Recognition: unknown
AttDiff-GAN: A Hybrid Diffusion-GAN Framework for Facial Attribute Editing
Pith reviewed 2026-05-09 22:27 UTC · model grok-4.3
The pith
AttDiff-GAN decouples attribute editing from image synthesis with feature-level adversarial learning to deliver more accurate facial edits and stronger preservation of non-target attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
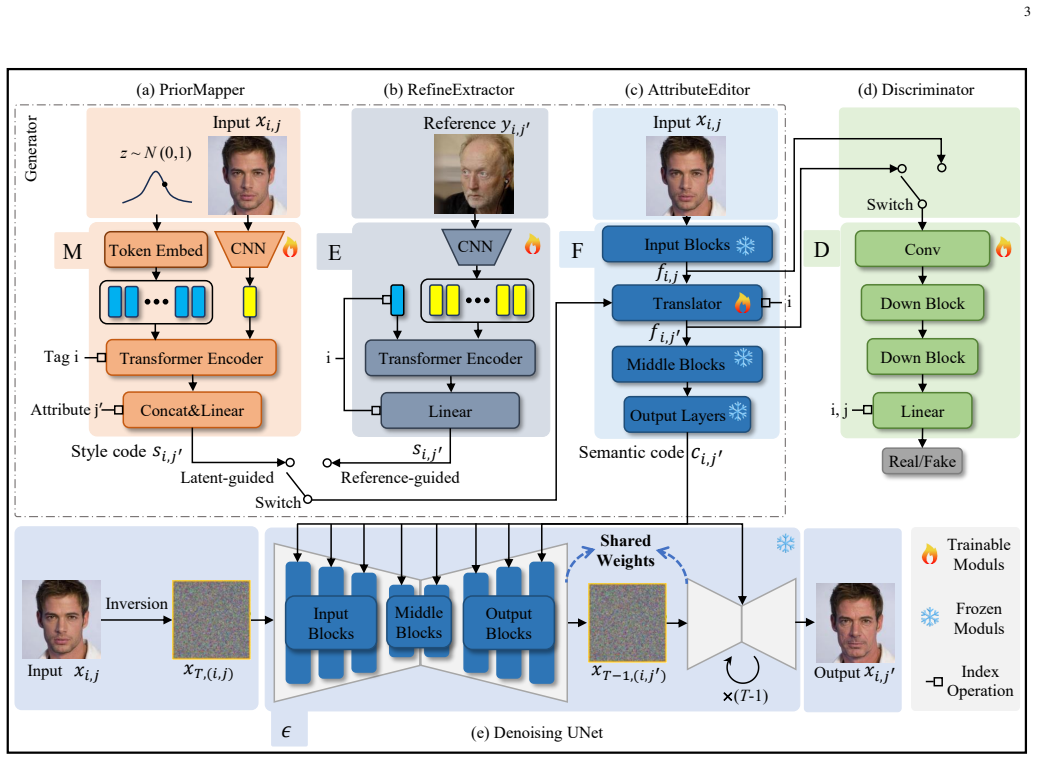
AttDiff-GAN integrates GAN-based attribute manipulation with diffusion-based image generation by introducing a feature-level adversarial learning scheme that decouples the editing step from synthesis. This removes reliance on semantic direction vectors, uses the manipulated features to condition the diffusion process, and adds PriorMapper to fold facial priors into style codes along with RefineExtractor to capture global semantic relations via a Transformer. The result is more precise target-attribute changes and better retention of unrelated content than prior methods, as shown in both visual and numerical tests on CelebA-HQ.
What carries the argument
Feature-level adversarial learning scheme that learns explicit attribute manipulation in feature space and feeds the result to guide multi-step diffusion denoising.
If this is right
- Target attributes can be edited with higher precision because manipulation occurs explicitly at the feature level rather than through entangled semantic directions.
- Non-target attributes and overall image content remain more stable because the diffusion stage is conditioned only on the already-edited features.
