Recognition: unknown
Reinforcing 3D Understanding in Point-VLMs via Geometric Reward Credit Assignment
Pith reviewed 2026-05-09 22:56 UTC · model grok-4.3
The pith
Disentangling rewards in reinforcement learning fixes geometric hallucinations in Point-Vision-Language Models by aligning 3D predictions with 2D observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
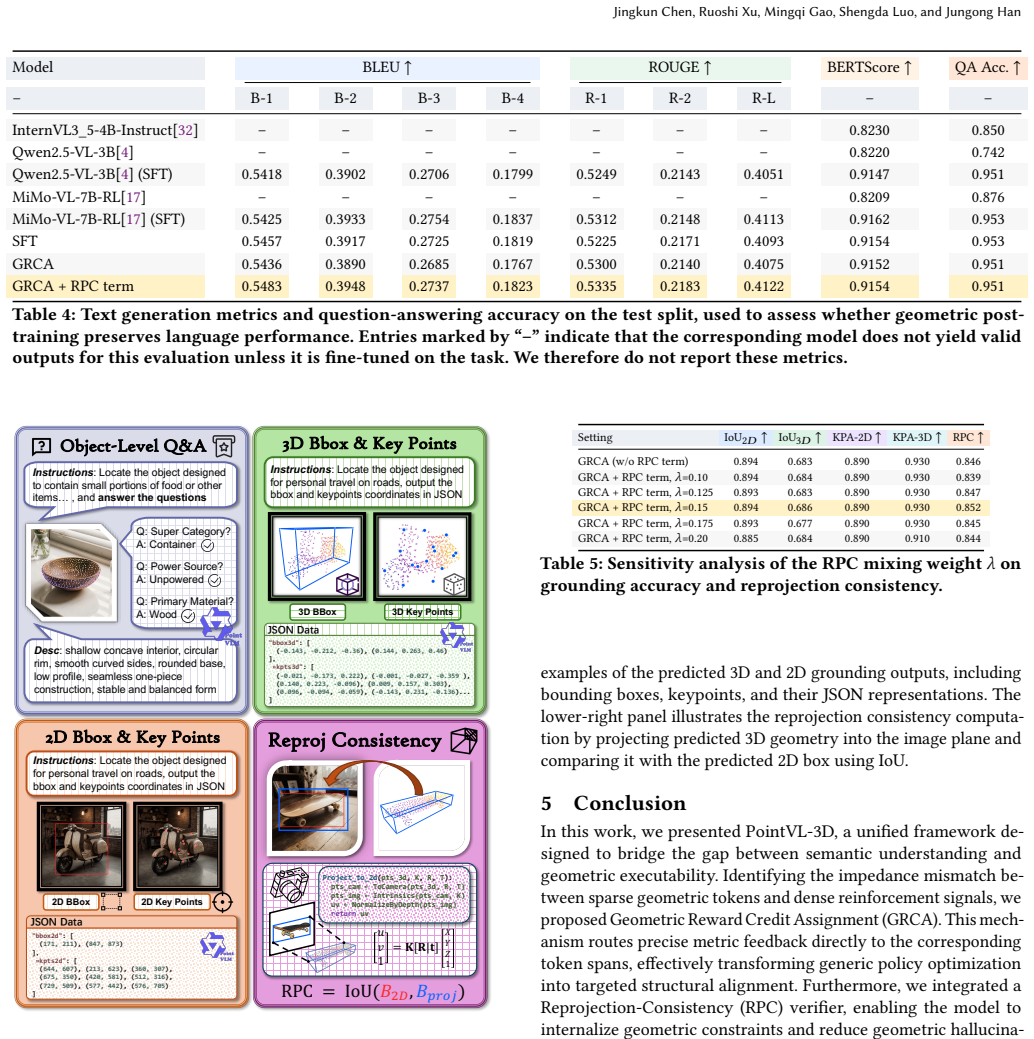
The paper establishes that geometric hallucination arises from structural misalignment in sequence-level RL rewards, where sparse geometric tokens receive diluted feedback. Geometric Reward Credit Assignment disentangles holistic supervision into field-specific signals routed to responsible token spans, converting vague feedback into precise gradient updates for targeted structural alignment. A Reprojection-Consistency term internalizes physical constraints as a cross-modal verifier to penalize impossible geometries. On a ShapeNetCore-derived benchmark, this raises 3D keypoint accuracy from 0.64 to 0.93, 3D bounding box IoU to 0.686, and reprojection consistency to 0.852, without degrading 2
What carries the argument
Geometric Reward Credit Assignment, a framework that disentangles sequence-level rewards into targeted signals for geometric tokens and incorporates reprojection consistency to enforce physical plausibility.
