Recognition: unknown
When Agents Look the Same: Quantifying Distillation-Induced Similarity in Tool-Use Behaviors
Pith reviewed 2026-05-09 22:04 UTC · model grok-4.3
The pith
Distillation causes LLM agents to converge on similar tool-use behaviors beyond what tasks require.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
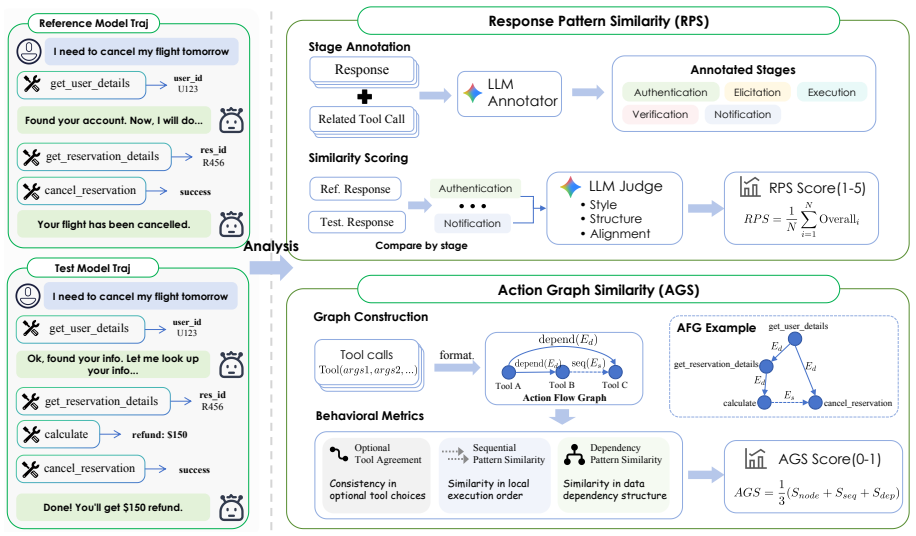
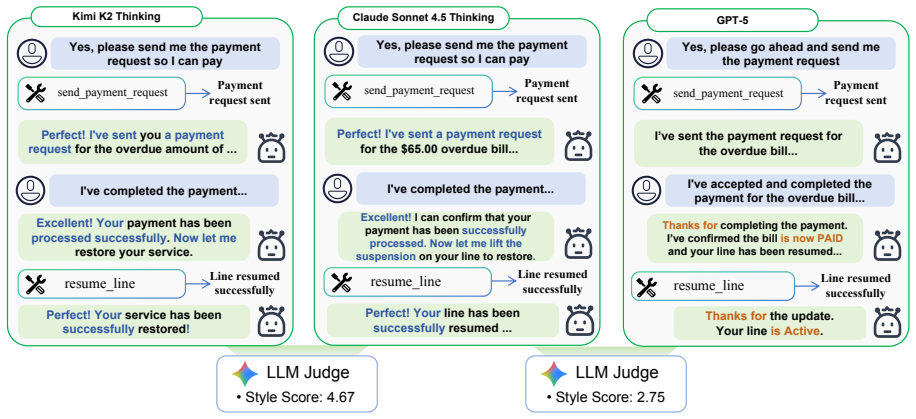
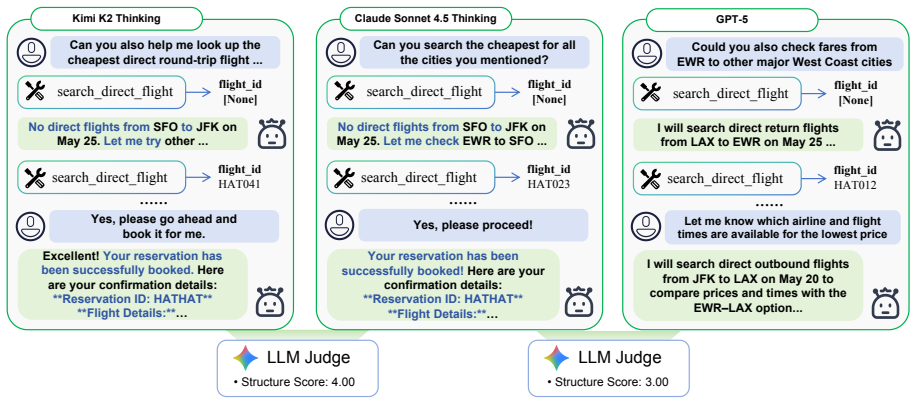
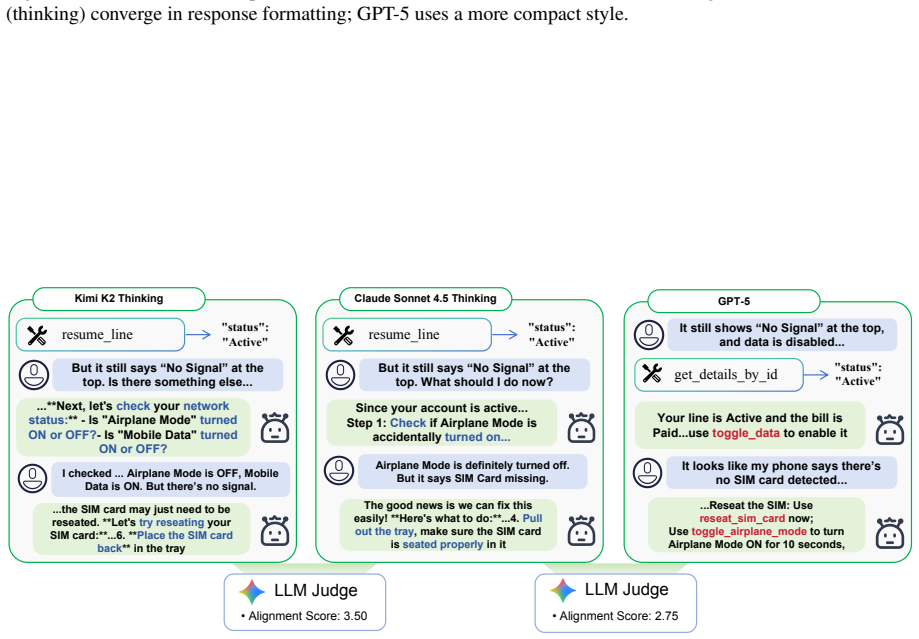
Model distillation drives rapid progress in LLM agents but produces behavioral homogenization in which many agents echo the reasoning steps and failure modes of a few dominant teachers. Two complementary metrics isolate non-mandatory patterns: Response Pattern Similarity for verbal alignment and Action Graph Similarity for tool-use habits modeled as directed graphs. On evaluations against Claude Sonnet 4.5, within-family model pairs score 5.9 pp higher in AGS than cross-family pairs; Kimi-K2 reaches 82.6% node similarity and 94.7% dependency similarity, exceeding Anthropic's own Opus 4.1. A controlled distillation experiment shows AGS distinguishes teacher-specific convergence from general 1
What carries the argument
Action Graph Similarity (AGS), which models sequences of tool calls as directed graphs and measures overlap in chosen actions and their ordering dependencies to isolate autonomous tool-use habits.
If this is right
- Agents distilled from the same teacher or belonging to the same provider family will exhibit measurably higher AGS scores on tool-use tasks.
- AGS can separate the effects of teacher-specific behavioral copying from broad performance improvements in distillation experiments.
- RPS and AGS supply complementary diagnostic signals because they correlate only moderately (Pearson r = 0.491).
- These metrics enable systematic monitoring of homogenization across the growing population of LLM agents.
Where Pith is reading between the lines
- If AGS reliably flags preference convergence, developers could use it during training to penalize excessive copying and preserve behavioral diversity for better robustness on novel tasks.
- The graph-based approach could extend to detecting convergence in other agent skills such as planning depth or multi-agent coordination.
- Shared high-similarity failure modes across many agents could create common vulnerabilities exploitable by a single adversarial input.
Load-bearing premise
The chosen benchmarks contain enough distinct valid solution paths that high similarity in tool choices and sequences can be treated as reflecting preferences rather than necessities for task success.
What would settle it
If unrelated models from different families achieve AGS scores comparable to within-family pairs when evaluated on tasks that admit multiple clearly distinct valid tool sequences, the claim that AGS isolates non-mandatory patterns would be falsified.
