Recognition: unknown
OmniFit: Multi-modal 3D Body Fitting via Scale-agnostic Dense Landmark Prediction
Pith reviewed 2026-05-09 22:29 UTC · model grok-4.3
The pith
A conditional transformer decoder maps surface points from multi-modal inputs to dense landmarks for scale-agnostic SMPL-X body fitting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OmniFit shows that directly predicting dense body landmarks with a conditional transformer decoder from diverse surface points allows accurate fitting of the SMPL-X model across different input modalities and without scale information. The decoder conditions on the input points and produces landmarks that serve as targets for parameter estimation. Supporting components include an optional image adapter for visual cues and a scale predictor for canonical proportions. On the CAPE and 4D-DRESS benchmarks the method reaches millimeter-level accuracy while substantially outperforming prior single-modal and multi-view approaches in both daily and loose clothing settings.
What carries the argument
Conditional transformer decoder that maps arbitrary surface points from multi-modal inputs to dense body landmarks for subsequent SMPL-X fitting.
If this is right
- Body fitting becomes possible from incomplete or image-only observations.
- Scale distortions common in synthetic data no longer prevent accurate reconstruction.
- Performance exceeds that of traditional multi-view optimization methods.
- Millimeter-level accuracy is achieved on standard clothed body benchmarks.
Where Pith is reading between the lines
- This suggests transformer-based decoders could replace hand-crafted correspondence search in other 3D registration tasks.
- Future work might test whether the same decoder architecture works for non-human parametric models or dynamic sequences.
- Integration with generative image models could allow end-to-end creation of fitted 3D assets from text prompts alone.
Load-bearing premise
The conditional transformer decoder must reliably predict accurate dense landmarks from any combination of surface points and images, even when clothing hides body shape and scale is unknown.
What would settle it
Running the landmark predictor on the CAPE benchmark test set and measuring the resulting SMPL-X fit error; if the average error remains above 5 millimeters, the millimeter-level accuracy claim would be falsified.
Figures

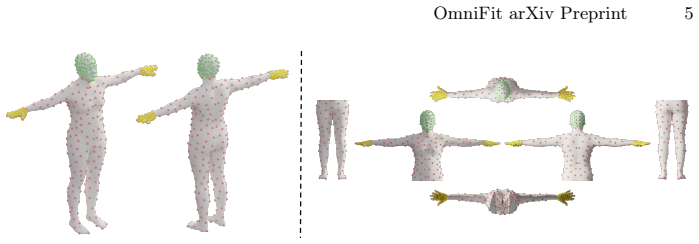

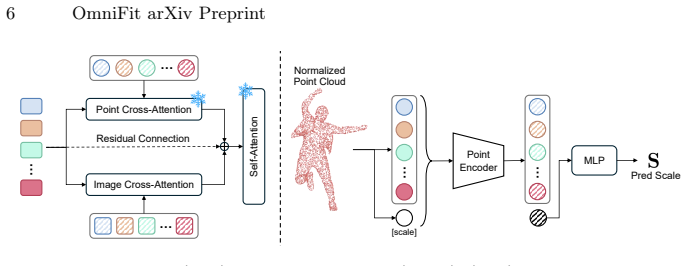



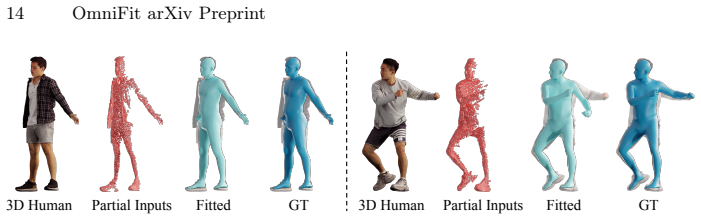







read the original abstract
Fitting an underlying body model to 3D clothed human assets has been extensively studied, yet most approaches focus on either single-modal inputs such as point clouds or multi-view images alone, often requiring a known metric scale. This constraint is frequently impractical, especially for AI-generated assets where scale distortion is common. We propose OmniFit, a method that can seamlessly handle diverse multi-modal inputs, including full scans, partial depth observations, and image captures, while remaining scale-agnostic for both real and synthetic assets. Our key innovation is a simple yet effective conditional transformer decoder that directly maps surface points to dense body landmarks, which are then used for SMPL-X parameter fitting. In addition, an optional plug-and-play image adapter incorporates visual cues to compensate for missing geometric information. We further introduce a dedicated scale predictor that rescales subjects to canonical body proportions. OmniFit substantially outperforms state-of-the-art methods by 57.1 to 80.9 percent across daily and loose clothing scenarios. To the best of our knowledge, it is the first body fitting method to surpass multi-view optimization baselines and the first to achieve millimeter-level accuracy on the CAPE and 4D-DRESS benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OmniFit, a scale-agnostic method for fitting SMPL-X body models