Recognition: unknown
Job Skill Extraction via LLM-Centric Multi-Module Framework
Pith reviewed 2026-05-09 21:57 UTC · model grok-4.3
The pith
SRICL framework improves LLM skill extraction from job ads by retrieving examples, fine-tuning, and verifying outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SRICL constructs format-constrained prompts by retrieving in-domain annotated sentences and skill definitions from ESCO, applies supervised fine-tuning to align output behavior, and runs a deterministic verifier that checks pairing, non-overlap, and BIO legality with minimal retries; this combination yields substantial STRICT-F1 gains over GPT-3.5 prompting baselines while sharply cutting invalid tags and hallucinated spans on six public corpora across sectors and languages.
What carries the argument
SRICL, the LLM-centric pipeline that pairs semantic retrieval from ESCO for prompt construction with in-context learning, supervised fine-tuning, and a deterministic verifier to enforce valid span tags.
If this is right
- Substantial STRICT-F1 gains over GPT-3.5 prompting baselines on six span-labeled job-ad corpora.
- Sharp reduction in invalid tags and hallucinated spans.
- Better handling of coordination structures and long-tail skill terms through constrained prompts.
- Dependable sentence-level deployment in low-resource and multi-domain settings.
- Minimal retries needed once the verifier enforces BIO legality, pairing, and non-overlap.
Where Pith is reading between the lines
- The same retrieval-plus-verifier pattern could be tested on other span-extraction tasks such as medical entity recognition where boundary precision is critical.
- If the verifier alone accounts for much of the error reduction, simpler pipelines without full supervised fine-tuning might be explored for faster deployment.
- Broader coverage could come from swapping or augmenting ESCO with other skill taxonomies in new labor markets.
- Real-time job-market dashboards might become feasible if the reduced hallucination rate holds at scale on streaming ad text.
Load-bearing premise
The specific combination of ESCO retrieval, in-context learning, supervised fine-tuning, and the verifier will stabilize outputs and generalize beyond the six tested corpora without further domain adjustments.
What would settle it
Evaluating SRICL on a fresh collection of job-ad sentences from an unseen sector or language and finding no STRICT-F1 improvement or persistent hallucinations and invalid tags would show the claimed stabilization does not hold.
Figures




read the original abstract
Span-level skill extraction from job advertisements underpins candidate-job matching and labor-market analytics, yet generative large language models (LLMs) often yield malformed spans, boundary drift, and hallucinations, especially with long-tail terms and cross-domain shift. We present SRICL, an LLM-centric framework that combines semantic retrieval (SR), in-context learning (ICL), and supervised fine-tuning (SFT) with a deterministic verifier. SR pulls in-domain annotated sentences and definitions from ESCO to form format-constrained prompts that stabilize boundaries and handle coordination. SFT aligns output behavior, while the verifier enforces pairing, non-overlap, and BIO legality with minimal retries. On six public span-labeled corpora of job-ad sentences across sectors and languages, SRICL achieves substantial STRICT-F1 improvements over GPT-3.5 prompting baselines and sharply reduces invalid tags and hallucinated spans, enabling dependable sentence-level deployment in low-resource, multi-domain settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SRICL, an LLM-centric multi-module framework for span-level skill extraction from job advertisements. It integrates semantic retrieval (SR) of in-domain examples and ESCO definitions, in-context learning (ICL), supervised fine-tuning (SFT), and a deterministic verifier to constrain outputs, enforce BIO legality, and reduce hallucinations and boundary errors. On six public span-labeled job-ad corpora spanning sectors and languages, the framework is claimed to deliver substantial STRICT-F1 gains over GPT-3.5 prompting baselines while sharply reducing invalid tags.
Significance. If the performance claims and generalization hold, SRICL would provide a practical, deployable pipeline for reliable sentence-level skill extraction in low-resource, multi-domain labor-market settings where vanilla LLM prompting is unstable. The modular design (retrieval + ICL + SFT + verifier) directly targets documented LLM failure modes in structured IE.
major comments (2)
- [Abstract] Abstract and experimental evaluation: the central claim of 'dependable sentence-level deployment in low-resource, multi-domain settings' rests on generalization beyond the six tested corpora, yet no held-out sector/language OOD tests, no analysis of ESCO coverage gaps for long-tail skills, and no cross-domain transfer results are reported. This directly undermines the deployment assertion.
