Recognition: unknown
Finding Meaning in Embeddings: Concept Separation Curves
Pith reviewed 2026-05-09 21:49 UTC · model grok-4.3
The pith
Concept Separation Curves evaluate sentence embeddings by comparing the effects of syntactic noise and semantic negations on their vectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
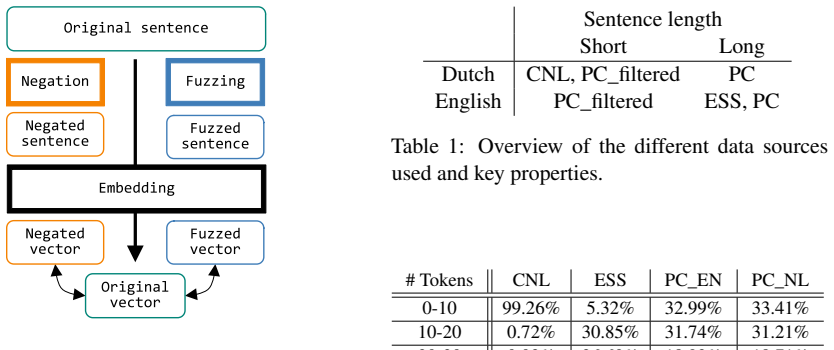
By systematically introducing syntactic noise and semantic negations into sentences and plotting the relative magnitude of their effects on embedding vectors, Concept Separation Curves reveal a model's capacity to maintain conceptual content separate from surface-level variations without relying on any downstream classifier.
What carries the argument
Concept Separation Curves, which plot the quantified differential impact of syntactic perturbations versus semantic negations to isolate conceptual stability in the embedding space.
If this is right
- Sentence embedding quality can be assessed without training or using any additional classifiers or task-specific models.
- Different embedding models become directly comparable on conceptual stability across English, Dutch, and varying sentence lengths.
- The influence of sentence length on how embeddings handle meaning versus noise becomes measurable and visualizable.
- Reproducible visualizations allow consistent tracking of how well models separate concepts from surface changes.
Where Pith is reading between the lines
- The curves could be used during model development to iteratively improve resistance to negation while preserving sensitivity to syntax.
- Similar perturbation-based curves might be constructed for other embedding types such as document or code embeddings.
- Adoption could shift evaluation norms away from task accuracy toward direct measures of meaning preservation.
Load-bearing premise
The relative effects of syntactic noise and semantic negations on embeddings can be measured and visualized in a way that cleanly isolates conceptual content from surface features.
What would settle it
If Concept Separation Curves produce overlapping or non-distinct patterns for embedding models that differ markedly on independent semantic benchmarks, or fail to replicate across additional domains, the method's ability to measure conceptual stability would be refuted.
Figures









read the original abstract
Sentence embedding techniques aim to encode key concepts of a sentence's meaning in a vector space. However, the majority of evaluation approaches for sentence embedding quality rely on the use of additional classifiers or downstream tasks. These additional components make it unclear whether good results stem from the embedding itself or from the classifier's behaviour. In this paper, we propose a novel method for evaluating the effectiveness of sentence embedding methods in capturing sentence-level concepts. Our approach is classifier-independent, allowing for an objective assessment of the model's performance. The approach adopted in this study involves the systematic introduction of syntactic noise and semantic negations into sentences, with the subsequent quantification of their relative effects on the resulting embeddings. The visualisation of these effects is facilitated by Concept Separation Curves, which show the model's capacity to differentiate between conceptual and surface-level variations. By leveraging data from multiple domains, employing both Dutch and English languages, and examining sentence lengths, this study offers a compelling demonstration that Concept Separation Curves provide an interpretable, reproducible, and cross-model approach for evaluating the conceptual stability of sentence embeddings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Concept Separation Curves as a classifier-independent method to evaluate sentence embeddings. It generates controlled syntactic perturbations (noise) and semantic negations, measures their relative effects on embedding distances, and visualizes the results to assess how well embeddings capture conceptual meaning versus surface form. The approach is demonstrated on English and Dutch sentences drawn from multiple domains and varying lengths, with the claim that the curves provide an interpretable, reproducible, and cross-model assessment of conceptual stability.
Significance. If the method can be shown to cleanly isolate conceptual change and if the curves prove reproducible across models, the work would supply a useful task-free alternative to classifier-based embedding evaluations. The cross-lingual and cross-domain scope is a positive feature. However, the absence of quantitative results, statistical controls, and reproducibility details substantially reduces the immediate significance of the contribution.
major comments (3)
- [Results] Results section: the manuscript asserts a 'compelling demonstration' across languages, domains, and sentence lengths, yet supplies no numerical values for separation distances, no error bars, no statistical tests, and no actual plots of the Concept Separation Curves. Without these data the central empirical claim cannot be evaluated.
