Recognition: unknown
Ramen: Robust Test-Time Adaptation of Vision-Language Models with Active Sample Selection
Pith reviewed 2026-05-09 21:40 UTC · model grok-4.3
The pith
Ramen adapts vision-language models at test time by retrieving matching past samples and balancing predictions to handle mixed domains without extra passes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ramen retrieves, for each incoming test sample, a customized batch of relevant past samples chosen by domain consistency and prediction balance, then aggregates the corresponding cached gradients to update the model. An embedding-gradient cache stores prior embeddings for retrieval and gradients for aggregation, eliminating any need for additional forward or backward passes during inference. Theoretical analysis shows why this selection mechanism remains effective under mixed-domain shifts.
What carries the argument
Active sample selection driven by domain consistency and prediction balance, supported by an embedding-gradient cache that stores past embeddings for retrieval and gradients for direct aggregation.
If this is right
- Adaptation remains efficient because cached gradients replace any new forward or backward computations.
- Performance holds steady across mixed-domain test streams where prior methods degrade.
- The same selection logic applies to both image corruption and domain-shift benchmarks.
- Theoretical support explains the stability of updates when domain consistency guides sample choice.
Where Pith is reading between the lines
- The cache-based update pattern could reduce compute costs in other online adaptation settings that process sequential data.
- Deployment systems might monitor domain-consistency scores as an early indicator of when adaptation should activate.
- The selection criteria may transfer to other multimodal models that face streaming inputs from varying sources.
- Real-world testing on unlabeled video or sensor streams with natural domain mixing would further check the method's scope.
Load-bearing premise
Test samples arrive from mixed domains that exhibit detectable consistencies allowing reliable selection of relevant past samples without labels or source data.
What would settle it
Ramen shows lower accuracy than zero-shot inference or standard single-domain test-time adaptation on a benchmark constructed with deliberately mixed domains that lack clear consistency signals.
Figures







read the original abstract
