Recognition: unknown
UHR-DETR: Efficient End-to-End Small Object Detection for Ultra-High-Resolution Remote Sensing Imagery
Pith reviewed 2026-05-09 22:11 UTC · model grok-4.3
The pith
UHR-DETR detects small objects in ultra-high-resolution remote sensing images by focusing computation on key regions rather than processing entire scenes uniformly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UHR-DETR is an efficient transformer-based detector for ultra-high-resolution remote sensing imagery that uses a Coverage-Maximizing Sparse Encoder to dynamically allocate limited compute to the most informative high-resolution regions, thereby maximizing small-object coverage while minimizing spatial redundancy, and a Global-Local Decoupled Decoder that fuses macroscopic scene context with microscopic object details to reduce semantic ambiguity and scene fragmentation.
What carries the argument
Coverage-Maximizing Sparse Encoder, which dynamically identifies and prioritizes high-resolution image regions containing small objects to allocate finite computational resources for maximum coverage at minimal redundancy.
If this is right
- Full-resolution ultra-high-resolution images can be analyzed end-to-end without downsampling or memory overflow on consumer GPUs.
- Small-object detection accuracy improves by 2.8 percent mAP on the STAR benchmark while inference runs ten times faster than sliding-window approaches.
- Semantic ambiguities arising from scene fragmentation are reduced by combining global context with local detail in the decoder.
- The same model architecture works on multiple ultra-high-resolution remote sensing datasets including STAR and SODA-A under identical hardware constraints.
Where Pith is reading between the lines
- The sparse allocation approach could scale object detection to even larger image sizes in domains such as aerial surveillance or large-scale mapping.
- Decoupling global and local processing in the decoder offers a template for handling multi-scale features in other transformer-based vision tasks.
- If the encoder generalizes, practitioners may shift from specialized high-memory hardware to standard GPUs for routine remote sensing analysis.
- Further tests on scenes with denser small-object clusters or lower contrast would clarify the limits of coverage maximization.
Load-bearing premise
The sparse encoder can reliably locate every important high-resolution region that contains small objects across varied scenes without missing critical instances.