Load-bearing premise
That the primary cause of geometric hallucination is misalignment in how rewards are distributed across the output sequence rather than fundamental shortcomings in the model's ability to process point cloud or 3D data.
What would settle it
Training a Point-VLM with the proposed Geometric Reward Credit Assignment and Reprojection-Consistency on the ShapeNetCore benchmark and observing no improvement in 3D KPA or reprojection scores compared to the baseline would falsify the claim.
Figures


read the original abstract
Point-Vision-Language Models promise to empower embodied agents with executable spatial reasoning, yet they frequently succumb to geometric hallucination where predicted 3D structures contradict the observed 2D reality. We identify a key cause of this failure not as a representation bottleneck but as a structural misalignment in reinforcement learning, where sparse geometric tokens are drowned out by noisy and broadcasted sequence-level rewards. To resolve this causal dilution, we propose Geometric Reward Credit Assignment, a framework that disentangles holistic supervision into field-specific signals and routes them exclusively to their responsible token spans. This mechanism transforms vague feedback into precise gradient updates and effectively turns generic policy optimization into targeted structural alignment. Furthermore, we internalize physical constraints via a Reprojection-Consistency term which serves as a cross-modal verifier to penalize physically impossible geometries. Validated on a calibrated benchmark derived from ShapeNetCore, our approach bridges the reliability gap by boosting 3D KPA from 0.64 to 0.93, increasing 3D bounding box intersection over union to 0.686, and raising reprojection consistency scores to 0.852. Crucially, these gains are achieved while maintaining robust 2D localization performance, marking a meaningful step from plausible textual outputs toward physically verifiable spatial predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that geometric hallucination in Point-Vision-Language Models arises primarily from structural misalignment in sequence-level RL rewards rather than representation limits. It introduces Geometric Reward Credit Assignment to disentangle holistic supervision into field-specific signals routed to responsible token spans, combined with a Reprojection-Consistency term as a cross-modal verifier for physical constraints. On a calibrated benchmark derived from ShapeNetCore, the method reportedly raises 3D KPA from 0.64 to 0.93, 3D bounding-box IoU to 0.686, and reprojection consistency to 0.852 while preserving 2D localization performance.
Significance. If the central mechanism and gains hold under controlled evaluation, the work offers a targeted way to convert generic policy optimization into structural alignment for 3D spatial reasoning in VLMs, which could benefit embodied agents. The explicit separation of reward fields and internalization of reprojection constraints represent a concrete step beyond sequence-level RL. The reported maintenance of 2D performance alongside 3D gains is a positive signal of non-destructive specialization.
major comments (3)
- Experimental Results (or equivalent section reporting the 0.64-to-0.93 KPA jump): no ablation isolates the contribution of Geometric Reward Credit Assignment from the Reprojection-Consistency term, hyper-parameter changes, or benchmark construction. The central claim that disentangling rewards (rather than the added consistency loss) drives the gains therefore lacks direct supporting evidence; a controlled comparison (e.g., full RL + reprojection only) is required to substantiate the causal attribution.
- Benchmark and Evaluation Protocol: the abstract states validation on a 'calibrated benchmark derived from ShapeNetCore' but provides no details on data splits, hyper-parameter tuning procedure, baseline implementations, error bars, or statistical significance tests for the reported metrics (KPA, IoU 0.686, reprojection 0.852). This omission makes it impossible to assess whether the improvements are robust or partly circular.
- Method description of credit assignment: the claim that sparse geometric tokens are 'drowned out by noisy and broadcasted sequence-level rewards' is load-bearing for the proposed solution, yet the manuscript does not quantify the degree of dilution or demonstrate that the disentangling step produces measurably more precise gradients than standard RL baselines.
minor comments (2)
- Notation for the reward disentanglement and reprojection term should be introduced with explicit equations and variable definitions in the Methods section to improve reproducibility.
- Figure captions and axis labels for any qualitative 3D visualizations should explicitly state the input point cloud, predicted geometry, and ground-truth comparison.
Simulated Author's Rebuttal
Thank you for the constructive feedback and the recommendation for major revision. We appreciate the referee's focus on strengthening the empirical support and transparency of our claims regarding Geometric Reward Credit Assignment. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: Experimental Results (or equivalent section reporting the 0.64-to-0.93 KPA jump): no ablation isolates the contribution of Geometric Reward Credit Assignment from the Reprojection-Consistency term, hyper-parameter changes, or benchmark construction. The central claim that disentangling rewards (rather than the added consistency loss) drives the gains therefore lacks direct supporting evidence; a controlled comparison (e.g., full RL + reprojection only) is required to substantiate the causal attribution.