Pretrained vision-language models such as CLIP exhibit strong zero-shot generalization but remain sensitive to distribution shifts. Test-time adaptation adapts models during inference without access to source data or target labels, offering a practical way to handle such shifts. However, existing methods typically assume that test samples come from a single, consistent domain, while in practice, test data often include samples from mixed domains with distinct characteristics. Consequently, their performance degrades under mixed-domain settings. To address this, we present Ramen, a framework for robust test-time adaptation through active sample selection. For each incoming test sample, Ramen retrieves a customized batch of relevant samples from previously seen data based on two criteria: domain consistency, which ensures that adaptation focuses on data from similar domains, and prediction balance, which mitigates adaptation bias caused by skewed predictions. To improve efficiency, Ramen employs an embedding-gradient cache that stores the embeddings and sample-level gradients of past test images. The stored embeddings are used to retrieve relevant samples, and the corresponding gradients are aggregated for model updates, eliminating the need for any additional forward or backward passes. Our theoretical analysis provides insight into why the proposed adaptation mechanism is effective under mixed-domain shifts. Experiments on multiple image corruption and domain-shift benchmarks demonstrate that Ramen achieves strong and consistent performance, offering robust and efficient adaptation in complex mixed-domain scenarios. Our code is available at https://github.com/baowenxuan/Ramen .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
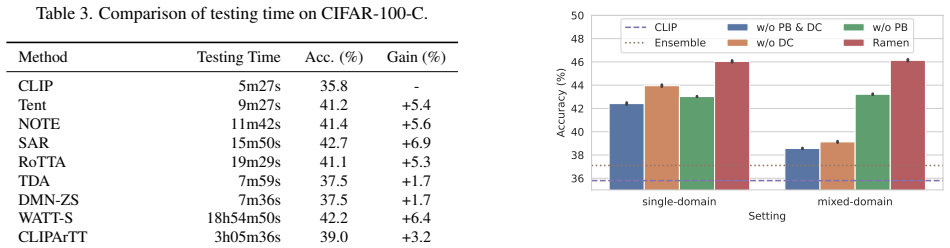
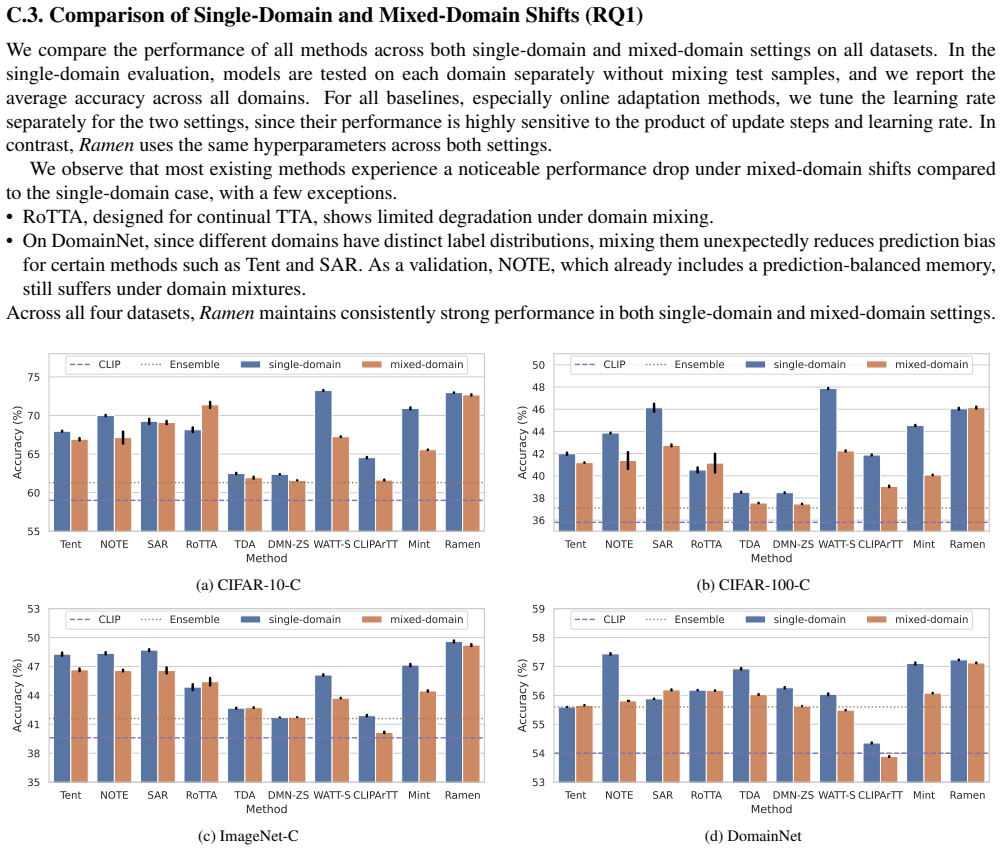
Summary. The manuscript proposes Ramen, a test-time adaptation framework for vision-language models (e.g., CLIP) that targets mixed-domain test streams. For each incoming sample it retrieves a customized batch from a cache of prior test embeddings using two selection criteria—domain consistency and prediction balance—then aggregates the corresponding cached gradients to perform an update without additional forward or backward passes. A theoretical analysis is provided to explain why the mechanism remains effective under mixed shifts, and the method is evaluated on standard image-corruption and domain-shift benchmarks under explicit mixed-domain streaming protocols.
Significance. If the reported gains hold, the work addresses a practically important gap: existing TTA methods degrade when test data arrive from multiple domains simultaneously, a common real-world condition. The active-selection-plus-cache design yields both robustness and computational efficiency, and the public code release supports reproducibility. The theoretical insight into the adaptation mechanism under mixed shifts is a modest but useful contribution.
minor comments (3)
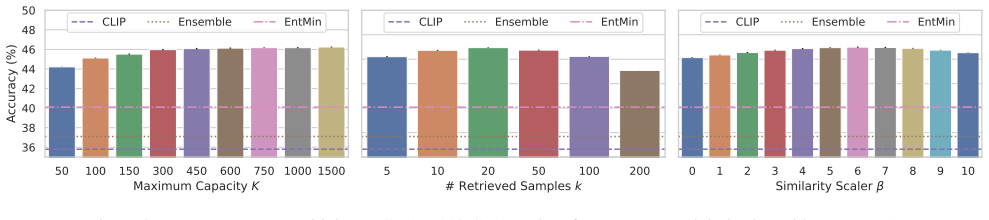
- [§3] §3 (Method): the precise definition and hyper-parameter sensitivity of the 'domain consistency' and 'prediction balance' scores should be stated explicitly, including how domain clusters are formed from embeddings without access to domain labels.