- Style-attribute alignment improves when facial priors are injected during style code generation and global relations are captured by a Transformer extractor.
- Optimization becomes feasible by avoiding direct conflict between single-step adversarial updates and iterative denoising steps.
Where Pith is reading between the lines
- The same decoupling pattern could be tested on non-face editing tasks such as changing object properties in natural scenes without altering background elements.
- If the feature-level bridge proves stable, hybrid models might allow diffusion generators to inherit controllability from adversarial components in other conditional generation settings.
- An ablation that removes only the feature-level adversarial component and measures the resulting rise in attribute entanglement would directly test the claimed resolution of the inconsistency.
Load-bearing premise
That a feature-level adversarial learning scheme can resolve the inconsistency between one-step adversarial learning and multi-step diffusion denoising to enable effective decoupling without introducing new entanglements.
What would settle it
Quantitative results on CelebA-HQ in which the method does not exceed state-of-the-art baselines on both attribute classification accuracy for the target and identity or non-target attribute preservation metrics.
Figures





read the original abstract
Facial attribute editing aims to modify target attributes while preserving attribute-irrelevant content and overall image fidelity. Existing GAN-based methods provide favorable controllability, but often suffer from weak alignment between style codes and attribute semantics. Diffusion-based methods can synthesize highly realistic images; however, their editing precision is limited by the entanglement of semantic directions among different attributes. In this paper, we propose AttDiff-GAN, a hybrid framework that combines GAN-based attribute manipulation with diffusion-based image generation. A key challenge in such integration lies in the inconsistency between one-step adversarial learning and multi-step diffusion denoising, which makes effective optimization difficult. To address this issue, we decouple attribute editing from image synthesis by introducing a feature-level adversarial learning scheme to learn explicit attribute manipulation, and then using the manipulated features to guide the diffusion process for image generation, while also removing the reliance on semantic direction-based editing. Moreover, we enhance style-attribute alignment by introducing PriorMapper, which incorporates facial priors into style generation, and RefineExtractor, which captures global semantic relationships through a Transformer for more precise style extraction. Experimental results on CelebA-HQ show that the proposed method achieves more accurate facial attribute editing and better preservation of non-target attributes than state-of-the-art methods in both qualitative and quantitative evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AttDiff-GAN, a hybrid framework that integrates GAN-based attribute manipulation with diffusion-based image generation for facial attribute editing. It identifies the inconsistency between one-step adversarial learning and multi-step diffusion denoising as a key challenge and addresses it by decoupling attribute editing from image synthesis via a feature-level adversarial learning scheme. The framework incorporates PriorMapper to integrate facial priors into style generation and RefineExtractor, which uses a Transformer to capture global semantic relationships for improved style extraction. Experimental results on the CelebA-HQ dataset are claimed to show superior performance in accurate editing and preservation of non-target attributes compared to state-of-the-art methods, in both qualitative and quantitative evaluations.
Significance. This work tackles a relevant problem in generative modeling by proposing a hybrid approach that leverages the strengths of both GANs and diffusion models. The decoupling strategy and the introduction of PriorMapper and RefineExtractor represent targeted solutions to alignment and consistency issues. If the experimental claims are substantiated with detailed metrics and ablations, the method could contribute to advancing controllable image editing techniques in computer vision.
major comments (2)
- Abstract: The abstract states that 'Experimental results on CelebA-HQ show that the proposed method achieves more accurate facial attribute editing and better preservation of non-target attributes than state-of-the-art methods in both qualitative and quantitative evaluations.' However, no specific quantitative metrics, such as attribute editing accuracy, FID scores, or comparisons with named baselines (e.g., StarGAN, DiffEdit), are provided. This absence undermines the ability to assess the central claim of superiority, which is load-bearing for the paper's contribution.
- Method section: The description of the feature-level adversarial learning scheme to resolve the inconsistency between adversarial and diffusion processes is high-level. Without explicit equations or a detailed analysis showing how the manipulated features guide the diffusion process without new entanglements, it is difficult to verify if the decoupling is effective as claimed.
minor comments (2)
- The paper introduces new components named PriorMapper and RefineExtractor; including a figure illustrating their architecture would enhance clarity.