to multi-modal 3D inputs including full scans, partial depth maps, and images. The central technical contribution is a conditional transformer decoder that maps arbitrary surface points to dense body landmarks, which are then used for SMPL-X parameter optimization; an optional plug-and-play image adapter supplies visual cues when geometry is incomplete, and a dedicated scale predictor normalizes subjects to canonical proportions. Experiments on the CAPE and 4D-DRESS benchmarks report 57.1–80.9 % error reductions relative to prior art, millimeter-level accuracy, and the first reported outperformance of multi-view optimization baselines under both daily and loose clothing conditions.
Significance. If the reported gains and protocols hold, the work is significant because it removes the metric-scale requirement that limits many existing pipelines, especially for AI-generated assets, while unifying single-view, partial, and multi-modal inputs under one landmark-prediction framework. Credit is due for the explicit experimental protocols, the internal consistency of the method (no circular reliance on self-generated data), and the reproducible benchmark leadership claims on CAPE and 4D-DRESS.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, recognition of its technical contributions in scale-agnostic multi-modal fitting, and recommendation for minor revision. We appreciate the acknowledgment of the experimental protocols, internal consistency, and benchmark results on CAPE and 4D-DRESS.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core pipeline—conditional transformer decoder predicting dense landmarks from multi-modal surface points, followed by standard SMPL-X parameter optimization and an independent scale predictor module—is presented as a sequence of trained components validated on external benchmarks (CAPE, 4D-DRESS). No step reduces by construction to its own inputs, fitted parameters renamed as predictions, or load-bearing self-citations; the landmark-to-SMPL-X fitting uses conventional optimization rather than self-referential outputs, and scale handling is a dedicated separate module without ansatz smuggling or uniqueness claims imported from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The SMPL-X parametric model is a sufficiently accurate representation for fitting to clothed human geometry from multi-modal inputs
invented entities (2)
-
Conditional transformer decoder for dense landmark prediction
no independent evidence
-
Dedicated scale predictor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Github (2021),https://github
EasyMoCap - Make human motion capture easier. Github (2021),https://github. com/zju3dv/EasyMocap
2021
-
[2]
Transactions on Graphics (TOG) (2003)
Allen, B., Curless, B., Popović, Z.: The space of human body shapes: reconstruction and parameterization from range scans. Transactions on Graphics (TOG) (2003)
2003
-
[3]
In: International Conference on 3D Vision (3DV) (2024)
Antić, D., Tiwari, G., Ozcomlekci, B., Marin, R., Pons-Moll, G.: Close: a 3D clothing segmentation dataset and model. In: International Conference on 3D Vision (3DV) (2024)
2024
-
[4]
In: European Conference on Computer Vision (ECCV) (2020)
Bertiche, H., Madadi, M., Escalera, S.: Cloth3d: Clothed 3d humans. In: European Conference on Computer Vision (ECCV) (2020)
2020
-
[5]
Bhatnagar, B., Petrov, I., Xie, X.: RVH mesh registration.https://github.com/ bharat-b7/RVH_Mesh_Registration(2022)
2022
-
[6]
In: European Conference on Computer Vision (ECCV) (2020)
Bhatnagar, B.L., Sminchisescu, C., Theobalt, C., Pons-Moll, G.: Combining implicit function learning and parametric models for 3d human reconstruction. In: European Conference on Computer Vision (ECCV) (2020)
2020
-
[7]
In: Conference on Neural Information Processing Systems (NeurIPS) (2020)
Bhatnagar, B.L., Sminchisescu, C., Theobalt, C., Pons-Moll, G.: Loopreg: self- supervised learning of implicit surface correspondences, pose and shape for 3d human mesh registration. In: Conference on Neural Information Processing Systems (NeurIPS) (2020)