What would settle it
Running UHR-DETR on a new ultra-high-resolution dataset with small objects placed in patterns that the encoder consistently overlooks, and measuring whether its mean average precision then falls below that of a standard sliding-window baseline.
Figures

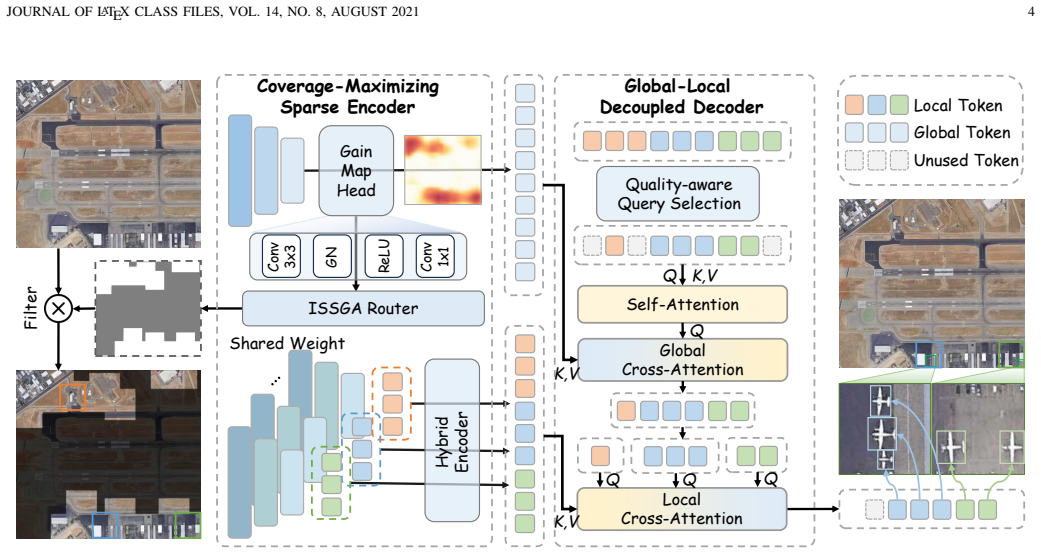
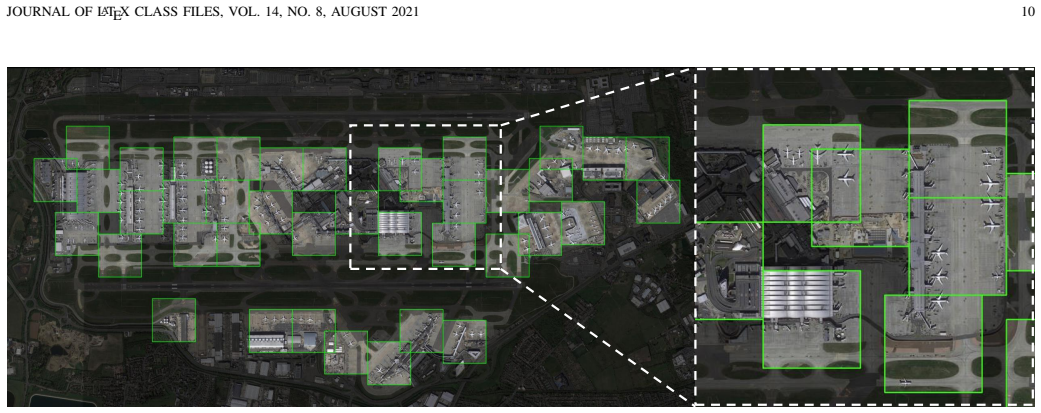


read the original abstract
Ultra-High-Resolution (UHR) imagery has become essential for modern remote sensing, offering unprecedented spatial coverage. However, detecting small objects in such vast scenes presents a critical dilemma: retaining the original resolution for small objects causes prohibitive memory bottlenecks. Conversely, conventional compromises like image downsampling or patch cropping either erase small objects or destroy context. To break this dilemma, we propose UHR-DETR, an efficient end-to-end transformer-based detector designed for UHR imagery. First, we introduce a Coverage-Maximizing Sparse Encoder that dynamically allocates finite computational resources to informative high-resolution regions, ensuring maximum object coverage with minimal spatial redundancy. Second, we design a Global-Local Decoupled Decoder. By integrating macroscopic scene awareness with microscopic object details, this module resolves semantic ambiguities and prevents scene fragmentation. Extensive experiments on the UHR imagery datasets (e.g., STAR and SODA-A) demonstrate the superiority of UHR-DETR under strict hardware constraints (e.g., a single 24GB RTX 3090). It achieves a 2.8\% mAP improvement while delivering a 10$\times$ inference speedup compared to standard sliding-window baselines on the STAR dataset. Our codes and models will be available at https://github.com/Li-JingFang/UHR-DETR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UHR-DETR, a transformer-based end-to-end detector for small objects in ultra-high-resolution remote sensing imagery. It introduces a Coverage-Maximizing Sparse Encoder that dynamically allocates computational resources to informative high-resolution regions for maximum object coverage with minimal redundancy, and a Global-Local Decoupled Decoder that combines macroscopic scene context with microscopic object details to reduce semantic ambiguity. Experiments on the STAR and SODA-A datasets report a 2.8% mAP gain and 10× inference speedup versus sliding-window baselines under a single 24 GB RTX 3090 constraint.