- Ensure that all claims of 'state-of-the-art' are supported by citations to the specific competing methods used in the experiments.
Simulated Author's Rebuttal
We sincerely thank the referee for the thoughtful and constructive feedback on our paper. We have addressed each of the major comments below and made revisions to the manuscript to improve clarity and substantiate our claims.
read point-by-point responses
-
Referee: [—] Abstract: The abstract states that 'Experimental results on CelebA-HQ show that the proposed method achieves more accurate facial attribute editing and better preservation of non-target attributes than state-of-the-art methods in both qualitative and quantitative evaluations.' However, no specific quantitative metrics, such as attribute editing accuracy, FID scores, or comparisons with named baselines (e.g., StarGAN, DiffEdit), are provided. This absence undermines the ability to assess the central claim of superiority, which is load-bearing for the paper's contribution.
Authors: We acknowledge that the abstract would be strengthened by the inclusion of specific quantitative metrics to support our claims of superiority. In the revised manuscript, we have updated the abstract to reference key results from our experiments, such as improved attribute editing accuracy and lower FID scores compared to baselines like StarGAN and DiffEdit. These details are elaborated in Section 4, and their inclusion in the abstract now provides a more concrete basis for assessing the method's performance. revision: yes
-
Referee: [—] Method section: The description of the feature-level adversarial learning scheme to resolve the inconsistency between adversarial and diffusion processes is high-level. Without explicit equations or a detailed analysis showing how the manipulated features guide the diffusion process without new entanglements, it is difficult to verify if the decoupling is effective as claimed.
Authors: Thank you for highlighting the need for more explicit details in the method description. We agree that the decoupling strategy benefits from clearer mathematical exposition. Accordingly, we have revised Section 3.1 to include the explicit formulation of the feature-level adversarial loss and a detailed analysis of how the edited features are used to condition the diffusion process. This addition demonstrates that the feature-level approach prevents the introduction of new entanglements by separating the attribute manipulation from the denoising steps, with supporting intuition and pseudocode for the guidance mechanism. revision: yes
Circularity Check
No significant circularity; derivation is self-contained engineering construction
full rationale
The paper introduces AttDiff-GAN as a hybrid framework that explicitly acknowledges the inconsistency between one-step adversarial learning and multi-step diffusion, then proposes a feature-level adversarial scheme, PriorMapper, and RefineExtractor to decouple editing from synthesis. No equations or claims reduce the output to fitted inputs by construction, no self-citation chains bear the central claim, and no ansatz or uniqueness result is smuggled in. Experimental superiority on CelebA-HQ is presented as an independent empirical outcome rather than a definitional consequence of the method's own parameters. The derivation chain remains externally falsifiable and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Compatibility of feature-level adversarial signals with subsequent diffusion denoising steps after decoupling
invented entities (2)
-
PriorMapper
no independent evidence
-
RefineExtractor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
High-fidelity gan inversion for image attribute editing,
T. Wang, Y . Zhang, Y . Fan, J. Wang, and Q. Chen, “High-fidelity gan inversion for image attribute editing,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11 379–11 388
2022
-
[2]
Styleres: Transforming the residuals for real image editing with stylegan,
H. Pehlivan, Y . Dalva, and A. Dundar, “Styleres: Transforming the residuals for real image editing with stylegan,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1828–1837
2023
-
[3]
Attgan: Facial attribute editing by only changing what you want,
Z. He, W. Zuo, M. Kan, S. Shan, and X. Chen, “Attgan: Facial attribute editing by only changing what you want,”IEEE Transactions on Image Processing, vol. 28, no. 11, pp. 5464–5478, 2019