- [§5] §5 (Experiments): the mixed-domain streaming protocol (e.g., domain mixing ratios, arrival order) is described but not ablated; a controlled sweep over mixing ratios would strengthen the robustness claim.
- [Theoretical Analysis] The theoretical analysis paragraph would benefit from a short statement of the key assumptions (e.g., embedding separability) that make the domain-consistency criterion effective.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work, the recognition of its practical significance for mixed-domain test-time adaptation, and the recommendation for minor revision. We appreciate the acknowledgment of the active-selection mechanism, cache-based efficiency, and theoretical analysis.
Circularity Check
No significant circularity identified
full rationale
The paper's central method selects test samples via domain consistency and prediction balance criteria, retrieves them using an embedding cache, aggregates stored gradients for updates, and applies standard TTA losses to the resulting batches. This construction is described directly in terms of the incoming data stream and prior computations without reducing any claimed prediction or theoretical insight to a fitted parameter or self-defined quantity by construction. The theoretical analysis is presented as explanatory insight into the mixed-domain mechanism rather than a uniqueness theorem or ansatz justified only by prior self-work. Experiments follow from applying the described selection and caching process to established benchmarks under explicit mixed-domain protocols. No load-bearing step equates an output to its input via definition, renaming, or self-citation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lei Jimmy Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.CoRR, abs/1607.06450, 2016. 4, 14, 15
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Adaptive test-time personalization for federated learning
Wenxuan Bao, Tianxin Wei, Haohan Wang, and Jingrui He. Adaptive test-time personalization for federated learning. In Advances in Neural Information Processing Systems 36: An- nual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. 13
2023
-
[3]
Mint: A sim- ple test-time adaptation of vision-language models against common corruptions
Wenxuan Bao, Ruxi Deng, and Jingrui He. Mint: A sim- ple test-time adaptation of vision-language models against common corruptions. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Infor- mation Processing Systems 2025, NeurIPS 2025, San Diego, CA, USA, December 2 - 7, 2025, 2025. 2, 4, 6, 7, 15, 17, 18, 24
2025
-
[4]
Latte: Collaborative test-time adaptation of vision-language models in federated learning
Wenxuan Bao, Ruxi Deng, Ruizhong Qiu, Tianxin Wei, Hanghang Tong, and Jingrui He. Latte: Collaborative test-time adaptation of vision-language models in federated learning. InIEEE/CVF International Conference on Com- puter Vision, ICCV 2025, Honolulu, Hawaii, USA, October 19-23, 2025. IEEE, 2025. 4, 13
2025
-
[5]
Matcha: Mitigating graph structure shifts with test-time adaptation
Wenxuan Bao, Zhichen Zeng, Zhining Liu, Hanghang Tong, and Jingrui He. Matcha: Mitigating graph structure shifts with test-time adaptation. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Sin- gapore, April 24-28, 2025. OpenReview.net, 2025. 13
2025
-
[6]
Food-101 - mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101 - mining discriminative components with random forests. InComputer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VI, pages 446–461. Springer, 2014. 5
2014
-
[7]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20- 25 June 2009, Miami, Florida, USA, pages 248–255. IEEE Computer Society, 2009. 5
2009
-
[8]
Panda: Test-time adaptation with negative data augmenta- tion
Ruxi Deng, Wenxuan Bao, Tianxin Wei, and Jingrui He. Panda: Test-time adaptation with negative data augmenta- tion. InFortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Arti- ficial Intelligence, Sixteenth Symposium on Educational Ad- vances in Artificial Intelligence, AAAI 2026, Singapore, Jan- uar...
2026
-
[9]
Marsden, Tobias Raichle, and Bin Yang
Mario D ¨obler, Robert A. Marsden, Tobias Raichle, and Bin Yang. A lost opportunity for vision-language models: A comparative study of online test-time adaptation for vision- language models. InComputer Vision - ECCV 2024 Work- shops - Milan, Italy, September 29-October 4, 2024, Pro- ceedings, Part XVIII, pages 117–133. Springer, 2024. 1, 2, 3, 17
2024
-
[10]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Rep- resentations, ICLR 202...
