Recognition: unknown
A Robust Framework for Two-Sample Mendelian Randomization under Population Heterogeneity
Pith reviewed 2026-05-09 20:48 UTC · model grok-4.3
The pith
A model-free estimator for two-sample Mendelian randomization produces consistent causal effect estimates even when the exposure and outcome samples come from different populations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a robust, model-free Mendelian randomization framework that directly addresses population heterogeneity in the two-sample summary-data setting. Our method avoids parametric assumptions about population differences and is designed to address real-world challenges, including measurement error, weak instruments, and pleiotropy. We show that the proposed estimator is consistent and asymptotically normal under heterogeneous designs, and may offer efficiency gains over the classic estimator even in homogeneous settings.
What carries the argument
The robust model-free estimator that corrects for population heterogeneity in two-sample summary-data Mendelian randomization without parametric modeling of the differences between samples.
If this is right
- Causal effect estimates remain unbiased when samples differ in ancestry, demographics, or measurement protocols.
- The estimator can be more efficient than the standard two-sample estimator even when the populations are in fact homogeneous.
- The approach simultaneously accommodates measurement error, weak instruments, and pleiotropy while handling heterogeneity.
- It enables causal analyses that combine ancestrally diverse cohorts that would otherwise be excluded.
Where Pith is reading between the lines
- Larger multi-ancestry genomic datasets could be analyzed for causal effects without first harmonizing samples to a single ancestry.
- The method may be tested on additional trait pairs where population mismatch is known to bias existing estimators.
- Extensions could examine performance when heterogeneity interacts with specific forms of pleiotropy not covered in the current proofs.
Load-bearing premise
The estimator remains consistent without any parametric description of how the two populations differ, provided the genetic instruments satisfy validity conditions that allow the correction to work.
What would settle it
A simulation or real-data application in which the estimator exhibits systematic bias when the two samples differ in ancestry or demographics in a way that the unstated minimal conditions for consistency do not hold.
Figures




read the original abstract
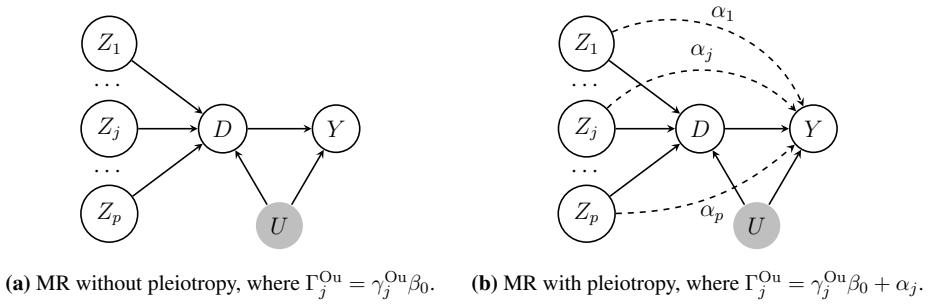
Mendelian randomization is a powerful tool for causal inference in observational studies. The two-sample summary-data design, which estimates genetic associations with exposures and outcomes in separate cohorts, is the most widely used Mendelian randomization approach in large-scale genomic studies. However, this approach relies on a strong assumption of population homogeneity across the two samples. In practice, available samples often differ in ancestry, demographics, socioeconomic factors, covariate adjustment, and measurement protocols. Violations of the homogeneity assumption can bias causal effect estimates and undermine the credibility of Mendelian randomization findings. We introduce a robust, model-free Mendelian randomization framework that directly addresses population heterogeneity in the two-sample summary-data setting. Our method avoids parametric assumptions about population differences and is designed to address real-world challenges, including measurement error, weak instruments, and pleiotropy. We show that the proposed estimator is consistent and asymptotically normal under heterogeneous designs, and may offer efficiency gains over the classic estimator even in homogeneous settings. Through numerical simulations and a real data analysis for estimating the causal effect of body mass index on high-density lipoprotein cholesterol across ancestrally diverse populations, we demonstrate the practical utility, stability, and robustness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a robust, model-free framework for two-sample summary-data Mendelian randomization designed to handle population heterogeneity without parametric assumptions on ancestry, demographics, or measurement differences. The proposed estimator is claimed to be consistent and asymptotically normal under heterogeneous designs, potentially offering efficiency gains over standard estimators even under homogeneity, while addressing challenges such as measurement error, weak instruments, and pleiotropy. Validation includes numerical simulations and a real-data application estimating the causal effect of BMI on HDL cholesterol across ancestrally diverse populations.