- [Method] Method section: the procedures for generating syntactic noise and semantic negations are not specified (no examples, no algorithmic description, no parameters), nor is the distance metric, normalization, or aggregation method used to produce the curves. These omissions make the approach non-reproducible and leave open whether the perturbations truly preserve or alter meaning as intended.
- [Evaluation] Evaluation: no baseline comparisons to existing embedding-quality metrics, no human validation of the conceptual/surface distinction, and no ablation on the choice of perturbation types are reported. These controls are required to substantiate that the curves measure conceptual stability rather than other embedding properties.
minor comments (2)
- [Abstract] The abstract and introduction repeat the phrase 'classifier-independent' multiple times; a single clear statement would suffice.
- [Figures] Figure captions should explicitly state the embedding models, languages, and domains shown so that readers can interpret the curves without returning to the text.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and indicate the changes we will make to strengthen the manuscript's reproducibility, quantitative support, and evaluation.
read point-by-point responses
-
Referee: [Results] Results section: the manuscript asserts a 'compelling demonstration' across languages, domains, and sentence lengths, yet supplies no numerical values for separation distances, no error bars, no statistical tests, and no actual plots of the Concept Separation Curves. Without these data the central empirical claim cannot be evaluated.
Authors: We agree that the Results section requires more quantitative rigor to allow proper evaluation of the claims. Although the manuscript describes and visualizes the curves, specific numerical summaries, error bars, and statistical tests were not included. In the revised version we will add a table of average separation distances (with standard deviations across runs and models), error bars on the figures, and appropriate statistical tests (e.g., paired t-tests or Wilcoxon tests) to quantify the separation between conceptual and syntactic effects. revision: yes
-
Referee: [Method] Method section: the procedures for generating syntactic noise and semantic negations are not specified (no examples, no algorithmic description, no parameters), nor is the distance metric, normalization, or aggregation method used to produce the curves. These omissions make the approach non-reproducible and leave open whether the perturbations truly preserve or alter meaning as intended.
Authors: We acknowledge that the Method section is insufficiently detailed for reproducibility. The revised manuscript will expand this section with: concrete examples of syntactic perturbations and semantic negations; pseudocode describing the generation procedure; all parameter settings; the distance metric (cosine distance); normalization steps; and the aggregation procedure used to construct the curves. These additions will make the perturbation process transparent and replicable. revision: yes
-
Referee: [Evaluation] Evaluation: no baseline comparisons to existing embedding-quality metrics, no human validation of the conceptual/surface distinction, and no ablation on the choice of perturbation types are reported. These controls are required to substantiate that the curves measure conceptual stability rather than other embedding properties.
Authors: We partially agree. The manuscript already demonstrates consistency across multiple models, languages, and domains, which provides an implicit form of comparative evaluation. However, we will add explicit baseline comparisons against standard metrics (e.g., SentEval tasks) and an ablation study on perturbation types in the revision. Human validation of the conceptual/surface distinction is a valuable suggestion; while our controlled perturbations are designed to isolate these effects, we will acknowledge the absence of direct human judgments as a limitation and outline plans for such validation in future work. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes a classifier-free evaluation method that introduces controlled syntactic noise and semantic negations into sentences, then visualizes their relative impact on embeddings via Concept Separation Curves. No equations, fitted parameters, or self-referential definitions appear in the abstract or summary. The central claim rests on empirical demonstration across domains, languages, and lengths rather than any derivation that reduces by construction to its own inputs or prior self-citations. The approach is presented as an independent visualization technique without load-bearing uniqueness theorems or ansatzes imported from the authors' own prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dependency-Based Self-Attention for Transformer
Deguchi, Hiroyuki and Tamura, Akihiro and Ninomiya, Takashi , year =. Dependency-Based Self-Attention for Transformer. Proceedings of the International Conference on Recent Advances in Natural Language Processing (