2021
-
[11]
OpenReview.net, 2021. 5
2021
-
[12]
Frustratingly easy test-time adaptation of vision-language models
Matteo Farina, Gianni Franchi, Giovanni Iacca, Massimil- iano Mancini, and Elisa Ricci. Frustratingly easy test-time adaptation of vision-language models. InAdvances in Neu- ral Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024,
2024
-
[13]
NOTE: robust continual test-time adaptation against temporal correlation
Taesik Gong, Jongheon Jeong, Taewon Kim, Yewon Kim, Jinwoo Shin, and Sung-Ju Lee. NOTE: robust continual test-time adaptation against temporal correlation. InAd- vances in Neural Information Processing Systems 35: An- nual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. 2,...
2022
-
[14]
Sotta: Robust test-time adaptation on noisy data streams
Taesik Gong, Yewon Kim, Taeckyung Lee, Sorn Chottana- nurak, and Sung-Ju Lee. Sotta: Robust test-time adaptation on noisy data streams. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Infor- mation Processing Systems 2023, NeurIPS 2023, New Or- leans, LA, USA, December 10 - 16, 2023, 2023. 13
2023
-
[15]
In search of lost domain generalization
Ishaan Gulrajani and David Lopez-Paz. In search of lost domain generalization. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Aus- tria, May 3-7, 2021. OpenReview.net, 2021. 1, 2, 17
2021
-
[16]
Cli- partt: Adaptation of CLIP to new domains at test time
Gustavo Adolfo Vargas Hakim, David Osowiechi, Mehrdad Noori, Milad Cheraghalikhani, Ali Bahri, Moslem Yazdan- panah, Ismail Ben Ayed, and Christian Desrosiers. Cli- partt: Adaptation of CLIP to new domains at test time. In IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2025, Tucson, AZ, USA, February 26 - March 6, 2025, pages 7092–710...
2025
-
[17]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV , USA, June 27-30, 2016, pages 770–778. IEEE Computer Society, 2016. 24
2016
-
[18]
Dietterich
Dan Hendrycks and Thomas G. Dietterich. Benchmarking neural network robustness to common corruptions and per- turbations. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. 1, 2, 5, 17
2019
-
[19]
The many faces of robustness: A crit- ical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kada- vath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, Dawn Song, Jacob Steinhardt, and Justin Gilmer. The many faces of robustness: A crit- ical analysis of out-of-distribution generalization. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal,...
2021
-
[20]
Natural adversarial examples
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Stein- hardt, and Dawn Song. Natural adversarial examples. In IEEE Conference on Computer Vision and Pattern Recogni- tion, CVPR 2021, virtual, June 19-25, 2021, pages 15262– 15271. Computer Vision Foundation / IEEE, 2021. 5
2021
-
[21]
Batch normalization: Accelerating deep network training by reducing internal co- variate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal co- variate shift. InProceedings of the 32nd International Con- ference on Machine Learning, ICML 2015, Lille, France, 6- 11 July 2015, pages 448–456. JMLR.org, 2015. 2, 4, 15
2015
-
[22]
Adilbek Karmanov, Dayan Guan, Shijian Lu, Abdulmotaleb El-Saddik, and Eric P. Xing. Efficient test-time adaptation of vision-language models. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 14162–14171. IEEE,
2024
-
[23]
2, 4, 5, 6, 7, 13, 17, 18, 24
-
[24]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 5
2009
-
[25]
Entropy is not enough for test-time adaptation: From the perspective of disentangled factors
Jonghyun Lee, Dahuin Jung, Saehyung Lee, Junsung Park, Juhyeon Shin, Uiwon Hwang, and Sungroh Yoon. Entropy is not enough for test-time adaptation: From the perspective of disentangled factors. InThe Twelfth International Con- ference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 2, 4
2024
-
[26]
A comprehensive sur- vey on test-time adaptation under distribution shifts.Int
