Recognition: unknown
Refining Covariance Matrix Estimation in Stochastic Gradient Descent Through Bias Reduction
Pith reviewed 2026-05-09 20:08 UTC · model grok-4.3
The pith
A fully online de-biased covariance estimator for SGD achieves faster convergence without Hessian derivatives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
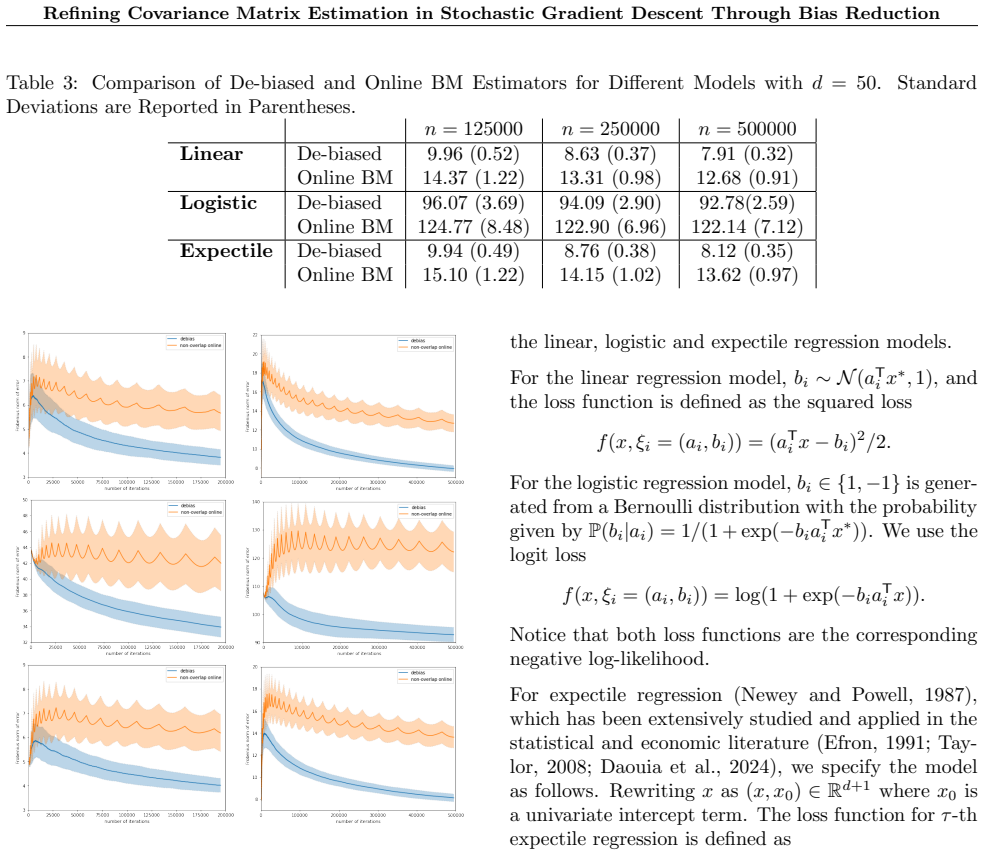
We propose a novel, fully online de-biased covariance estimator that eliminates the need for second-order derivatives while significantly improving estimation accuracy. Our method employs a bias-reduction technique to achieve a convergence rate of n^{(α-1)/2} √log n, outperforming existing Hessian-free alternatives.
What carries the argument
The bias-reduction technique applied to the online covariance estimator, which corrects accumulated bias without computing the Hessian and yields the stated convergence rate under standard SGD conditions.
If this is right
- Enables real-time construction of confidence intervals for SGD parameters without pausing for Hessian calculations.
- Improves statistical inference accuracy over both plug-in estimators that need second derivatives and slower batch-means methods.
- Preserves the streaming, single-pass nature of SGD so that covariance estimates update continuously with new observations.
- Applies directly to any first-order stochastic optimization procedure satisfying the paper's regularity conditions on step-size and noise.
Where Pith is reading between the lines
- The same bias-reduction idea could be tested on adaptive optimizers such as Adam to obtain online uncertainty estimates for their parameter trajectories.
- In high-dimensional problems the faster rate may translate into tighter confidence sets that improve downstream decisions like model selection.