2020
-
[8]
In: IEEE Conference on Artificial Intelligence (CAI) (2024)
Cai, Z., Huang, Z., Zheng, X., Liu, Y., Liu, C., Wang, Z., Wang, L.: Interact360: Interactive identity-driven text to 360 panorama generation. In: IEEE Conference on Artificial Intelligence (CAI) (2024)
2024
-
[9]
In: International Conference on Learning Representations (ICLR) (2026)
Cai, Z., Li, Z., Li, X., Li, B., Wang, Z., Zhang, Z., Xiu, Y.: Up2you: Fast reconstruc- tion of yourself from unconstrained photo collections. In: International Conference on Learning Representations (ICLR) (2026)
2026
-
[10]
arXiv preprint arXiv:2409.05099 (2024) 5
Cai, Z., Wang, D., Liang, Y., Shao, Z., Chen, Y.C., Zhan, X., Wang, Z.: Dreammap- ping: High-fidelity text-to-3d generation via variational distribution mapping. arXiv preprint arXiv:2409.05099 (2024)
-
[11]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Cao, Y., Cao, Y.P., Han, K., Shan, Y., Wong, K.Y.K.: Dreamavatar: Text-and-shape guided 3d human avatar generation via diffusion models. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[12]
Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2019)
Cao, Z., Hidalgo Martinez, G., Simon, T., Wei, S., Sheikh, Y.A.: Openpose: Realtime multi-person 2d pose estimation using part affinity fields. Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2019)
2019
-
[13]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Chen, J., Hu, J., Wang, G., Jiang, Z., Zhou, T., Chen, Z., Lv, C.: Taoavatar: Real- time lifelike full-body talking avatars for augmented reality via 3d gaussian splatting. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[14]
Conference on Neural Information Processing Systems (NeurIPS) (2025)
Chen, W., Li, P., Zheng, W., Zhao, C., Li, M., Zhu, Y., Dou, Z., Wang, R., Liu, Y.: SyncHuman: Synchronizing 2d and 3d generative models for single-view human reconstruction. Conference on Neural Information Processing Systems (NeurIPS) (2025)
2025
-
[15]
Image and vision computing (1992)
Chen, Y., Medioni, G.: Object modelling by registration of multiple range images. Image and vision computing (1992)
1992
-
[16]
MAMMA: Markerless & Automatic Multi-Person Motion Action Capture
Cuevas-Velasquez, H., Yiannakidis, A., Shin, S., Becherini, G., Höschle, M., Tesch, J., Obersat, T., Alexiadis, T., Halilaj, E., Black, M.J.: Mamma: Markerless & automatic multi-person motion action capture. arXiv preprint arXiv:2506.13040 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2022) 16 OmniFit arXiv Preprint
Fang, H.S., Li, J., Tang, H., Xu, C., Zhu, H., Xiu, Y., Li, Y.L., Lu, C.: Alpha- pose: Whole-body regional multi-person pose estimation and tracking in real-time. Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2022) 16 OmniFit arXiv Preprint
2022
-
[18]
In: International Conference on Computer Vision (ICCV) (2023)
Feng, H., Kulits, P., Liu, S., Black, M.J., Abrevaya, V.F.: Generalizing neural human fitting to unseen poses with articulated se (3) equivariance. In: International Conference on Computer Vision (ICCV) (2023)
2023
-
[19]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Gong, K., Gao, Y., Liang, X., Shen, X., Wang, M., Lin, L.: Graphonomy: Universal human parsing via graph transfer learning. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
2019
-
[20]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Han, S.H., Park, M.G., Yoon, J.H., Kang, J.M., Park, Y.J., Jeon, H.G.: High-fidelity 3d human digitization from single 2k resolution images. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[21]
In: International Conference on Learning Representa- tions (ICLR) (2025)
He, C., Sun, X., Shu, Z., Luan, F., Pirk, S., Herrera, J.A.A., Michels, D.L., Wang, T.Y., Zhang, M., Rushmeier, H., Zhou, Y.: Perm: A parametric representation for multi-style 3D hair modeling. In: International Conference on Learning Representa- tions (ICLR) (2025)