Significance. If the theoretical guarantees and empirical performance hold, the work would meaningfully advance causal inference in Mendelian randomization by relaxing the strong homogeneity assumption that is frequently violated in practice. The model-free nature and reported robustness to common MR issues represent a practical strength, as do the inclusion of simulations and a real-data example on ancestrally diverse cohorts. These elements provide concrete evidence of utility beyond purely theoretical claims.
major comments (1)
- [Theoretical results] The abstract asserts consistency and asymptotic normality under heterogeneous designs without parametric assumptions, yet the minimal conditions required for these properties (e.g., on the form of heterogeneity or moment restrictions) are not explicitly delineated; this makes it difficult to assess the scope of the result and should be stated clearly in the theoretical development section.
minor comments (2)
- [Abstract] The abstract would benefit from a concise statement of the estimator's construction or key innovation to help readers immediately grasp how it differs from existing two-sample MR methods.
- [Simulation studies] Figure captions and table legends should explicitly note the simulation settings for heterogeneity (e.g., ancestry differences or measurement protocols) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We appreciate the positive assessment of the proposed framework and its potential contributions to Mendelian randomization under population heterogeneity. We address the single major comment below.
read point-by-point responses
-
Referee: [Theoretical results] The abstract asserts consistency and asymptotic normality under heterogeneous designs without parametric assumptions, yet the minimal conditions required for these properties (e.g., on the form of heterogeneity or moment restrictions) are not explicitly delineated; this makes it difficult to assess the scope of the result and should be stated clearly in the theoretical development section.
Authors: We agree that the minimal conditions for consistency and asymptotic normality should be stated more explicitly to clarify the scope of the results. In the revised manuscript, we will add a dedicated subsection immediately preceding the main theorems in the theoretical development section. This subsection will enumerate the assumptions, including: (i) the permitted form of heterogeneity (arbitrary differences in ancestry, demographics, covariate adjustment, and measurement protocols across samples, without requiring parametric models for these differences); (ii) moment restrictions (finite second moments on the genetic association estimates and outcome summaries, along with uniform boundedness conditions to invoke the central limit theorem); and (iii) standard MR assumptions adapted to the heterogeneous setting (relevance, exclusion restriction, and no unmeasured confounding within each sample). These conditions will also be cross-referenced in the abstract and introduction. This change improves transparency without altering the stated results or proofs. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new model-free estimator for two-sample Mendelian randomization that targets consistency and asymptotic normality under population heterogeneity without parametric assumptions on ancestry or measurement differences. The abstract and description present the estimator as directly constructed to address heterogeneity, with theoretical claims supported by simulations and real-data analysis rather than by re-fitting or re-naming quantities derived from the same inputs. No self-definitional steps, fitted-input predictions, or load-bearing self-citations that reduce the central result to its own inputs are identifiable from the provided material. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
