Recognition: unknown
CARE: Counselor-Aligned Response Engine for Online Mental-Health Support
Pith reviewed 2026-05-09 22:28 UTC · model grok-4.3
The pith
Fine-tuning language models on expert-rated counselor conversations produces responses that align more closely with professional mental health strategies than general models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
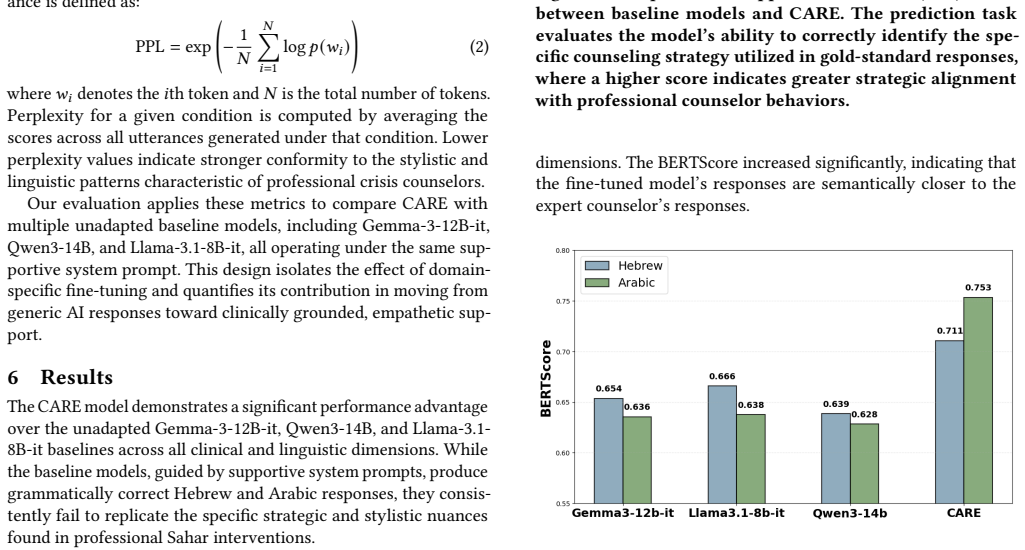
CARE fine-tunes open-source LLMs separately for Hebrew and Arabic using curated subsets of real-world crisis conversations rated as highly effective by professional counselors. Training on complete conversation histories enables the models to maintain evolving emotional context and dynamic dialogue structure. In experimental settings, CARE demonstrates stronger semantic and strategic alignment with gold-standard counselor responses compared to non-specialized LLMs, indicating that domain-specific fine-tuning on expert-validated data can support counselor workflows and improve care quality in low-resource language contexts.
What carries the argument
CARE (Counselor-Aligned Response Engine), which fine-tunes separate LLMs for Hebrew and Arabic on full histories of expert-rated effective crisis sessions to generate real-time response recommendations.
Load-bearing premise
That fine-tuning on curated subsets of highly effective counselor sessions will enable models to generalize to new conversations while preserving nuanced, context-aware support without introducing harmful biases or errors.
What would settle it
A test on new, unseen crisis conversations where CARE responses show no better or worse alignment with professional counselors than base LLMs, or where they produce unsafe or biased suggestions absent from the base models.
Figures



read the original abstract
Mental health challenges are increasing worldwide, straining emotional support services and leading to counselor overload. This can result in delayed responses during critical situations, such as suicidal ideation, where timely intervention is essential. While large language models (LLMs) have shown strong generative capabilities, their application in low-resource languages, especially in sensitive domains like mental health, remains underexplored. Furthermore, existing LLM-based agents often struggle to replicate the supportive language and intervention strategies used by professionals due to a lack of training on large-scale, real-world datasets. To address this, we propose CARE (Counselor-Aligned Response Engine), a GenAI framework that assists counselors by generating real-time, psychologically aligned response recommendations. CARE fine-tunes open-source LLMs separately for Hebrew and Arabic using curated subsets of real-world crisis conversations. The training data consists of sessions rated as highly effective by professional counselors, enabling the models to capture interaction patterns associated with successful de-escalation. By training on complete conversation histories, CARE maintains the evolving emotional context and dynamic structure of counselor-help-seeker dialogue. In experimental settings, CARE demonstrates stronger semantic and strategic alignment with gold-standard counselor responses compared to non-specialized LLMs. These findings suggest that domain-specific fine-tuning on expert-validated data can significantly support counselor workflows and improve care quality in low-resource language contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CARE, a GenAI framework to assist counselors in online mental-health support for Hebrew and Arabic. It fine-tunes open-source LLMs separately on curated subsets of real-world crisis conversations rated as highly effective by professionals, using complete session histories to preserve emotional context and dialogue structure. The central claim, based on experimental settings, is that CARE produces responses with stronger semantic and strategic alignment to gold-standard counselor replies than non-specialized LLMs, with potential to reduce counselor overload and improve care quality in low-resource languages.
