Recognition: unknown
LatRef-Diff: Latent and Reference-Guided Diffusion for Facial Attribute Editing and Style Manipulation
Pith reviewed 2026-05-09 22:41 UTC · model grok-4.3
The pith
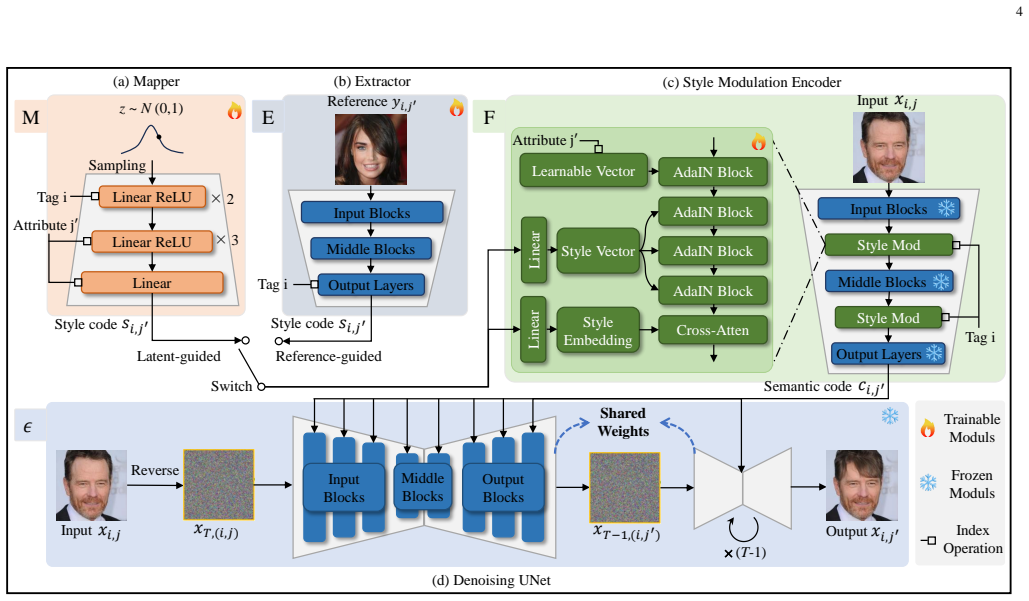
LatRef-Diff replaces semantic directions in diffusion models with latent and reference-guided style codes, uses a hierarchical style modulation module, and applies forward-backward consistency training to achieve state-of-the-art facial attribute editing and style manipulation on CelebA-HQ.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Extensive experiments on CelebA-HQ demonstrate that LatRef-Diff achieves state-of-the-art performance in both qualitative and quantitative evaluations.
Load-bearing premise
That style codes from latent and reference guidance combined with the style modulation module can precisely control target attributes without altering unrelated facial features, and that the forward-backward consistency strategy provides stable training without paired images.
Figures







read the original abstract
Facial attribute editing and style manipulation are crucial for applications like virtual avatars and photo editing. However, achieving precise control over facial attributes without altering unrelated features is challenging due to the complexity of facial structures and the strong correlations between attributes. While conditional GANs have shown progress, they are limited by accuracy issues and training instability. Diffusion models, though promising, face challenges in style manipulation due to the limited expressiveness of semantic directions. In this paper, we propose LatRef-Diff, a novel diffusion-based framework that addresses these limitations. We replace the traditional semantic directions in diffusion models with style codes and propose two methods for generating them: latent and reference guidance. Based on these style codes, we design a style modulation module that integrates them into the target image, enabling both random and customized style manipulation. This module incorporates learnable vectors, cross-attention mechanisms, and a hierarchical design to improve accuracy and image quality. Additionally, to enhance training stability while eliminating the need for paired images (e.g., before and after editing), we propose a forward-backward consistency training strategy. This strategy first removes the target attribute approximately using image-specific semantic directions and then restores it via style modulation, guided by perceptual and classification losses. Extensive experiments on CelebA-HQ demonstrate that LatRef-Diff achieves state-of-the-art performance in both qualitative and quantitative evaluations. Ablation studies validate the effectiveness of our model's design choices.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity: method components are independently specified and validated externally
full rationale
The derivation introduces style codes via latent/reference guidance, a style modulation module with learnable vectors and cross-attention, and a forward-backward consistency strategy using perceptual/classification losses to train without paired data. None of these reduce by construction to fitted inputs or prior self-citations; the abstract and described pipeline treat them as novel design choices whose effectiveness is checked via independent CelebA-HQ experiments rather than being presupposed by the equations themselves. No load-bearing step equates a prediction to its own training signal.