2025
-
[22]
In: AAAI Conference on Artificial Intelligence (2025)
He, X., Wu, Z., Li, X., Kang, D., Zhang, C., Ye, J., Chen, L., Gao, X., Zhang, H., Zhuang, H.: Magicman: Generative novel view synthesis of humans with 3d-aware diffusion and iterative refinement. In: AAAI Conference on Artificial Intelligence (2025)
2025
-
[23]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Ho, H.I., Xue, L., Song, J., Hilliges, O.: Learning locally editable virtual humans. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[24]
In: International Conference on Computer Vision (ICCV) (2025)
Huang, Z., Guo, Y.C., Wang, H., Yi, R., Ma, L., Cao, Y.P., Sheng, L.: Mv-adapter: Multi-view consistent image generation made easy. In: International Conference on Computer Vision (ICCV) (2025)
2025
-
[25]
In: International Conference on Machine Learning (ICML) (2021)
Jaegle, A., Gimeno, F., Brock, A., Vinyals, O., Zisserman, A., Carreira, J.: Perceiver: General perception with iterative attention. In: International Conference on Machine Learning (ICML) (2021)
2021
-
[26]
In: International Conference on Computer Vision (ICCV) (2019)
Jiang, H., Cai, J., Zheng, J.: Skeleton-aware 3d human shape reconstruction from point clouds. In: International Conference on Computer Vision (ICCV) (2019)
2019
-
[27]
Transactions on Graphics (TOG) (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. Transactions on Graphics (TOG) (2023)
2023
-
[28]
In: European Conference on Computer Vision (ECCV) (2024)
Khirodkar, R., Bagautdinov, T., Martinez, J., Zhaoen, S., James, A., Selednik, P., Anderson, S., Saito, S.: Sapiens: Foundation for human vision models. In: European Conference on Computer Vision (ECCV) (2024)
2024
-
[29]
arXiv preprint arXiv:2504.03602 (2025)
Lascheit, K., Barath, D., Pollefeys, M., Guibas, L., Engelmann, F.: Robust human registration with body part segmentation on noisy point clouds. arXiv preprint arXiv:2504.03602 (2025)
-
[30]
In: International Conference on Computer Vision (ICCV) (2025)
Li, B., Feng, H., Cai, Z., Black, M.J., Xiu, Y.: Etch: Generalizing body fitting to clothed humans via equivariant tightness. In: International Conference on Computer Vision (ICCV) (2025)
2025
-
[31]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Li, P., Zheng, W., Liu, Y., Yu, T., Li, Y., Qi, X., Chi, X., Xia, S., Cao, Y.P., Xue, W., et al.: Pshuman: Photorealistic single-image 3d human reconstruction using cross-scale multiview diffusion and explicit remeshing. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[32]
Conference on Neural Information Processing Systems (NeurIPS) (2023)
Lin, J., Zeng, A., Lu, S., Cai, Y., Zhang, R., Wang, H., Zhang, L.: Motion-x: A large-scale 3d expressive whole-body human motion dataset. Conference on Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[33]
In: ACM International Conference on Multimedia (MM) (2021)
Liu, G., Rong, Y., Sheng, L.: Votehmr: Occlusion-aware voting network for robust 3d human mesh recovery from partial point clouds. In: ACM International Conference on Multimedia (MM) (2021)
2021
-
[34]
In: International Conference on Computer Vision (ICCV) (2020) OmniFit arXiv Preprint 17
Ma, Q., Yang, J., Ranjan, A., Pujades, S., Pons-Moll, G., Tang, S., Black, M.J.: Learning to dress 3d people in generative clothing. In: International Conference on Computer Vision (ICCV) (2020) OmniFit arXiv Preprint 17
2020
-
[35]
In: International Conference on Computer Vision (ICCV) (2019)
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: Amass: Archive of motion capture as surface shapes. In: International Conference on Computer Vision (ICCV) (2019)
2019
-
[36]
In: European Conference on Computer Vision (ECCV) (2024)
Marin, R., Corona, E., Pons-Moll, G.: Nicp: Neural icp for 3d human registration at scale. In: European Conference on Computer Vision (ECCV) (2024)
2024
-