Figures


read the original abstract
Model distillation is a primary driver behind the rapid progress of LLM agents, yet it often leads to behavioral homogenization. Many emerging agents share nearly identical reasoning steps and failure modes, suggesting they may be distilled echoes of a few dominant teachers. Existing metrics, however, fail to distinguish mandatory behaviors required for task success from non-mandatory patterns that reflect a model's autonomous preferences. We propose two complementary metrics to isolate non-mandatory behavioral patterns: \textbf{Response Pattern Similarity (RPS)} for verbal alignment and \textbf{Action Graph Similarity (AGS)} for tool-use habits modeled as directed graphs. Evaluating 18 models from 8 providers on $\tau$-Bench and $\tau^2$-Bench against Claude Sonnet 4.5 (thinking), we find that within-family model pairs score 5.9 pp higher in AGS than cross-family pairs, and that Kimi-K2 (thinking) reaches 82.6\% $S_{\text{node}}$ and 94.7\% $S_{\text{dep}}$, exceeding Anthropic's own Opus 4.1. A controlled distillation experiment further confirms that AGS distinguishes teacher-specific convergence from general improvement. RPS and AGS capture distinct behavioral dimensions (Pearson $r$ = 0.491), providing complementary diagnostic signals for behavioral convergence in the agent ecosystem. Our code is available at https://github.com/Syuchin/AgentEcho.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that distillation causes behavioral homogenization in LLM agents and introduces Response Pattern Similarity (RPS) for verbal alignment plus Action Graph Similarity (AGS) for tool-use habits modeled as directed graphs to isolate non-mandatory patterns. Evaluating 18 models from 8 providers on τ-Bench and τ²-Bench against Claude Sonnet 4.5 (thinking), it reports that within-family pairs score 5.9 pp higher in AGS than cross-family pairs, that Kimi-K2 (thinking) reaches 82.6% S_node and 94.7% S_dep (exceeding Opus 4.1), and that a controlled distillation experiment confirms AGS distinguishes teacher-specific convergence from general improvement. RPS and AGS are complementary (Pearson r = 0.491), with code released at https://github.com/Syuchin/AgentEcho.
Significance. If the metrics successfully separate optional teacher-specific patterns from task-required behaviors, the work supplies useful diagnostics for the agent ecosystem and highlights risks of convergence beyond raw performance. The controlled distillation experiment and public code are concrete strengths that aid reproducibility and allow direct testing of the claims.
major comments (2)
- [Methods (RPS/AGS definitions) and Abstract] The central claim that RPS and AGS isolate non-mandatory behavioral patterns (rather than behaviors required for high performance on τ-Bench / τ²-Bench) is load-bearing but lacks an explicit operationalization. No filtering rule, success-rate conditioning, or ablation is described showing that retained nodes/edges are avoidable without accuracy loss; if high AGS largely reflects dominant successful strategies, the within-family gap could indicate shared capability or data overlap instead of distillation.
- [Controlled Distillation Experiment] The controlled distillation experiment is presented as decisive evidence that AGS captures teacher-specific convergence, yet the text supplies no details on whether task distribution, optimizer, and data volume were held fixed while only the teacher traces varied. Without these controls the distinction from general capability improvement remains unverified.
minor comments (2)
- [Results] The 5.9 pp AGS difference, correlation r = 0.491, and per-model percentages should be accompanied by error bars, statistical significance tests, and exact sample sizes or number of traces per model to permit verification.
- [Methods] Exact formulas for RPS, AGS, S_node, and S_dep (including graph construction from tool-call traces and any normalization) should be stated explicitly in the main text rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments identify areas where additional clarity will strengthen the paper's claims about isolating non-mandatory behavioral patterns. We address each point below and will revise the manuscript to incorporate the requested details and operationalizations.
read point-by-point responses
-
Referee: [Methods (RPS/AGS definitions) and Abstract] The central claim that RPS and AGS isolate non-mandatory behavioral patterns (rather than behaviors required for high performance on τ-Bench / τ²-Bench) is load-bearing but lacks an explicit operationalization. No filtering rule, success-rate conditioning, or ablation is described showing that retained nodes/edges are avoidable without accuracy loss; if high AGS largely reflects dominant successful strategies, the within-family gap could indicate shared capability or data overlap instead of distillation.