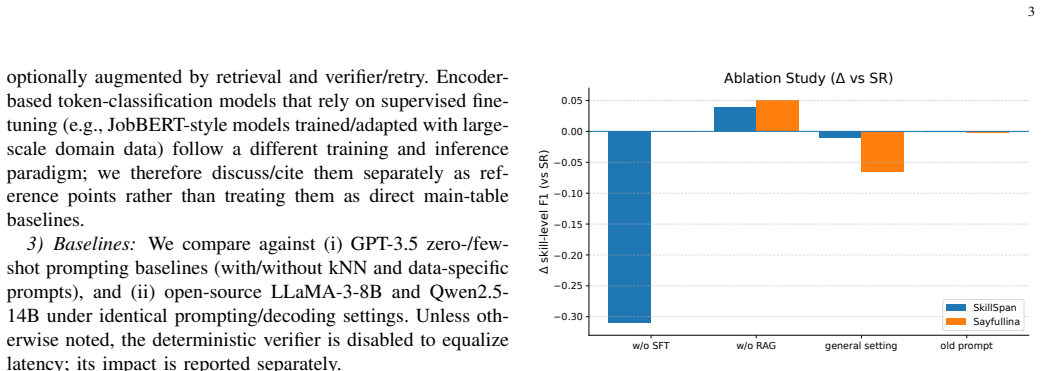
- [Experiments] Experimental section: no ablation studies isolate the contribution of each module (SR, ICL, SFT, verifier). Without these, it is impossible to determine whether the reported STRICT-F1 gains require the full combination or could be achieved with simpler prompting or retrieval alone.
minor comments (2)
- [Abstract] Abstract: the phrase 'substantial STRICT-F1 improvements' is used without any numerical deltas, baseline scores, or statistical significance indicators, making the magnitude of the advance difficult to assess from the summary alone.
- [Method] Clarify the precise definition and implementation of the 'deterministic verifier' (pairing, non-overlap, BIO legality) and the retry mechanism; a short pseudocode or formal description would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the insightful comments. Below we provide point-by-point responses to the major comments and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental evaluation: the central claim of 'dependable sentence-level deployment in low-resource, multi-domain settings' rests on generalization beyond the six tested corpora, yet no held-out sector/language OOD tests, no analysis of ESCO coverage gaps for long-tail skills, and no cross-domain transfer results are reported. This directly undermines the deployment assertion.
Authors: The six corpora used in our evaluation span various sectors and languages, providing a basis for our generalization claims in low-resource and multi-domain settings. However, we recognize that dedicated out-of-distribution tests, such as held-out sector evaluations and analysis of ESCO coverage for long-tail skills, would provide stronger evidence. In the revised manuscript, we will add cross-domain transfer experiments and a discussion section addressing ESCO coverage gaps. revision: yes
-
Referee: [Experiments] Experimental section: no ablation studies isolate the contribution of each module (SR, ICL, SFT, verifier). Without these, it is impossible to determine whether the reported STRICT-F1 gains require the full combination or could be achieved with simpler prompting or retrieval alone.
Authors: We agree that ablation studies are necessary to isolate the impact of each module in SRICL. The current results demonstrate the effectiveness of the complete framework compared to baselines, but do not break down individual contributions. We will incorporate ablation experiments in the revised version, including variants without semantic retrieval, without the verifier, and with only ICL or SFT, to show that the full multi-module approach is required for the observed performance gains. revision: yes
Circularity Check
No circularity: empirical framework evaluated on external benchmarks
full rationale
The paper describes an LLM-centric framework SRICL that integrates semantic retrieval from the external ESCO ontology, in-context learning, supervised fine-tuning, and a deterministic verifier to improve span-level skill extraction. All performance claims (STRICT-F1 gains on six public corpora) rest on direct evaluation against held-out labeled datasets rather than any derivation, equation, or prediction that reduces to fitted parameters or self-referential definitions by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked; the central results are falsifiable via the reported external benchmarks and do not collapse into the input data or module choices.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Semantic retrieval from ESCO stabilizes LLM span boundaries and reduces hallucinations for job skill extraction
- domain assumption The deterministic verifier can enforce BIO legality, non-overlap, and pairing with minimal retries
Reference graph
Works this paper leans on
-
[1]
Skillspan: Hard and soft skill extraction from english job postings,
M. Zhang, K. Jensen, S. Sonniks, and B. Plank, “Skillspan: Hard and soft skill extraction from english job postings,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle, United States: Association for Computational Linguistics, 2022, pp. 4962–4984
2022
-
[2]
Deep learning- based computational job market analysis: A survey on skill extraction and classification from job postings,
E. Senger, M. Zhang, R. van der Goot, and B. Plank, “Deep learning- based computational job market analysis: A survey on skill extraction and classification from job postings,” inProceedings of the First Work- shop on Natural Language Processing for Human Resources (NLP4HR 2024). St. Julian’s, Malta: Association for Computational Linguistics, 2024, pp. 1–15