(2015), Mendelian randomization with invalid instruments: effect estimation and bias detection through Egger regression, International Journal of Epidemiology, 44, 512--525
Bowden, J., Davey Smith, G., and Burgess, S. (2015), Mendelian randomization with invalid instruments: effect estimation and bias detection through Egger regression, International Journal of Epidemiology, 44, 512--525
2015
-
[3]
C., and Burgess, S
Bowden, J., Davey Smith, G., Haycock, P. C., and Burgess, S. (2016), Consistent estimation in Mendelian randomization with some invalid instruments using a weighted median estimator, Genetic epidemiology, 40, 304--314
2016
-
[4]
(2017), A framework for the investigation of pleiotropy in two-sample summary data Mendelian randomization, Statistics in Medicine, 36, 1783--1802
Bowden, J., Del Greco M, F., Minelli, C., Davey Smith, G., Sheehan, N., and Thompson, J. (2017), A framework for the investigation of pleiotropy in two-sample summary data Mendelian randomization, Statistics in Medicine, 36, 1783--1802
2017
-
[5]
Burgess, S., Butterworth, A., and Thompson, S. G. (2013), Mendelian randomization analysis with multiple genetic variants using summarized data, Genetic epidemiology, 37, 658--665
2013
-
[6]
M., and Thompson, S
Burgess, S., Davies, N. M., and Thompson, S. G. (2016), Bias due to participant overlap in two-sample Mendelian randomization, Genetic epidemiology, 40, 597--608
2016
-
[7]
D., Davies, N
Burgess, S., Smith, G. D., Davies, N. M., Dudbridge, F., Gill, D., Glymour, M. M., Hartwig, F. P., Kutalik, Z., Holmes, M. V., Minelli, C., et al. (2023), Guidelines for performing Mendelian randomization investigations: update for summer 2023, Wellcome Open Research, 4, 186
2023
-
[8]
and Thompson, S
Burgess, S. and Thompson, S. G. (2017), Interpreting findings from Mendelian randomization using the MR-Egger method, European journal of epidemiology, 32, 377--389
2017
-
[9]
and Hemani, G
Davey Smith, G. and Hemani, G. (2014), Mendelian randomization: genetic anchors for causal inference in epidemiological studies, Human molecular genetics, 23, R89--R98
2014
-
[10]
L., Justice, A
Fern \'a ndez-Rhodes, L., Graff, M., Buchanan, V. L., Justice, A. E., Highland, H. M., Guo, X., Zhu, W., Chen, H.-H., Young, K. L., Adhikari, K., et al. (2022), Ancestral diversity improves discovery and fine-mapping of genetic loci for anthropometric traits-The Hispanic/Latino Anthropometry Consortium, Human Genetics and Genomics Advances, 3, 1--21
2022
-
[11]
and Burgess, S
Gkatzionis, A. and Burgess, S. (2019), Contextualizing selection bias in Mendelian randomization: how bad is it likely to be? International Journal of Epidemiology, 48, 691--701
2019
-
[12]
P., Davey Smith, G., and Bowden, J
Hartwig, F. P., Davey Smith, G., and Bowden, J. (2017), Robust inference in summary data Mendelian randomization via the zero modal pleiotropy assumption, International Journal of Epidemiology, 46, 1985--1998
2017
-
[13]
H., Haberland, V., Baird, D., Laurin, C., Burgess, S., Bowden, J., Langdon, R., et al
Hemani, G., Zheng, J., Elsworth, B., Wade, K. H., Haberland, V., Baird, D., Laurin, C., Burgess, S., Bowden, J., Langdon, R., et al. (2018), The MR-Base platform supports systematic causal inference across the human phenome, elife, 7, e34408
2018
-
[14]
(2024), A latent mixture model for heterogeneous causal mechanisms in Mendelian randomization, The Annals of Applied Statistics, 18, 966--990
Iong, D., Zhao, Q., and Chen, Y. (2024), A latent mixture model for heterogeneous causal mechanisms in Mendelian randomization, The Annals of Applied Statistics, 18, 966--990
2024
-
[15]
