Recognition: unknown
Optimizing High-Throughput Distributed Data Pipelines for Reproducible Deep Learning at Scale
Pith reviewed 2026-05-08 14:12 UTC · model grok-4.3
The pith
Targeted fixes to data loading in distributed GPU training cut end-to-end time by a factor of six and enforce reproducibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
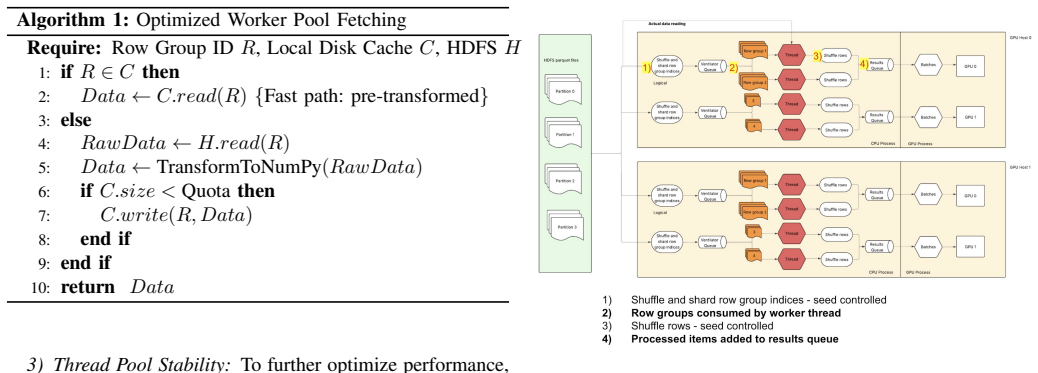
By applying push-down worker-level transformations and local-disk caching via Fanout-Cache to Petastorm and Apache Parquet pipelines, together with dedicated round-robin ventilator and result queues plus updated RNG handling, the authors remove race conditions and redundant I/O. This produces a sixfold reduction in end-to-end training time from 22 hours to 3 hours, raises GPU utilization above 60 percent, and eliminates run-to-run variance in data loading.
What carries the argument
The Fanout-Cache architecture with push-down transformations and dedicated round-robin queues that eliminate shared-state contention in multi-worker data pipelines.
If this is right
- Large-scale model training becomes feasible within practical time windows rather than requiring days of wall-clock time.
- GPU clusters deliver more than four times the effective throughput for the same hardware cost.
- Training runs produce identical data streams on every execution, removing a major source of non-reproducibility.
- The same pipeline changes apply to other Parquet-based loaders without requiring changes to model code.
Where Pith is reading between the lines
- Libraries that manage distributed data loading could adopt similar worker-level caching as a default to prevent repeated I/O across epochs.
- The determinism fixes may allow more reliable comparison of model variants during hyperparameter searches at scale.
- Extending the approach to other storage formats or cloud object stores would test whether the speedup pattern holds beyond Parquet.
Load-bearing premise
That network I/O and PyArrow-to-NumPy conversions remain the dominant bottlenecks in typical distributed GPU setups and that the added caching and queue changes introduce no new performance or correctness problems in other environments.
What would settle it
Run the identical large-scale training job on the same hardware and dataset but without the proposed caching, push-down transformations, or dedicated queues and measure whether total time stays near 22 hours, GPU utilization stays below 20 percent, and run-to-run data order varies.
Figures





read the original abstract
Training massive-scale deep learning models on datasets spanning tens of terabytes presents critical challenges in hardware utilization and training reproducibility. In this paper, we identify and resolve profound data-loading bottlenecks within distributed GPU training pipelines using the Petastorm data loader and Apache Parquet datasets. Through systematic profiling, we demonstrate that network I/O and CPU-bound data transformations (e.g., PyArrow to NumPy) constrain GPU utilization to as low as 10-15%. To address this, we propose an optimized architecture that features push-down worker-level transformations coupled with local-disk caching via Fanout-Cache, minimizing redundant I/O and CPU overhead across training epochs. Furthermore, we eliminate race conditions in multi-worker shared queues by implementing dedicated round-robin ventilator and result queues, alongside modernized RNG handling, achieving strict deterministic data loading. Our optimizations yield a 6x speedup, reducing end-to-end training time from 22 hours to 3 hours, increasing GPU utilization to over 60%, and drastically reducing run-to-run variance, enabling robust, high-throughput, and reproducible large-scale model training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that network I/O and PyArrow-to-NumPy transformations are the dominant bottlenecks in Petastorm-based distributed GPU training on terabyte-scale Parquet datasets, limiting utilization to 10-15%. It proposes an architecture with push-down worker transformations, local-disk caching via a new Fanout-Cache component, dedicated round-robin ventilator and result queues, and updated RNG handling to achieve determinism. These changes are reported to deliver a 6x end-to-end speedup (22 h to 3 h), GPU utilization above 60%, and substantially lower run-to-run variance.
Significance. If the measured gains prove robust and generalizable, the work would be significant for practitioners running large-scale reproducible training, as it directly targets data-loading overheads that commonly throttle GPU clusters. The emphasis on determinism via queue and RNG changes addresses a practical pain point. However, the current manuscript provides no quantitative profiling traces, ablation results, or head-to-head baselines, so the practical impact cannot yet be assessed.
major comments (4)
- Abstract: the claim that network I/O and PyArrow-to-NumPy conversions are the dominant constraints (limiting GPU utilization to 10-15%) is presented without any profiling data, traces, or utilization breakdowns to substantiate the diagnosis.