Axiom & Free-Parameter Ledger
invented entities (1)
-
style modulation module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Attgan: Facial attribute editing by only changing what you want,
Z. He, W. Zuo, M. Kan, S. Shan, and X. Chen, “Attgan: Facial attribute editing by only changing what you want,” IEEE Transactions on Image Processing, vol. 28, no. 11, pp. 5464–5478, 2019
2019
-
[2]
Stargan: Unified generative adversarial networks for multi-domain image-to- image translation,
Y . Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo, “Stargan: Unified generative adversarial networks for multi-domain image-to- image translation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2018, pp. 8789–8797
2018
-
[3]
Dreamsalon: A staged diffusion framework for preserving identity-context in editable face generation,
H. Lin, “Dreamsalon: A staged diffusion framework for preserving identity-context in editable face generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024, pp. 8589–8598
2024
-
[4]
Image-to-image translation with disentangled latent vectors for face editing,
Y . Dalva, H. Pehlivan, O. I. Hatipoglu, C. Moran, and A. Dundar, “Image-to-image translation with disentangled latent vectors for face editing,” IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2023
2023
-
[5]
Sdgan: Disentangling semantic manipulation for facial attribute editing,
W. Huang, W. Luo, J. Huang, and X. Cao, “Sdgan: Disentangling semantic manipulation for facial attribute editing,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 38, no. 3, 2024, pp. 2374–2381
2024
-
[6]
Facemug: A multi- modal generative and fusion framework for local facial editing,
W. Lu, J. Wang, X. Jin, X. Jiang, and H. Zhao, “Facemug: A multi- modal generative and fusion framework for local facial editing,” IEEE Transactions on Visualization and Computer Graphics , vol. 31, no. 9, pp. 5130–5145, 2025
2025
-
[7]
Conditional Generative Adversarial Nets
M. Mirza, “Conditional generative adversarial nets,” arXiv preprint arXiv:1411.1784, 2014
work page internal anchor Pith review arXiv 2014
-
[8]
High-fidelity gan inversion for image attribute editing,
T. Wang, Y . Zhang, Y . Fan, J. Wang, and Q. Chen, “High-fidelity gan inversion for image attribute editing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022, pp. 11 379–11 388
2022
-
[9]
Styleres: Transforming the residuals for real image editing with stylegan,
H. Pehlivan, Y . Dalva, and A. Dundar, “Styleres: Transforming the residuals for real image editing with stylegan,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023, pp. 1828–1837
2023
-
[10]
Drawinginstyles: Portrait image generation and editing with spatially conditioned stylegan,
W. Su, H. Ye, S.-Y . Chen, L. Gao, and H. Fu, “Drawinginstyles: Portrait image generation and editing with spatially conditioned stylegan,” IEEE Transactions on Visualization and Computer Graphics , vol. 29, no. 10, pp. 4074–4088, 2023
2023
-
[11]
An- alyzing and improving the image quality of stylegan,
T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila, “An- alyzing and improving the image quality of stylegan,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 8110–8119
2020
-
[12]
Interactive generative adversarial networks with high-frequency compensation for facial at- tribute editing,
W. Huang, W. Luo, X. Cao, and J. Huang, “Interactive generative adversarial networks with high-frequency compensation for facial at- tribute editing,” IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[13]
Towards principled methods for training generative adversarial networks,
M. Arjovsky and L. Bottou, “Towards principled methods for training generative adversarial networks,” International Conference on Learning Representations, 2017
2017
-
[14]
Which training methods for gans do actually converge?