(2018), Genetic analysis of quantitative traits in the Japanese population links cell types to complex human diseases, Nature Genetics, 50, 390--400
Kanai, M., Akiyama, M., Takahashi, A., Matoba, N., Momozawa, Y., Ikeda, M., Iwata, N., Ikegawa, S., Hirata, M., Matsuda, K., et al. (2018), Genetic analysis of quantitative traits in the Japanese population links cell types to complex human diseases, Nature Genetics, 50, 390--400
2018
-
[16]
J., Gupta, R., Kanai, M., Lu, W., Tsuo, K., Wang, Y., Walters, R
Karczewski, K. J., Gupta, R., Kanai, M., Lu, W., Tsuo, K., Wang, Y., Walters, R. K., Turley, P., Callier, S., Shah, N. N., et al. (2025), Pan-UK Biobank genome-wide association analyses enhance discovery and resolution of ancestry-enriched effects, Nature genetics, 57, 2408--2417
2025
-
[17]
(2005), Quantile regression, vol
Koenker, R. (2005), Quantile regression, vol. 38, Cambridge University Press
2005
-
[18]
A., Harbord, R
Lawlor, D. A., Harbord, R. M., Sterne, J. A., Timpson, N., and Davey Smith, G. (2008), Mendelian randomization: using genes as instruments for making causal inferences in epidemiology, Statistics in medicine, 27, 1133--1163
2008
-
[19]
and Morrison, J
Li, J. and Morrison, J. (2026), Mind the gap: characterizing bias due to population mismatch in two-sample Mendelian randomization, The American Journal of Human Genetics, 113, 483--493
2026
-
[20]
E., Kahali, B., Berndt, S
Locke, A. E., Kahali, B., Berndt, S. I., Justice, A. E., Pers, T. H., Day, F. R., Powell, C., Vedantam, S., Buchkovich, M. L., Yang, J., et al. (2015), Genetic studies of body mass index yield new insights for obesity biology, Nature, 518, 197--206
2015
-
[21]
Manuck, S. B. and McCaffery, J. M. (2014), Gene-environment interaction, Annual review of psychology, 65, 41--70
2014
-
[22]
A., Ziyatdinov, A., Benner, C., O'Dushlaine, C., Barber, M., Boutkov, B., et al
Mbatchou, J., Barnard, L., Backman, J., Marcketta, A., Kosmicki, J. A., Ziyatdinov, A., Benner, C., O'Dushlaine, C., Barber, M., Boutkov, B., et al. (2021), Computationally efficient whole-genome regression for quantitative and binary traits, Nature Genetics, 53, 1097--1103
2021
-
[23]
H., Stephens, M., and He, X
Morrison, J., Knoblauch, N., Marcus, J. H., Stephens, M., and He, X. (2020), Mendelian randomization accounting for correlated and uncorrelated pleiotropic effects using genome-wide summary statistics, Nature genetics, 52, 740--747
2020
-
[24]
Pierce, B. L. and Burgess, S. (2013), Efficient design for Mendelian randomization studies: subsample and 2-sample instrumental variable estimators, American Journal of Epidemiology, 178, 1177--1184
2013
-
[25]
A., Bender, D., Maller, J., Sklar, P., De Bakker, P
Purcell, S., Neale, B., Todd-Brown, K., Thomas, L., Ferreira, M. A., Bender, D., Maller, J., Sklar, P., De Bakker, P. I., Daly, M. J., et al. (2007), PLINK: a tool set for whole-genome association and population-based linkage analyses, The American Journal of Human Genetics, 81, 559--575
2007
-
[26]
and Genest, J
Rashid, S. and Genest, J. (2007), Effect of obesity on high-density lipoprotein metabolism, Obesity, 15, 2875--2888
2007
-
[27]
M., Wood, A
Rees, J. M., Wood, A. M., Dudbridge, F., and Burgess, S. (2019), Robust methods in Mendelian randomization via penalization of heterogeneous causal estimates, PloS One, 14, e0222362
2019
-
[28]
E., Rodriguez, A., Conery, M., Liu, M., Ho, Y.-L., Kim, Y., Heise, D
Verma, A., Huffman, J. E., Rodriguez, A., Conery, M., Liu, M., Ho, Y.-L., Kim, Y., Heise, D. A., Guare, L., Panickan, V. A., et al. (2024), Diversity and scale: Genetic architecture of 2068 traits in the VA Million Veteran Program, Science, 385, eadj1182
2024
-
[29]
(1940), The fitting of straight lines if both variables are subject to error, The Annals of Mathematical Statistics, 11, 284--300
