Recognition: unknown
Sapiens2
Pith reviewed 2026-05-09 21:56 UTC · model grok-4.3
The pith
Sapiens2 uses combined masked reconstruction and contrastive pretraining on one billion human images to set new benchmarks on pose estimation, body-part segmentation, and normal prediction while adding pointmap and albedo tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
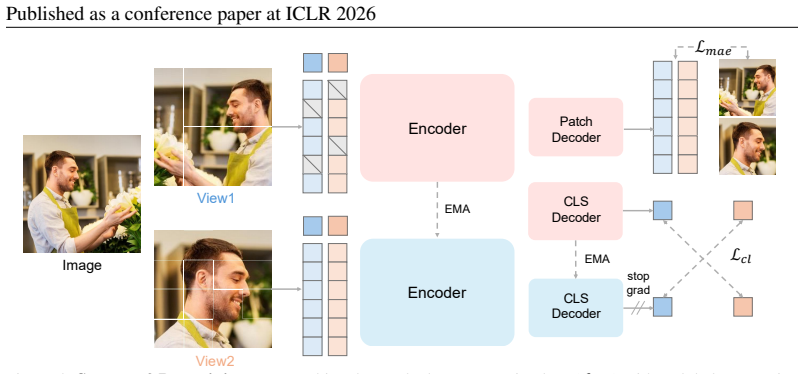
Sapiens2 improves over its predecessor by combining masked image reconstruction with self-distilled contrastive objectives during pretraining on one billion curated human images, incorporating architectural advances from frontier models that support stable longer training, and adopting windowed attention in hierarchical variants for 4K resolution; the resulting models raise performance by 4 mAP on pose estimation, 24.3 mIoU on body-part segmentation, and 45.6 percent lower angular error on normal estimation while extending to pointmap and albedo estimation.
What carries the argument
The unified pretraining objective that pairs masked image reconstruction with self-distilled contrastive learning on a 1-billion-image human dataset, together with hierarchical transformers that use windowed attention for high-resolution outputs up to 4K.
If this is right
- Pose estimation accuracy rises by 4 mAP points over the prior generation.
- Body-part segmentation quality increases by 24.3 mIoU.
- Surface normal estimation error falls by 45.6 percent in angular measure.
- The same models gain the ability to output pointmaps and albedo maps without separate training.
- Hierarchical variants with windowed attention maintain stability at 4K output resolution after pretraining at 2K.
Where Pith is reading between the lines
- The results imply that a single pretraining mixture can reduce the need for separate low-level and high-level feature learners in human vision pipelines.
- Similar unified objectives might transfer to other dense prediction domains if large curated datasets become available.
- The stability gains from the architectural updates could support even longer training runs or larger parameter counts without additional regularization.
Load-bearing premise
The reported performance gains arise mainly from the specific mix of pretraining objectives, data volume and curation, and architectural tweaks rather than from hidden differences in data quality or simple increases in model scale.
What would settle it
Retraining an otherwise identical model using only one of the two pretraining objectives on the same 1B-image set and checking whether the drops in pose mAP, segmentation mIoU, and normal error match the full reported improvements.
Figures


















read the original abstract
We present Sapiens2, a model family of high-resolution transformers for human-centric vision focused on generalization, versatility, and high-fidelity outputs. Our model sizes range from 0.4 to 5 billion parameters, with native 1K resolution and hierarchical variants that support 4K. Sapiens2 substantially improves over its predecessor in both pretraining and post-training. First, to learn features that capture low-level details (for dense prediction) and high-level semantics (for zero-shot or few-label settings), we combine masked image reconstruction with self-distilled contrastive objectives. Our evaluations show that this unified pretraining objective is better suited for a wider range of downstream tasks. Second, along the data axis, we pretrain on a curated dataset of 1 billion high-quality human images and improve the quality and quantity of task annotations. Third, architecturally, we incorporate advances from frontier models that enable longer training schedules with improved stability. Our 4K models adopt windowed attention to reason over longer spatial context and are pretrained with 2K output resolution. Sapiens2 sets a new state-of-the-art and improves over the first generation on pose (+4 mAP), body-part segmentation (+24.3 mIoU), normal estimation (45.6% lower angular error) and extends to new tasks such as pointmap and albedo estimation. Code: https://github.com/facebookresearch/sapiens2
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sapiens2, a family of high-resolution (native 1K, hierarchical 4K) transformer models ranging from 0.4B to 5B parameters for human-centric vision. It claims that combining masked image reconstruction with self-distilled contrastive pretraining on a curated 1B-image human dataset, together with architectural advances (longer stable training, windowed attention), yields substantial gains over the prior Sapiens generation: +4 mAP on pose, +24.3 mIoU on body-part segmentation, 45.6% lower angular error on normals, plus new tasks (pointmap, albedo). The work positions the unified pretraining objective as better suited for dense prediction and zero/few-shot settings.