L. Mescheder, A. Geiger, and S. Nowozin, “Which training methods for gans do actually converge?” in International Conference on Machine Learning, 2018, pp. 3481–3490
2018
-
[15]
Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models,
N. Ruiz, Y . Li, V . Jampani, W. Wei, T. Hou, Y . Pritch, N. Wadhwa, M. Rubinstein, and K. Aberman, “Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024, pp. 6527–6536
2024
-
[16]
Isolated diffusion: Optimizing multi-concept text-to-image generation training-freely with isolated dif- fusion guidance,
J. Zhu, H. Ma, J. Chen, and J. Yuan, “Isolated diffusion: Optimizing multi-concept text-to-image generation training-freely with isolated dif- fusion guidance,” IEEE Transactions on Visualization and Computer Graphics, vol. 31, no. 9, pp. 6280–6292, 2025
2025
-
[17]
Sdedit: Guided image synthesis and editing with stochastic differen- tial equations,
C. Meng, Y . He, Y . Song, J. Song, J. Wu, J.-Y . Zhu, and S. Ermon, “Sdedit: Guided image synthesis and editing with stochastic differen- tial equations,” International Conference on Learning Representations , 2021
2021
-
[18]
Diffusionclip: Text-guided diffusion models for robust image manipulation,
G. Kim, T. Kwon, and J. C. Ye, “Diffusionclip: Text-guided diffusion models for robust image manipulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022, pp. 2426–2435
2022
-
[19]
Diffusion autoencoders: Toward a meaningful and decodable represen- tation,
K. Preechakul, N. Chatthee, S. Wizadwongsa, and S. Suwajanakorn, “Diffusion autoencoders: Toward a meaningful and decodable represen- tation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 619–10 629
2022
-
[20]
Diffusion video autoencoders: Toward temporally consistent face video editing via disentangled video encoding,
G. Kim, H. Shim, H. Kim, Y . Choi, J. Kim, and E. Yang, “Diffusion video autoencoders: Toward temporally consistent face video editing via disentangled video encoding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023, pp. 6091–6100
2023
-
[22]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502 , 2020. 15
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
Arbitrary style transfer in real-time with adaptive instance normalization,
X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” in Proceedings of the IEEE Interna- tional Conference on Computer Vision , 2017, pp. 1501–1510
2017
-
[24]
Unpaired image-to-image translation using cycle-consistent adversarial networks,
J.-Y . Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proceedings of the IEEE International Conference on Computer Vision , 2017, pp. 2223–2232
2017
-
[25]
Progressive growing of gans for improved quality, stability, and variation,
T. Karras, “Progressive growing of gans for improved quality, stability, and variation,” International Conference on Learning Representations , 2018
2018
-
[26]
Generative adversarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in Neural Information Processing Systems , vol. 27, 2014
2014
-
[27]
Auto-encoding variational bayes,
D. P. Kingma, “Auto-encoding variational bayes,” International Confer- ence on Learning Representations , 2014
2014
-
[28]
Variational inference with normalizing flows,
D. Rezende and S. Mohamed, “Variational inference with normalizing flows,” in International Conference on Machine Learning , 2015, pp. 1530–1538
2015
-
[29]
Pixel recurrent neural networks,
A. Van Den Oord, N. Kalchbrenner, and K. Kavukcuoglu, “Pixel recurrent neural networks,” in International conference on machine learning, 2016, pp. 1747–1756
2016
-
[30]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in Neural Information Processing Systems , vol. 33, pp. 6840– 6851, 2020
2020
-
[31]
High- fidelity and arbitrary face editing,
Y . Gao, F. Wei, J. Bao, S. Gu, D. Chen, F. Wen, and Z. Lian, “High- fidelity and arbitrary face editing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2021, pp. 16 115–16 124