[37]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Müller, L., Osman, A.A.A., Tang, S., Huang, C.H.P., Black, M.J.: On self-contact and human pose. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
2021
-
[38]
Transactions on Machine Learning Research Journal (TMLR) (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research Journal (TMLR) (2024)
2024
-
[39]
In: European Conference on Computer Vision (ECCV) (2024)
Örnek, E.P., Labbé, Y., Tekin, B., Ma, L., Keskin, C., Forster, C., Hodan, T.: Foundpose: Unseen object pose estimation with foundation features. In: European Conference on Computer Vision (ECCV) (2024)
2024
-
[40]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Patel, P., Huang, C.H.P., Tesch, J., Hoffmann, D.T., Tripathi, S., Black, M.J.: Agora: Avatars in geography optimized for regression analysis. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
2021
-
[41]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single image. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
2019
-
[42]
Transactions on Graphics (TOG) (2015)
Pons-Moll, G., Romero, J., Mahmood, N., Black, M.J.: Dyna: A model of dynamic human shape in motion. Transactions on Graphics (TOG) (2015)
2015
-
[43]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
2017
-
[44]
In: Conference on Neural Information Processing Systems (NeurIPS) (2017)
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In: Conference on Neural Information Processing Systems (NeurIPS) (2017)
2017
-
[45]
In: International Conference on Computer Vision (ICCV) (2025)
Qiu, L., Gu, X., Li, P., Zuo, Q., Shen, W., Zhang, J., Qiu, K., Yuan, W., Chen, G., Dong, Z., et al.: Lhm: Large animatable human reconstruction model from a single image in seconds. In: International Conference on Computer Vision (ICCV) (2025)
2025
-
[46]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Qiu, L., Zhu, S., Zuo, Q., Gu, X., Dong, Y., Zhang, J., Xu, C., Li, Z., Yuan, W., Bo, L., et al.: Anigs: Animatable gaussian avatar from a single image with inconsistent gaussian reconstruction. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[47]
Transactions on Graphics (TOG) (2024)
Shao, R., Pang, Y., Zheng, Z., Sun, J., Liu, Y.: 360-degree human video generation with 4d diffusion transformer. Transactions on Graphics (TOG) (2024)
2024
-
[48]
In: International Conference on 3D Vision (3DV) (2025)
Shao, Z., Wang, D., Tian, Q.Y., Yang, Y.D., Meng, H., Cai, Z., Dong, B., Zhang, Y., Zhang, K., Wang, Z.: Degas: Detailed expressions on full-body gaussian avatars. In: International Conference on 3D Vision (3DV) (2025)
2025
-
[49]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Shen, K., Guo, C., Kaufmann, M., Zarate, J.J., Valentin, J., Song, J., Hilliges, O.: X-avatar: Expressive human avatars. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[50]
Conference on Neural Information Processing Systems (NeurIPS) (2025)
Tesch, J., Becherini, G., Achar, P., Yiannakidis, A., Kocabas, M., Patel, P., Black, M.J.: BEDLAM2.0: Synthetic humans and cameras in motion. Conference on Neural Information Processing Systems (NeurIPS) (2025)
2025
-
[51]
In: International Conference on Computer Vision (ICCV) (2019) 18 OmniFit arXiv Preprint
Thomas, H., Qi, C.R., Deschaud, J.E., Marcotegui, B., Goulette, F., Guibas, L.J.: Kpconv: Flexible and deformable convolution for point clouds. In: International Conference on Computer Vision (ICCV) (2019) 18 OmniFit arXiv Preprint
2019
-
[52]
In: IEEE Conference Virtual Reality and 3D User Interfaces (VR) (2025)
Wang,B.,Meng,H.,Cao,R.,Cai,Z.,Li,L.,Ma,Y.,Chen,Q.,Wang,Z.:MagicScroll: Enhancing immersive storytelling with controllable scroll image generation. In: IEEE Conference Virtual Reality and 3D User Interfaces (VR) (2025)
2025
-
[53]
In: International Conference on 3D Vision (3DV) (2025)
Wang, D., Meng, H., Cai, Z., Shao, Z., Liu, Q., Wang, L., Fan, M., Zhan, X., Wang, Z.: Headevolver: Text to head avatars via expressive and attribute-preserving mesh deformation. In: International Conference on 3D Vision (3DV) (2025)
