Recognition: unknown
High-Fidelity 3D Gaussian Human Reconstruction via Region-Aware Initialization and Geometric Priors
Pith reviewed 2026-05-10 02:36 UTC · model grok-4.3
The pith
Initializing 3D Gaussians via SMPL-X and region-aware strategies delivers high-fidelity dynamic human reconstruction at real-time speeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
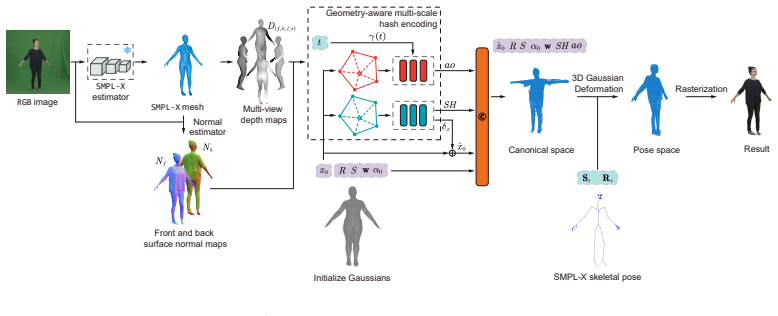
The central discovery is a 3D Gaussian human reconstruction framework that leverages the SMPL-X model for initializing both 3D Gaussians and skinning weights as a robust geometric foundation, further enhanced by a region-aware density initialization strategy and a geometry-aware multi-scale hash encoding module to recover local details efficiently.
What carries the argument
Region-aware density initialization and geometry-aware multi-scale hash encoding applied to SMPL-X-initialized 3D Gaussians and skinning weights for dynamic human modeling.
If this is right
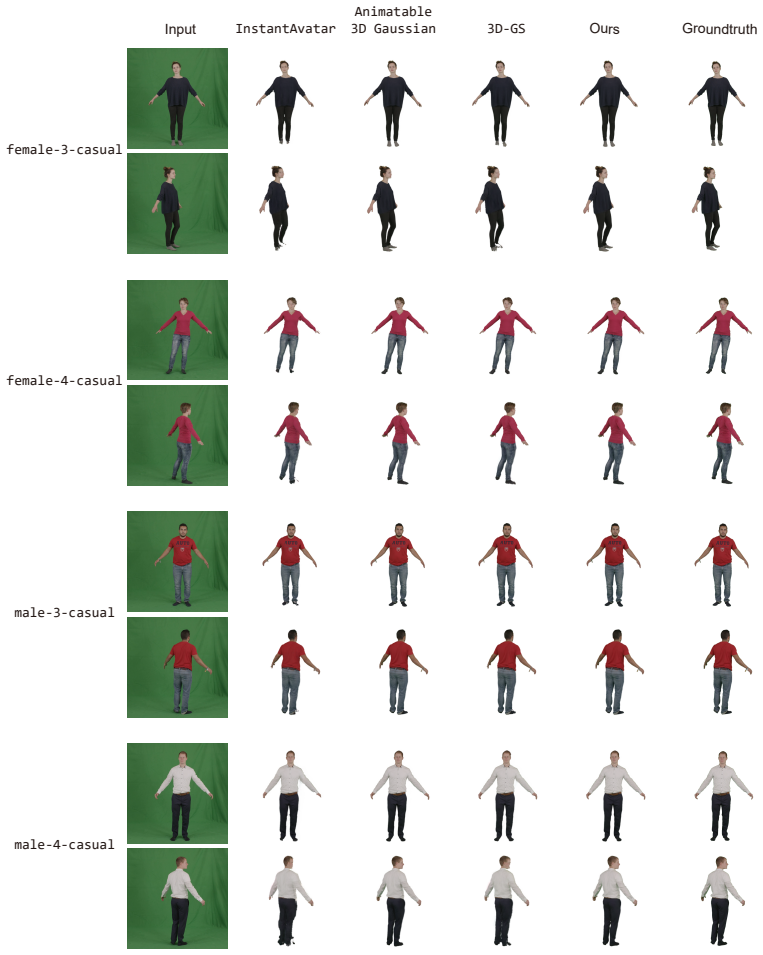
- The method outperforms prior approaches in reconstruction quality on the PeopleSnapshot and GalaBasketball datasets.