Wald, A. (1940), The fitting of straight lines if both variables are subject to error, The Annals of Mathematical Statistics, 11, 284--300
1940
-
[30]
(2021), Debiased inverse-variance weighted estimator in two-sample summary-data Mendelian randomization, The Annals of Statistics, 49, 2079--2100
Ye, T., Shao, J., and Kang, H. (2021), Debiased inverse-variance weighted estimator in two-sample summary-data Mendelian randomization, The Annals of Statistics, 49, 2079--2100
2021
-
[31]
(2020), Statistical inference in two-sample summary-data mendelian randomization using robust adjusted profile score, Annals of Statistics, 48, 1742--1769
Zhao, Q., Wang, J., Hemani, G., Bowden, J., and Small, D. (2020), Statistical inference in two-sample summary-data mendelian randomization using robust adjusted profile score, Annals of Statistics, 48, 1742--1769
2020
-
[32]
Zhao, Q., Wang, J., Spiller, W., Bowden, J., and Small, D. S. (2019), Two-sample instrumental variable analyses using heterogeneous samples, Statistical Science, 34, 317--333
2019
-
[33]
J., Cole, J
Zhu, C., Ming, M. J., Cole, J. M., Edge, M. D., Kirkpatrick, M., and Harpak, A. (2023), Amplification is the primary mode of gene-by-sex interaction in complex human traits, Cell Genomics, 3, 100297
2023
-
[34]
Nature genetics , volume=
Mendelian randomization accounting for correlated and uncorrelated pleiotropic effects using genome-wide summary statistics , author=. Nature genetics , volume=. 2020 , publisher=
2020
-
[35]
Econometric theory , volume=
Generic uniform convergence , author=. Econometric theory , volume=. 1992 , publisher=
1992
-
[36]
Econometrica: journal of the Econometric Society , pages=
Regression quantiles , author=. Econometrica: journal of the Econometric Society , pages=. 1978 , publisher=
1978
-
[37]
Handbook of econometrics , volume=
Large sample estimation and hypothesis testing , author=. Handbook of econometrics , volume=. 1994 , publisher=
1994
-
[38]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Statistical inferences of linear forms for noisy matrix completion , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2021 , publisher=
2021
-
[40]
Journal of the American statistical Association , volume=
Identification of causal effects using instrumental variables , author=. Journal of the American statistical Association , volume=. 1996 , publisher=
1996
-
[41]
2005 , publisher=
Quantile regression , author=. 2005 , publisher=
2005
-
[42]
Science , volume=
Diversity and scale: Genetic architecture of 2068 traits in the VA Million Veteran Program , author=. Science , volume=. 2024 , publisher=
2068
-
[43]
Obesity , volume=
Effect of obesity on high-density lipoprotein metabolism , author=. Obesity , volume=. 2007 , publisher=
2007
-
[44]
Nature genetics , volume=
Pan-UK Biobank genome-wide association analyses enhance discovery and resolution of ancestry-enriched effects , author=. Nature genetics , volume=. 2025 , publisher=
2025
-
[45]
Statistics in medicine , volume=
Mendelian randomization: using genes as instruments for making causal inferences in epidemiology , author=. Statistics in medicine , volume=. 2008 , publisher=
2008
-
[46]
American Journal of Epidemiology , volume=
Efficient design for Mendelian randomization studies: subsample and 2-sample instrumental variable estimators , author=. American Journal of Epidemiology , volume=. 2013 , publisher=
2013
-
[47]
Annual review of psychology , volume=
Gene-environment interaction , author=. Annual review of psychology , volume=. 2014 , publisher=
2014
-
[48]
Cell Genomics , volume =
Amplification is the primary mode of gene-by-sex interaction in complex human traits , author=. Cell Genomics , volume =. 2023 , issn =
2023
-
[49]
Annals of statistics , pages=