Significance. If the reported gains hold under controlled conditions, Sapiens2 would represent a meaningful advance in scalable, high-fidelity human-centric perception, particularly for applications needing both low-level detail and semantic robustness at high resolution. The extension to new dense tasks and the 4K variants are practically useful. However, the absence of isolating controls makes it difficult to attribute improvements to the proposed pretraining or architecture rather than dataset scale and curation.
major comments (3)
- §4 (Experiments) and abstract: The SOTA claims and quantitative improvements (+4 mAP, +24.3 mIoU, 45.6% error reduction) are presented without any description of baselines, evaluation protocols, error bars, data splits, or ablation studies. This prevents verification of whether the unified pretraining objective, rather than the 1B-image dataset scale or undisclosed curation, drives the gains.
- §3 (Pretraining): The central assertion that 'this unified pretraining objective is better suited for a wider range of downstream tasks' lacks any controlled comparison holding model scale, data volume, and curation fixed. Without such ablations, the attribution of improvements to masked reconstruction plus self-distilled contrastive learning versus simpler scaling remains untested.
- §4.2 (Architectural changes and 4K models): The use of windowed attention for longer context and 2K pretraining resolution is described, but no ablation isolates its contribution to the reported metrics or stability gains relative to standard attention at equivalent compute.
minor comments (2)
- The abstract and introduction would benefit from explicit pointers to the specific tables or figures that support each quantitative claim (e.g., the exact table reporting the +4 mAP pose result).
- Model parameter counts and pretraining dataset details are mentioned but not tabulated with corresponding downstream performance; a summary table linking scale to each task would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, clarifying the current manuscript content and outlining revisions to improve transparency and add supporting analyses where feasible.
read point-by-point responses
-
Referee: §4 (Experiments) and abstract: The SOTA claims and quantitative improvements (+4 mAP, +24.3 mIoU, 45.6% error reduction) are presented without any description of baselines, evaluation protocols, error bars, data splits, or ablation studies. This prevents verification of whether the unified pretraining objective, rather than the 1B-image dataset scale or undisclosed curation, drives the gains.
Authors: We agree that the experimental section would benefit from expanded descriptions of evaluation protocols, data splits, and error bars to aid reproducibility. In the revised manuscript we will add these details explicitly in §4, including the precise benchmark splits and reporting conventions used for each task. The reported gains are measured against the prior Sapiens model (same architecture family) as well as other published state-of-the-art methods on the respective public benchmarks; these comparisons are already tabulated but will be described more fully in text. Full-scale ablations that hold the 1 B-image curated dataset fixed while varying only the pretraining objective are computationally prohibitive, but we will include smaller-scale controlled experiments (e.g., 100 M images) to provide additional evidence on the contribution of the unified objective versus data scale. revision: partial
-
Referee: §3 (Pretraining): The central assertion that 'this unified pretraining objective is better suited for a wider range of downstream tasks' lacks any controlled comparison holding model scale, data volume, and curation fixed. Without such ablations, the attribution of improvements to masked reconstruction plus self-distilled contrastive learning versus simpler scaling remains untested.