- Fine details are preserved in complex motions without artifacts such as fused fingers or smoothed faces.
- Real-time rendering is achieved without additional GPU memory overhead.
- Local details are recovered more effectively through the combination of geometric priors and multi-scale encoding.
Where Pith is reading between the lines
- The reliance on SMPL-X could limit applicability to clothed humans with loose garments not well-modeled by the template.
- Similar initialization strategies might improve 3D reconstruction of other deformable objects like animals if parametric models exist.
- Combining this with learned appearance models could further enhance photorealism in rendered outputs.
- Deployment in mobile VR applications would require verifying the real-time performance on lower-end hardware.
Load-bearing premise
That the SMPL-X model provides a robust geometric foundation via initialization of 3D Gaussians and skinning weights, and that the region-aware density initialization strategy together with the geometry-aware multi-scale hash encoding module will improve local detail recovery without new artifacts or memory trade-offs.
What would settle it
Failure to show measurable improvement in detail metrics or the appearance of new artifacts in tests on complex motion sequences from the PeopleSnapshot dataset would indicate the approach does not deliver the claimed benefits.
Figures




read the original abstract
Real-time, high-fidelity 3D human reconstruction from RGB images is essential for interactive applications such as virtual reality and gaming, yet remains challenging due to the complex non-rigid deformations of dynamic human bodies. Although 3D Gaussian Splatting enables efficient rendering, existing methods struggle to capture fine geometric details and often produce artifacts such as fused fingers and over-smoothed faces. Moreover, conventional spatial-field-based dynamic modeling faces a trade-off between reconstruction fidelity and GPU memory consumption. To address these issues, we propose a novel 3D Gaussian human reconstruction framework that combines region-aware initialization with rich geometric priors. Specifically, we leverage the expressive SMPL-X model to initialize both 3D Gaussians and skinning weights, providing a robust geometric foundation for precise reconstruction. We further introduce a region-aware density initialization strategy and a geometry-aware multi-scale hash encoding module to improve local detail recovery while maintaining computational efficiency.Experiments on PeopleSnapshot and GalaBasketball show that our method achieves superior reconstruction quality and finer detail preservation under complex motions, while maintaining real-time rendering speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a novel 3D Gaussian human reconstruction framework that uses the SMPL-X model to initialize both 3D Gaussians and skinning weights, combined with a region-aware density initialization strategy and a geometry-aware multi-scale hash encoding module. This is asserted to deliver superior reconstruction quality and finer detail preservation under complex motions on the PeopleSnapshot and GalaBasketball datasets while maintaining real-time rendering speed.
Significance. If the quantitative results and ablations support the claims, the work could advance practical real-time dynamic human modeling for VR and gaming by improving local detail recovery without excessive memory overhead. The integration of established geometric priors from SMPL-X with Gaussian splatting is a pragmatic strength for reproducibility, but the significance hinges on demonstrating that the added modules genuinely enhance fidelity beyond what standard initialization provides.
major comments (2)
- [Abstract and §5] Abstract and §5 (Experiments): the central claim of superior reconstruction quality and finer detail preservation is asserted without any quantitative metrics (e.g., PSNR, SSIM, LPIPS), baselines, error analysis, or ablation results in the provided information. This is load-bearing because the significance of the region-aware and hash-encoding modules cannot be assessed without evidence that they improve over SMPL-X initialization alone.
- [§3.1] §3.1 (SMPL-X Initialization): the method relies on SMPL-X supplying a robust geometric foundation for Gaussian placement and skinning weights, yet no analysis or correction mechanism is described for known SMPL-X inaccuracies in fine structures (e.g., fingers) or extreme poses. This directly risks the claim that downstream modules recover local detail without new artifacts, as initialization errors may persist or be amplified under complex motions.
minor comments (2)
- [§3.3] §3.3 (Hash Encoding Module): the multi-scale aspect of the geometry-aware encoding would benefit from an explicit equation or pseudocode showing how scales are fused, as the current description leaves the memory-efficiency trade-off unclear.