Significance. If the alignment results hold under rigorous evaluation, the work could meaningfully advance domain-adapted LLMs for sensitive, low-resource applications by demonstrating that expert-validated fine-tuning on full conversation histories can capture effective de-escalation patterns. The emphasis on real-world crisis data and separate language models is a practical strength for deployment in Hebrew/Arabic contexts where general LLMs underperform.
major comments (2)
- [Results section] Results section (and abstract): The claim of stronger semantic and strategic alignment is load-bearing for the paper's contribution, yet no specific metrics (e.g., embedding similarity, strategy classification accuracy), baselines, dataset sizes, number of sessions, or statistical tests are described. This prevents evaluation of whether the reported improvement is reliable or merely qualitative.
- [Methods section] Methods / Data curation: The selection of 'highly effective' sessions is central to the domain-adaptation argument, but the paper provides no details on the rating protocol, inter-rater reliability, or criteria used by professional counselors. Without this, it is unclear whether the training data truly isolates successful intervention strategies or introduces selection bias.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief statement of the exact open-source base models used and the fine-tuning hyperparameters to allow reproducibility.
- [Results] Figure or table captions for any alignment comparisons should explicitly list the evaluation metrics and sample sizes.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for improving the clarity and rigor of our presentation. We address each major comment below and have revised the manuscript to provide the requested details.
read point-by-point responses
-
Referee: Results section (and abstract): The claim of stronger semantic and strategic alignment is load-bearing for the paper's contribution, yet no specific metrics (e.g., embedding similarity, strategy classification accuracy), baselines, dataset sizes, number of sessions, or statistical tests are described. This prevents evaluation of whether the reported improvement is reliable or merely qualitative.
Authors: We agree that the original results section and abstract would benefit from explicit quantitative support for the alignment claims. In the revised manuscript, we have expanded the Results section (and updated the abstract) to report the specific metrics used for semantic alignment (cosine similarity via multilingual embeddings) and strategic alignment (accuracy on counselor-defined strategy classification), the full set of baselines (including untuned open-source LLMs and general-purpose models), exact dataset sizes, number of sessions, and statistical tests with p-values. These additions allow readers to assess the reliability of the improvements. revision: yes
-
Referee: Methods / Data curation: The selection of 'highly effective' sessions is central to the domain-adaptation argument, but the paper provides no details on the rating protocol, inter-rater reliability, or criteria used by professional counselors. Without this, it is unclear whether the training data truly isolates successful intervention strategies or introduces selection bias.
Authors: We acknowledge that the original Methods section lacked sufficient transparency on data curation. We have revised this section to describe the rating protocol in detail, including the criteria used by professional counselors to identify 'highly effective' sessions (e.g., demonstrated empathy, appropriate de-escalation techniques, and positive session outcomes), the rating scale, and inter-rater reliability statistics. We also add a brief discussion of how selection bias was mitigated through session diversity. This clarifies the quality and representativeness of the training data. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical domain-adaptation pipeline: curate highly-rated counselor sessions in Hebrew/Arabic, fine-tune separate open-source LLMs on full conversation histories, then measure semantic/strategic alignment against gold-standard responses and non-specialized baselines. No equations, first-principles derivations, or predictions are claimed. The central result is an experimental comparison whose inputs (fine-tuning data, evaluation metrics) are independent of the reported outputs. No self-citation chains, fitted parameters renamed as predictions, or ansatzes are present in the provided abstract or described setup. The evaluation relies on external gold-standard counselor responses, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Highly effective sessions rated by professional counselors capture the key interaction patterns needed for successful de-escalation and emotional support.