Limiting distributions for L 1 regression estimators under general conditions , author=. Annals of statistics , pages=. 1998 , publisher=
1998
-
[50]
The Annals of Statistics , volume=
A general Bahadur representation of M-estimators and its application to linear regression with nonstochastic designs , author=. The Annals of Statistics , volume=. 1996 , publisher=
1996
-
[51]
Journal of Computational and Graphical Statistics , volume=
Mixed matrix completion in complex survey sampling under heterogeneous missingness , author=. Journal of Computational and Graphical Statistics , volume=. 2024 , publisher=
2024
-
[52]
Annals of Statistics , volume=
Statistical inference in two-sample summary-data mendelian randomization using robust adjusted profile score , author=. Annals of Statistics , volume=
-
[53]
arXiv preprint arXiv:2110.07740 , year=
More Efficient, Doubly Robust, Nonparametric Estimators of Treatment Effects in Multilevel Studies , author=. arXiv preprint arXiv:2110.07740 , year=
-
[54]
Japanese Journal of Statistics and Data Science , volume=
Statistical data integration in survey sampling: A review , author=. Japanese Journal of Statistics and Data Science , volume=. 2020 , publisher=
2020
-
[55]
International Journal of Epidemiology , volume=
Two-sample Mendelian randomization: avoiding the downsides of a powerful, widely applicable but potentially fallible technique , author=. International Journal of Epidemiology , volume=. 2016 , publisher=
2016
-
[56]
International Journal of Epidemiology , volume=
Mendelian randomization with invalid instruments: effect estimation and bias detection through Egger regression , author=. International Journal of Epidemiology , volume=. 2015 , publisher=
2015
-
[57]
The Annals of Applied Statistics , volume=
A latent mixture model for heterogeneous causal mechanisms in Mendelian randomization , author=. The Annals of Applied Statistics , volume=. 2024 , publisher=
2024
-
[58]
European journal of epidemiology , volume=
Interpreting findings from Mendelian randomization using the MR-Egger method , author=. European journal of epidemiology , volume=. 2017 , publisher=
2017
-
[59]
PloS One , volume=
Robust methods in Mendelian randomization via penalization of heterogeneous causal estimates , author=. PloS One , volume=. 2019 , publisher=
2019
-
[60]
arXiv preprint arXiv:2406.14140 , year=
Nonparametric Jackknife Instrumental Variable Estimation and Confounding Robust Surrogate Indices , author=. arXiv preprint arXiv:2406.14140 , year=
-
[61]
International Journal of Epidemiology , volume=
Contextualizing selection bias in Mendelian randomization: how bad is it likely to be? , author=. International Journal of Epidemiology , volume=. 2019 , publisher=
2019
-
[62]
International Journal of Epidemiology , volume=
Robust inference in summary data Mendelian randomization via the zero modal pleiotropy assumption , author=. International Journal of Epidemiology , volume=. 2017 , publisher=
2017
-
[63]
Genetic epidemiology , volume=
Consistent estimation in Mendelian randomization with some invalid instruments using a weighted median estimator , author=. Genetic epidemiology , volume=. 2016 , publisher=
2016
-
[64]
Statistical Science , volume=
Two-sample instrumental variable analyses using heterogeneous samples , author=. Statistical Science , volume=. 2019 , publisher=
2019
-
[65]
Human molecular genetics , volume=
Mendelian randomization: genetic anchors for causal inference in epidemiological studies , author=. Human molecular genetics , volume=. 2014 , publisher=
2014
-
[66]
Quantitative Economics , volume=
Semiparametric efficiency in nonlinear LATE models , author=. Quantitative Economics , volume=. 2010 , publisher=
2010
-
[67]
and Zubizarreta, J