Authors: We acknowledge that a controlled comparison at full scale would strengthen the claim. Repeating the entire 1 B-image pretraining run with alternative objectives is resource-intensive and was not performed. The manuscript motivates the unified objective by the complementary signals it provides (low-level detail from masked reconstruction and semantic robustness from self-distilled contrastive learning), and the downstream results across dense-prediction and zero/few-shot tasks are consistent with this motivation. In revision we will add a limitations paragraph discussing the absence of full-scale ablations and include reduced-scale experiments that hold model size and data volume fixed while varying the pretraining objective. revision: partial
-
Referee: §4.2 (Architectural changes and 4K models): The use of windowed attention for longer context and 2K pretraining resolution is described, but no ablation isolates its contribution to the reported metrics or stability gains relative to standard attention at equivalent compute.
Authors: We will add a dedicated ablation in the revised §4.2 that directly compares windowed attention against standard global attention under matched compute budgets. The study will report effects on training stability (loss curves and convergence speed) as well as downstream metrics for both the 1 K and 4 K model variants, thereby isolating the architectural contribution. revision: yes
Circularity Check
No circularity: purely empirical training and benchmarking
full rationale
The paper reports results from large-scale pretraining and fine-tuning of transformer models on a 1B-image dataset, with performance measured on standard external benchmarks (pose, segmentation, normals, etc.). No equations, fitted parameters, or derivations are presented that could reduce to inputs by construction. Improvements over Sapiens1 are stated as measured outcomes on held-out tasks rather than self-defined or self-cited necessities. Self-reference to prior work is present but does not carry the central claim; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- model parameter counts
- pretraining dataset size
axioms (1)
- domain assumption Transformer architectures with windowed attention can stably train at 2K-4K resolutions for human images.
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebr´on, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head check- points.arXiv preprint arXiv:2305.13245,
work page internal anchor Pith review arXiv
-
[2]
Andrew Aitken, Christian Ledig, Lucas Theis, Jose Caballero, Zehan Wang, and Wenzhe Shi. Checkerboard artifact free sub-pixel convolution: A note on sub-pixel convolution, resize con- volution and convolution resize.arXiv preprint arXiv:1707.02937,
-
[3]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Am- mar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review arXiv
-
[4]
Loss functions in the era of semantic segmentation: A survey and outlook,
Reza Azad, Moein Heidary, Kadir Yilmaz, Michael H¨uttemann, Sanaz Karimijafarbigloo, Yuli Wu, Anke Schmeink, and Dorit Merhof. Loss functions in the era of semantic segmentation: A survey and outlook.arXiv preprint arXiv:2312.05391,
-
[5]
BEiT: BERT Pre-Training of Image Transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254,
work page internal anchor Pith review arXiv
-
[6]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video.arXiv preprint arXiv:2404.08471,
work page internal anchor Pith review arXiv
-
[7]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, Ama ˜AG ¸ l Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. arXiv preprint arXiv:2410.02073,
work page internal anchor Pith review arXiv
-
[8]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, et al. Perception encoder: The best visual embeddings are not at the output of the network.arXiv preprint arXiv:2504.13181,
work page internal anchor Pith review arXiv
-
[9]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pp. 1597–1607. PmLR, 2020a. Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey E Hinton. Big self-supervised models are strong semi-supervised learn...
2026
-
[10]
Meta clip 2: A worldwide scaling recipe.arXiv preprint arXiv:2507.22062,
Yung-Sung Chuang, Yang Li, Dong Wang, Ching-Feng Yeh, Kehan Lyu, Ramya Raghavendra, James Glass, Lifei Huang, Jason Weston, Luke Zettlemoyer, et al. Meta clip 2: A worldwide scaling recipe.arXiv preprint arXiv:2507.22062,
-
[11]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
Convmae: Masked convolution meets masked autoencoders,
Peng Gao, Teli Ma, Hongsheng Li, Ziyi Lin, Jifeng Dai, and Yu Qiao. Convmae: Masked convolu- tion meets masked autoencoders.arXiv preprint arXiv:2205.03892,
-
[13]
Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. Query-key normalization for transformers.arXiv preprint arXiv:2010.04245,
-
[14]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[15]
Sapiens: Foundation for human vision models
12 Published as a conference paper at ICLR 2026 Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, Su Zhaoen, Austin James, Peter Selednik, Stuart Anderson, and Shunsuke Saito. Sapiens: Foundation for human vision models. InEuro- pean Conference on Computer Vision, pp. 206–228. Springer,
2026
-
[16]
Gwanghyun Kim, Xueting Li, Ye Yuan, Koki Nagano, Tianye Li, Jan Kautz, Se Young Chun, and Umar Iqbal. Geoman: Temporally consistent human geometry estimation using image-to-video diffusion.arXiv preprint arXiv:2505.23085, 2025a. Hoon Kim, Minje Jang, Wonjun Yoon, Jisoo Lee, Donghyun Na, and Sanghyun Woo. Switchlight: Co-design of physics-driven architectu...
