Recognition: unknown
Can Large Language Models Assist the Comprehension of ROS2 Software Architectures?
Pith reviewed 2026-05-09 20:46 UTC · model grok-4.3
The pith
Large language models can answer nearly all architecturally relevant questions about ROS2 systems with 98 percent average accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
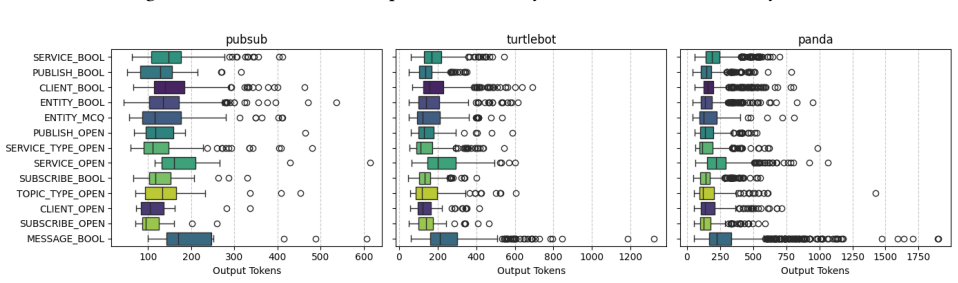
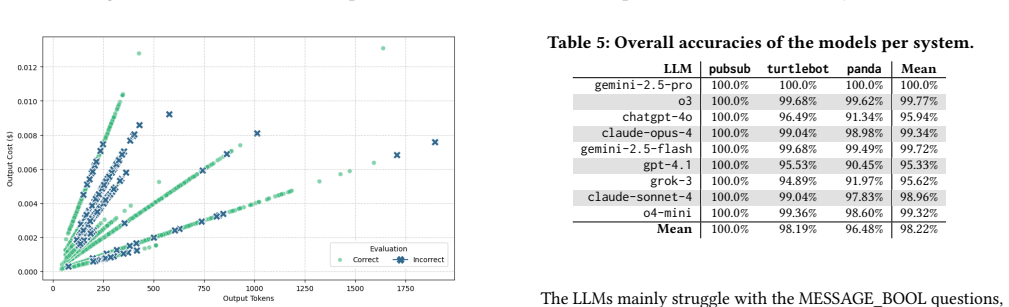
When nine large language models received 1,230 prompts containing architecturally relevant questions about three ROS2 systems, they produced correct answers for 98.22 percent of the questions on average. The top model achieved 100 percent accuracy across every prompt and system, while the weakest reached 95 percent; most incorrect answers concerned the largest of the three systems. Coherence of the models' explanations ranged from 0.394 for service references to 0.762 for communication paths.
What carries the argument
A generic algorithm that systematically produces architecturally relevant questions for any ROS2 system, evaluated for factual accuracy against runtime ground truth collected by executing and monitoring the target systems.
If this is right
- Developers can use LLMs to obtain reliable details on communication paths, node connections, and service references within existing ROS2 codebases.
- Accuracy remains high even for moderately complex systems, but larger systems produce more errors and therefore require extra verification.
- Different models exhibit consistent performance differences, so teams can select stronger models when high reliability is required.
- LLM explanations for architectural facts vary in coherence by topic, with communication paths receiving the most consistent treatment.
Where Pith is reading between the lines
- Embedding such LLM queries inside ROS2 development environments could shorten the time needed to explore unfamiliar codebases.
- The question-generation algorithm could be adapted to produce training data for fine-tuning models on robotics-specific architectures.
- Similar question-and-verify methods may apply to other distributed middleware frameworks beyond ROS2.
Load-bearing premise
The ground truth collected by running and monitoring the three ROS2 systems is complete and unbiased, and the generated questions fairly represent the kinds of information developers actually need.
What would settle it
Applying the same question-generation process to a fourth, independently developed ROS2 system and finding accuracy well below 90 percent would indicate the reported performance does not generalize.