Significance. If the performance claims hold after verification, the approach could meaningfully advance practical small-object detection in UHR remote-sensing scenes by mitigating memory bottlenecks without sacrificing coverage, offering a concrete efficiency-accuracy trade-off for hardware-limited deployments.
major comments (2)
- [Coverage-Maximizing Sparse Encoder description and experimental validation] The central claims of 2.8% mAP improvement and 10× speedup on STAR rest on the Coverage-Maximizing Sparse Encoder's premise of complete coverage of informative regions containing small objects. No quantitative coverage metric (e.g., recall of ground-truth small-object instances inside selected patches versus the full image, or saliency-threshold sensitivity analysis) is reported to bound the risk of omitting low-saliency instances across scene variations. This directly affects both the mAP and speedup figures.
- [Experiments and results] The experimental section reports aggregate gains on STAR and SODA-A but provides insufficient detail on exact baseline implementations (including sliding-window patch size, overlap, and post-processing), full ablation results isolating the Sparse Encoder and Decoupled Decoder contributions, error bars across multiple runs, or statistical significance tests. These omissions make it difficult to assess whether the reported margins are robust under the stated 24 GB hardware constraint.
minor comments (1)
- [Abstract] The abstract states that code will be released but does not specify the exact license or repository structure; adding this would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will incorporate revisions to improve the clarity and rigor of the manuscript.
read point-by-point responses
-
Referee: [Coverage-Maximizing Sparse Encoder description and experimental validation] The central claims of 2.8% mAP improvement and 10× speedup on STAR rest on the Coverage-Maximizing Sparse Encoder's premise of complete coverage of informative regions containing small objects. No quantitative coverage metric (e.g., recall of ground-truth small-object instances inside selected patches versus the full image, or saliency-threshold sensitivity analysis) is reported to bound the risk of omitting low-saliency instances across scene variations. This directly affects both the mAP and speedup figures.
Authors: We agree that explicitly quantifying coverage would strengthen the validation of the Sparse Encoder. In the revised manuscript, we will add a coverage analysis reporting the recall of ground-truth small-object instances contained within the dynamically selected high-resolution patches relative to the full image. We will also include a saliency-threshold sensitivity study across multiple scenes to demonstrate that the risk of omitting low-saliency objects remains low and does not undermine the reported mAP gains or speedup. These additions will be presented with supporting figures or tables. revision: yes
-
Referee: [Experiments and results] The experimental section reports aggregate gains on STAR and SODA-A but provides insufficient detail on exact baseline implementations (including sliding-window patch size, overlap, and post-processing), full ablation results isolating the Sparse Encoder and Decoupled Decoder contributions, error bars across multiple runs, or statistical significance tests. These omissions make it difficult to assess whether the reported margins are robust under the stated 24 GB hardware constraint.
Authors: We acknowledge the need for greater experimental transparency. In the revision, we will expand the experimental section to specify the exact sliding-window baseline settings (patch size, overlap ratio, and post-processing such as NMS), provide full ablation tables isolating the Sparse Encoder and Decoupled Decoder, report error bars from multiple runs with different random seeds, and include statistical significance tests (e.g., paired t-tests) confirming the improvements. All results will remain under the single 24 GB RTX 3090 constraint to ensure fair comparison. revision: yes
