Recognition: unknown
Sub-Token Routing in LoRA for Adaptation and Query-Aware KV Compression
Pith reviewed 2026-05-09 22:47 UTC · model grok-4.3
The pith
Sub-token routing inside LoRA-adapted transformers enables deeper KV cache compression with nearly unchanged task accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
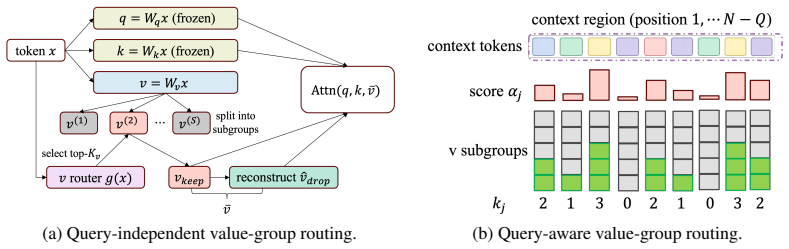
Sub-token routing supplies a finer compression axis than tokens, pages, heads, or layers. The query-independent setting combines routed subspace LoRA with value-group routing on the KV path and improves language-model quality under reduced KV budgets. The query-aware setting employs a predictor-based selector to allocate retention budgets over context-token/value-group pairs using query-conditioned relevance and preserves downstream behavior under KV compression. Sub-token routing works best as a complement to token-level query-aware selection, allowing deeper KV compression at nearly unchanged task accuracy.
What carries the argument
Sub-token routing via routed subspace LoRA combined with value-group routing on the KV path, optionally extended by a query-aware predictor-based selector that allocates a global retention budget over token/value-group pairs.
If this is right
- Query-independent sub-token routing improves language-model quality under reduced KV budgets.
- Query-aware sub-token routing preserves downstream task behavior well under KV compression.
- Sub-token routing functions as a complementary axis to token-level query-aware selection.
- The combination of the two axes supports deeper KV compression while keeping task accuracy nearly the same.
Where Pith is reading between the lines
- The same sub-token mechanism could be tested on other memory-bound components such as attention scores or intermediate activations.
- Integration with adaptation methods other than LoRA might yield similar compression gains.
- Dynamic adjustment of the retention budget during a single inference pass could further reduce average memory use.
- The approach may scale to longer contexts where KV cache size grows linearly with sequence length.
Load-bearing premise
That routing decisions made inside individual token representations preserve the information needed for the model's downstream predictions without introducing errors that cannot be recovered.
What would settle it
Measuring downstream task accuracy at KV compression ratios higher than those achieved by token-level methods alone; a clear drop below the reported 'nearly unchanged' level when sub-token routing is added would refute the central claim.
Figures

read the original abstract
Sub-token routing provides a finer compression axis for transformer efficiency than the coarse units used in most prior work, such as tokens, pages, heads, or layers. In this paper, we study routing within a token representation itself in LoRA-adapted transformers. We consider two settings. In the query-independent setting, we combine routed subspace LoRA with value-group routing on the KV path for compression-aware language modeling. In the query-aware setting, we use a predictor-based selector to allocate a global retention budget over context-token/value-group pairs using query-conditioned relevance. Experiments show that the query-independent design improves language-model quality under reduced KV budgets, while the query-aware design preserves downstream behavior well under KV compression. We further show that sub-token routing is most effective as a complementary compression axis to token-level query-aware selection: token-level methods decide which tokens survive globally, while sub-token routing determines how the surviving tokens are compressed internally. Their combination enables deeper KV compression at nearly unchanged task accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity: empirical claims rest on experiments, not self-referential derivations
full rationale
The paper presents no mathematical derivation chain or first-principles predictions. Its core claims concern experimental outcomes from two routing settings (query-independent and query-aware) combined with LoRA adaptation and KV compression. The abstract and described content rely on empirical results showing improved quality or preserved accuracy under reduced budgets, without equations that reduce fitted parameters to predictions by construction, self-citations that bear the load of uniqueness theorems, or ansatzes smuggled via prior work. No load-bearing step equates outputs to inputs tautologically; the work is self-contained against external benchmarks via reported task accuracies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (2023)
Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y ., Lebrón, F., Sanghai, S.: Gqa: Training generalized multi-query transformer models from multi-head checkpoints. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (2023)
2023
-
[2]
Devoto, A., Jeblick, M., Jégou, S.: Expected attention: Kv cache compression by estimating attention from future queries distribution. arXiv preprint arXiv:2510.00636 (2025)
-
[3]
In: International Conference on Learning Representations (ICLR) (2021),https://openreview.net/forum?id=d7KBjmI3GmQ
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Mea- suring massive multitask language understanding. In: International Conference on Learning Representations (ICLR) (2021),https://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E.J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al.: Mistral 7B. arXiv preprint arXiv:2310.06825 (2023),https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
arXiv preprint arXiv:2410.15704 (2024)
Kumar, A.: Residual vector quantization for kv cache compression in large language model. arXiv preprint arXiv:2410.15704 (2024)
-
[7]
In: Advances in Neural Information Processing Systems (2024)
Liu, A., Liu, J., Pan, Z., He, Y ., Haffari, G., Zhuang, B.: Minicache: Kv cache compression in depth dimension for large language models. In: Advances in Neural Information Processing Systems (2024)
2024
-
[8]
F., Cheng, K.-T., and Chen, M.-H
Liu, S.Y ., Wang, C.Y ., Yin, H., Molchanov, P., Wang, Y .C.F., Cheng, K.T., Chen, M.H.: Dora: Weight-decomposed low-rank adaptation. arXiv preprint arXiv:2402.09353 (2024)
-
[9]
In: Proceedings of the ACM SIGCOMM 2024 Conference (2024)
Liu, Y ., Li, H., Cheng, Y ., Ray, S., Huang, Y ., Zhang, Q., Du, K., Yao, J., Lu, S., Anan- thanarayanan, G., Maire, M., Hoffmann, H., Holtzman, A., Jiang, J.: Cachegen: Kv cache compression and streaming for fast large language model serving. In: Proceedings of the ACM SIGCOMM 2024 Conference (2024)
2024
-
[10]
AdaMoLE: Adaptive mixture of LoRA experts.arXiv preprint arXiv:2405.00361, 2024
Liu, Z., Luo, J.: Adamole: Adaptive mixture of low-rank adaptation experts. arXiv preprint arXiv:2405.00361 (2024)
-
[11]
Luo, T., Lei, J., Lei, F., Liu, W., He, S., Zhao, J., Liu, K.: Moelora: Contrastive learning guided mixture of experts on parameter-efficient fine-tuning for large language models. arXiv preprint arXiv:2402.12851 (2024)
-
[12]
In: International Conference on Learning Representations (ICLR) (2017), https://openreview.net/forum? id=Byj72udxe
Merity, S., Xiong, C., Bradbury, J., Socher, R.: Pointer sentinel mixture models. In: International Conference on Learning Representations (ICLR) (2017), https://openreview.net/forum? id=Byj72udxe
2017
-
[13]
Qwen Team: Qwen2.5 technical report (2024), https://qwenlm.github.io/blog/qwen2. 5/
2024
-
[14]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, N.: Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150 (2019)
work page internal anchor Pith review arXiv 1911
-
[15]
arXiv preprint arXiv:2406.10774 , year=
Tang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., Han, S.: Quest: Query-aware sparsity for efficient long-context llm inference. arXiv preprint arXiv:2406.10774 (2024)
-
[16]
In: Advances in Neural Information Processing Systems
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems. vol. 30 (2017)
2017
-
[17]
In: International Conference on Learning Representations (2024)
Wu, X., Huang, S., Ye, Y ., Xia, F., Stoyanov, V ., Roth, D.: Mixture of lora experts. In: International Conference on Learning Representations (2024)
2024
-
[18]
In: International Conference on Learning Representations (2024) 11
Xiao, G., Tian, Y ., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. In: International Conference on Learning Representations (2024) 11
2024
-
[19]
In: International Conference on Learning Representations (2023)
Zhang, Q., Chen, M., Bukharin, A., Karampatziakis, N., He, P., Cheng, Y ., Chen, W., Zhao, T.: Adalora: Adaptive budget allocation for parameter-efficient fine-tuning. In: International Conference on Learning Representations (2023)
2023
-
[20]
arXiv preprint arXiv:2306.14048 , year=
Zhang, Z., Sheng, Y ., Zhou, T., Chen, T., Zheng, L., Cai, R., Song, Z., Tian, Y ., Ré, C., Barrett, C., Wang, Z., Chen, B.: H 2o: Heavy-hitter oracle for efficient generative inference of large language models. arXiv preprint arXiv:2306.14048 (2023) A Additional Method Details A.1 Optimization Objectives Query-independent routing.The query-independent mo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.