-
[2]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[3]
Evaluating the Construct Validity of Text Embeddings with Application to Survey Questions , author =. 2022 , month = dec, journal =. doi:10.1140/epjds/s13688-022-00353-7 , urldate =
- [4]
-
[5]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[6]
doi:10.48550/ARXIV.2004.09297 , urldate =
Song, Kaitao and Tan, Xu and Qin, Tao and Lu, Jianfeng and Liu, Tie-Yan , year =. doi:10.48550/ARXIV.2004.09297 , urldate =
-
[7]
Ba. Proceedings of the 58th. 2020 , pages =. doi:10.18653/v1/2020.acl-main.417 , urldate =
-
[8]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R. , year =. arXiv , keywords =:1804.07461 , primaryclass =
work page internal anchor Pith review arXiv
-
[9]
Dror, Itiel E. , year =. Cognitive and. Analytical Chemistry , volume =. doi:10.1021/acs.analchem.0c00704 , urldate =
-
[10]
and Varoquaux, G
Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E. , journal=. Scikit-learn: Machine Learning in
-
[11]
Liu, Xiao and Zheng, Yanan and Du, Zhengxiao and Ding, Ming and Qian, Yujie and Yang, Zhilin and Tang, Jie , year =. AI Open , volume =. doi:10.1016/j.aiopen.2023.08.012 , urldate =
-
[12]
List of wikipedias , author =
-
[13]
Wikipedia Statistics , author =
-
[14]
Wikipedia Statistieken , author =
-
[15]
Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas , year =. Bag of. arXiv , keywords =:1607.01759 , primaryclass =
-
[16]
arXiv preprint arXiv:2007.01852 , year=
Feng, Fangxiaoyu and Yang, Yinfei and Cer, Daniel and Arivazhagan, Naveen and Wang, Wei , year =. Language-Agnostic. arXiv , keywords =:2007.01852 , primaryclass =
-
[17]
doi:10.48550/arXiv.2001.06286 , urldate =
Delobelle, Pieter and Winters, Thomas and Berendt, Bettina , year =. doi:10.48550/arXiv.2001.06286 , urldate =. arXiv , keywords =:2001.06286 , primaryclass =
-
[18]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , year =. arXiv , keywords =:1810.04805 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and. Nature Methods , year =
-
[20]
The Concept of Validity in Theory and Practice , author =. 2010 , month = may, journal =. doi:10.1080/09695941003693856 , urldate =
-
[21]
ChatGPT MT: Competitive for High-(but not Low-) Resource Languages
Robinson, Nathaniel R. and Ogayo, Perez and Mortensen, David R. and Neubig, Graham , year =. doi:10.48550/arXiv.2309.07423 , urldate =. arXiv , keywords =:2309.07423 , primaryclass =
-
[22]
Zero-shot Sentiment Analysis in Low-Resource Languages Using a Multilingual Sentiment Lexicon
Koto, Fajri and Beck, Tilman and Talat, Zeerak and Gurevych, Iryna and Baldwin, Timothy. Zero-shot Sentiment Analysis in Low-Resource Languages Using a Multilingual Sentiment Lexicon. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[23]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[24]
International conference on machine learning , pages=
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav) , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[25]
Zong, Mingyu and Krishnamachari, Bhaskar , year =. A Survey on. doi:10.48550/ARXIV.2212.00857 , urldate =
-
[26]
Kim, Been and Wattenberg, Martin and Gilmer, Justin and Cai, Carrie and Wexler, James and Viegas, Fernanda and Sayres, Rory , year =. Interpretability. doi:10.48550/arXiv.1711.11279 , urldate =. arXiv , keywords =:1711.11279 , primaryclass =
-
[27]
de Vries, Wietse and van Cranenburgh, Andreas and Bisazza, Arianna and Caselli, Tommaso and Noord, Gertjan van and Nissim, Malvina , year =
-
[28]
Wang, Hao and Li, Yangguang and Huang, Zhen and Dou, Yong and Kong, Lingpeng and Shao, Jing , date =. 2022 , eprint =. doi:10.48550/arXiv.2201.05979 , url =
-
[29]
, author=
Validity Challenge in GenAI Models: Evaluating the Validity of Content Generated by Text-to-Image Models in the Context of Social Studies Education. , author=. Journal of Pedagogical Research , volume=. 2025 , publisher=
2025
-
[30]
2025 , organization =
concept - Dictionary Definition , url =. 2025 , organization =
2025
-
[31]
Postgraduate Medical Journal , volume=
ChatGPT prompts for generating multiple-choice questions in medical education and evidence on their validity: a literature review , author=. Postgraduate Medical Journal , volume=. 2024 , publisher=
2024
-
[32]
Want To Reduce Labeling Cost? GPT -3 Can Help
Wang, Shuohang and Liu, Yang and Xu, Yichong and Zhu, Chenguang and Zeng, Michael. Want To Reduce Labeling Cost? GPT -3 Can Help. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.354
-
[33]
Fine-grained Analysis of Sentence Embeddings Using Auxiliary Prediction Tasks
Adi, Yossi and Kermany, Einat and Belinkov, Yonatan and Lavi, Ofer and Goldberg, Yoav , year = 2017, month = feb, number =. Fine-Grained. doi:10.48550/arXiv.1608.04207 , urldate =. arXiv , keywords =:1608.04207 , primaryclass =
-
[34]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Climbing towards NLU: On meaning, form, and understanding in the age of data , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.