Circularity Check
No significant circularity; empirical claims rest on dataset comparisons
full rationale
The paper introduces an architectural proposal (Coverage-Maximizing Sparse Encoder + Global-Local Decoupled Decoder) for UHR small-object detection and reports empirical gains (2.8% mAP, 10× speedup) on public benchmarks (STAR, SODA-A) under fixed hardware. No equations, uniqueness theorems, or predictions are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claims are falsifiable via external baselines and do not rely on internal parameter renaming or ansatz smuggling. This is the expected non-circular outcome for an applied CV architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ffca-yolo for small object detection in remote sensing images,
Y . Zhang, M. Ye, G. Zhu, Y . Liu, P. Guo, and J. Yan, “Ffca-yolo for small object detection in remote sensing images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–15, 2024
2024
-
[2]
Boundary- aware feature fusion with dual-stream attention for remote sensing small object detection,
J. Song, M. Zhou, J. Luo, H. Pu, Y . Feng, X. Wei, and W. Jia, “Boundary- aware feature fusion with dual-stream attention for remote sensing small object detection,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–13, 2025
2025
-
[3]
STAR: A first-ever dataset and a large-scale bench- mark for scene graph generation in large-size satellite imagery
Y . Li, L. Wang, T. Wang, X. Yang, J. Luo, Q. Wang, Y . Deng, W. Wang, X. Sun, H. Liet al., “STAR: A first-ever dataset and a large-scale bench- mark for scene graph generation in large-size satellite imagery.”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 1832–1849, 2025
2025
-
[4]
Object detection in aerial images: A large-scale benchmark and challenges,
J. Ding, N. Xue, G.-S. Xia, X. Bai, W. Yang, M. Y . Yang, S. Belongie, J. Luo, M. Datcu, M. Pelilloet al., “Object detection in aerial images: A large-scale benchmark and challenges,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 11, pp. 7778–7796, 2021
2021
-
[5]
GeoLLaV A-8k: Scaling remote-sensing multimodal large language models to 8k resolution,
F. Wang, M. Chen, Y . Li, D. Wang, H. Wang, Z. Guo, Z. Wang, S. Boqi, L. Lan, Y . Wang, H. Wang, W. Yang, B. Du, and J. Zhang, “GeoLLaV A-8k: Scaling remote-sensing multimodal large language models to 8k resolution,” inAdvances in Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id= LTgUInLTbP
2025
-
[6]
Fovea: Foveated image magnification for autonomous navigation,
C. Thavamani, M. Li, N. Cebron, and D. Ramanan, “Fovea: Foveated image magnification for autonomous navigation,” inIEEE International Conference on Computer Vision, 2021, pp. 15 519–15 528
2021
-
[7]
Learning to zoom and unzoom,
C. Thavamani, M. Li, F. Ferroni, and D. Ramanan, “Learning to zoom and unzoom,” inIEEE Conference on Computer Vision and Pattern Recognition, 2023, pp. 5086–5095
2023
-
[8]
Adaptive image zoom-in with bounding box transformation for uav object detection,
T. Wang, C. Lin, C. Tang, J. Zhou, D. Xiong, J. Li, J. Zhao, and J. Lv, “Adaptive image zoom-in with bounding box transformation for uav object detection,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 233, pp. 452–466, 2026
2026
-
[9]
Clustered object detec- tion in aerial images,
F. Yang, H. Fan, P. Chu, E. Blasch, and H. Ling, “Clustered object detec- tion in aerial images,” inIEEE International Conference on Computer Vision, 2019, pp. 8310–8319
2019
-
[10]
‘skimming-perusal’ de- tection: A simple object detection baseline in gigapixel-level images,
Z. Zhang, W. Xue, K. Zhang, and S. Chen, “‘skimming-perusal’ de- tection: A simple object detection baseline in gigapixel-level images,” inIEEE International Conference on Multimedia and Expo, 2023, pp. 2471–2476
2023
-
[11]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean Conference on Computer Vision. Springer, 2014, pp. 740–755
2021
-
[12]
Detrs beat yolos on real-time object detection,
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, and J. Chen, “Detrs beat yolos on real-time object detection,” inIEEE Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 965–16 974