Jian Liang, Ran He, and Tieniu Tan. A comprehensive sur- vey on test-time adaptation under distribution shifts.Int. J. Comput. Vis., 133(1):31–64, 2025. 1
2025
-
[27]
Marsden, Mario D ¨obler, and Bin Yang
Robert A. Marsden, Mario D ¨obler, and Bin Yang. Univer- sal test-time adaptation through weight ensembling, diversity weighting, and prior correction. InIEEE/CVF Winter Con- ference on Applications of Computer Vision, WACV 2024, Waikoloa, HI, USA, January 3-8, 2024, pages 2543–2553. IEEE, 2024. 1, 2, 3
2024
-
[28]
Bag of tricks for fully test-time adaptation
Saypraseuth Mounsaveng, Florent Chiaroni, Malik Boudiaf, Marco Pedersoli, and Ismail Ben Ayed. Bag of tricks for fully test-time adaptation. InIEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2024, Waikoloa, HI, USA, January 3-8, 2024, pages 1925–1934. IEEE, 2024. 3
2024
-
[29]
Efficient test-time model adaptation without forgetting
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Yaofo Chen, Shijian Zheng, Peilin Zhao, and Mingkui Tan. Efficient test-time model adaptation without forgetting. InInterna- tional Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, pages 16888–16905. PMLR, 2022. 1, 2, 3, 4
2022
-
[30]
Towards sta- ble test-time adaptation in dynamic wild world
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Zhiquan Wen, Yaofo Chen, Peilin Zhao, and Mingkui Tan. Towards sta- ble test-time adaptation in dynamic wild world. InThe Eleventh International Conference on Learning Representa- tions, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenRe- view.net, 2023. 1, 2, 3, 4, 5, 6, 7, 13, 15, 17, 18, 24
2023
-
[31]
Shuaicheng Niu, Guohao Chen, Deyu Chen, Yifan Zhang, Jiaxiang Wu, Zhiquan Wen, Yaofo Chen, Peilin Zhao, Chun- yan Miao, and Mingkui Tan. Adapt in the wild: Test-time entropy minimization with sharpness and feature regulariza- tion.CoRR, abs/2509.04977, 2025. 1, 3, 13
-
[32]
W ATT: weight average test time adaptation of CLIP
David Osowiechi, Mehrdad Noori, Gustavo Adolfo Vargas Hakim, Moslem Yazdanpanah, Ali Bahri, Milad Cheragha- likhani, Sahar Dastani, Farzad Beizaee, Ismail Ben Ayed, and Christian Desrosiers. W ATT: weight average test time adaptation of CLIP. InAdvances in Neural Information Pro- cessing Systems 38: Annual Conference on Neural Infor- mation Processing Sys...
2024
-
[33]
Styleclip: Text-driven manipu- lation of stylegan imagery
Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen- Or, and Dani Lischinski. Styleclip: Text-driven manipu- lation of stylegan imagery. In2021 IEEE/CVF Interna- tional Conference on Computer Vision, ICCV 2021, Mon- treal, QC, Canada, October 10-17, 2021, pages 2065–2074. IEEE, 2021. 1
2021
-
[34]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. In2019 IEEE/CVF International Con- ference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 1406–1415. IEEE, 2019. 5, 17
2019
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, ...
2021
-
[36]
1, 2, 6, 7, 17, 18, 24
PMLR, 2021. 1, 2, 6, 7, 17, 18, 24
2021
-
[37]
Denseclip: Language-guided dense prediction with context- aware prompting
Yongming Rao, Wenliang Zhao, Guangyi Chen, Yansong Tang, Zheng Zhu, Guan Huang, Jie Zhou, and Jiwen Lu. Denseclip: Language-guided dense prediction with context- aware prompting. InIEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 18061–18070. IEEE, 2022. 1
2022
-
[38]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to ima- genet? InProceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, pages 5389–5400. PMLR, 2019. 5
2019
-
[39]
Test- time prompt tuning for zero-shot generalization in vision- language models
Manli Shu, Weili Nie, De-An Huang, Zhiding Yu, Tom Goldstein, Anima Anandkumar, and Chaowei Xiao. Test- time prompt tuning for zero-shot generalization in vision- language models. InAdvances in Neural Information Pro- cessing Systems 35: Annual Conference on Neural Informa- tion Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - De...