2021
-
[32]
A style-based generator architecture for generative adversarial networks
T. Karras, “A style-based generator architecture for generative adversar- ial networks,” arXiv preprint arXiv:1812.04948 , 2019
-
[33]
Interfacegan: Interpreting the disentangled face representation learned by gans,
Y . Shen, C. Yang, X. Tang, and B. Zhou, “Interfacegan: Interpreting the disentangled face representation learned by gans,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 44, no. 4, pp. 2004– 2018, 2020
2004
-
[34]
Styleclip: Text-driven manipulation of stylegan imagery,
O. Patashnik, Z. Wu, E. Shechtman, D. Cohen-Or, and D. Lischinski, “Styleclip: Text-driven manipulation of stylegan imagery,” in Proceed- ings of the IEEE/CVF International Conference on Computer Vision , 2021, pp. 2085–2094
2021
-
[35]
Stylespace analysis: Disen- tangled controls for stylegan image generation,
Z. Wu, D. Lischinski, and E. Shechtman, “Stylespace analysis: Disen- tangled controls for stylegan image generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2021, pp. 12 863–12 872
2021
-
[36]
Deep identity-aware transfer of facial attributes,
M. Li, W. Zuo, and D. Zhang, “Deep identity-aware transfer of facial attributes,” arXiv preprint arXiv:1610.05586 , 2016
-
[37]
Learning residual images for face attribute ma- nipulation,
W. Shen and R. Liu, “Learning residual images for face attribute ma- nipulation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2017, pp. 4030–4038
2017
-
[38]
Image-to-image translation via hierarchical style disentangle- ment,
X. Li, S. Zhang, J. Hu, L. Cao, X. Hong, X. Mao, F. Huang, Y . Wu, and R. Ji, “Image-to-image translation via hierarchical style disentangle- ment,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8639–8648
2021
-
[39]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,” Advances in Neural Information Processing Systems, vol. 34, pp. 8780–8794, 2021
2021
-
[40]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” in International Conference on Machine Learning , 2015, pp. 2256–2265
2015
-
[41]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[42]
Elegant: Exchanging latent encodings with gan for transferring multiple face attributes,
T. Xiao, J. Hong, and J. Ma, “Elegant: Exchanging latent encodings with gan for transferring multiple face attributes,” in Proceedings of the European Conference on Computer Vision , 2018, pp. 168–184
2018
-
[43]
Facial attribute editing via a balanced simple attention generative adversarial network,
F. Ren, W. Liu, F. Wang, B. Wang, and F. Sun, “Facial attribute editing via a balanced simple attention generative adversarial network,” Expert Systems with Applications , vol. 277, p. 127245, 2025
2025
-
[44]
Instructpix2pix: Learning to follow image editing instructions,
T. Brooks, A. Holynski, and A. A. Efros, “Instructpix2pix: Learning to follow image editing instructions,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2023, pp. 18 392–18 402
2023
-
[45]
Instruct-clip: Improving instruction- guided image editing with automated data refinement using contrastive learning,
S. X. Chen, M. Sra, and P. Sen, “Instruct-clip: Improving instruction- guided image editing with automated data refinement using contrastive learning,” in Proceedings of the Computer Vision and Pattern Recogni- tion Conference, 2025, pp. 28 513–28 522
2025
-
[46]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in Neural Information Processing Systems , vol. 30, 2017
2017
-
[47]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2016, pp. 770–778
2016
-
[48]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” in Proceedings of the IEEE/CVF international conference on computer vision , 2023, pp. 3836–3847. Wenmin Huang received the M.E. degree in intel- ligent science and technology from Tianjin Normal University, in 2021. He is currently working toward the Ph.D. ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.