Reference graph
Works this paper leans on
-
[1]
Abdelaziz Amr AbdelAziz, Mohamed Ahmed Youssef, Mamdouh Mohamed Ko- ritam, Marwa Eldeeb, and Ensaf Hussein. 2025. Arabic Mental Health Question Answering: A Multi-Task Approach with Advanced Retrieval-Augmented Gener- ation. InProceedings of The Third Arabic Natural Language Processing Conference: Shared Tasks. 192–197
2025
-
[2]
Eatedal Alabdulkreem. 2021. Prediction of depressed Arab women using their tweets.Journal of Decision Systems30, 2-3 (2021), 102–117. doi:10.1080/12460125. 2020.1859745
-
[3]
Hind Alatawi, Shadi Abudalfa, and Hamzah Luqman. 2024. Empirical Analysis for Detecting Arabic Online Suicidal Ideation.Procedia Computer Science244 (2024), 143–150. doi:10.1016/j.procs.2024.10.187 6th International Conference on AI in Computational Linguistics
-
[4]
Hassan Alhuzali, Ashwag Alasmari, and Hamad Alsaleh. 2024. MentalQA: An Annotated Arabic Corpus for Questions and Answers of Mental Healthcare.IEEE Access12 (2024), 101155–101165. doi:10.1109/ACCESS.2024.3430068
-
[5]
Abdulqader M. Almars. 2022. Attention-Based Bi-LSTM Model for Arabic De- pression Classification.Computers, Materials & Continua71, 2 (2022), 3091–3106. doi:10.32604/cmc.2022.022609
-
[6]
Salma Almouzini, Maher khemakhem, and Asem Alageel. 2019. Detecting Arabic Depressed Users from Twitter Data.Procedia Computer Science163 (2019), 257–
2019
-
[7]
doi:10.1016/j.procs.2019.12.107 16th Learning and Technology Conference 2019: Artificial Intelligence and Machine Learning: Embedding the Intelligence
- [8]
-
[9]
Baghdadi, Amer Malki, Hossam Magdy Balaha, Yousry AbdulAzeem, Mahmoud Badawy, and Mostafa Elhosseini
Nadiah A. Baghdadi, Amer Malki, Hossam Magdy Balaha, Yousry AbdulAzeem, Mahmoud Badawy, and Mostafa Elhosseini. 2022. An optimized deep learning approach for suicide detection through Arabic tweets.PeerJ Computer Science8 (23 Aug. 2022), e1070. doi:10.7717/peerj-cs.1070
-
[10]
Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. 2003. A neural probabilistic language model.Journal of machine learning research3, Feb (2003), 1137–1155
2003
-
[11]
S. Bhatt. 2024. Digital Mental Health: Role of Artificial Intelligence in Psychother- apy.Annals of Neurosciences32, 2 (2024), 117–127. doi:10.1177/09727531231221612
-
[12]
B. Chiang, Y. Law, and P. Yip. 2024. Using Discrete-Event Simulation to Model Web-Based Crisis Counseling Service Operation: Evaluation Study.JMIR Forma- tive Research8 (2024), e46823. doi:10.2196/46823
-
[13]
Avihay Chriqui and Inbal Yahav. 2021. HeBERT and HebEMO: a Hebrew BERT model and a tool for polarity analysis and emotion recognition.Soft Computing 25, 14 (2021), 9323–9335
2021
-
[14]
Shiri Daniels, Hadas Yeshayahu, Gil Zalsman, Sahar Yihia, Ella Sarel-Mahlev, and Joy Benatov. 2025. Calls with suicidality and psychological distress to a national helpline during the COVID-19 pandemic.Journal of Psychiatric Research188 (2025), 57–63. doi:10.1016/j.jpsychires.2025.05.054
-
[15]
Suzan Elmajali and Irfan Ahmad. 2024. Toward Early Detection of Depression: Detecting Depression Symptoms in Arabic Tweets Using Pretrained Transform- ers.IEEE Access12 (2024), 88134–88145. doi:10.1109/ACCESS.2024.3417821
-
[16]
Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. ChatGPT outperforms crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences120, 30 (2023), e2305016120. doi:10.1073/pnas.2305016120
-
[17]
Meytal Grimland, Joy Benatov, Hadas Yeshayahu, Daniel Izmaylov, Avi Segal, Kobi Gal, and Yossi Levi-Belz. 2024. Predicting suicide risk in real-time crisis hotline chats integrating machine learning with psychological factors: Exploring the black box.Suicide and Life-Threatening Behavior54, 3 (2024), 416–424
2024
-
[18]
Gilmar Gutierrez, Callum Stephenson, Jazmin Eadie, Kimia Asadpour, and Nazanin Alavi. 2024. Examining the Role of AI Technology in Online Men- tal Healthcare: Opportunities, Challenges, and Implications, a Mixed-Methods Review.Frontiers in Psychiatry15 (2024). doi:10.3389/fpsyt.2024.1356773
-
[19]
D. Hadar-Shoval, K. Asraf, Y. Mizrachi, Y. Haber, and Z. Elyoseph. 2024. Assessing the Alignment of Large Language Models With Human Values for Mental Health Integration: Cross-Sectional Study Using Schwartz’s Theory of Basic Values. JMIR Mental Health11 (2024), e55988. doi:10.2196/55988
-
[20]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 [cs.CL] https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [21]
-
[22]
Zainab Iftikhar, Amy Xiao, Sean Ransom, Jeff Huang, and Harini Suresh. 2025. How LLM Counselors Violate Ethical Standards in Mental Health Practice: A Practitioner-Informed Framework.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society8, 2 (Oct. 2025), 1311–1323. doi:10.1609/aies.v8i2.36632
-
[23]
Onno P Kampman, Ye Sheng Phang, Stanley Han, Michael Xing, Xinyi Hong, Hazirah Hoosainsah, Caleb Tan, Genta Indra Winata, Skyler Wang, Creighton Heaukulani, Janice Huiqin Weng, and Robert JT Morris. 2022. A Multi-Agent Dual Dialogue System to Support Mental Health Care Providers. InProceedings of the 29th International Conference on Computational Linguist...