2019
-
[4]
Interactive generative adversarial networks with high-frequency compensation for facial at- tribute editing,
W. Huang, W. Luo, X. Cao, and J. Huang, “Interactive generative adversarial networks with high-frequency compensation for facial at- tribute editing,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[5]
Image-to-image translation with disentangled latent vectors for face editing,
Y . Dalva, H. Pehlivan, O. I. Hatipoglu, C. Moran, and A. Dundar, “Image-to-image translation with disentangled latent vectors for face editing,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2023
2023
-
[6]
Sdgan: Disentangling semantic manipulation for facial attribute editing,
W. Huang, W. Luo, J. Huang, and X. Cao, “Sdgan: Disentangling semantic manipulation for facial attribute editing,” inAAAI Conference on Artificial Intelligence, vol. 38, no. 3, 2024, pp. 2374–2381
2024
-
[7]
Facial attribute editing via a balanced simple attention generative adversarial network,
F. Ren, W. Liu, F. Wang, B. Wang, and F. Sun, “Facial attribute editing via a balanced simple attention generative adversarial network,”Expert Systems with Applications, vol. 277, p. 127245, 2025
2025
-
[8]
Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models,
N. Ruiz, Y . Li, V . Jampani, W. Wei, T. Hou, Y . Pritch, N. Wadhwa, M. Rubinstein, and K. Aberman, “Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 6527–6536
2024
-
[9]
Sdedit: Guided image synthesis and editing with stochastic differen- tial equations,
C. Meng, Y . He, Y . Song, J. Song, J. Wu, J.-Y . Zhu, and S. Ermon, “Sdedit: Guided image synthesis and editing with stochastic differen- tial equations,”International Conference on Learning Representations, 2021
2021
-
[10]
Osdface: One-step diffusion model for face restoration,
J. Wang, J. Gong, L. Zhang, Z. Chen, X. Liu, H. Gu, Y . Liu, Y . Zhang, and X. Yang, “Osdface: One-step diffusion model for face restoration,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 12 626–12 636
2025
-
[11]
Diffusion autoencoders: Toward a meaningful and decodable repre- sentation,
K. Preechakul, N. Chatthee, S. Wizadwongsa, and S. Suwajanakorn, “Diffusion autoencoders: Toward a meaningful and decodable repre- sentation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 619–10 629
2022
-
[12]
Diffusion video autoencoders: Toward temporally consistent face video editing via disentangled video encoding,
G. Kim, H. Shim, H. Kim, Y . Choi, J. Kim, and E. Yang, “Diffusion video autoencoders: Toward temporally consistent face video editing via disentangled video encoding,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6091–6100
2023
-
[13]
Progressive growing of gans for improved quality, stability, and variation,
T. Karras, “Progressive growing of gans for improved quality, stability, and variation,”International Conference on Learning Representations, 2018
2018
-
[14]
Auto-encoding variational bayes,
D. P. Kingma, “Auto-encoding variational bayes,”International Confer- ence on Learning Representations, 2014
2014
-
[15]
Variational inference with normalizing flows,
D. Rezende and S. Mohamed, “Variational inference with normalizing flows,” inInternational Conference on Machine Learning, 2015, pp. 1530–1538
2015
-
[16]
Pixel recurrent neural networks,
A. Van Den Oord, N. Kalchbrenner, and K. Kavukcuoglu, “Pixel recurrent neural networks,” inInternational Conference on Machine Learning, 2016, pp. 1747–1756
2016
-
[17]
Generative adversarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in Neural Information Processing Systems, vol. 27, 2014
2014
-
[18]
Analyzing and improving the image quality of stylegan,
T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila, “Analyzing and improving the image quality of stylegan,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 8110–8119
2020
-
[19]
Kernel reformulation with deep constrained least squares for blind image super-resolution,
Z. Luo, H. Huang, L. Yu, Y . Li, B. Zeng, and S. Liu, “Kernel reformulation with deep constrained least squares for blind image super-resolution,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 8, pp. 7380–7394, 2025
2025
-
[20]
Infostyler: Disentanglement information bottleneck for artistic style transfer,
Y . Lyu, Y . Jiang, B. Peng, and J. Dong, “Infostyler: Disentanglement information bottleneck for artistic style transfer,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 4, pp. 2070– 2082, 2024