2025
-
[54]
arXiv preprint arXiv:2601.02267 (2025)
Wang, R., Zhang, Z., Tai, Y., Yang, J.: DiffProxy: Multi-view human mesh recovery via diffusion-generated dense proxies. arXiv preprint arXiv:2601.02267 (2025)
-
[55]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Wang, S., Geiger, A., Tang, S.: Locally aware piecewise transformation fields for 3d human mesh registration. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
2021
-
[56]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Wang, W., Ho, H.I., Guo, C., Rong, B., Grigorev, A., Song, J., Zarate, J.J., Hilliges, O.: 4d-dress: A 4d dataset of real-world human clothing with semantic annotations. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[57]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Wang, Y., Sun, Y., Patel, P., Daniilidis, K., Black, M.J., Kocabas, M.: Prompthmr: Promptable human mesh recovery. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[58]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Wu, X., Jiang, L., Wang, P.S., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T., Zhao, H.: Point transformer v3: simpler, faster, stronger. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[59]
Conference on Neural Information Processing Systems (NeurIPS) (2022)
Wu, X., Lao, Y., Jiang, L., Liu, X., Zhao, H.: Point transformer v2: grouped vector attention and partition-based pooling. Conference on Neural Information Processing Systems (NeurIPS) (2022)
2022
-
[60]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[61]
In: International Conference on Computer Vision (ICCV) (2023)
Yang, Z., Cai, Z., Mei, H., Liu, S., Chen, Z., Xiao, W., Wei, Y., Qing, Z., Wei, C., Dai, B., et al.: Synbody: Synthetic dataset with layered human models for 3d human perception and modeling. In: International Conference on Computer Vision (ICCV) (2023)
2023
-
[62]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Yu, T., Zheng, Z., Guo, K., Liu, P., Dai, Q., Liu, Y.: Function4d: Real-time human volumetric capture from very sparse consumer rgbd sensors. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
2021
-
[63]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Yu, X., Tang, L., Rao, Y., Huang, T., Zhou, J., Lu, J.: Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[64]
Conference on Neural Information Processing Systems (NeurIPS) (2017)
Zaheer, M., Kottur, S., Ravanbakhsh, S., Poczos, B., Salakhutdinov, R.R., Smola, A.J.: Deep sets. Conference on Neural Information Processing Systems (NeurIPS) (2017)
2017
-
[65]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Zhang, C., Pujades, S., Black, M.J., Pons-Moll, G.: Detailed, accurate, human shape estimation from clothed 3d scan sequences. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
2017
-
[66]
In: Interna- tional Conference on Computer Vision (ICCV) (2021)
Zhao, H., Jiang, L., Jia, J., Torr, P.H., Koltun, V.: Point transformer. In: Interna- tional Conference on Computer Vision (ICCV) (2021)
2021
-
[67]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zhao, Z., Lai, Z., Lin, Q., Zhao, Y., Liu, H., Yang, S., Feng, Y., Yang, M., Zhang, S., Yang, X., et al.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation. arXiv preprint arXiv:2501.12202 (2025)
work page Pith review arXiv 2025
-
[68]
In: International Conference on Computer Vision (ICCV) (2019) OmniFit arXiv Preprint 19
Zheng, Z., Yu, T., Wei, Y., Dai, Q., Liu, Y.: Deephuman: 3d human reconstruction from a single image. In: International Conference on Computer Vision (ICCV) (2019) OmniFit arXiv Preprint 19
2019
-
[69]
Zuffi, S., Black, M.J.: The stitched puppet: A graphical model of 3d human shape and pose. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015) 20 OmniFit arXiv Preprint A Details of Unified Dataset To train our generalizable landmark predictor, we construct a unified dataset by combiningCAPE, 4D-DRESS, and two newly collected synt...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.