://arxiv.org/abs/2202.00512
work page internal anchor Pith review arXiv
-
[18]
Diffusion schrödinger bridge matching.Advances in Neural Information Processing Systems, 36:62183–62223, 2023
Yuyang Shi, Valentin De Bortoli, Andrew Campbell, and Arnaud Doucet. Diffusion schrödinger bridge matching.Advances in Neural Information Processing Systems, 36:62183–62223, 2023
2023
-
[19]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[20]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InInter- national Conference on Machine Learning, pages 32211–32252, 2023
2023
-
[21]
Towards general text-guided image synthesis for customized multimodal brain mri generation, 2024
Yulin Wang, Honglin Xiong, Kaicong Sun, Shuwei Bai, Ling Dai, Zhongxiang Ding, Jiameng Liu, Qian Wang, Qian Liu, and Dinggang Shen. Towards general text-guided image synthesis for customized multimodal brain mri generation, 2024. URLhttps://arxiv.org/abs/2409. 16818
2024
-
[22]
Unpaired image-to-image translation using cycle-consistent adversarial networkss
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networkss. InComputer Vision (ICCV), 2017 IEEE International Conference on, 2017
2017
-
[23]
Lianrui Zuo, Yihao Liu, Yuan Xue, Blake E. Dewey, Samuel W. Remedios, Savannah P. Hays, Murat Bilgel, Ellen M. Mowry, Scott D. Newsome, Peter A. Calabresi, Susan M. Resnick, Jerry L. Prince, and Aaron Carass. Haca3: A unified approach for multi-site mr image harmonization.Computerized Medical Imaging and Graphics, 109:102285, 2023. ISSN 0895-6111. doi: ht...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.