Figures



read the original abstract
Context. The most used development framework for robotics software is ROS2. ROS2 architectures are highly complex, with thousands of components communicating in a decentralized fashion. Goal. We aim to evaluate how LLMs can assist in the comprehension of factual information about the architecture of ROS2 systems. Method. We conduct a controlled experiment where we administer 1,230 prompts to 9 LLMs containing architecturally-relevant questions about 3 ROS2 systems with incremental size. We provide a generic algorithm that systematically generates architecturally-relevant questions for a ROS2 system. Then, we (i) assess the accuracy of the answers of the LLMs against a ground truth established via running and monitoring the 3 ROS2 systems and (ii) qualitatively analyse the explanations provided by the LLMs. Results. Almost all questions are answered correctly across all LLMs (mean=98.22%). gemini-2.5-pro performs best (100% accuracy across all prompts and systems), followed by o3 (99.77%), and gemini-2.5-flash (99.72%); the least performing LLM is gpt-4.1 (95%). Only 300/1,230 prompts are incorrectly answered, of which 249 are about the most complex system. The coherence scores in LLM's explanations range from 0.394 for "service references" to 0.762 for "communication path". The mean perplexity varies significantly across models, with chatgpt-4o achieving the lowest score (19.6) and o4-mini the highest (103.6). Conclusions. There is great potential in the usage of LLMs to aid ROS2 developers in comprehending non-trivial aspects of the software architecture of their systems. Nevertheless, developers should be aware of the intrinsic limitations and different performances of the LLMs and take those into account when using them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a controlled experiment administering 1,230 architecturally relevant questions—generated by a generic algorithm—to nine LLMs across three ROS2 systems of increasing size. Ground truth is obtained by executing and monitoring the systems; the authors report mean accuracy of 98.22% (with gemini-2.5-pro at 100%), analyze explanation coherence and perplexity, and conclude there is great potential for LLMs to aid comprehension of non-trivial ROS2 architecture aspects while noting model-specific limitations.
Significance. If the central accuracy claims hold under validated question sets and complete ground truth, the work provides concrete evidence that current LLMs can reliably extract factual architecture information from ROS2 systems at scale. The independent execution-based ground truth, use of multiple systems, and quantitative plus qualitative analysis are strengths that would make the results useful for both ROS2 practitioners and LLM evaluation in software engineering.
major comments (3)
- [Method] The question-generation algorithm (described in the Method section) produces 1,230 questions claimed to be 'architecturally-relevant,' yet the manuscript provides no validation of ecological validity against real developer needs (e.g., ROS Answers posts, GitHub issues, or expert interviews). Because the central claim of 'great potential' for 'non-trivial aspects' rests on these questions fairly representing developer queries, this omission directly weakens extrapolation from the 98.22% accuracy figure.
- [Method] Ground truth is established solely by running and monitoring the three ROS2 systems (Method and Results sections). This procedure can miss static design decisions, unexecuted code paths, configuration-dependent behaviors, and developer intent. The fact that 249 of the 300 errors occur on the largest system makes it essential to demonstrate that ground-truth incompleteness is not the dominant cause; without such analysis the accuracy numbers cannot be confidently attributed to LLM capability.
- [Results] Table or results breakdown (Results section) shows error concentration on the most complex system, yet the manuscript does not provide a per-question-type or per-system error analysis that distinguishes LLM limitations from possible ground-truth gaps. This analysis is load-bearing for the conclusion that LLMs can handle 'non-trivial' aspects.
minor comments (3)
- Model names in the abstract and results (e.g., 'o3', 'o4-mini', 'chatgpt-4o') should be standardized to official identifiers for reproducibility.
- [Method] The abstract states 'details on prompt construction... are absent,' which should be expanded in the main text with exact prompt templates and handling of ambiguous questions.
- [Results] Coherence scores and perplexity values are reported but the exact formulas and inter-rater reliability for coherence (if any) are not specified.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each of the major comments point-by-point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Method] The question-generation algorithm (described in the Method section) produces 1,230 questions claimed to be 'architecturally-relevant,' yet the manuscript provides no validation of ecological validity against real developer needs (e.g., ROS Answers posts, GitHub issues, or expert interviews). Because the central claim of 'great potential' for 'non-trivial aspects' rests on these questions fairly representing developer queries, this omission directly weakens extrapolation from the 98.22% accuracy figure.
Authors: We agree that direct validation of the generated questions against real developer queries (such as those in ROS Answers or GitHub issues) was not performed in the current study. Our algorithm was designed to systematically cover core architectural elements that are inherently non-trivial, including node interactions, communication paths, and service references. To strengthen the manuscript, we will add a new subsection in the Discussion or Limitations section acknowledging this limitation and outlining plans for future validation through developer surveys or analysis of public ROS2 repositories. This will better contextualize the generalizability of our findings. revision: partial
-
Referee: [Method] Ground truth is established solely by running and monitoring the three ROS2 systems (Method and Results sections). This procedure can miss static design decisions, unexecuted code paths, configuration-dependent behaviors, and developer intent. The fact that 249 of the 300 errors occur on the largest system makes it essential to demonstrate that ground-truth incompleteness is not the dominant cause; without such analysis the accuracy numbers cannot be confidently attributed to LLM capability.