Authors: We agree that an explicit operationalization is essential to support the central claim. While the manuscript motivates RPS and AGS by focusing on response structures and directed action graphs that extend beyond the minimal actions needed for task completion (e.g., optional tool sequencing and dependency patterns), we acknowledge the absence of a formal filtering rule or ablation. In the revised version we will add a new subsection in Methods that (i) defines a frequency-based filtering rule retaining only patterns appearing in at least k successful trajectories, (ii) introduces success-rate conditioning by comparing AGS/RPS on high- vs. low-accuracy subsets, and (iii) reports an ablation removing high-similarity nodes/edges and verifying that task accuracy remains statistically unchanged. These additions will directly address whether the observed within-family AGS gap reflects teacher-specific preferences rather than shared optimal strategies or data overlap. We also note that models exceeding their teachers (e.g., Kimi-K2) provide supporting evidence against a pure capability explanation, but the new analyses will make this distinction rigorous. revision: yes
-
Referee: [Controlled Distillation Experiment] The controlled distillation experiment is presented as decisive evidence that AGS captures teacher-specific convergence, yet the text supplies no details on whether task distribution, optimizer, and data volume were held fixed while only the teacher traces varied. Without these controls the distinction from general capability improvement remains unverified.
Authors: We accept that the current description is insufficiently detailed. The experiment was designed with fixed task distribution, optimizer hyperparameters, and training data volume, varying only the teacher-generated traces. In the revision we will expand the relevant section (and add a table or appendix) to explicitly document these controls, including the exact task sampling procedure, optimizer settings, and data volume per teacher. This will confirm that observed AGS differences are attributable to teacher-specific convergence rather than general capability gains. We will also report any sensitivity checks performed on these fixed parameters. revision: yes
Circularity Check
No significant circularity; metrics and validation are independently defined
full rationale
The paper introduces RPS and AGS as newly proposed metrics for isolating non-mandatory behavioral patterns, with definitions and graph modeling presented as independent of task success rates. Results are computed on external benchmarks (τ-Bench and τ²-Bench) and supported by a described controlled distillation experiment that tests teacher-specific convergence. No equations, parameter fits, or self-citations are shown to reduce the headline claims (within-family AGS gap, specific S_node/S_dep scores, or metric complementarity) to tautological inputs by construction. The derivation chain remains self-contained against the stated benchmarks and experiment.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The τ-Bench and τ²-Bench benchmarks are representative of real tool-use tasks and allow separation of mandatory from non-mandatory behaviors.
invented entities (1)
-
Action Graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gkd: Generalized knowledge distillation for auto- regressive sequence models,
GKD: generalized knowledge distilla- tion for auto-regressive sequence models.CoRR, abs/2306.13649. Anthropic. 2025a. Claude-4.1-Opus: A large lan- guage model. https://www.anthropic.com/ news/claude-opus-4-1. Accessed: January 2026. Anthropic. 2025b. Claude-4.5-Sonnet: A large language model. https://www.anthropic.com/ news/claude-sonnet-4-5 . Accessed: ...
-
[2]
InACL (Findings), pages 15094–15119
Unveiling the key factors for distilling chain- of-thought reasoning. InACL (Findings), pages 15094–15119. Association for Computational Lin- guistics. Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An open- source chatbot...
-
[3]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network. CoRR, abs/1503.02531. Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. 2023. Dis- tilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InACL (Findings), pages 8003–80...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Medagentbench: Dataset for benchmark- ing llms as agents in medical applications.CoRR, abs/2501.14654. Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. Tinybert: Distilling BERT for natural language un- derstanding. InEMNLP (Findings), volume EMNLP 2020 ofFindings of ACL, pages 4163–4174. Associ- ation ...
-
[5]
Promptkd: Distilling student-friendly knowl- edge for generative language models via prompt tun- ing. InEMNLP (Findings), pages 6266–6282. Asso- ciation for Computational Linguistics. Sunbowen Lee, Junting Zhou, Chang Ao, Kaige Li, Xeron Du, Sirui He, Haihong Wu, Tianci Liu, Jiaheng Liu, Hamid Alinejad-Rokny, Min Yang, Yitao Liang, Zhoufutu Wen, and Shiwe...