- Abstract: the reported 6x speedup and 22 h to 3 h reduction are stated without any baseline configuration details (hardware, cluster size, dataset cardinality, or unmodified Petastorm/PyTorch DataLoader numbers), preventing verification that the gains are caused by the proposed changes rather than other factors.
- Abstract: no ablation or incremental experiments are described that isolate the contribution of Fanout-Cache, the dedicated queues, or the push-down transformations to the overall speedup and variance reduction.
- Abstract: the assertion of 'drastically reducing run-to-run variance' lacks any quantitative metric (e.g., standard deviation of epoch times or statistical test) or comparison across multiple runs on the same workload.
minor comments (2)
- Abstract: the Fanout-Cache mechanism is introduced by name but without a concise definition, pseudocode, or diagram, making it difficult to understand its interaction with Petastorm workers.
- Abstract: the phrase 'modernized RNG handling' is too vague; the specific changes to random-number generation and how they guarantee determinism across epochs should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive feedback on strengthening the quantitative support for our claims. We address each major comment point-by-point below.
read point-by-point responses
-
Referee: Abstract: the claim that network I/O and PyArrow-to-NumPy conversions are the dominant constraints (limiting GPU utilization to 10-15%) is presented without any profiling data, traces, or utilization breakdowns to substantiate the diagnosis.
Authors: We agree that the abstract does not include supporting profiling data. The manuscript's Section 3 details the systematic profiling that identified network I/O and PyArrow-to-NumPy transformations as the primary bottlenecks, with GPU utilization at 10-15%. To address this, we will incorporate a summary of key profiling metrics and a utilization breakdown into the revised abstract and add a corresponding figure. revision: yes
-
Referee: Abstract: the reported 6x speedup and 22 h to 3 h reduction are stated without any baseline configuration details (hardware, cluster size, dataset cardinality, or unmodified Petastorm/PyTorch DataLoader numbers), preventing verification that the gains are caused by the proposed changes rather than other factors.
Authors: The experimental section of the manuscript specifies the hardware configuration, cluster size, dataset details, and baseline measurements with unmodified Petastorm and PyTorch DataLoader. We will revise the abstract to explicitly include these baseline configuration details to facilitate verification of the reported gains. revision: yes
-
Referee: Abstract: no ablation or incremental experiments are described that isolate the contribution of Fanout-Cache, the dedicated queues, or the push-down transformations to the overall speedup and variance reduction.
Authors: We acknowledge that the current manuscript does not present ablation studies isolating each optimization's contribution. In the revised version, we will add incremental ablation experiments that enable components one at a time to quantify their individual impacts on speedup and variance. revision: yes
-
Referee: Abstract: the assertion of 'drastically reducing run-to-run variance' lacks any quantitative metric (e.g., standard deviation of epoch times or statistical test) or comparison across multiple runs on the same workload.
Authors: The manuscript observes reduced variance through the deterministic queues and RNG changes, but does not provide quantitative metrics. We will add standard deviations of epoch times across multiple runs, along with statistical comparisons, to the results section and abstract in the revision. revision: yes
Circularity Check
Empirical optimizations with direct measurements; no derivations or self-referential reductions
full rationale
The paper is an empirical systems paper that profiles bottlenecks (network I/O, PyArrow-to-NumPy), implements concrete changes (Fanout-Cache, dedicated queues, RNG fixes), and reports measured outcomes (22h to 3h, GPU util >60%). No equations, predictions, or first-principles derivations appear in the provided text. Claims rest on timing and utilization measurements rather than any fitted parameter renamed as prediction or self-citation chain. This is the normal non-circular case for applied performance engineering.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Network I/O and CPU-bound data transformations are the primary constraints limiting GPU utilization in distributed training pipelines.
invented entities (1)
-
Fanout-Cache
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Petastorm,
Uber Technologies, “Petastorm,” GitHub Repository. [Online]. Avail- able: https://github.com/uber/petastorm
-
[2]
Horovod: fast and easy distributed deep learning in TensorFlow
A. Sergeev and M. Del Balso, “Horovod: fast and easy distributed deep learning in TensorFlow,”arXiv preprint arXiv:1802.05799, 2018
work page Pith review arXiv 2018
-
[3]
Ray: A Distributed Framework for Emerging AI Ap- plications,
P. Moritzet al., “Ray: A Distributed Framework for Emerging AI Ap- plications,” in13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, 2018, pp. 561–577
2018
-
[4]
The Hadoop Distributed File System,
K. Shvachko, H. Kuang, S. Radia, and R. Chansler, “The Hadoop Distributed File System,” in2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV , 2010, pp. 1–10
2010
-
[5]
Apache Parquet,
Apache Software Foundation, “Apache Parquet,” [Online]. Available: https://parquet.apache.org/
-
[6]
tf.data: A Machine Learning Data Processing Framework,
D. G. Murrayet al., “tf.data: A Machine Learning Data Processing Framework,”Proceedings of the VLDB Endowment, vol. 14, no. 12, pp. 2945–2958, 2021
2021
-
[7]
PyTorch: An Imperative Style, High-Performance Deep Learning Library,
A. Paszkeet al., “PyTorch: An Imperative Style, High-Performance Deep Learning Library,” inAdvances in Neural Information Processing Systems 32 (NeurIPS), 2019, pp. 8024–8035
2019
-
[8]
NVIDIA DALI: A GPU-accelerated data aug- mentation and image loading library,
NVIDIA Corporation, “NVIDIA DALI: A GPU-accelerated data aug- mentation and image loading library,” GitHub Repository. [Online]. Available: https://github.com/NVIDIA/DALI
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.