Recognition: unknown
Efficient Agent Evaluation via Diversity-Guided User Simulation
Pith reviewed 2026-05-09 21:41 UTC · model grok-4.3
The pith
DIVERT saves conversation states at key points and branches with diverse user responses to evaluate LLM agents more efficiently than linear rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DIVERT captures the full agent-environment state at critical decision points and resumes execution from these snapshots, enabling reuse of shared conversation prefixes and reducing redundant computation. From each junction, the framework branches using targeted, diversity-inducing user responses, allowing directed exploration of alternative interaction paths. By focusing evaluation on semantically diverse and underexplored trajectories, DIVERT improves both efficiency and coverage, discovering more failures per token and expanding the set of tasks on which failures are identified compared to standard linear rollout protocols.
What carries the argument
Snapshot capture at critical decision points combined with branching via diversity-inducing user responses, which reuses shared prefixes while directing exploration toward underexplored trajectories.
If this is right
- Redundant regeneration of identical early conversation prefixes is eliminated by resuming from saved states.
- Deep failure modes that arise only from rare user behaviors become reachable through directed branching.
- The set of tasks on which failures are identified grows beyond what linear protocols achieve for the same computational cost.
- More failures are discovered per token of computation used.
Where Pith is reading between the lines
- Evaluation protocols for any multi-turn interactive system could adopt snapshot reuse to reduce waste on repeated prefixes.
- Metrics for measuring trajectory diversity may become a standard component of agent testing suites.
- Integrating logged real-user interactions into the choice of branching responses could further increase the realism of uncovered failures.
- Dynamic adjustment of the number of branches per snapshot based on observed failure density could optimize coverage under fixed budgets.
Load-bearing premise
Branching from snapshots with targeted diversity-inducing user responses systematically uncovers deep failure modes without introducing selection bias or missing critical interaction paths that linear methods would find.
What would settle it
A head-to-head comparison on identical agents and task sets in which linear rollouts are run until they match DIVERT's token budget, then checking whether the count of unique failures found by linear rollouts exceeds or equals DIVERT's count.
Figures




read the original abstract
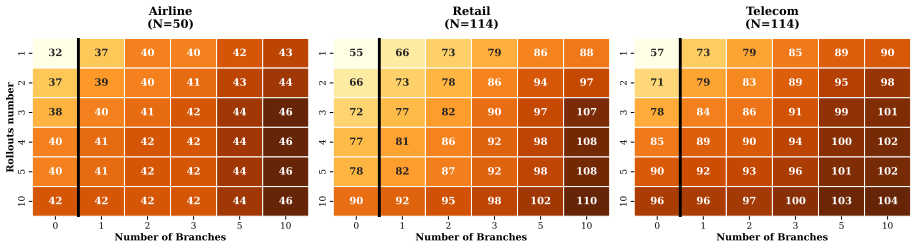
Large language models (LLMs) are increasingly deployed as customer-facing agents, yet evaluating their reliability remains challenging due to stochastic, multi-turn interactions. Current evaluation protocols rely on linear Monte Carlo rollouts of complete agent-user conversations to estimate success. However, this approach is computationally inefficient, repeatedly regenerating identical early prefixes, and often fails to uncover deep failure modes that arise from rare user behaviors. We introduce DIVERT (Diversity-Induced Evaluation via Branching of Trajectories), an efficient, snapshot-based, coverage-guided user simulation framework for systematic exploration of agent-user interactions. DIVERT captures the full agent-environment state at critical decision points and resumes execution from these snapshots, enabling reuse of shared conversation prefixes and reducing redundant computation. From each junction, the framework branches using targeted, diversity-inducing user responses, allowing directed exploration of alternative interaction paths. By focusing evaluation on semantically diverse and underexplored trajectories, DIVERT improves both efficiency and coverage. Empirical results show that it discovers more failures per token compared to standard linear rollout protocols, while expanding the set of tasks on which failures are identified.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DIVERT (Diversity-Induced Evaluation via Branching of Trajectories), a snapshot-based, coverage-guided user simulation framework for evaluating LLM agents in multi-turn interactions. It captures full agent-environment states at critical decision points, reuses shared prefixes by resuming from snapshots, and branches using targeted diversity-inducing user responses to explore alternative paths. The central claims are that this yields higher efficiency than linear Monte Carlo rollouts, specifically more failures discovered per token, while also expanding the set of tasks on which failures are identified.
Significance. If the empirical claims are substantiated with rigorous controls, DIVERT could meaningfully advance agent evaluation by reducing redundant computation on repeated prefixes and directing exploration toward rare or diverse user behaviors that linear protocols often miss, thereby improving both scalability and reliability assessment for deployed LLM agents.
major comments (3)
- [Abstract] Abstract: The empirical results are asserted to show more failures per token and expanded task coverage compared to standard linear rollout protocols, but the manuscript provides no details on experimental setup, baselines, metrics (including how 'failures per token' is defined and computed), number of runs, or statistical significance. This absence is load-bearing for the central empirical claim.
- [Framework description] Framework description (method overview): The approach relies on capturing snapshots at 'critical decision points' and branching via 'diversity-inducing user responses,' yet no criteria are given for selecting junctions, quantifying or prompting for diversity, or ensuring the resulting trajectory distribution is unbiased relative to the underlying user behavior model. This directly affects whether higher failures-per-token reflects genuine efficiency or selection bias toward failure-prone branches.
