Recognition: unknown
Thinking with Reasoning Skills: Fewer Tokens, More Accuracy
Pith reviewed 2026-05-09 21:58 UTC · model grok-4.3
The pith
Distilling reusable reasoning skills from prior deliberation lets models solve new problems with fewer tokens and higher accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
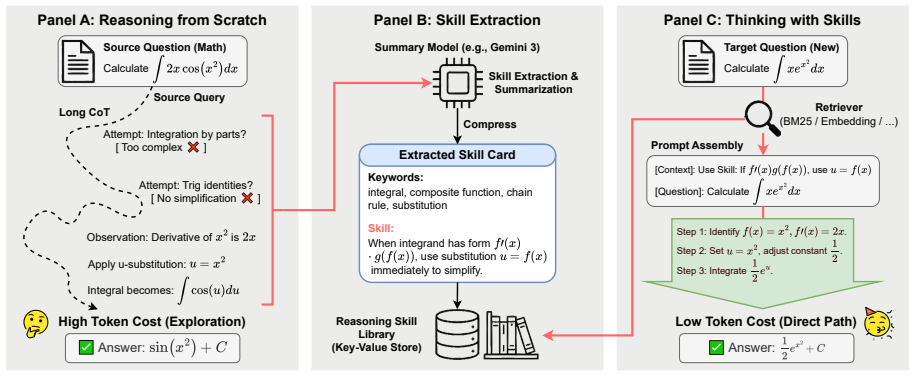
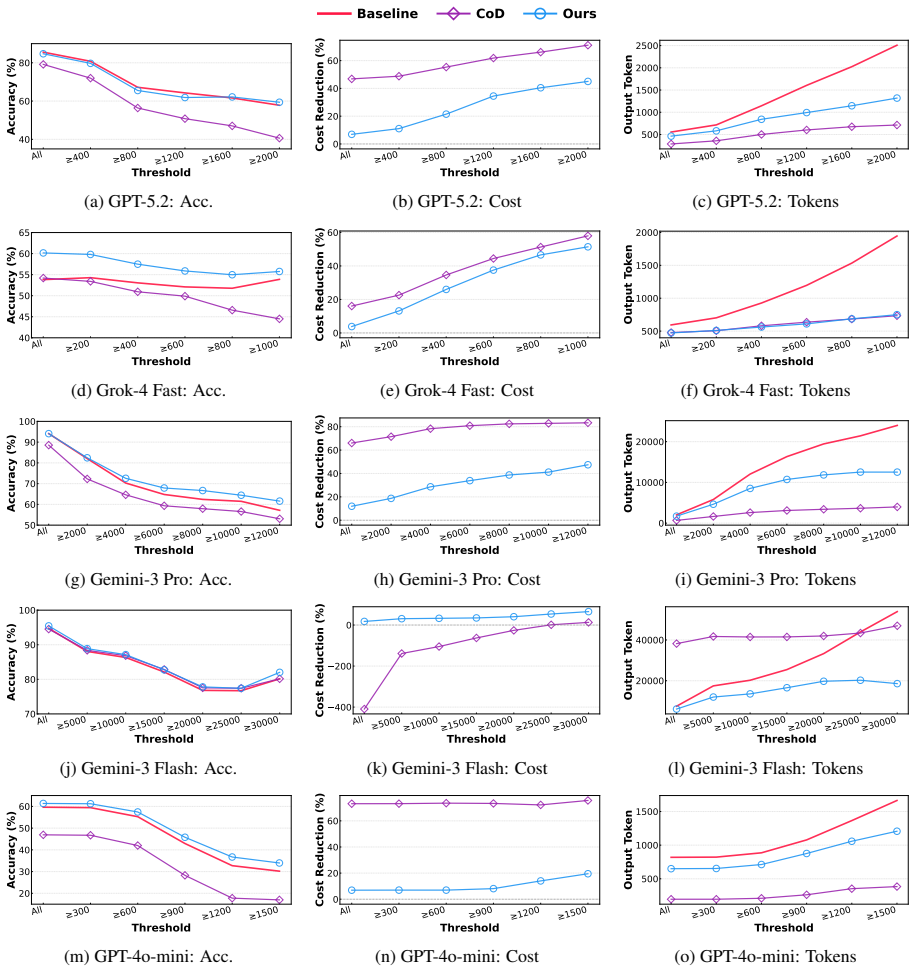
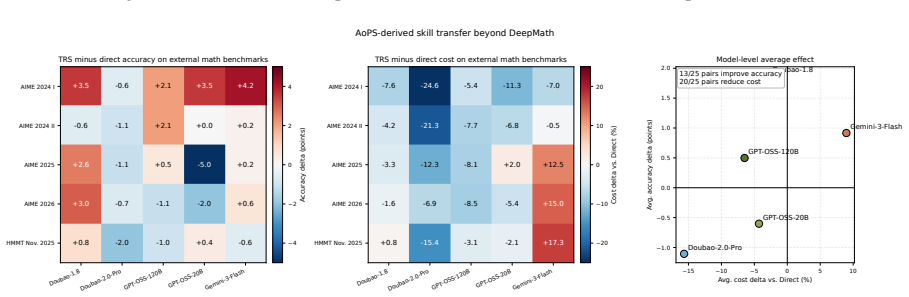
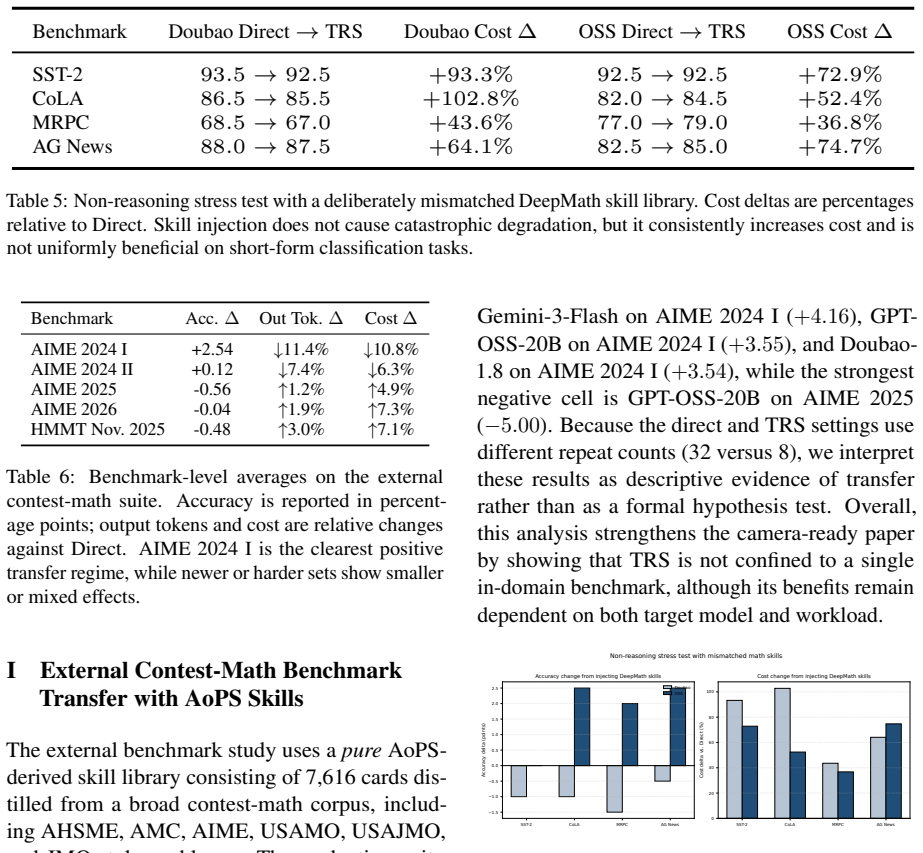
By first recalling relevant skills distilled from prior deliberation and trial-and-error, the model avoids redundant detours and focuses on effective solution paths, yielding shorter reasoning traces and improved accuracy on coding and mathematical tasks compared with reasoning entirely from scratch.
What carries the argument
Reusable reasoning skills: compact summaries of effective solution strategies extracted from extensive prior deliberation and retrieved at inference time to guide the current reasoning process.
Load-bearing premise
Skills distilled from earlier problems remain general enough, accurately retrievable, and free of errors when applied to fresh problems.
What would settle it
A test set of coding and math problems where retrieving and applying the stored skills produces lower accuracy or longer token counts than standard chain-of-thought reasoning from scratch.
Figures













read the original abstract
Reasoning LLMs often spend substantial tokens on long intermediate reasoning traces (e.g., chain-of-thought) when solving new problems. We propose to summarize and store reusable reasoning skills distilled from extensive deliberation and trial-and-error exploration, and to retrieve these skills at inference time to guide future reasoning. Unlike the prevailing \emph{reasoning from scratch} paradigm, our approach first recalls relevant skills for each query, helping the model avoid redundant detours and focus on effective solution paths. We evaluate our method on coding and mathematical reasoning tasks, and find that it significantly reduces reasoning tokens while improving overall performance. The resulting lower per-request cost indicates strong practical and economic potential for real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes distilling reusable reasoning skills from extensive deliberation and trial-and-error exploration, storing them for later use, and retrieving relevant skills at inference time to guide reasoning on new problems. This is positioned as an alternative to 'reasoning from scratch' with long chain-of-thought traces, with the central claim being that the approach significantly reduces reasoning tokens while improving performance on coding and mathematical reasoning tasks.