-
[6]
Ruijie Xu, Zengzhi Wang, Run-Ze Fan, and Pengfei Liu
Butterfly effects in toolchains: A compre- hensive analysis of failed parameter filling in LLM tool-agent systems.CoRR, abs/2507.15296. Ruijie Xu, Zengzhi Wang, Run-Ze Fan, and Pengfei Liu
-
[7]
Benchmarking benchmark leakage in large language models
Benchmarking benchmark leakage in large language models.CoRR, abs/2404.18824. Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. τ-bench: A benchmark for tool- agent-user interaction in real-world domains.CoRR, abs/2406.12045. Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Zhengran Zeng, Wei Ye, Jindong Wang, Yue Zhang, and Shikun Zhang...
-
[8]
Identifying the user, verifying identity, or handling retry after verification failure
**Authentication**: Identity verification. Identifying the user, verifying identity, or handling retry after verification failure
-
[9]
In non-authentication contexts, requesting missing parameters from the user needed to proceed with the task
**Elicitation**: Information gathering. In non-authentication contexts, requesting missing parameters from the user needed to proceed with the task
-
[10]
Invoking domain-specific tools to perform query or modification operations
**Execution**: Task execution. Invoking domain-specific tools to perform query or modification operations
-
[11]
Seeking explicit user confirmation before executing critical write operations
**Verification**: Operation confirmation. Seeking explicit user confirmation before executing critical write operations
-
[12]
Reporting tool execution results or current status to the user
**Notification**: Result reporting. Reporting tool execution results or current status to the user. # Annotation Principles
-
[13]
g., explaining + asking), prioritize the main purpose
**Primary intent takes precedence**: If multiple behaviors are present (e. g., explaining + asking), prioritize the main purpose
-
[14]
**Authentication takes precedence**: As long as the process of establishing user identity is ongoing, it must be annotated as Authentication
-
[15]
reason":
**Fact-based**: The reason field must be based on observable content, without speculation. # Output Format ```json { "reason": "Brief explanation of classification rationale", "intent": "Authentication|Elicitation |Execution|Verification|Notification " } ``` A.2 Trajectory Alignment For each trajectory, all think/response items are grouped by their annota...
-
[16]
Only when the declared tool call is never executed in the entire turn should it be considered Omission
**Consecutive thinking is not Omission **: If think1 declares intent, think2 continues reasoning, then tool_call executes, this is a normal multi-step thinking process, not Omission. Only when the declared tool call is never executed in the entire turn should it be considered Omission
-
[17]
Hallucinated_Action only refers to tool calls that appear out of nowhere within the current turn and cannot be explained by context
**Historical context is not Hallucinated_Action**: If the tool_call's parameters or purpose can be traced back to information or intent from previous conversation turns, this is not hallucinated execution. Hallucinated_Action only refers to tool calls that appear out of nowhere within the current turn and cannot be explained by context
-
[18]
**Delayed execution is normal**: In structures like think1-think2- toolcall1-toolcall2, it is normal for think2's idea to be executed in toolcall2, and should not be judged as anomalous. ### Structure Pattern - **Template_Based**: Follows strict, repetitive sentence patterns, such as fixed scripts - **Free_Form**: No obvious fixed templates, flexible and ...
-
[19]
**Exclude instruction requirements**: Formats/wording required by System Prompt or few-shot examples should not count toward similarity
-
[20]
**Same anomaly is a strong signal**: If both models exhibit the same type of execution anomaly, this is the strongest distillation signal
-
[21]
**Non-standard convergence is more valuable**: Both models adopting the same non-standard expression is more indicative of similarity than both adopting standard approaches
-
[22]
**Holistic judgment**: High similarity in any dimension can justify a high overall score
-
[23]
Important Judgment Rules
**Cautious anomaly judgment**: Before determining Omission or Hallucinated_Action, verify whether exceptions in the "Important Judgment Rules" apply # Scoring Rubric - **5**: Very similar. Highly consistent wording style and sentence structure, or identical anomaly patterns - **4**: Similar. Multiple similarities but with some differences - **3**: Neutral...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.