- [Figure captions and §4] Figure captions and §4: some figures comparing reconstructions lack side-by-side baseline results or zoomed insets on challenging regions (hands, faces), reducing clarity of the qualitative claims.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which help us improve the clarity and robustness of our manuscript. We address the major comments point by point below, providing clarifications and committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experiments): the central claim of superior reconstruction quality and finer detail preservation is asserted without any quantitative metrics (e.g., PSNR, SSIM, LPIPS), baselines, error analysis, or ablation results in the provided information. This is load-bearing because the significance of the region-aware and hash-encoding modules cannot be assessed without evidence that they improve over SMPL-X initialization alone.
Authors: We appreciate this observation. While the abstract provides a high-level summary without specific numbers to maintain brevity, the full manuscript in Section 5 presents quantitative results including PSNR, SSIM, and LPIPS metrics on the PeopleSnapshot and GalaBasketball datasets. It includes comparisons against relevant baselines and ablation studies demonstrating the contributions of the region-aware density initialization and geometry-aware multi-scale hash encoding. These results support that our modules enhance fidelity beyond standard SMPL-X initialization. To make this more prominent, we will revise the abstract to include key quantitative improvements and add cross-references in the abstract to the experimental section. This will ensure the claims are clearly evidenced. revision: partial
-
Referee: [§3.1] §3.1 (SMPL-X Initialization): the method relies on SMPL-X supplying a robust geometric foundation for Gaussian placement and skinning weights, yet no analysis or correction mechanism is described for known SMPL-X inaccuracies in fine structures (e.g., fingers) or extreme poses. This directly risks the claim that downstream modules recover local detail without new artifacts, as initialization errors may persist or be amplified under complex motions.
Authors: We agree that SMPL-X can exhibit inaccuracies in fine details such as fingers and in extreme poses. Our framework uses SMPL-X primarily for initialization of Gaussians and skinning weights, after which the 3D Gaussian optimization, combined with the region-aware density strategy and multi-scale hash encoding, refines the reconstruction to recover local details. We will add a dedicated paragraph in §3.1 discussing the known limitations of SMPL-X and how our subsequent modules mitigate potential propagation of errors, supported by qualitative examples from our experiments showing improved finger separation and pose handling. This will strengthen the manuscript without altering the core method. revision: yes
Circularity Check
No significant circularity; derivation relies on external models and independent modules
full rationale
The paper's core chain initializes 3D Gaussians and skinning weights from the external SMPL-X model, then applies a region-aware density strategy and geometry-aware multi-scale hash encoding to recover details. No equations, predictions, or claims in the abstract reduce by construction to fitted parameters or self-referential definitions. No self-citations, uniqueness theorems, or ansatz smuggling are present. The method is self-contained against external benchmarks (PeopleSnapshot, GalaBasketball) with experimental validation that does not tautologically restate inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SMPL-X model supplies accurate initial 3D Gaussians and skinning weights for human bodies
Reference graph
Works this paper leans on
-
[1]
H. Xie, X. Zhang, Y. Zhu, Nsghg: Neural surface guided generalizable hu- man gaussian splatting for sparse view synthesis, Neurocomputing 653 (2025) 131207
2025
-
[2]
Nazir, O
S. Nazir, O. Lézoray, S. Bougleux, 3dgeomeshnet: A multi-scale graph auto- encoder for 3d mesh reconstruction and completion, Neurocomputing (2026) 132652