Significance. If the empirical claims are substantiated with detailed results, the work could offer meaningful practical value by lowering per-request inference costs for reasoning LLMs, which has clear economic implications for deployment. The core idea of reusable skill distillation builds on existing concepts in knowledge reuse and could address inefficiencies in current reasoning paradigms, but its significance hinges on demonstrating reliable generalization.
major comments (3)
- [Abstract] Abstract: The claim that the method 'significantly reduces reasoning tokens while improving overall performance' is presented without any quantitative metrics, baselines, error bars, task-specific results, or implementation details. This is load-bearing for the central empirical claim, as no evaluation data is supplied to allow verification or assessment of effect sizes.
- [Method] Method description: The distillation of skills from deliberation, their summarization and storage, and the retrieval mechanism at inference time are described only at a high level with no algorithmic details, pseudocode, or formalization. This prevents evaluation of how token reduction is achieved in practice and whether retrieval introduces latency or errors.
- [Evaluation] Evaluation section: Despite stating that the method was evaluated on coding and mathematical reasoning tasks, the manuscript provides no description of the experimental setup, models, datasets, number of stored skills, retrieval implementation, or comparison results. This directly undermines the ability to assess the accuracy improvement and generalization claims.
minor comments (1)
- [Abstract] The abstract could be strengthened by including at least one key quantitative result (e.g., token reduction percentage or accuracy delta) to make the claims more concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify opportunities to improve the clarity and verifiability of our claims. We address each major point below and will incorporate the requested details through substantial revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the method 'significantly reduces reasoning tokens while improving overall performance' is presented without any quantitative metrics, baselines, error bars, task-specific results, or implementation details. This is load-bearing for the central empirical claim, as no evaluation data is supplied to allow verification or assessment of effect sizes.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the central claims. In the revised version, we will add specific metrics drawn from our experiments (e.g., observed token reductions and accuracy gains on the coding and math tasks) together with baseline comparisons, so that the effect sizes are evident directly from the abstract. revision: yes
-
Referee: [Method] Method description: The distillation of skills from deliberation, their summarization and storage, and the retrieval mechanism at inference time are described only at a high level with no algorithmic details, pseudocode, or formalization. This prevents evaluation of how token reduction is achieved in practice and whether retrieval introduces latency or errors.
Authors: We acknowledge that the current method presentation remains conceptual. We will expand this section with algorithmic details, pseudocode for the distillation, summarization, storage, and retrieval steps, and a formal description of the overall process. We will also discuss any latency or error considerations introduced by retrieval. revision: yes
-
Referee: [Evaluation] Evaluation section: Despite stating that the method was evaluated on coding and mathematical reasoning tasks, the manuscript provides no description of the experimental setup, models, datasets, number of stored skills, retrieval implementation, or comparison results. This directly undermines the ability to assess the accuracy improvement and generalization claims.