2022
-
[24]
Kunyao Lan, Tianyi Sun, Cong Ming, Binwei Yao, Yanli Ding, Yiming Yan, Yan Li, Chao Luo, Lu Chen, Jianhua Chen, et al. 2025. Towards reliable and empathetic depression-diagnosis-oriented chats.Science China Technological Sciences68, 11 (2025), 2120406
2025
-
[25]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013/
2004
- [26]
-
[27]
Daniel M Low, Laurie Rumker, Tanya Talkar, John Torous, Guillermo Cecchi, and Satrajit S Ghosh. 2020. Natural Language Processing Reveals Vulnerable Mental Health Support Groups and Heightened Health Anxiety on Reddit During COVID-19: Observational Study.Journal of Medical Internet Research22, 10 (2020), e22635
2020
-
[28]
Ridha Mezzi, Aymen Yahyaoui, Mohamed Wassim Krir, Wadii Boulila, and Anis Koubaa. 2022. Mental Health Intent Recognition for Arabic-Speaking Patients Using the Mini International Neuropsychiatric Interview (MINI) and BERT Model. Sensors22, 3 (2022). doi:10.3390/s22030846
-
[29]
James C Overholser, Stacy R Freiheit, and Julia M DiFilippo. 1997. Emotional Distress and Substance Abuse as Risk Factors for Suicide Attempts.The Canadian Journal of Psychiatry42, 4 (1997), 402–408. doi:10.1177/070674379704200407 PMID: 9161765
-
[30]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Pierre Isabelle, Eugene Charniak, and Dekang Lin (Eds.). Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, 31...
-
[31]
Caroline Sabty, Mohamad Rasmy, Mohamed Eyad Badran, Nourhan Sakr, and Alia El Bolock. 2025. Fahmni at AraHealthQA Track 1: Multi-Agent Retrieval- Augmented Generation and Multi-Label Classification for Arabic Mental Health Q&A. InProceedings of The Third Arabic Natural Language Processing Conference: Shared Tasks. 204–212
2025
- [32]
-
[33]
Joan-Carles Surís, Nuria Parera, and Conxita Puig. 1996. Chronic illness and emotional distress in adolescence.Journal of Adolescent Health19, 2 (1996), 153–156. doi:10.1016/1054-139X(95)00231-G
-
[34]
Qingyue Wang, Yanhe Fu, Yanan Cao, Shuai Wang, Zhiliang Tian, and Liang Ding
-
[35]
arXiv preprint arXiv:2308.15022 , year=
Recursively Summarizing Enables Long-Term Dialogue Memory in Large Language Models. arXiv:2308.15022 [cs.CL] https://arxiv.org/abs/2308.15022
-
[36]
Anuradha Welivita and Pearl Pu. 2024. HEAL: A Knowledge Graph for Distress Management Conversations. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[37]
Yijun Xu, Zhaoxi Fang, Weinan Lin, Yue Jiang, Wen Jin, Prasanalakshmi Balaji, Jiangda Wang, and Ting Xia. 2025. Evaluation of large language models on mental health: from knowledge test to illness diagnosis.Frontiers in Psychiatry Volume 16 - 2025 (2025). doi:10.3389/fpsyt.2025.1646974
- [38]
-
[39]
Gil Zalsman, Yael Levy, Eliane Sommerfeld, Avi Segal, Dana Assa, Loona Ben- Dayan, Avi Valevski, and J. John Mann. 2021. Suicide-related calls to a national crisis chat hotline service during the COVID-19 pandemic and lockdown.Journal of Psychiatric Research139 (2021), 193–196. doi:10.1016/j.jpsychires.2021.05.060
-
[40]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore: Evaluating Text Generation with BERT. arXiv:1904.09675 [cs.CL] https://arxiv.org/abs/1904.09675
work page internal anchor Pith review arXiv 2020
- [41]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.