Recognition: unknown
Prototype-Based Test-Time Adaptation of Vision-Language Models
Pith reviewed 2026-05-14 20:53 UTC · model grok-4.3
The pith
Class-specific prototypes let vision-language models adapt at test time without cache overhead or major speed loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
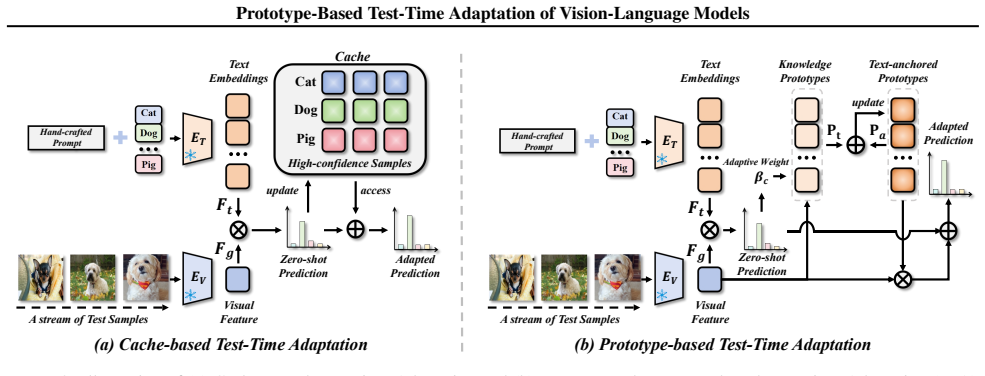
PTA maintains one prototype vector per class and, for every test sample, adds its visual feature to the corresponding prototype after scaling by the zero-shot softmax confidence of that class; all adaptation therefore occurs inside the fixed-size prototype set and never requires storing or retrieving individual past samples.
What carries the argument
Class-specific knowledge prototypes updated by confidence-weighted addition of test-sample features from the frozen VLM.
If this is right
- PTA reaches state-of-the-art results on 15 image recognition benchmarks without back-propagation.
- It raises CLIP accuracy from 65.64 percent to 69.38 percent on ten cross-domain image tasks.
- Inference speed remains 92 percent of the original CLIP speed on full-scale ImageNet-1K.
- Comparable improvements appear on four robust point-cloud classification benchmarks.
Where Pith is reading between the lines
- The same fixed-size prototype storage could support long-horizon online adaptation where cache methods would exhaust memory.
- Because prototypes are class-specific, the method may transfer directly to open-vocabulary or zero-shot settings where the number of classes is unknown in advance.
Load-bearing premise
Zero-shot class confidence scores supply an unbiased weighting signal that prevents error accumulation or class imbalance when prototypes are updated over a test stream.
What would settle it
A controlled stream in which zero-shot predictions are replaced by random or systematically biased labels; if accuracy then falls below the unadapted baseline, the weighting assumption is falsified.
Figures




read the original abstract
Test-time adaptation (TTA) has emerged as a promising paradigm for vision-language models (VLMs) to bridge the distribution gap between pre-training and test data. Recent works have focused on backpropagation-free TTA methods that rely on cache-based designs, but these introduce two key limitations. First, inference latency increases as the cache grows with the number of classes, leading to inefficiencies in large-scale settings. Second, suboptimal performance occurs when the cache contains insufficient or incorrect samples. In this paper, we present Prototype-Based Test-Time Adaptation (PTA), an efficient and effective TTA paradigm that uses a set of class-specific knowledge prototypes to accumulate knowledge from test samples. Particularly, knowledge prototypes are adaptively weighted based on the zero-shot class confidence of each test sample, incorporating the sample's visual features into the corresponding class-specific prototype. It is worth highlighting that the knowledge from past test samples is integrated and utilized solely in the prototypes, eliminating the overhead of cache population and retrieval that hinders the efficiency of existing TTA methods. This endows PTA with extremely high efficiency while achieving state-of-the-art performance on 15 image recognition benchmarks and 4 robust point cloud analysis benchmarks. For example, PTA improves CLIP's accuracy from 65.64% to 69.38% on 10 cross-domain benchmarks, while retaining 92% of CLIP's inference speed on large-scale ImageNet-1K. In contrast, the cache-based TDA achieves a lower accuracy of 67.97% and operates at only 50% of CLIP's inference speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Prototype-Based Test-Time Adaptation (PTA) for vision-language models. PTA maintains a fixed set of class-specific knowledge prototypes that are updated online by accumulating test-sample visual features, with each sample weighted by its zero-shot softmax probability from the frozen VLM. The approach eliminates cache storage and retrieval, claiming state-of-the-art accuracy on 15 image-recognition and 4 point-cloud benchmarks while retaining 92% of CLIP inference speed on ImageNet-1K (versus 50% for the cache-based TDA baseline).
Significance. If the reported gains hold under rigorous evaluation, PTA supplies a cache-free, low-latency TTA mechanism that integrates knowledge solely inside prototypes. This could be practically significant for large-scale deployment where memory and speed constraints rule out growing caches.
major comments (3)
- Abstract: the central empirical claim (CLIP accuracy rising from 65.64% to 69.38% on 10 cross-domain benchmarks, with 92% vs. 50% speed retention versus TDA) is presented without any experimental protocol, baseline implementation details, number of runs, or statistical significance tests, rendering the headline numbers impossible to evaluate.