Authors: This is a valid concern, as execution-based ground truth primarily captures runtime behaviors and may overlook purely static or intent-based aspects. We will revise the manuscript to include a more detailed discussion of ground truth limitations in the Method section. Additionally, we will conduct a post-hoc analysis of the 300 erroneous responses (focusing on the 249 from the largest system) by manually inspecting the source code for a subset of cases to determine if ground truth gaps contributed to the errors. The results of this analysis will be reported in the revised Results section to better attribute the accuracy to LLM performance. revision: yes
-
Referee: [Results] Table or results breakdown (Results section) shows error concentration on the most complex system, yet the manuscript does not provide a per-question-type or per-system error analysis that distinguishes LLM limitations from possible ground-truth gaps. This analysis is load-bearing for the conclusion that LLMs can handle 'non-trivial' aspects.
Authors: We concur that a finer-grained error analysis is necessary to support our conclusions. In the revision, we will expand the Results section to include breakdowns of errors by question type (e.g., separating errors on 'communication path' questions from 'service references') and by system size. We will also provide qualitative examples of errors on the largest system, discussing whether they appear to be due to LLM limitations (such as hallucination or misunderstanding) or potential ground truth issues. This will allow readers to better evaluate the claims regarding non-trivial aspects. revision: yes
Circularity Check
No circularity: accuracy derived from independent runtime ground truth
full rationale
The paper's central claim of LLM accuracy (mean 98.22%) is obtained by direct comparison of model answers against a ground truth produced by executing and monitoring the three ROS2 systems. This ground truth is external to the LLM outputs and the question-generation algorithm. No equations, fitted parameters, or self-citations are used to derive the accuracy metric from the LLM responses themselves. The question-generation procedure supplies evaluation inputs but does not reduce the reported performance figures to those inputs by construction. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three ROS2 systems of incremental size are representative of typical real-world ROS2 architectures.
Reference graph
Works this paper leans on
- [1]
-
[2]
Michel Albonico, Andreas Wortmann, and Ivano Malavolta. 2026. Tuning ROS 2 for Energy-Efficient Navigation: Empirical Insights from Costmap 2D Configura- tions. In2026 IEEE International Conference on Robotics and Automation (ICRA). IEEE
2026
-
[3]
Domenico Amalfitano, Marco De Luca, Tiziano Santilli, Patrizio Pelliccione, and Anna Rita Fasolino. 2026. Automated Software Architecture Design Recovery from Source Code Using LLMs. InSoftware Architecture, Vasilios Andrikopoulos, Cesare Pautasso, Nour Ali, Jacopo Soldani, and Xiwei Xu (Eds.). Springer Nature Switzerland, Cham, 73–89
2026
-
[4]
Abdulrahman Ahmed Bobakr Baqais and Mohammad Alshayeb. 2020. Automatic software refactoring: a systematic literature review.Software Quality Journal28, 2 (2020), 459–502
2020
-
[5]
Victor R Basili and H Dieter Rombach. 1988. The TAME project: Towards improvement-oriented software environments.IEEE Transactions on software engineering14, 6 (1988), 758–773
1988
-
[6]
2021.Software architecture in practice
Len Bass, Paul Clements, and Rick Kazman. 2021.Software architecture in practice. Addison-Wesley Professional
2021
-
[7]
Kai Beckman and Jonas Reininger. 2018. Adaptation of the DDS Security Standard for Resource-Constrained Sensor Networks. In2018 IEEE 13th International Sym- posium on Industrial Embedded Systems (SIES). 1–4. doi:10.1109/SIES.2018.8442103
-
[8]
Paulo Canelas, Bradley Schmerl, Alcides Fonesca, and Christopher Steven Timper- ley. 2025. The Usability Argument for ROS-based Robot Architectural Description Languages. InProc. the 15th annual workshop on the intersection of HCI and PL
2025
- [9]
-