2024
-
[13]
To- wards large-scale small object detection: Survey and benchmarks,
G. Cheng, X. Yuan, X. Yao, K. Yan, Q. Zeng, X. Xie, and J. Han, “To- wards large-scale small object detection: Survey and benchmarks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 13 467–13 488, 2023
2023
-
[14]
Deformable detr: Deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” in International Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/forum?id=gZ9hCDWe6ke
2021
-
[15]
Dynamic adaptive region transformer for tiny-object detection in remote sensing,
A. Siddique, L. Zhengzhou, A. Azeem, Z. Yuting, and Y . Li, “Dynamic adaptive region transformer for tiny-object detection in remote sensing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1– 18, 2025
2025
-
[16]
Cross- dino: Cross the deep mlp and transformer for small object detection,
G. Cao, W. Huang, X. Lan, J. Zhang, D. Jiang, and Y . Wang, “Cross- dino: Cross the deep mlp and transformer for small object detection,” IEEE Transactions on Multimedia, vol. 27, pp. 7369–7379, 2025
2025
-
[17]
D3R-DETR: DETR with dual-domain density refinement for tiny object detection in aerial images,
Z. Wen, Z. Yang, X. Bao, L. Zhang, X. Xiang, W. Li, and Y . Liu, “D3R-DETR: DETR with dual-domain density refinement for tiny object detection in aerial images,” 2026. [Online]. Available: https://arxiv.org/abs/2601.02747
-
[18]
Detrs with collaborative hybrid assign- ments training,
Z. Zong, G. Song, and Y . Liu, “Detrs with collaborative hybrid assign- ments training,” inIEEE International Conference on Computer Vision, 2023, pp. 6748–6758
2023
-
[19]
FCOS: Fully convolutional one- stage object detection,
Z. Tian, C. Shen, H. Chen, and T. He, “FCOS: Fully convolutional one- stage object detection,” inIEEE International Conference on Computer Vision, 2019, pp. 9626–9635
2019
-
[20]
Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection,
S. Zhang, C. Chi, Y . Yao, Z. Lei, and S. Z. Li, “Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection,” inIEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 9759–9768
2020
-
[21]
DQ-DETR: DETR with dynamic query for tiny object detection,
Y .-X. Huang, H.-I. Liu, H.-H. Shuai, and W.-H. Cheng, “DQ-DETR: DETR with dynamic query for tiny object detection,” inEuropean Conference on Computer Vision. Springer, 2024, p. 290–305
2024
-
[22]
Density-aware detr with dynamic query for end-to-end tiny object detection,
X. Ye, C. Xu, H. Zhu, F. Xu, H. Zhang, and W. Yang, “Density-aware detr with dynamic query for end-to-end tiny object detection,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 18, pp. 13 554–13 569, 2025
2025
-
[23]
Dome-detr: Detr with density-oriented feature-query manipulation for efficient tiny object detection,
Z. Hu, P. Wu, J. Chen, H. Zhu, Y . Wang, Y . Peng, H. Li, and X. Sun, “Dome-detr: Detr with density-oriented feature-query manipulation for efficient tiny object detection,” inProceedings of the 33rd ACM Inter- national Conference on Multimedia, 2025, pp. 101–110
2025
-
[24]
Generalized Small Object Detection:A Point-Prompted Paradigm and Benchmark
H. Zhu, W. Yang, G. Yang, C. Xu, R. Zhang, F. Xu, H. Zhang, and G.-S. Xia, “Generalized small object detection:a point-prompted paradigm and benchmark,” 2026. [Online]. Available: https://arxiv.org/abs/2604.02773
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Detection and tracking meet drones challenge,
P. Zhu, L. Wen, D. Du, X. Bian, H. Fan, Q. Hu, and H. Ling, “Detection and tracking meet drones challenge,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 11, pp. 7380–7399, 2021
2021
-
[26]
The unmanned aerial vehicle benchmark: Object detection and tracking,
D. Du, Y . Qi, H. Yu, Y . Yang, K. Duan, G. Li, W. Zhang, Q. Huang, and Q. Tian, “The unmanned aerial vehicle benchmark: Object detection and tracking,” inEuropean Conference on Computer Vision, 2018, pp. 370–386
2018
-
[27]
Panda: A gigapixel-level human- centric video dataset,