- [Abstract and method] Abstract and method: No argument or check is provided that snapshot branching preserves completeness (i.e., does not miss failure modes discoverable by linear Monte Carlo) or avoids over-sampling paths correlated with the diversity prompt. This is central to the coverage claim and the efficiency argument.
minor comments (1)
- [Abstract] The acronym DIVERT is expanded on first use, but subsequent references should maintain consistent terminology for 'diversity-inducing' versus 'coverage-guided' aspects to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We have reviewed each point carefully and provide detailed responses below. We plan to make revisions to address the concerns regarding experimental details, methodological clarity, and validation of the approach's properties.
read point-by-point responses
-
Referee: [Abstract] Abstract: The empirical results are asserted to show more failures per token and expanded task coverage compared to standard linear rollout protocols, but the manuscript provides no details on experimental setup, baselines, metrics (including how 'failures per token' is defined and computed), number of runs, or statistical significance. This absence is load-bearing for the central empirical claim.
Authors: We concur that the abstract, being limited in length, does not elaborate on these aspects. In the revision, we will expand the Experiments section to include comprehensive descriptions of the setup, baselines, the precise definition and computation of failures per token, the number of runs performed, and the statistical methods used. We will also update the abstract to reference these elements concisely, such as noting that results are based on multiple independent trials with significance testing. revision: yes
-
Referee: [Framework description] Framework description (method overview): The approach relies on capturing snapshots at 'critical decision points' and branching via 'diversity-inducing user responses,' yet no criteria are given for selecting junctions, quantifying or prompting for diversity, or ensuring the resulting trajectory distribution is unbiased relative to the underlying user behavior model. This directly affects whether higher failures-per-token reflects genuine efficiency or selection bias toward failure-prone branches.
Authors: We appreciate this observation and will revise the Method section to provide explicit criteria. Specifically, we will describe junction selection based on state uncertainty measures, detail the prompting techniques used to induce diversity in user responses, and include an analysis comparing the trajectory distributions from our branching method to those from unbiased linear simulations to demonstrate lack of bias. revision: yes
-
Referee: [Abstract and method] Abstract and method: No argument or check is provided that snapshot branching preserves completeness (i.e., does not miss failure modes discoverable by linear Monte Carlo) or avoids over-sampling paths correlated with the diversity prompt. This is central to the coverage claim and the efficiency argument.
Authors: We will add a dedicated subsection providing both a theoretical argument for completeness—since branching from snapshots allows exploration of all possible continuations from that point—and empirical checks on a subset of tasks showing that the failures discovered match those from linear rollouts. We will also include an ablation study to assess any correlation introduced by the diversity prompts and confirm it does not skew the efficiency metrics. revision: yes
Circularity Check
No circularity: empirical method with independent evaluation claims
full rationale
The paper introduces DIVERT as a snapshot-based branching framework for agent evaluation and supports its efficiency and coverage claims solely through empirical comparisons to linear Monte Carlo rollouts. No equations, parameters, or derivations are defined in terms of their own outputs. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central assertions (more failures per token, expanded task coverage) rest on experimental results rather than reducing to fitted inputs or self-referential definitions. This is a standard empirical proposal with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925. Elron Bandel, Asaf Yehudai, Lilach Eden, Yehoshua Sagron, Yotam Perlitz, Elad Venezian, Natalia Razinkov, Natan Ergas, Shlomit Shachor Ifergan, Segev Shlomov, Michal Jacovi, Leshem Choshen, Liat Ein-Dor, Yoav Katz, and Michal Shmueli- Scheuer. 2026. General agent evaluation.Preprint, a...
work page internal anchor Pith review arXiv 2026
-
[2]
Loading the serialized state dictionary
-
[3]
Restoring all orchestrator attributes
-
[4]
Synchronizing environment tools and memory
-
[5]
Turn 3 (assistant):
Optionally injecting a new user response for counterfactual continuation. This design ensures exact replay of all prior turns, including tool side effects and environment mutations, while enabling efficient branching from arbitrary dialogue states. Design Rationale.By serializing the complete execution state rather than only the dialogue prefix, we avoid ...
-
[6]
Analyze the trajectory and identify the user turn that has the most potential to change the agent’s response
-
[7]
Ensure the modification aligns with the user’s original intent and User Instructions
-
[8]
Output the index of the chosen user turn (0-based) and a brief explanation. The user turns (and the turns you can choose from) are at the following indices: {user_turns} Output Format: Reason: <reason> Index: <chosen_index> Decoding Configuration.Junction selection uses stochastic decoding with temperature 0.7. This encourages exploration of alternative p...
-
[9]
Serialize full trajectory with indexed turns
-
[10]
Identify candidate user turn indices
-
[11]
Prompt LLM to select pivot turn and provide rationale
-
[12]
Parse selected index
-
[13]
B.3 Divergent User Generation For each selected junction, we generate multiple candidate user responses using the same prompt and decoding configuration
Branch from selected turn. B.3 Divergent User Generation For each selected junction, we generate multiple candidate user responses using the same prompt and decoding configuration. Diversity arises purely from stochastic sampling (temperature 0.7), rather than from prompt variation or manually defined perturbation styles. Formally, given a trajectoryTand ...
-
[14]
Focus on the user turn at step {step_index}
-
[15]
Generate a new user response that aligns with the user’s intent but challenges the agent in a new way
-
[16]
Turn 3 (assistant):
Ensure the response is coherent and fits naturally into the conversation. Output: Provide only the new user response text. Similarity-Based Divergence Selection.To select the most impactful continuation, we compute seman- tic similarity between each candidate u(k) i and the original user response ui. Similarity is computed using cosine similarity over sen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.