-
[17]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Xiaoding Lu, Zongyi Liu, Adian Liusie, Vyas Raina, Vineet Mudupalli, Yuwen Zhang, and William Beauchamp. Blending is all you need: Cheaper, better alternative to trillion-parameters llm.arXiv preprint arXiv:2401.02994,
-
[19]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation
AI Meta. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation. https://ai. meta. com/blog/llama-4-multimodal-intelligence/, checked on, 4(7):2025,
2025
-
[20]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
High-fidelity facial albedo estimation via texture quantization.arXiv preprint arXiv:2406.13149,
Zimin Ran, Xingyu Ren, Xiang An, Kaicheng Yang, Xiangzi Dai, Ziyong Feng, Jia Guo, Linchao Zhu, and Jiankang Deng. High-fidelity facial albedo estimation via texture quantization.arXiv preprint arXiv:2406.13149,
-
[22]
Hiera: A hierarchical vision transformer without the bells-and-whistles
13 Published as a conference paper at ICLR 2026 Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Ag- garwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, et al. Hiera: A hierarchical vision transformer without the bells-and-whistles. InInternational conference on machine learn- ing, pp. 29441–29454. PMLR,
2026
-
[23]
Fatemeh Saleh, Sadegh Aliakbarian, Charlie Hewitt, Lohit Petikam, Antonio Criminisi, Thomas J Cashman, Tadas Baltruˇsaitis, et al. David: Data-efficient and accurate vision models from syn- thetic data.arXiv preprint arXiv:2507.15365,
-
[24]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review arXiv 2002
-
[25]
Oriane Sim´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Baptiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Deep learning-based human pose estimation: A survey.ACM computing surveys, 56(1):1–37,
14 Published as a conference paper at ICLR 2026 Ce Zheng, Wenhan Wu, Chen Chen, Taojiannan Yang, Sijie Zhu, Ju Shen, Nasser Kehtarnavaz, and Mubarak Shah. Deep learning-based human pose estimation: A survey.ACM computing surveys, 56(1):1–37,
2026
-
[28]
iBOT: Image BERT Pre-Training with Online Tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. ibot: Image bert pre-training with online tokenizer.arXiv preprint arXiv:2111.07832,
work page internal anchor Pith review arXiv
-
[29]
For instance, we pretrain the SAPIENS2–1B (embed dim1536,40layers,24 heads, patch size16, final norm with [CLS]) at1024×768
15 Published as a conference paper at ICLR 2026 A APPENDIX A.1 PRETRAINING A.1.1 IMPLEMENTATIONDETAILS We use the dense-probing evaluations as the final metrics to guide any design decisions during the pretraining stage. For instance, we pretrain the SAPIENS2–1B (embed dim1536,40layers,24 heads, patch size16, final norm with [CLS]) at1024×768. Training us...
2026
-
[30]
Blockwise Masking Patchwise Masking Figure 11: We randomly mix blockwise and patchwise masking to provide coarse occlusions
At1024×768(64×48=3072 patches), this masks∼2304patches per image, yielding coarse occlusions that regularize MAE while leaving sufficient context for contrastive learning. Blockwise Masking Patchwise Masking Figure 11: We randomly mix blockwise and patchwise masking to provide coarse occlusions. For MAE pre- training at high resolution (1024), we use a75%...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.