X. Wang, X. Zhang, Y . Zhu, Y . Guo, X. Yuan, L. Xiang, Z. Wang, G. Ding, D. Brady, Q. Daiet al., “Panda: A gigapixel-level human- centric video dataset,” inIEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 3268–3278
2020
-
[28]
Object detection using clustering algorithm adaptive searching regions in aerial images,
Y . Wang, Y . Yang, and X. Zhao, “Object detection using clustering algorithm adaptive searching regions in aerial images,” inEuropean Con- ference on Computer Vision Workshops. Springer, 2020, p. 651–664
2020
-
[29]
Speed up object detection on gigapixel-level images with patch arrangement,
J. Fan, H. Liu, W. Yang, J. See, A. Zhang, and W. Lin, “Speed up object detection on gigapixel-level images with patch arrangement,” in IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 4643–4653
2022
-
[30]
Density map guided object detection in aerial images,
C. Li, T. Yang, S. Zhu, C. Chen, and S. Guan, “Density map guided object detection in aerial images,” inIEEE Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 737–746
2020
-
[31]
Saccadedet: A novel dual-stage architecture for rapid and accurate detection in gigapixel images,
W. Li, R. Zhang, H. Lin, Y . Guo, C. Ma, and X. Yang, “Saccadedet: A novel dual-stage architecture for rapid and accurate detection in gigapixel images,” inJoint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2024, p. 392–408
2024
-
[32]
Towards real-time object detection in gigapixel-level video,
K. Chen, Z. Wang, X. Wang, D. Gong, L. Yu, Y . Guo, and G. Ding, “Towards real-time object detection in gigapixel-level video,”Neuro- computing, vol. 477, pp. 14–24, 2022
2022
-
[33]
Salisa: Saliency-based input sampling for efficient video object detection,
B. Ehteshami Bejnordi, A. Habibian, F. Porikli, and A. Ghodrati, “Salisa: Saliency-based input sampling for efficient video object detection,” in European Conference on Computer Vision. Springer, 2022, pp. 300– 316
2022
-
[34]
Sparseformer: Detecting objects in HRW shots via sparse vision transformer,
W. Li, Y . Guo, J. Zheng, H. Lin, C. Ma, L. Fang, and X. Yang, “Sparseformer: Detecting objects in HRW shots via sparse vision transformer,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, p. 4851–4860
2024
-
[35]
GigaMoE: Sparsity-guided mixture of experts for efficient gigapixel object detection,
X. Li, W. Li, Y . Wang, C. Lyu, H. Lin, G. Ding, and Y . Guo, “GigaMoE: Sparsity-guided mixture of experts for efficient gigapixel object detection,” inAAAI Conference on Artificial Intelligence, vol. 40, no. 21, 2026, pp. 17 553–17 561
2026
-
[36]
Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images,
B. Du, Y . Huang, J. Chen, and D. Huang, “Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images,” inIEEE Conference on Computer Vision and Pattern Recognition, 2023, pp. 13 435–13 444
2023
-
[37]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[38]
Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection,
X. Li, W. Wang, L. Wu, S. Chen, X. Hu, J. Li, J. Tang, and J. Yang, “Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 21 002–21 012
2020
-
[39]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, 2017, p. 6000–6010
2017
-
[40]
DAB-DETR: Dynamic anchor boxes are better queries for DETR,
S. Liu, F. Li, H. Zhang, X. Yang, X. Qi, H. Su, J. Zhu, and L. Zhang, “DAB-DETR: Dynamic anchor boxes are better queries for DETR,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=oMI9PjOb9Jl
2022
-
[41]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137– 1149, 2016
2016
-
[42]
YOLOX: Exceeding yolo series in 2021,
Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “YOLOX: Exceeding yolo series in 2021,” 2021. [Online]. Available: https://arxiv.org/abs/2107. 08430
2021
-
[44]
MMDetection: Open mmlab detection toolbox and benchmark,
[Online]. Available: https://arxiv.org/abs/1906.07155
-
[45]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015
2015
-
[46]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in International Conference on Learning Representations, 2019. [Online]. Available: https://openreview.net/forum?id=Bkg6RiCqY7
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.