- Combining the estimator with existing variance-reduction schemes for SGD could produce still higher convergence orders while remaining fully online.
- Empirical checks on streaming data from large-scale recommendation or language-model training would reveal whether the theoretical rate appears in practice.
Load-bearing premise
The bias-reduction technique can be applied fully online and delivers the improved convergence rate under standard SGD conditions without requiring inaccessible Hessian information.
What would settle it
A numerical experiment in which the estimator's mean-squared error fails to decrease at the claimed rate when the Hessian is withheld, or in which it performs no better than a batch-means estimator, would falsify the central claim.
Figures



read the original abstract
We study online inference and asymptotic covariance estimation for the stochastic gradient descent (SGD) algorithm. While classical methods (such as plug-in and batch-means estimators) are available, they either require inaccessible second-order (Hessian) information or suffer from slow convergence. To address these challenges, we propose a novel, fully online de-biased covariance estimator that eliminates the need for second-order derivatives while significantly improving estimation accuracy. Our method employs a bias-reduction technique to achieve a convergence rate of $n^{(\alpha-1)/2} \sqrt{\log n}$, outperforming existing Hessian-free alternatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a fully online, Hessian-free de-biased covariance estimator for SGD that employs a bias-reduction technique. It claims this yields a convergence rate of n^{(α-1)/2} √log n, outperforming classical plug-in and batch-means estimators that either require inaccessible Hessian information or converge slowly.
Significance. If rigorously established, the result would advance online inference for SGD by providing a practical, derivative-free covariance estimator with improved rates. This addresses a key limitation in stochastic optimization where accurate asymptotic covariance is needed for confidence intervals but second-order information is unavailable. No machine-checked proofs or reproducible code are mentioned, but a parameter-free derivation under standard assumptions would strengthen the contribution.
major comments (2)
- [Abstract] Abstract: The claimed convergence rate n^{(α-1)/2} √log n is stated without any derivation, theorem, or list of assumptions. For the standard step-size exponent α=1 (required for √n-asymptotic normality of SGD), the rate reduces to √log n, which diverges. This is a load-bearing correctness-risk for the central claim of consistency and improved accuracy under standard SGD conditions; the manuscript must either restrict the range of α, redefine the parameterization, or provide a concrete test showing the rate holds for α=1.
- [Abstract] Abstract: The bias-reduction technique is described as fully online and eliminating second-order derivatives, but no explicit construction, update rule, or bias-correction formula is visible. Without these, it is impossible to verify independence from fitted parameters or to confirm it does not implicitly rely on quantities defined by the SGD trajectory itself.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We will revise the abstract to incorporate key assumptions, a reference to the main theorem, and a concise description of the bias-reduction update rule. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claimed convergence rate n^{(α-1)/2} √log n is stated without any derivation, theorem, or list of assumptions. For the standard step-size exponent α=1 (required for √n-asymptotic normality of SGD), the rate reduces to √log n, which diverges. This is a load-bearing correctness-risk for the central claim of consistency and improved accuracy under standard SGD conditions; the manuscript must either restrict the range of α, redefine the parameterization, or provide a concrete test showing the rate holds for α=1.
Authors: The derivation of the rate, together with the full set of assumptions (strong convexity, smoothness, bounded variance, and 1/2 < α ≤ 1), appears in Theorem 3.1 and the surrounding analysis. We agree the abstract omits these details and will revise it to state the assumptions explicitly and cite the theorem. For the boundary case α = 1 we acknowledge that the rate becomes √log n; we will either restrict the primary claim in the abstract to 1/2 < α < 1 or add a clarifying remark on the α = 1 regime, where the estimator remains useful for inference despite the logarithmic factor. revision: yes
-
Referee: [Abstract] Abstract: The bias-reduction technique is described as fully online and eliminating second-order derivatives, but no explicit construction, update rule, or bias-correction formula is visible. Without these, it is impossible to verify independence from fitted parameters or to confirm it does not implicitly rely on quantities defined by the SGD trajectory itself.