2026
-
[3]
Mildenhall, P
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, R. Ng, Nerf: Representing scenes as neural radiance fields for view synthesis, Communications of the ACM 65 (1) (2021) 99–106
2021
- [4]
-
[5]
S. Peng, Y. Zhang, Y. Xu, Q. Wang, Q. Shuai, H. Bao, X. Zhou, Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 9054–9063
2021
-
[6]
Y. Xiu, J. Yang, D. Tzionas, M. J. Black, Icon: Implicit clothed humans obtained from normals, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2022, pp. 13286– 13296
2022
-
[7]
Y. Xiu, J. Yang, X. Cao, D. Tzionas, M. J. Black, Econ: Explicit clothed humans optimized via normal integration, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 512–523
2023
-
[8]
Fridovich-Keil, A
S. Fridovich-Keil, A. Yu, M. Tancik, Q. Chen, B. Recht, A. Kanazawa, Plenoxels: Radiance fields without neural networks, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 5501–5510
2022
-
[9]
Müller, A
T. Müller, A. Evans, C. Schied, A. Keller, Instant neural graphics primitives with a multiresolution hash encoding, ACM Transactions on Graphics (TOG) 41 (4) (2022) 1–15
2022
-
[10]
C. Sun, M. Sun, H.-T. Chen, Direct voxel grid optimization: Super-fast con- vergence for radiance fields reconstruction, in: Proceedings of the IEEE/CVF 24 Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 5459–5469
2022
-
[11]
L. Wang, J. Zhang, X. Liu, F. Zhao, Y. Zhang, Y. Zhang, M. Wu, J. Yu, L. Xu, Fourier plenoctrees for dynamic radiance field rendering in real-time, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2022, pp. 13524–13534
2022
-
[12]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimkühler, G. Drettakis, et al., 3d gaussian splat- ting for real-time radiance field rendering, ACM Transactions on Graphics (TOG) 42 (4) (2023) 139:1–139:14
2023
-
[13]
Q. Li, R. Fu, Novel view synthesis for underwater scene with gaussian splat fields and physically-based water modeling, Neurocomputing (2026) 133060
2026
-
[14]
K. Wang, K. Wei, S.-Y. Li, Dynamic view synthesis with topologically- varying neural radiance fields from sparse input views, Neurocomputing (2026) 132942
2026
-
[15]
Y. Liu, X. Huang, M. Qin, Q. Lin, H. Wang, Animatable 3d gaussian: Fast and high-quality reconstruction of multiple human avatars, in: Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1120–1129
2024
-
[16]
Loper, N
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, M. J. Black, Smpl: A skinned multi-person linear model, in: Seminal Graphics Papers: Pushing the Boundaries, Volume 2, 2023, pp. 851–866
2023
-
[17]
Pavlakos, V
G. Pavlakos, V. Choutas, N. Ghorbani, T. Bolkart, A. A. Osman, D. Tzionas, M. J. Black, Expressive body capture: 3d hands, face, and body from a single image, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10975–10985
2019
-
[18]
Collet, M
A. Collet, M. Chuang, P. Sweeney, D. Gillett, D. Evseev, D. Calabrese, H. Hoppe, A. Kirk, S. Sullivan, High-quality streamable free-viewpoint video, ACM Transactions on Graphics (ToG) 34 (4) (2015) 1–13
2015
-
[19]
Habermann, L
M. Habermann, L. Liu, W. Xu, G. Pons-Moll, M. Zollhoefer, C. Theobalt, Hdhumans: A hybrid approach for high-fidelity digital humans, Proceedings of the ACM on Computer Graphics and Interactive Techniques 6 (3) (2023) 1–23
2023
-
[20]
H.-I. Ho, L. Xue, J. Song, O. Hilliges, Learning locally editable virtual hu- mans, in: Proceedings of the IEEE/cvf conference on computer vision and pattern recognition, 2023, pp. 21024–21035
2023
-
[21]
Z. Chai, H. Zhang, J. Ren, D. Kang, Z. Xu, X. Zhe, C. Yuan, L. Bao, Realy: Rethinking the evaluation of 3d face reconstruction, in: European conference on computer vision, Springer, 2022, pp. 74–92
2022
-
[22]
T. Li, T. Bolkart, M. J. Black, H. Li, J. Romero, Learning a model of facial shape and expression from 4d scans., ACM Trans. Graph. 36 (6) (2017) 194–1
2017
-
[23]
S. Ma, T. Simon, J. Saragih, D. Wang, Y. Li, F. De La Torre, Y. Sheikh, Pixel 25 codec avatars, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 64–73
2021
-
[24]
Xiang, F