[10]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning
2024
-
[11]
Zina Chkirbene, Ridha Hamila, Ala Gouissem, and Unal Devrim. 2024. Large lan- guage models (llm) in industry: A survey of applications, challenges, and trends. In2024 IEEE 21st International Conference on Smart Communities: Improving Quality of Life using AI, Robotics and IoT (HONET). IEEE, 229–234
2024
- [12]
-
[13]
Andrés Díaz-Pace, Antonela Tommasel, and Rafael Capilla
J. Andrés Díaz-Pace, Antonela Tommasel, and Rafael Capilla. 2024. Helping Novice Architects to Make Quality Design Decisions Using an LLM-Based As- sistant. InSoftware Architecture, Matthias Galster, Patrizia Scandurra, Tommi Mikkonen, Pablo Oliveira Antonino, Elisa Yumi Nakagawa, and Elena Navarro (Eds.). Springer Nature Switzerland, Cham, 324–332
2024
-
[14]
Colin Diggs, Michael Doyle, Amit Madan, Eric O. Scott, Emily Escamilla, Jacob Zimmer, Naveed Nekoo, Paul Ursino, Michael Bartholf, Zachary Robin, Anand Patel, Chris Glasz, William Macke, Paul Kirk, Jasper Phillips, Arun Sridharan, Doug Wendt, Scott Rosen, Nitin Naik, Justin F. Brunelle, and Samruddhi Thaker
-
[15]
In2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code)
Leveraging LLMs for Legacy Code Modernization: Evaluation of LLM- Generated Documentation. In2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). 177–184. doi:10.1109/LLM4Code66737. 2025.00027
-
[16]
Open Robotics Discourse. 2025. 2024 ROS Metrics Report. https://discourse. openrobotics.org/t/2024-ros-metrics-report/42354. Forum post, accessed 22 October 2025
2025
-
[17]
Roman Egger and Joanne Yu. 2022. A Topic Modeling Comparison Between LDA, NMF, Top2Vec, and BERTopic to Demystify Twitter Posts.Frontiers in Sociology Volume 7 - 2022 (2022). doi:10.3389/fsoc.2022.886498
-
[18]
Matteo Esposito, Xiaozhou Li, Sergio Moreschini, Noman Ahmad, Tomas Cerny, Karthik Vaidhyanathan, Valentina Lenarduzzi, and Davide Taibi. 2025. Genera- tive ai for software architecture. applications, challenges, and future directions. Journal of Systems and Software(2025), 112607
2025
-
[19]
David Garlan, Bradley Schmerl, and Shang-Wen Cheng. 2009. Software architecture-based self-adaptation. InAutonomic computing and networking. Springer, 31–55
2009
-
[20]
Maarten Grootendorst. 2022. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv:2203.05794 [cs.CL] https://arxiv.org/abs/2203.05794
work page internal anchor Pith review arXiv 2022
-
[21]
Engel Hamer, Michel Albonico, and Ivano Malavolta. 2025. Resource Utilization of 2D SLAM Algorithms in ROS-Based Systems: an Empirical Evaluation.Journal of the Brazilian Computer Society (JBCS)31, 1 (2025), 229–261. doi:10.5753/jbcs. 2025.4343
-
[22]
Mustapha Hankar, Mohammed Kasri, and Abderrahim Beni-Hssane. 2025. A com- prehensive overview of topic modeling: Techniques, applications and challenges. Neurocomputing628 (2025), 129638. doi:10.1016/j.neucom.2025.129638
-
[23]
Hugging Face. 2025. Transformers. https://huggingface.co/docs/transformers/ index
2025
-
[24]
IFRA Group, Cranfield University. 2022. ros2_RobotSimulation: Ready-to-use ROS 2 Gazebo + MoveIt!2 simulation packages for industrial and collaborative robots. https://github.com/IFRA-Cranfield/ros2_RobotSimulation
2022
-
[25]
iRobot ROS. 2019. iRobot ROS 2 Performance Evaluation Framework. https: //github.com/irobot-ros/ros2-performance. Accessed: 27/03/2025
2019
-
[26]
Abhishek Kumar Kashyap and Kavya Konathalapalli. 2025. Autonomous nav- igation of ROS2 based Turtlebot3 in static and dynamic environments using intelligent approach.International Journal of Information Technology(2025), 1–23
2025
-
[27]
Laura Duits and Bouazza El Moutaouakil and Ivano Malavolta. 2026. Replication package of this study. https://figshare.com/s/bb59cd6b6e03a5e861ca
2026
-
[28]
Athul Krishna M J, Ajai V Babu, Suraj Damodaran, Rekha K James, Muhammed Murshid, and Tripti S Warrier. 2024. ROS2 - Powered Autonomous Navigation for TurtleBot3: Integrating Nav2 Stack in Gazebo, RViz and Real-World Environments. In2024 IEEE International Conference on Signal Processing, Informatics, Communi- cation and Energy Systems (SPICES). 1–6. doi:...