Authors: The explicit recursive update rule for the de-biased estimator is given in Section 2.2; it is fully online, uses only first-order gradients and iterates, and contains no Hessian or second-order terms. The formula depends solely on quantities generated by the SGD trajectory itself and introduces no additional fitted parameters. We will revise the abstract to include a brief statement of this update rule and the bias-correction step so that the construction is visible without reference to the body. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces a bias-reduction technique for a fully online, Hessian-free covariance estimator in SGD and claims a specific convergence rate under standard conditions. No load-bearing steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the estimator is presented as independently constructed from SGD iterates without re-using the target covariance as an input. The derivation remains self-contained against external benchmarks such as classical batch-means or plug-in estimators, with the rate claim standing as a separate theoretical result rather than a tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- α
axioms (1)
- domain assumption Standard regularity conditions for SGD to possess an asymptotic normal distribution with finite covariance
Reference graph
Works this paper leans on
-
[1]
Online Covariance Estimation in Nonsmooth Stochastic Approximation , year =
Jiang, Liwei and Roy, Abhishek and Balasubramanian, Krishna and Davis, Damek and Drusvyatskiy, Dmitriy and Na, Sen , journal =. Online Covariance Estimation in Nonsmooth Stochastic Approximation , year =
-
[2]
Xi Chen and Weidong Liu and Yichen Zhang , journal =. First-Order. 2021 , month =. doi:10.1080/01621459.2021.1891925 , publisher =
-
[3]
Chen, Xi and Lee, Jason D. and Tong, Xin T. and Zhang, Yichen , journal =. Statistical inference for model parameters in stochastic gradient descent , year =. doi:10.1214/18-aos1801 , publisher =
-
[4]
Statistical inference of constrained stochastic optimization via sketched sequential quadratic programming , year =
Na, Sen and Mahoney, Michael , journal =. Statistical inference of constrained stochastic optimization via sketched sequential quadratic programming , year =
-
[5]
Bernoulli , volume=
Berry--Esseen bounds for multivariate nonlinear statistics with applications to M-estimators and stochastic gradient descent algorithms , author=. Bernoulli , volume=. 2022 , publisher=
2022
-
[6]
Gaussian Approximation and Multiplier Bootstrap for Stochastic Gradient Descent
Gaussian approximation and multiplier bootstrap for stochastic gradient descent , author=. arXiv preprint arXiv:2502.06719 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Gaussian Approximation and Concentration of Constant Learning-Rate Stochastic Gradient Descent , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[8]
The 29th International Conference on Artificial Intelligence and Statistics , year=
General Weighted Averaging in Stochastic Gradient Descent: CLT and Adaptive Optimality , author=. The 29th International Conference on Artificial Intelligence and Statistics , year=
-
[9]
SIAM Journal on optimization , volume=
Robust stochastic approximation approach to stochastic programming , author=. SIAM Journal on optimization , volume=. 2009 , publisher=
2009
-
[10]
A simpler approach to obtaining an
Lacoste-Julien, Simon and Schmidt, Mark and Bach, Francis , note =. A simpler approach to obtaining an
-
[11]
SIAM review , volume=
Optimization methods for large-scale machine learning , author=. SIAM review , volume=. 2018 , publisher=
2018
-
[12]
Journal of the American Statistical Association , volume=
Online covariance matrix estimation in stochastic gradient descent , author=. Journal of the American Statistical Association , volume=. 2023 , publisher=
2023
-
[13]
Journal of the American Statistical Association , volume=
Statistical inference for online decision making via stochastic gradient descent , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
2021
-
[14]
SIAM Journal of Control Optimization , volume=
Acceleration of stochastic approximation by averaging , author=. SIAM Journal of Control Optimization , volume=. 1992 , publisher=
1992
-
[15]
arXiv preprint arXiv:2401.09346 , year=
High Confidence Level Inference is Almost Free using Parallel Stochastic Optimization , author=. arXiv preprint arXiv:2401.09346 , year=
-
[16]
Conference on Learning Theory , pages=
Root-sgd: Sharp nonasymptotics and asymptotic efficiency in a single algorithm , author=. Conference on Learning Theory , pages=. 2022 , organization=
2022
-
[17]
Asymptotic convergence rate and statistical inference for stochastic sequential quadratic programming , author=. arXiv: 2205.13687 v1 , year=