2022
-
[40]
Just shift it: Test-time prototype shifting for zero-shot general- ization with vision-language models
Elaine Sui, Xiaohan Wang, and Serena Yeung-Levy. Just shift it: Test-time prototype shifting for zero-shot general- ization with vision-language models. InIEEE/CVF Win- ter Conference on Applications of Computer Vision, WACV 2025, Tucson, AZ, USA, February 26 - March 6, 2025, pages 825–835. IEEE, 2025. 2
2025
-
[41]
Un-mixing test-time normalization statistics: Combatting label temporal correlation
Devavrat Tomar, Guillaume Vray, Jean-Philippe Thiran, and Behzad Bozorgtabar. Un-mixing test-time normalization statistics: Combatting label temporal correlation. InThe Twelfth International Conference on Learning Representa- tions, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net, 2024. 1, 2, 3
2024
-
[42]
Ol- shausen, and Trevor Darrell
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno A. Ol- shausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Aus- tria, May 3-7, 2021. OpenReview.net, 2021. 2, 4, 6, 7, 13, 15, 17, 18, 24
2021
-
[43]
Lipton, and Eric P
Haohan Wang, Songwei Ge, Zachary C. Lipton, and Eric P. Xing. Learning robust global representations by penalizing local predictive power. InAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Infor- mation Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 10506–10518,
2019
-
[44]
Con- tinual test-time domain adaptation
Qin Wang, Olga Fink, Luc Van Gool, and Dengxin Dai. Con- tinual test-time domain adaptation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 7191–7201. IEEE, 2022. 2, 13
2022
-
[45]
In search of lost online test-time adap- tation: A survey.Int
Zixin Wang, Yadan Luo, Liang Zheng, Zhuoxiao Chen, Sen Wang, and Zi Huang. In search of lost online test-time adap- tation: A survey.Int. J. Comput. Vis., 133(3):1106–1139,
-
[46]
Group normalization
Yuxin Wu and Kaiming He. Group normalization. InCom- puter Vision - ECCV 2018 - 15th European Conference, Mu- nich, Germany, September 8-14, 2018, Proceedings, Part XIII, pages 3–19. Springer, 2018. 4, 15
2018
- [47]
-
[48]
Robust test-time adaptation in dynamic scenarios
Longhui Yuan, Binhui Xie, and Shuang Li. Robust test-time adaptation in dynamic scenarios. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 15922– 15932. IEEE, 2023. 1, 2, 6, 7, 13, 17, 18, 24
2023
-
[49]
Realistic test- time adaptation of vision-language models
Maxime Zanella, Cl ´ement Fuchs, Christophe De Vleeschouwer, and Ismail Ben Ayed. Realistic test- time adaptation of vision-language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 25103–25112. Computer Vision Foundation / IEEE, 2025. 13
2025
-
[50]
Subspace alignment for vision-language model test-time adaptation
Zhichen Zeng, Wenxuan Bao, Xiao Lin, Ruizhong Qiu, Tianxin Wei, Xuying Ning, Yuchen Yan, Chen Luo, Mon- ica Xiao Cheng, Jingrui He, and Hanghang Tong. Subspace alignment for vision-language model test-time adaptation. CoRR, abs/2601.08139, 2026. 15
-
[51]
Root mean square layer nor- malization
Biao Zhang and Rico Sennrich. Root mean square layer nor- malization. InAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Information Pro- cessing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 12360–12371, 2019. 4, 15
2019
-
[52]
Tip- adapter: Training-free adaption of CLIP for few-shot classi- fication
Renrui Zhang, Wei Zhang, Rongyao Fang, Peng Gao, Kun- chang Li, Jifeng Dai, Yu Qiao, and Hongsheng Li. Tip- adapter: Training-free adaption of CLIP for few-shot classi- fication. InComputer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceed- ings, Part XXXV, pages 493–510. Springer, 2022. 6, 17
2022
-
[53]
Adanpc: Ex- ploring non-parametric classifier for test-time adaptation
Yifan Zhang, Xue Wang, Kexin Jin, Kun Yuan, Zhang Zhang, Liang Wang, Rong Jin, and Tieniu Tan. Adanpc: Ex- ploring non-parametric classifier for test-time adaptation. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, pages 41647– 41676. PMLR, 2023. 2
2023
-
[54]
Dual memory networks: A ver- satile adaptation approach for vision-language models
Yabin Zhang, Wenjie Zhu, Hui Tang, Zhiyuan Ma, Kaiyang Zhou, and Lei Zhang. Dual memory networks: A ver- satile adaptation approach for vision-language models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 28718–28728. IEEE, 2024. 2, 4, 5, 6, 7, 13, 17, 18, 24
2024
-
[55]
Regionclip: Region-based language-image pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, and Jianfeng Gao. Regionclip: Region-based language-image pretraining. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 16772–16782. IEEE, 2022. 1
2022
-
[56]
itap of a{class}
Lihua Zhou, Mao Ye, Shuaifeng Li, Nianxin Li, Xiatian Zhu, Lei Deng, Hongbin Liu, and Zhen Lei. Bayesian test-time adaptation for vision-language models. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 29999– 30009. Computer Vision Foundation / IEEE, 2025. 13 Ramen: Robust Test-Tim...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.