2024
-
[3]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models,
P. Manakul, A. Liusie, and M. Gales, “Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore: Association for Computational Linguistics, 2023, pp. 9004–9017
2023
-
[4]
Large language models for generative infor- mation extraction: A survey,
D. Xu, W. Chen, W. Peng, C. Zhang, T. Xu, X. Zhao, X. Wu, Y . Zheng, Y . Wang, and E. Chen, “Large language models for generative infor- mation extraction: A survey,”Frontiers of Computer Science, vol. 18, no. 6, p. 186357, 2024
2024
-
[5]
Unsupervised cross-lingual representation learning at scale,
A. Conneau, K. Khandelwal, N. Goyal, V . Chaudhary, G. Wenzek, F. Guzmánet al., “Unsupervised cross-lingual representation learning at scale,” inACL, 2020
2020
-
[6]
Unleashing the true potential of sequence-to- sequence models for sequence tagging and structure parsing,
H. He and J. D. Choi, “Unleashing the true potential of sequence-to- sequence models for sequence tagging and structure parsing,”Trans- actions of the Association for Computational Linguistics, vol. 11, pp. 582–599, 2023
2023
-
[7]
Y . Ma, Y . Cao, Y . Hong, and A. Sun, “Large language model is not a good few-shot information extractor, but a good reranker for hard samples!”arXiv preprint arXiv:2303.08559, 2023
-
[8]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
J. Wei, X. Wang, D. Schuurmanset al., “Chain-of-thought prompting elicits reasoning in large language models,”arXiv:2201.11903, 2022
work page internal anchor Pith review arXiv 2022
-
[9]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdh- ery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[10]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks,” Advances in Neural Information Processing Systems, vol. 33, pp. 9459– 9474, 2020
2020
-
[11]
Unified structure generation for universal information extraction,
Y . Lu, Q. Liu, D. Dai, X. Xiao, H. Lin, X. Han, L. Sun, and H. Wu, “Unified structure generation for universal information extraction,” in Proceedings of the 60th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds., May 2022, pp. 5755–5772
2022
-
[12]
arXiv preprint arXiv:2304.08085
X. Wang, W. Zhou, C. Zu, H. Xia, T. Chen, Y . Zhang, R. Zheng, J. Ye, Q. Zhang, T. Guiet al., “Instructuie: Multi-task instruction tuning for unified information extraction,”arXiv preprint arXiv:2304.08085, 2023
-
[13]
Verifiner: Verification- augmented ner via knowledge-grounded reasoning with large language models,
S. Kim, K. Seo, H. Chae, J. Yeo, and D. Lee, “Verifiner: Verification- augmented ner via knowledge-grounded reasoning with large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Bangkok, Thailand: Association for Computational Linguistics, 2024, pp. 2441– 2461
2024
-
[14]
Self-refine: Iter- ative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yanget al., “Self-refine: Iter- ative refinement with self-feedback,”Advances in Neural Information Processing Systems, vol. 36, pp. 46 534–46 594, 2023
2023
-
[15]
Reflexion: Language Agents with Verbal Reinforcement Learning
N. Shinn, F. Cassano, B. Labash, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning, 2023,”URL https://arxiv. org/abs/2303.11366, vol. 1, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Rethinking skill extraction in the job market domain using large language models,
K. Nguyen, M. Zhang, S. Montariol, and A. Bosselut, “Rethinking skill extraction in the job market domain using large language models,” inProceedings of the First Workshop on Natural Language Processing for Human Resources (NLP4HR 2024), E. Hruschka, T. Lake, N. Otani, and T. Mitchell, Eds. St. Julian’s, Malta: Association for Computational Linguistics, M...
2024
-
[17]
S. Geng, B. Döner, C. Wendler, M. Josifoski, and R. West, “Sketch- guided constrained decoding for boosting blackbox large language models without logit access,”arXiv preprint arXiv:2401.09967, 2024
-
[18]
ESCO: European Skills, Competences, Quali- fications and Occupations (main classification, v1.2),
European Commission, Directorate-General for Employment, Social Affairs and Inclusion, “ESCO: European Skills, Competences, Quali- fications and Occupations (main classification, v1.2),” Online database, 2024, available: https://ec.europa.eu/esco/ Accessed: 2025-09-17
2024
-
[19]
ESCO Escopedia: Green skills and related knowledge concepts,
European Commission, “ESCO Escopedia: Green skills and related knowledge concepts,” Web page, 2024, available: https://ec.europa.eu/esco/ Accessed: 2025-09-17
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.