-
[18]
Management Science , volume=
Strong consistency and other properties of the spectral variance estimator , author=. Management Science , volume=. 1991 , publisher=
1991
-
[19]
Statistical science , pages=
Practical markov chain monte carlo , author=. Statistical science , pages=. 1992 , publisher=
1992
-
[20]
Mathematics of Operations Research , volume=
Simulation output analysis using standardized time series , author=. Mathematics of Operations Research , volume=. 1990 , publisher=
1990
-
[21]
Operations Research Letters , volume=
Estimating the asymptotic variance with batch means , author=. Operations Research Letters , volume=. 1991 , publisher=
1991
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Statistical inference using SGD , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
Journal of Machine Learning Research , volume=
Online bootstrap confidence intervals for the stochastic gradient descent estimator , author=. Journal of Machine Learning Research , volume=
-
[24]
Journal of Machine Learning Research , volume=
Higrad: Uncertainty quantification for online learning and stochastic approximation , author=. Journal of Machine Learning Research , volume=
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Fast and robust online inference with stochastic gradient descent via random scaling , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[26]
arXiv preprint arXiv:2212.01259 , year=
Covariance estimators for the root-sgd algorithm in online learning , author=. arXiv preprint arXiv:2212.01259 , year=
-
[27]
The Annals of Applied Probability , number =
Wei Biao Wu , title =. The Annals of Applied Probability , number =. 2009 , doi =
2009
-
[28]
Econometrica: Journal of the Econometric Society , pages=
Asymmetric least squares estimation and testing , author=. Econometrica: Journal of the Econometric Society , pages=. 1987 , publisher=
1987
-
[29]
Statistica Sinica , pages=
Regression percentiles using asymmetric squared error loss , author=. Statistica Sinica , pages=. 1991 , publisher=
1991
-
[30]
Journal of Financial Econometrics , volume=
Estimating value at risk and expected shortfall using expectiles , author=. Journal of Financial Econometrics , volume=. 2008 , publisher=
2008
-
[31]
Airoldi , title =
Panos Toulis and Edoardo M. Airoldi , title =. The Annals of Statistics , number =. 2017 , doi =
2017
-
[32]
The annals of mathematical statistics , pages=
A stochastic approximation method , author=. The annals of mathematical statistics , pages=. 1951 , volume=
1951
-
[33]
International conference on machine learning , pages=
Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging schemes , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[34]
IEEE Transactions on Automatic Control , volume=
Finite-time analysis of markov gradient descent , author=. IEEE Transactions on Automatic Control , volume=. 2022 , publisher=
2022
-
[35]
Econometric Theory , volume=
Asymptotics of spectral density estimates , author=. Econometric Theory , volume=. 2010 , publisher=
2010
-
[36]
Flegal and Galin L
James M. Flegal and Galin L. Jones , title =. The Annals of Statistics , number =. 2010 , doi =
2010
-
[37]
IEEE transactions on information theory , volume=
A single-pass algorithm for spectrum estimation with fast convergence , author=. IEEE transactions on information theory , volume=. 2011 , publisher=
2011
-
[38]
The Annals of Statistics , number =
Han Xiao and Wei Biao Wu , title =. The Annals of Statistics , number =. 2012 , doi =
2012
-
[39]
The Annals of Statistics , number =
Xiaohui Chen and Mengyu Xu and Wei Biao Wu , title =. The Annals of Statistics , number =. 2013 , doi =
2013
-
[40]
IEEE Transactions on Information Theory , volume=
Asymptotic theory for estimators of high-order statistics of stationary processes , author=. IEEE Transactions on Information Theory , volume=. 2017 , publisher=
2017
-
[41]
Online Covariance Matrix Estimation in Sketched Newton Methods
Online Covariance Matrix Estimation in Sketched Newton Methods , author=. arXiv preprint arXiv:2502.07114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Statistics and Computing , volume=
An expectile computation cookbook , author=. Statistics and Computing , volume=. 2024 , publisher=
2024
-
[43]
Statistics & Probability Letters , volume=
Expectiles and M-quantiles are quantiles , author=. Statistics & Probability Letters , volume=. 1994 , publisher=
1994
-
[44]
Rio, Emmanuel , journal =. Moment
-
[45]
arXiv preprint arXiv:2306.02205 , year=
Online bootstrap inference with nonconvex stochastic gradient descent estimator , author=. arXiv preprint arXiv:2306.02205 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.