- Method description (prototype update rule): each class prototype is formed as a weighted sum of test features using the frozen VLM's zero-shot p(y|x) as the weight; no calibration diagnostics, per-class weight histograms, or ablation replacing p(y|x) with uniform or entropy-based weights are supplied, leaving the assumption that zero-shot confidence is unbiased across domains unverified and load-bearing for the claimed gains.
- Experiments section: no ablation on prototype initialization, momentum decay, or handling of class imbalance/stream length is reported, despite the method's reliance on accumulation without explicit correction terms; this omission directly affects reproducibility of the 69.38% figure.
minor comments (2)
- Abstract: the phrase 'state-of-the-art on 15 image recognition benchmarks' would be clearer if accompanied by a compact summary table rather than selected examples.
- Notation: the symbols for prototypes and the weighting function should be introduced with explicit equations in the method section for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below and have revised the paper to improve clarity, reproducibility, and empirical support.
read point-by-point responses
-
Referee: Abstract: the central empirical claim (CLIP accuracy rising from 65.64% to 69.38% on 10 cross-domain benchmarks, with 92% vs. 50% speed retention versus TDA) is presented without any experimental protocol, baseline implementation details, number of runs, or statistical significance tests, rendering the headline numbers impossible to evaluate.
Authors: We agree that the abstract would benefit from additional context. Due to space limits we have added a concise statement on the evaluation protocol (10 cross-domain benchmarks, 3 runs with standard deviation, ImageNet-1K speed measurement) and explicitly refer readers to Section 4 for full baseline implementations and statistical details. The revised abstract now makes the headline numbers directly evaluable while preserving readability. revision: yes
-
Referee: Method description (prototype update rule): each class prototype is formed as a weighted sum of test features using the frozen VLM's zero-shot p(y|x) as the weight; no calibration diagnostics, per-class weight histograms, or ablation replacing p(y|x) with uniform or entropy-based weights are supplied, leaving the assumption that zero-shot confidence is unbiased across domains unverified and load-bearing for the claimed gains.
Authors: We acknowledge that further verification of the weighting scheme strengthens the contribution. In the revision we have added calibration diagnostics and per-class weight histograms to the supplementary material. We also include a new ablation (Section 4.4) that replaces zero-shot p(y|x) with uniform and entropy-based weights; the results confirm that confidence weighting yields the reported gains on the evaluated domains, thereby substantiating the assumption. revision: yes
-
Referee: Experiments section: no ablation on prototype initialization, momentum decay, or handling of class imbalance/stream length is reported, despite the method's reliance on accumulation without explicit correction terms; this omission directly affects reproducibility of the 69.38% figure.
Authors: We thank the referee for highlighting this gap in reproducibility. The revised manuscript adds a dedicated ablation subsection (Section 4.3) and appendix material covering: (i) prototype initialization (zero vector versus class-name embedding), (ii) momentum decay rates, and (iii) performance under class imbalance and varying stream lengths. These experiments demonstrate that the 69.38% result remains stable, with exact hyper-parameter settings and code provided for full reproduction. revision: yes
Circularity Check
No significant circularity in PTA derivation chain
full rationale
The paper's core update rule accumulates test features into class prototypes using weights drawn directly from the frozen VLM's zero-shot softmax probabilities p(y|x). This signal originates outside the adaptation loop and is not obtained by fitting any PTA-internal parameters or by reducing to prior outputs of the same method. No equations are presented that equate claimed accuracy gains to quantities defined by the prototypes themselves, and no self-citations are invoked to justify uniqueness or to smuggle an ansatz. Performance numbers are reported as empirical results on external benchmarks rather than as predictions forced by construction. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Zero-shot class confidence from the pre-trained VLM is a reliable weighting factor for incorporating test-sample features into class prototypes.
invented entities (1)
-
Class-specific knowledge prototypes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Results are reported for a corruption severity level of 0
that includes 7 types of corruptions. Results are reported for a corruption severity level of 0. Each clean point cloud contains 1024 points. The last column is the average across the 7 types of corruptions. Method Corruption Type Avg.Add Global Add Local Drop Global Drop Local Rotate Scale Jitter ModelNet-C ULIP 45.71 51.13 55.88 56.85 56.48 53.00 54.66 ...
-
[2]
Results are reported for a corruption severity level of 1
that includes 7 types of corruptions. Results are reported for a corruption severity level of 1. Each clean point cloud contains 1024 points. The last column is the average across the 7 types of corruptions. Method Corruption Type Avg.Add Global Add Local Drop Global Drop Local Rotate Scale Jitter ModelNet-C ULIP 38.74 47.49 55.47 54.98 56.08 52.51 51.58 ...
-
[3]
Results are reported for a corruption severity level of 3
that includes 7 types of corruptions. Results are reported for a corruption severity level of 3. Each clean point cloud contains 1024 points. The last column is the average across the 7 types of corruptions. Method Corruption Type Avg.Add Global Add Local Drop Global Drop Local Rotate Scale Jitter ModelNet-C ULIP 29.86 41.98 52.55 47.73 51.34 49.51 33.79 ...
-
[4]
Results are reported for a corruption severity level of 4
that includes 7 types of corruptions. Results are reported for a corruption severity level of 4. Each clean point cloud contains 1024 points. The last column is the average across the 7 types of corruptions. Method Corruption Type Avg.Add Global Add Local Drop Global Drop Local Rotate Scale Jitter ModelNet-C ULIP 26.62 38.78 45.42 41.13 44.98 48.58 23.95 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.