D. Xiang, F. Prada, T. Bagautdinov, W. Xu, Y. Dong, H. Wen, J. Hodgins, C. Wu, Modeling clothing as a separate layer for an animatable human avatar, ACM Transactions on Graphics (TOG) 40 (6) (2021) 1–15
2021
-
[25]
Q. Ma, J. Yang, A. Ranjan, S. Pujades, G. Pons-Moll, S. Tang, M. J. Black, Learning to dress 3d people in generative clothing, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 6469–6478
2020
-
[26]
Prokudin, M
S. Prokudin, M. J. Black, J. Romero, Smplpix: Neural avatars from 3d human models, in: Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 1810–1819
2021
-
[27]
X. Chen, Y. Zheng, M. J. Black, O. Hilliges, A. Geiger, Snarf: Differentiable forward skinning for animating non-rigid neural implicit shapes, in: Proceed- ings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 11594–11604
2021
-
[28]
X. Chen, T. Jiang, J. Song, M. Rietmann, A. Geiger, M. J. Black, O. Hilliges, Fast-snarf: A fast deformer for articulated neural fields, IEEE Transactions on Pattern Analysis and Machine Intelligence 45 (10) (2023) 11796–11809
2023
-
[29]
K. Shen, C. Guo, M. Kaufmann, J. J. Zarate, J. Valentin, J. Song, O. Hilliges, X-avatar: Expressive human avatars, in: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2023, pp. 16911–16921
2023
-
[30]
Grassal, M
P.-W. Grassal, M. Prinzler, T. Leistner, C. Rother, M. Nießner, J. Thies, Neural head avatars from monocular rgb videos, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18653–18664
2022
-
[31]
S. Bharadwaj, Y. Zheng, O. Hilliges, M. J. Black, V. Fernandez-Abrevaya, Flare: Fast learning of animatable and relightable mesh avatars, arXiv preprint arXiv:2310.17519 (2023)
-
[32]
Z. Bai, F. Tan, Z. Huang, K. Sarkar, D. Tang, D. Qiu, A. Meka, R. Du, M. Dou, S. Orts-Escolano, et al., Learning personalized high quality volumet- ric head avatars from monocular rgb videos, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 16890– 16900
2023
-
[33]
Jiang, X
T. Jiang, X. Chen, J. Song, O. Hilliges, Instantavatar: Learning avatars from monocular video in 60 seconds, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 16922– 16932
2023
-
[34]
S. Peng, J. Dong, Q. Wang, S. Zhang, Q. Shuai, X. Zhou, H. Bao, Animatable neural radiance fields for modeling dynamic human bodies, in: Proceedings of 26 the IEEE/CVF international conference on computer vision, 2021, pp. 14314– 14323
2021
-
[35]
H. Xu, T. Alldieck, C. Sminchisescu, H-nerf: Neural radiance fields for ren- dering and temporal reconstruction of humans in motion, Advances in Neural Information Processing Systems 34 (2021) 14955–14966
2021
-
[36]
Z. Yu, W. Cheng, X. Liu, W. Wu, K.-Y. Lin, Monohuman: Animatable human neural field from monocular video, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 16943– 16953
2023
-
[37]
Zielonka, T
W. Zielonka, T. Bolkart, J. Thies, Instant volumetric head avatars, in: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, 2023, pp. 4574–4584
2023
-
[38]
C. Guo, T. Jiang, X. Chen, J. Song, O. Hilliges, Vid2avatar: 3d avatar recon- struction from videos in the wild via self-supervised scene decomposition, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 12858–12868
2023
-
[39]
Zwicker, H
M. Zwicker, H. Pfister, J. Van Baar, M. Gross, Ewa volume splatting, in: Proceedings Visualization, 2001. VIS’01., IEEE, 2001, pp. 29–538
2001
-
[40]
X. Cao, H. Santo, B. Shi, F. Okura, Y. Matsushita, Bilateral normal inte- gration, in: Proceedings of the European Conference on Computer Vision (ECCV), Springer, 2022, pp. 552–567
2022
-
[41]
Alldieck, M
T. Alldieck, M. Magnor, W. Xu, C. Theobalt, G. Pons-Moll, Detailed human avatars from monocular video, in: 2018 International Conference on 3D Vision (3DV), IEEE, 2018, pp. 98–109
2018
-
[42]
Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, Image quality as- sessment: from error visibility to structural similarity, IEEE Transactions on Image Processing (TIP) 13 (4) (2004) 600–612
2004
-
[43]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, O. Wang, The unreason- able effectiveness of deep features as a perceptual metric, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 586–595. 27
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.