Authors: We agree that the evaluation section requires a more complete description to substantiate the reported improvements. In the revision we will add a detailed experimental setup covering the models, datasets, number of stored skills, retrieval implementation, and full comparison results with baselines and task-specific breakdowns. revision: yes
Circularity Check
High-level empirical method proposal with no derivation chain or self-referential reductions
full rationale
The paper advances a practical proposal for distilling and retrieving reasoning skills to reduce token usage in LLMs, supported by evaluations on coding and mathematical tasks. No equations, fitted parameters, uniqueness theorems, or ansatzes are described in the provided text. The central claims rest on observed performance improvements rather than any derivation that reduces to its own inputs by construction. No self-citation load-bearing steps or renamings of known results appear. This is a standard non-circular empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972 , volume =
1972
-
[2]
Publications Manual , year =
-
[3]
Chandra and Dexter C
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , title =. Journal of the Association for Computing Machinery , year =
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle =. Scalable training of. 2007 , pages =
2007
-
[5]
1997 , publisher =
Dan Gusfield , title =. 1997 , publisher =
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , year =
-
[7]
Journal of Machine Learning Research , year =
Ando, Rie Kubota and Zhang, Tong , title =. Journal of Machine Learning Research , year =
-
[8]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. arXiv preprint arXiv:2201.11903 , year =
work page internal anchor Pith review arXiv
-
[9]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. arXiv preprint arXiv:2203.11171 , year =
work page internal anchor Pith review arXiv
-
[10]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author =. arXiv preprint arXiv:2305.10601 , year =
work page internal anchor Pith review arXiv
-
[11]
2022 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , journal =. 2022 , url =
2022
-
[12]
Token-budget-aware llm reasoning
Han, Tingxu and Fang, Chunrong and Zhao, Shiyu and Ma, Shiqing and Chen, Zhenyu and Wang, Zhenting , year =. Token-Budget-Aware. 2412.18547 , archivePrefix=
-
[13]
2025 , eprint =
Chain of Draft: Thinking Faster by Writing Less , author =. 2025 , eprint =
2025
-
[14]
arXiv preprint arXiv:2506.08343 , year =
Wait, We Don't Need to ``Wait''! Removing Thinking Tokens Improves Reasoning Efficiency , author =. arXiv preprint arXiv:2506.08343 , year =
-
[15]
2025 , eprint =
Reasoning Models Can Be Effective Without Thinking , author =. 2025 , eprint =
2025
-
[16]
Training Large Language Models to Reason in a Continuous Latent Space
Coconut: Reasoning in Continuous Latent Space for Efficient Inference , author =. arXiv preprint arXiv:2412.06769 , year =
work page internal anchor Pith review arXiv
-
[17]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. arXiv preprint arXiv:2303.11366 , year =
work page internal anchor Pith review arXiv
-
[18]
Findings of the Association for Computational Linguistics: ACL 2023 , year =
Prompt-Guided Retrieval Augmentation for Non-Knowledge-Intensive Tasks , author =. Findings of the Association for Computational Linguistics: ACL 2023 , year =
2023
-
[19]
arXiv preprint arXiv:2205.14704 , year =
Retrieval-Augmented Prompt Learning , author =. arXiv preprint arXiv:2205.14704 , year =
-
[20]
A Survey of Case-Based Reasoning for
Hatalis, Kostas and Christou, Despina and Kondapalli, Vyshnavi , journal =. A Survey of Case-Based Reasoning for. 2025 , url =
2025
-
[21]
Yan, JianZhi and Liu, Le and Pan, Youcheng and Chen, Shiwei and Xiang, Yang and Tang, Buzhou , booktitle =. Towards Efficient. 2025 , month = nov, address =. doi:10.18653/v1/2025.findings-emnlp.413 , url =
-
[23]
2024 , howpublished =
OpenAI o1 System Card , author =. 2024 , howpublished =
2024
-
[24]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. arXiv preprint arXiv:2501.12948 , year =. doi:10.48550/arXiv.2501.12948 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948
-
[25]
2025 , month = nov, howpublished =
A new era of intelligence with Gemini 3 , author =. 2025 , month = nov, howpublished =
2025
-
[26]
2026 , month = feb, howpublished =
Introducing Claude Opus 4.6 , author =. 2026 , month = feb, howpublished =
2026
-
[27]
2025 , howpublished =
GPT-5 System Card , author =. 2025 , howpublished =
2025
-
[28]
2026 , howpublished =
OpenAI API Pricing , author =. 2026 , howpublished =
2026
-
[29]
2025 , howpublished =
AI reasoning will take a toll on infrastructure footprint , author =. 2025 , howpublished =
2025
-
[30]
Findings of the Association for Computational Linguistics: ACL 2025 , year =
RaaS: Reasoning-Aware Attention Sparsity for Efficient LLM Reasoning , author =. Findings of the Association for Computational Linguistics: ACL 2025 , year =. doi:10.18653/v1/2025.findings-acl.131 , pages =
-
[31]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
Cache-of-Thought: Master-Apprentice Framework for Cost-Effective Vision Language Model Reasoning , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/2025.emnlp-main.97 , pages =
-
[32]
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models,
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models , author =. arXiv preprint arXiv:2406.04271 , year =. doi:10.48550/arXiv.2406.04271 , url =
-
[33]
International Conference on Learning Representations (ICLR) , year =
SuperCorrect: Advancing Small LLM Reasoning with Thought Template Distillation and Self-Correction , author =. International Conference on Learning Representations (ICLR) , year =
-
[34]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. arXiv preprint arXiv:2305.16291 , year =. doi:10.48550/arXiv.2305.16291 , url =
work page internal anchor Pith review doi:10.48550/arxiv.2305.16291
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.