-
[29]
Steven Macenski, Tully Foote, Brian Gerkey, Chris Lalancette, and William Woodall. 2022. Robot operating system 2: Design, architecture, and uses in the wild.Science robotics7, 66 (2022), eabm6074
2022
-
[30]
Lewis, Bradley Schmerl, Patricia Lago, and David Garlan
Ivano Malavolta, Grace A. Lewis, Bradley Schmerl, Patricia Lago, and David Garlan. 2021. Mining guidelines for architecting robotics software.Journal of Systems and Software178 (2021), 110969. doi:10.1016/j.jss.2021.110969
-
[31]
Yuya Maruyama, Shinpei Kato, and Takuya Azumi. 2016. Exploring the perfor- mance of ROS2.2016 International Conference on Embedded Software (EMSOFT) (2016), 1–10. https://api.semanticscholar.org/CorpusID:9703204
2016
-
[32]
Ran Mo, Yuanfang Cai, Rick Kazman, Lu Xiao, and Qiong Feng. 2019. Architecture anti-patterns: Automatically detectable violations of design principles.IEEE Transactions on Software Engineering47, 5 (2019), 1008–1028
2019
-
[33]
José Francisco Molina Santiago, José-Armando Fragoso-Mandujano, Samuel Gómez-Peñate, Victor David Castillo González, and Francisco-Ronay López- Estrada. 2023. Trajectory Tracking and Obstacle Avoidance with Turtlebot 3 Burger and ROS 2. In2023 XXV Robotics Mexican Congress (COMRob). 93–98. doi:10.1109/COMRob60035.2023.10349744
-
[34]
Open Robotics. [n. d.]. Writing a Simple Publisher and Subscriber (Python). https://docs.ros.org/en/humble/Tutorials/Beginner-Client-Libraries/ Writing-A-Simple-Py-Publisher-And-Subscriber.html
-
[35]
Pardo-Castellote
G. Pardo-Castellote. 2003. OMG Data-Distribution Service: architectural overview. In23rd International Conference on Distributed Computing Systems Workshops,
2003
-
[36]
doi:10.1109/ICDCSW.2003.1203555
Proceedings.200–206. doi:10.1109/ICDCSW.2003.1203555
-
[37]
Morgan Quigley, Ken Conley, Brian Gerkey, Josh Faust, Tully Foote, Jeremy Leibs, Rob Wheeler, Andrew Y Ng, et al. 2009. ROS: an open-source Robot Operating System. InICRA workshop on open source software, Vol. 3. Kobe, 5
2009
-
[38]
ROBOTIS Co., Ltd. [n. d.]. TurtleBot3 Simulation Documentation. https://emanual. robotis.com/docs/en/platform/turtlebot3/simulation/
- [39]
-
[40]
Mohamed Soliman, Elia Ashraf, Kamel M. K. Abdelsalam, Jan Keim, and Ashwin Prasad Shivarpatna Venkatesh. 2026. LLMs for Software Architecture Knowledge: EASE 2026, 9–12 June, 2026, Glasgow, Scotland, United Kingdom Laura Duits, Bouazza El Moutaouakil, and Ivano Malavolta A Comparative Analysis Among Seven LLMs. InSoftware Architecture, Vasilios Andrikopou...
2026
-
[41]
Mohamed Soliman and Jan Keim. 2025. Do Large Language Models Contain Software Architectural Knowledge? : An Exploratory Case Study with GPT. In 2025 IEEE 22nd International Conference on Software Architecture (ICSA). 13–24. doi:10.1109/ICSA65012.2025.00012
-
[42]
Karthik Vaidhyanathan and Henry Muccini. 2025. Software Architecture in the Age of Agentic AI. InEuropean Conference on Software Architecture. Springer, 41–49
2025
-
[43]
Jianxun Wang and Yixiang Chen. 2023. A Review on Code Generation with LLMs: Application and Evaluation. In2023 IEEE International Conference on Medical Artificial Intelligence (MedAI). 284–289. doi:10.1109/MedAI59581.2023.00044
- [44]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.