Yang, F. and Zubizarreta, J. R. and Small, D. S. and Lorch, S. and Rosenbaum, P. R. , date-added =. Dissonant conclusions when testing the validity of an instrumental variable , volume =. American Statistician , pages =
-
[68]
and Cheng, J
Guo, Z. and Cheng, J. and Lorch, S. A. and Small, D. S. , date-added =. Using an instrumental variable to test for unmeasured confounding , volume =. Statistics in Medicine , pages =
-
[69]
Angrist, J. D. and Imbens, G. W. , date-added =. Identification and estimation of local average treatment effects , volume =. Econometrica , pages =
-
[70]
Principal stratification with predictors of compliance for randomized trials with 2 active treatments , volume =
Roy, Jason and Hogan, Joseph W and Marcus, Bess H , date-modified =. Principal stratification with predictors of compliance for randomized trials with 2 active treatments , volume =. Biostatistics , pages =
-
[71]
Health effects of power plant emissions through ambient air quality , year =
Kim, Chanmin and Henneman, Lucas RF and Choirat, Christine and Zigler, Corwin M , journal =. Health effects of power plant emissions through ambient air quality , year =
-
[72]
Surrogacy assessment using principal stratification and a
Conlon, ASC and Taylor, JMG and Elliott, MR , date-modified =. Surrogacy assessment using principal stratification and a. Statistical Methods in Medical Research , pages =
-
[73]
Using survival information in truncation by death problems without the monotonicity assumption , volume =
Yang, Fan and Ding, Peng , date-modified =. Using survival information in truncation by death problems without the monotonicity assumption , volume =. Biometrics , pages =
-
[74]
VanderWeele, T. J. , date-modified =. Simple relations between principal stratification and direct and indirect effects , volume =. Statistics and Probability Letters , pages =
-
[75]
Bayesian inference for the causal effect of mediation , volume =
Daniels, Michael J and Roy, Jason A and Kim, Chanmin and Hogan, Joseph W and Perri, Michael G , date-modified =. Bayesian inference for the causal effect of mediation , volume =. Biometrics , pages =
-
[76]
Modeling partial compliance through copulas in a principal stratification framework , volume =
Bartolucci, Francesco and Grilli, Leonardo , journal =. Modeling partial compliance through copulas in a principal stratification framework , volume =
-
[77]
Identification of principal causal effects using additional outcomes in concentration graphs , volume =
Mealli, Fabrizia and Pacini, Barbara and Stanghellini, Elena , journal =. Identification of principal causal effects using additional outcomes in concentration graphs , volume =
-
[78]
Identification, inference and sensitivity analysis for causal mediation effects , volume =
Imai, Kosuke and Keele, Luke and Yamamoto, Teppei , journal =. Identification, inference and sensitivity analysis for causal mediation effects , volume =
-
[79]
, date-modified =
Imai, K. , date-modified =. Sharp bounds on the causal effects in randomized experiments with ``truncation-by-death'' , volume =. Statistics and Probability Letters , pages =
-
[80]
Principal stratification for causal inference with extended partial compliance , volume =
Jin, Hui and Rubin, Donald B , journal =. Principal stratification for causal inference with extended partial compliance , volume =
-
[81]
Compliance as an explanatory variable in clinical trials (with discussion) , volume =
Efron, Bradley and Feldman, David , journal =. Compliance as an explanatory variable in clinical trials (with discussion) , volume =
-
[82]
A Bayesian semiparametric approach to intermediate variables in causal inference , volume =
Schwartz, Scott L and Li, Fan and Mealli, Fabrizia , journal =. A Bayesian semiparametric approach to intermediate variables in causal inference , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.