2070
-
[21]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in Neural Information Processing Systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[22]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 684–10 695
2022
-
[24]
Instructpix2pix: Learning to follow image editing instructions,
T. Brooks, A. Holynski, and A. A. Efros, “Instructpix2pix: Learning to follow image editing instructions,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 392–18 402
2023
-
[25]
Soedit: Improving instruction-driven object editing by focusing on a single object within a cropped region,
W. Luo, S. Yang, and H. Niu, “Soedit: Improving instruction-driven object editing by focusing on a single object within a cropped region,” IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2026
2026
-
[26]
High-fidelity and arbitrary face editing,
Y . Gao, F. Wei, J. Bao, S. Gu, D. Chen, F. Wen, and Z. Lian, “High-fidelity and arbitrary face editing,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 115–16 124
2021
-
[27]
A style-based generator architecture for generative adversarial networks
T. Karras, “A style-based generator architecture for generative adversar- ial networks,”arXiv preprint arXiv:1812.04948, 2019
-
[28]
Interfacegan: Interpreting the disentangled face representation learned by gans,
Y . Shen, C. Yang, X. Tang, and B. Zhou, “Interfacegan: Interpreting the disentangled face representation learned by gans,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 4, pp. 2004– 2018, 2020
2004
-
[29]
Styleclip: Text-driven manipulation of stylegan imagery,
O. Patashnik, Z. Wu, E. Shechtman, D. Cohen-Or, and D. Lischinski, “Styleclip: Text-driven manipulation of stylegan imagery,” inIEEE/CVF International Conference on Computer Vision, 2021, pp. 2085–2094
2021
-
[30]
Stylespace analysis: Disentan- gled controls for stylegan image generation,
Z. Wu, D. Lischinski, and E. Shechtman, “Stylespace analysis: Disentan- gled controls for stylegan image generation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 863–12 872
2021
-
[31]
Deep identity-aware transfer of facial attributes,
M. Li, W. Zuo, and D. Zhang, “Deep identity-aware transfer of facial attributes,”arXiv preprint arXiv:1610.05586, 2016
-
[32]
Learning residual images for face attribute ma- nipulation,
W. Shen and R. Liu, “Learning residual images for face attribute ma- nipulation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 4030–4038
2017
-
[33]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[34]
Image-to-image translation via hierarchical style disentan- glement,
X. Li, S. Zhang, J. Hu, L. Cao, X. Hong, X. Mao, F. Huang, Y . Wu, and R. Ji, “Image-to-image translation via hierarchical style disentan- glement,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8639–8648
2021
-
[35]
Interpreting the latent space of gans for semantic face editing,
Y . Shen, J. Gu, X. Tang, and B. Zhou, “Interpreting the latent space of gans for semantic face editing,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9243–9252
2020
-
[36]
Arbitrary style transfer in real-time with adaptive instance normalization,
X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” inIEEE/CVF International Conference on Computer Vision, 2017, pp. 1501–1510. 13
2017
-
[37]
Instruct-clip: Improving instruction- guided image editing with automated data refinement using contrastive learning,
S. X. Chen, M. Sra, and P. Sen, “Instruct-clip: Improving instruction- guided image editing with automated data refinement using contrastive learning,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition Conference, 2025, pp. 28 513–28 522
2025
-
[38]
L2m- gan: Learning to manipulate latent space semantics for facial attribute editing,
G. Yang, N. Fei, M. Ding, G. Liu, Z. Lu, and T. Xiang, “L2m- gan: Learning to manipulate latent space semantics for facial attribute editing,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2951–2960
2021
-
[39]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[40]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[41]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,”Advances in Neural Information Processing Systems, vol. 35, pp. 36 479–36 494, 2022. Wenmin Huangreceived the M.E. degree in intel- ligent sci...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.