Authors: We agree that the current manuscript does not include an ablation that isolates Geometric Reward Credit Assignment from the Reprojection-Consistency term. The reported gains reflect the full method, and without this separation the causal role of the credit assignment mechanism is not directly evidenced. In the revised version we will add a controlled ablation study that includes a baseline using full RL plus the reprojection consistency term but without the geometric credit assignment routing. This will allow direct comparison of the incremental contribution of the disentangling step. revision: yes
-
Referee: Benchmark and Evaluation Protocol: the abstract states validation on a 'calibrated benchmark derived from ShapeNetCore' but provides no details on data splits, hyper-parameter tuning procedure, baseline implementations, error bars, or statistical significance tests for the reported metrics (KPA, IoU 0.686, reprojection 0.852). This omission makes it impossible to assess whether the improvements are robust or partly circular.
Authors: We acknowledge that the submitted manuscript omits these protocol details. To address the concern, the revised experimental section will specify the exact data splits from ShapeNetCore, the hyper-parameter search and selection procedure, the implementation details for all baselines, and will report standard error bars together with statistical significance tests (e.g., paired t-tests) for the key metrics. These additions will make the evaluation fully transparent and reproducible. revision: yes
-
Referee: Method description of credit assignment: the claim that sparse geometric tokens are 'drowned out by noisy and broadcasted sequence-level rewards' is load-bearing for the proposed solution, yet the manuscript does not quantify the degree of dilution or demonstrate that the disentangling step produces measurably more precise gradients than standard RL baselines.
Authors: The manuscript presents the dilution effect conceptually as the motivation for credit assignment and supports it indirectly through the observed 3D metric improvements. However, we recognize that the absence of explicit quantification (e.g., reward attribution ratios or gradient statistics) leaves the claim without direct measurement. In the revision we will add an analysis that quantifies the dilution under standard sequence-level RL and compares gradient precision (norms and variance) before versus after the disentangling operation to provide the requested empirical demonstration. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes Geometric Reward Credit Assignment to address reward misalignment in RL for Point-VLMs and adds a Reprojection-Consistency term, then reports empirical gains on a ShapeNetCore-derived benchmark. No equations, self-citations, or fitted parameters are shown in the provided text that reduce the claimed improvements (e.g., 3D KPA from 0.64 to 0.93) to the inputs by construction; the central premise is presented as an independent identification of cause and mechanism rather than a renaming or self-referential fit. The validation remains an external empirical check without load-bearing self-citation chains or ansatzes imported from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas. 2020. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. InEuropean conference on computer vision. Springer, 422–440
2020
-
[2]
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. 2022. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19129–19139
2022
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qix- ing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. 2015. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012(2015)
work page internal anchor Pith review arXiv 2015
-
[6]
Dave Zhenyu Chen, Angel X Chang, and Matthias Nießner. 2020. Scanrefer: 3d object localization in rgb-d scans using natural language. InEuropean conference on computer vision. Springer, 202–221
2020
-
[7]
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. 2024. Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 26428–26438
2024
- [8]
- [9]
- [10]
-
[11]
Ziyu Guo, Renrui Zhang, Xiangyang Zhu, Yiwen Tang, Xianzheng Ma, Jiaming Han, Kexin Chen, Peng Gao, Xianzhi Li, Hongsheng Li, et al. 2023. Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following.arXiv preprint arXiv:2309.00615(2023)
-
[12]
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 2023. 3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems36 (2023), 20482– 20494
2023
-
[13]
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al . 2024. Chat-scene: Bridging 3d scene and large language models with object identifiers.Advances in Neural Information Processing Systems37 (2024), 113991–114017
2024
- [14]
-
[15]
Baoxiong Jia, Yixin Chen, Huangyue Yu, Yan Wang, Xuesong Niu, Tengyu Liu, Qing Li, and Siyuan Huang. 2024. Sceneverse: Scaling 3d vision-language learning for grounded scene understanding. InEuropean Conference on Computer Vision. Springer, 289–310
2024
-
[16]
Sangwu Lee, Titus Ebbecke, Erwann Millon, Will Beddow, Le Zhuo, Iker García- Ferrero, Liam Esparraguera, Mihai Petrescu, Gian Sa, Gabriel Menezes, and Victor Perez. 2025. FLUX.1 Krea [dev]. https://github.com/krea-ai/flux-krea
2025
- [17]
-
[18]
Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, and Junwei Liang. 2025. See- ground: See and ground for zero-shot open-vocabulary 3d visual grounding. In Proceedings of the Computer Vision and Pattern Recognition Conference. 3707– 3717
2025
-
[19]
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. 2023. SQA3D: Situated Question Answering in 3D Scenes. In The Eleventh International Conference on Learning Representations
2023
-
[20]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[21]
Songyou Peng, Kyle Genova, Chiyu Jiang, Andrea Tagliasacchi, Marc Pollefeys, Thomas Funkhouser, et al. 2023. Openscene: 3d scene understanding with open vocabularies. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 815–824
2023
-
[22]
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. 2017. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition. 652–660
2017
-
[23]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. 2017. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems30 (2017)
2017
-
[24]
Zhangyang Qi, Ye Fang, Zeyi Sun, Xiaoyang Wu, Tong Wu, Jiaqi Wang, Dahua Lin, and Hengshuang Zhao. 2024. Gpt4point: A unified framework for point-language understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 26417–26427
2024
-
[25]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[26]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deep- speed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 3505–3506
2020
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Ayca Takmaz, Elisabetta Fedele, Robert Sumner, Marc Pollefeys, Federico Tombari, and Francis Engelmann. 2023. OpenMask3D: Open-Vocabulary 3D Instance Segmentation.Advances in Neural Information Processing Systems36 (2023), 68367–68390
2023
- [29]
-
[30]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, et al. 2024. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19757– 19767
2024
-
[32]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265(2025)
work page internal anchor Pith review arXiv 2025
- [33]
-
[34]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
work page internal anchor Pith review arXiv 2025
-
[35]
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. 2024. Point transformer v3: Simpler faster stronger. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4840–4851
2024
-
[36]
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. 2024. Deepseek- vl2: Mixture-of-experts vision-language models for advanced multimodal under- standing.arXiv preprint arXiv:2412.10302(2024)
work page internal anchor Pith review arXiv 2024
-
[37]
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. 2024. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision. Springer, 131–147
2024
-
[38]
Le Xue, Mingfei Gao, Chen Xing, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. 2023. Ulip: Learning a unified representation of language, images, and point clouds for 3d understand- ing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1179–1189
2023
-
[39]
Jianing Yang, Xuweiyi Chen, Nikhil Madaan, Madhavan Iyengar, Shengyi Qian, David F Fouhey, and Joyce Chai. 2025. 3d-grand: A million-scale dataset for 3d- llms with better grounding and less hallucination. InProceedings of the Computer Vision and Pattern Recognition Conference. 29501–29512
2025
-
[40]
Jianing Yang, Xuweiyi Chen, Shengyi Qian, Nikhil Madaan, Madhavan Iyengar, David F Fouhey, and Joyce Chai. 2024. Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent. In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 7694–7701
2024
-
[41]
Yueqin Yin, Shentao Yang, Yujia Xie, Ziyi Yang, Yuting Sun, Hany Awadalla, Weizhu Chen, and Mingyuan Zhou. 2025. Segmenting text and learning their rewards for improved rlhf in language model.arXiv preprint arXiv:2501.02790 (2025). Jingkun Chen, Ruoshi Xu, Mingqi Gao, Shengda Luo, and Jungong Han
-
[42]
Hanxun Yu, Wentong Li, Song Wang, Junbo Chen, and Jianke Zhu. 2025. Inst3d- lmm: Instance-aware 3d scene understanding with multi-modal instruction tun- ing. InProceedings of the Computer Vision and Pattern Recognition Conference. 14147–14157
2025
-
[43]
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu
-
[44]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Point-bert: Pre-training 3d point cloud transformers with masked point modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19313–19322
-
[45]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF inter- national conference on computer vision. 3836–3847
2023
-
[46]
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, and Hongsheng Li. 2022. Pointclip: Point cloud understanding by clip. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8552–8562
2022
-
[47]
Yiming Zhang, ZeMing Gong, and Angel X Chang. 2023. Multi3drefer: Grounding text description to multiple 3d objects. InProceedings of the IEEE/CVF International Conference on Computer Vision. 15225–15236
2023
-
[48]
Wenxuan Zhou, Shujian Zhang, Lingxiao Zhao, and Tao Meng. 2025. T-reg: Preference optimization with token-level reward regularization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 27876–27889
2025
-
[49]
Chenming Zhu, Tai Wang, Wenwei Zhang, Kai Chen, and Xihui Liu. 2024. Scan- reason: Empowering 3d visual grounding with reasoning capabilities. InEuropean Conference on Computer Vision. Springer, 151–168
2024
-
[50]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. 2025. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479(2025)
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.